

This repo is NOT supported since Fall 2016. It is not recommended using it for real life projects. I keep this repo here rather for historical purposes.
The package contains scikit-learn to TMVA convertor called skTMVA. The idea is to save scikit-learn BDT model to the TMVA xml-file. This allows you to use scikit-learn model directly from TMVA. Once the model is trained and converted, scikit-learn library is not needed anymore! The classification task can be performed with TMVA/ROOT only. This is particularly useful within ATLAS framework where there is no scikit-learn installed. A user can train the classifier with scikit-learn on his laptop and later use in ATLAS framework converted to the TMVA xml-file.
- ROOT (with TMVA package)
- NumPy
- scikit-learn
Basically just add koza4ok root directory to your PYTHONPATH enviroment variable. Or you can do this,
> source setup_koza4ok.sh
To convert BDT to TMVA xml-file, use the following method in your python code (see Examples),
convert_bdt_sklearn_tmva(bdt, [('var1', 'F'), ('var2', 'F')], 'bdt_sklearn_to_tmva_example.xml')where
bdtis your scikit-learn trained model,'[('var1', 'F'), ('var2', 'F')]'is the input variable description for TMVA. It consists of variable names and their basic types (e.g.'F'is for float). Please note, that the ordering here must be the same as the order of columns in your numpy array,bdt_sklearn_to_tmva_example.xmlis the output TMVA xml-file
Supports: AdaBoost or Gradient Boosting decision trees for binary classification.
In terms of High-Energy Physics jargon, AdaBoost or Gradient Boosting BDTs for signal and background discrimination.
You can play with our example. No input dataset is needed. The dataset is generated on-fly - both signal and background follow Gaussian distribution with different mean values (thanks to root_numpy, I steal this part of the code from them).
The example is devided in two pieces,
-
Training and converting
Depending on the type of boosting you prefer more, there are two scripts to test. Both of these train BDT with sklearn, then save it to TMVA xml-file and to a pickle file for scikit-learn,
- examples/bdt_sklearn_to_tmva_AdaBoost.py - AdaBoost
- examples/bdt_sklearn_to_tmva_Grad.py - Gradient Boosting
-
Validation
After the previous step, it's critical to insure that scikit-learn and TMVA give you the same classification predictions on a test dataset. The following script performs the converter validation,
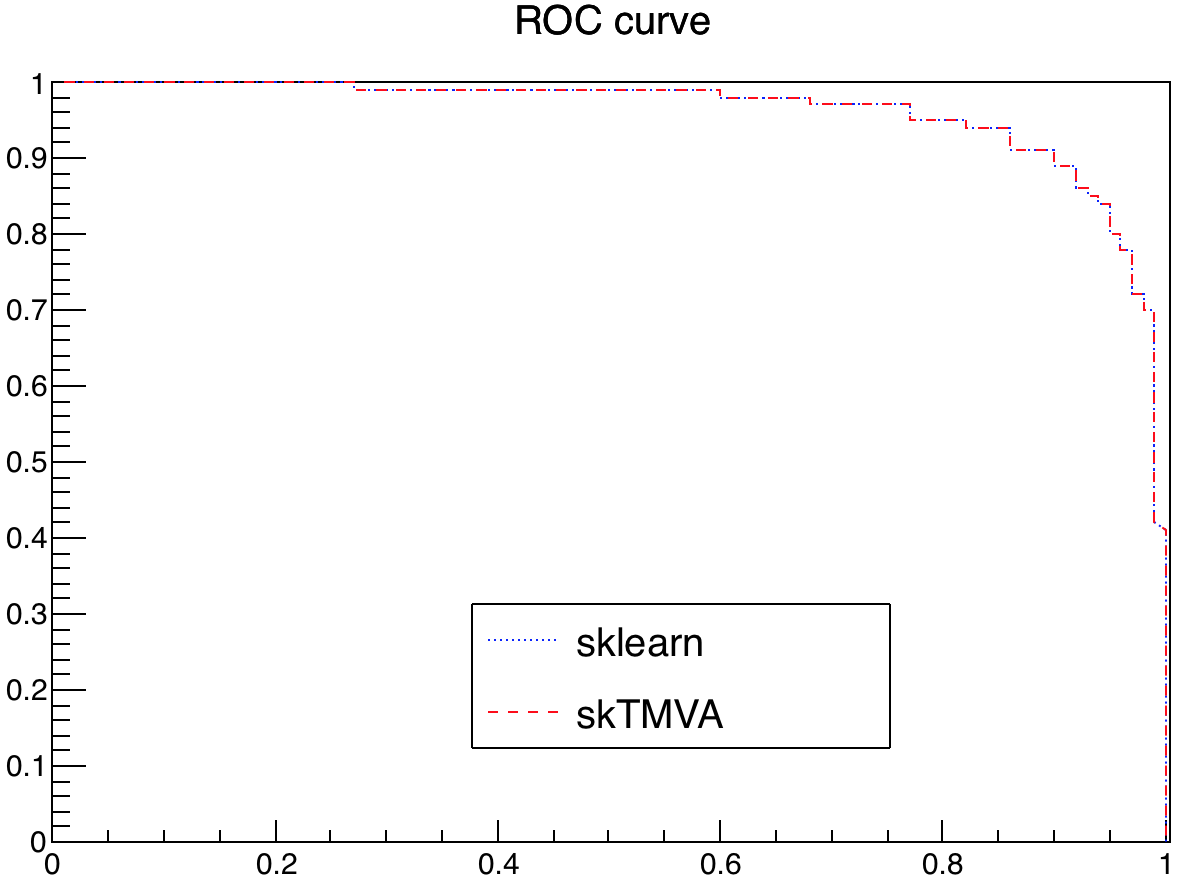
- examples/validate_sklearn_to_tmva.py - build two ROC-curves: one from sklearn by extracting BDT from pickle file and another from TMVA by using the reader on the input TMVA xml file from previous stage
To run the example, in the command line change directory to examples folder, and run
AdaBoost:
> python bdt_sklearn_to_tmva_AdaBoost.py
> python -i validate_sklearn_to_tmva.pyGradient Boosting:
> python bdt_sklearn_to_tmva_Grad.py
> python -i validate_sklearn_to_tmva.pyYou should notice two files created - bdt_sklearn_to_tmva_example.pkl and bdt_sklearn_to_tmva_example.xml - the first one contains trained BDT model whereas the second one is TMVA xml-file. validate_sklearn_to_tmva.py uses these two files to produce and compare two ROC-curves that are produced by scikit-learn and TMVA correspondingly. Ideally, the ROC-curves should be drawn one on top of another. The pop-up window will show up with the ROC-curve comparison.
For any question, suggestion or comment, please don't hesitate to contact me - https://web2.ph.utexas.edu/~ilchenko/index.html