muduo是最近几年中国开源界里产生的优秀作品。它是由业内大牛陈硕实现的。详细介绍,请参考其博客介绍http://blog.csdn.net/solstice/article/details/5848547。
本次测试是参考陈硕的博客文章muduo与libevent2吞吐量对比,该文章的结论是:muduo吞吐量平均比libevent2高 18% 以上。
由于evpp本身是基于libevent2实现的,因此我们希望将evpp和muduo放到一起做一次全面的性能测试。本文是关于这两个库在吞吐量方面的测试。
- evpp-v0.2.4 based on libevent-2.0.21
- muduo-v1.0.9
- Linux CentOS 6.2, 2.6.32-220.7.1.el6.x86_64
- Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz
- gcc version 4.8.2 20140120 (Red Hat 4.8.2-15) (GCC)
依据 boost.asio 性能测试 http://think-async.com/Asio/LinuxPerformanceImprovements 的办法,用 ping pong 协议来测试吞吐量。
简单地说,ping pong 协议是客户端和服务器都实现 echo 协议。当 TCP 连接建立时,客户端向服务器发送一些数据,服务器会 echo 回这些数据,然后客户端再 echo 回服务器。这些数据就会像乒乓球一样在客户端和服务器之间来回传送,直到有一方断开连接为止。这是用来测试吞吐量的常用办法。
muduo的测试代码在软件包内的路径为 examples/pingpong/,代码如https://github.com/chenshuo/muduo/tree/master/examples/pingpong所示。并使用BUILD_TYPE=release ./build.sh方式编译muduo的优化版本。
evpp的测试代码在软件包内的路径为benchmark/throughput/evpp,代码如https://github.com/Qihoo360/evpp/tree/master/benchmark/throughput/evpp所示。并使用 tools目录下的benchmark-build.sh
我们做了下面两项测试:
- 单线程测试,测试并发连接数为 1/10/100/1000/10000 时,消息大小分别为 4096 8192 81920 409600 时的吞吐量
- 多线程测试,并发连接数为 100 或 1000,服务器和客户端的线程数同时设为 2/3/4/6/8,ping pong 消息的大小为 16k bytes。测试用的 shell 脚本可从evpp的源码包中找到。
最终测试结论如下:
- 在吞吐量方面的性能总体来说,比较接近,各擅胜场
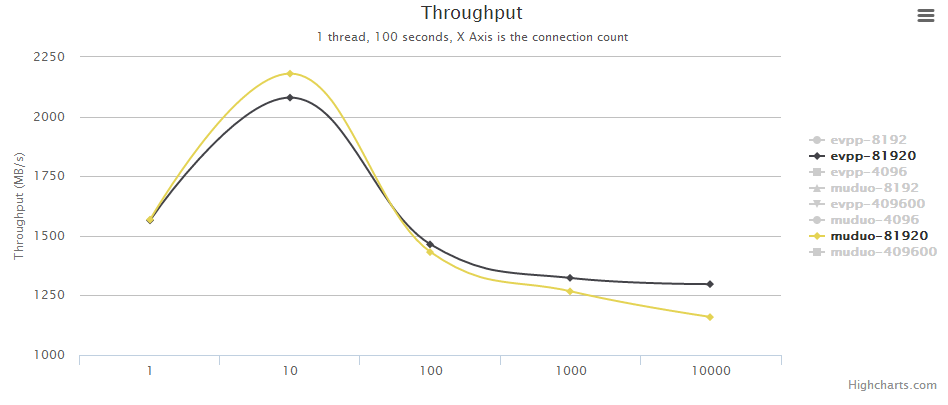
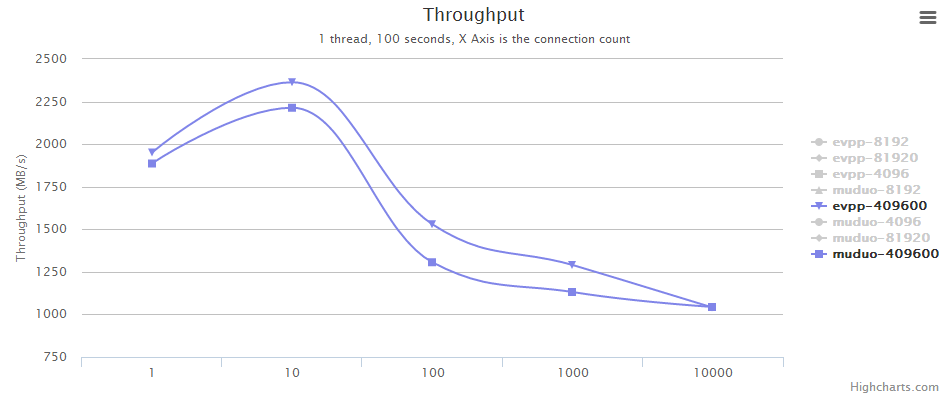
- 在单个消息较大时(>81K),evpp比muduo整体上更快
- 在单个消息不太大时,并发数小于1000时,evpp占优
- 在单个消息不太大时,并发数大于1000时,muduo占优
测试中,单个消息较大时,evpp比muduo整体上更快的结论,我们认为是与Buffer类的设计实现有关。evpp的Buffer类是自己人肉实现的内存管理,而muduo的Buffer类的底层是用std::vector<char>实现的,我们推测muduo的这个实现性能方面稍差。本次吞吐量测试中,主要的开销是网络IO事件的触发回调和数据读写,当消息size不太大时,网络IO的事件触发耗费CPU更多;当消息size较大时,数据的读写和拷贝占用更多CPU。当然这只是一个推测,后面如果有时间或大家感兴趣,可以自行验证两个库的Buffer类的操作性能。
这个测试结果进一步推断,evpp比libevent2更快(因为muduo吞吐量平均比libevent2高 18% 以上),表面上看不符合逻辑,因为evpp的底层就是libevent2,但仔细分析发现,evpp只是用了libevent2核心的事件循环,并没有用libevent2中的evbuffer相关类和函数来读写网络数据,而是借鉴muduo和Golang实现了自己独立的Buffer类来读写网络数据。
下面是具体的测试数据和图表。
| Name | Message Size | 1 connection | 10 connections | 100 connections | 1000 connections | 10000 connections |
|---|---|---|---|---|---|---|
| evpp | 4096 | 229.274 | 631.611 | 671.219 | 495.566 | 366.071 |
| muduo | 4096 | 222.117 | 609.152 | 631.119 | 514.235 | 365.959 |
| evpp | 8192 | 394.162 | 1079.67 | 1127.09 | 786.706 | 645.866 |
| muduo | 8192 | 393.683 | 1064.43 | 1103.02 | 815.269 | 670.503 |
| evpp | 81920 | 1565.22 | 2079.77 | 1464.16 | 1323.09 | 1297.18 |
| muduo | 81920 | 1567.959 | 2180.467 | 1432.009 | 1267.181 | 1159.278 |
| evpp | 409600 | 1950.79 | 2363.68 | 1528.97 | 1290.17 | 1039.96 |
| muduo | 409600 | 1887.057 | 2213.813 | 1305.899 | 1131.383 | 1043.612 |
我们用https://github.com/zieckey/gochart这个图表绘制工具将上述数据绘制为图表。


测试结论如下:
- 在多线程场景下,evpp和muduo两个库在吞吐量方面,的性能整体上来看没有明显区别,分阶段分别领先
- 100并发连接比1000并发连接测试,两个库的吞吐量都明显的高得多
- 在100并发连接测试下,随着线程数的增长,吞吐量基本上是线性增长。muduo库在中段领先于evpp,但在前期和后期又弱于evpp
- 在1000并发连接测试下,随着线程数的增长,前期基本上是线性增长,后期增长乏力。muduo库这方面表现尤其明显

The IO Event performance benchmark against Boost.Asio : evpp is higher than [asio] about 20%~50% in this case
The ping-pong benchmark against Boost.Asio : evpp is higher than [asio] about 5%~20% in this case
The throughput benchmark against libevent2 : evpp is higher than libevent about 17%~130% in this case
The performance benchmark of queue with std::mutex against boost::lockfree::queue and moodycamel::ConcurrentQueue : moodycamel::ConcurrentQueue is the best, the average is higher than boost::lockfree::queue about 25%~100% and higher than queue with std::mutex about 100%~500%
The throughput benchmark against Boost.Asio : evpp and [asio] have the similar performance in this case
The throughput benchmark against Boost.Asio(中文) : evpp and [asio] have the similar performance in this case
The throughput benchmark against muduo(中文) : evpp and muduo have the similar performance in this case
报告中的图表是使用[gochart]绘制的。
非常感谢您的阅读。如果您有任何疑问,请随时在issue跟我们讨论。谢谢。