You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
@@ -53,7 +53,6 @@ For this grant application, we are developing a decentralized task verification
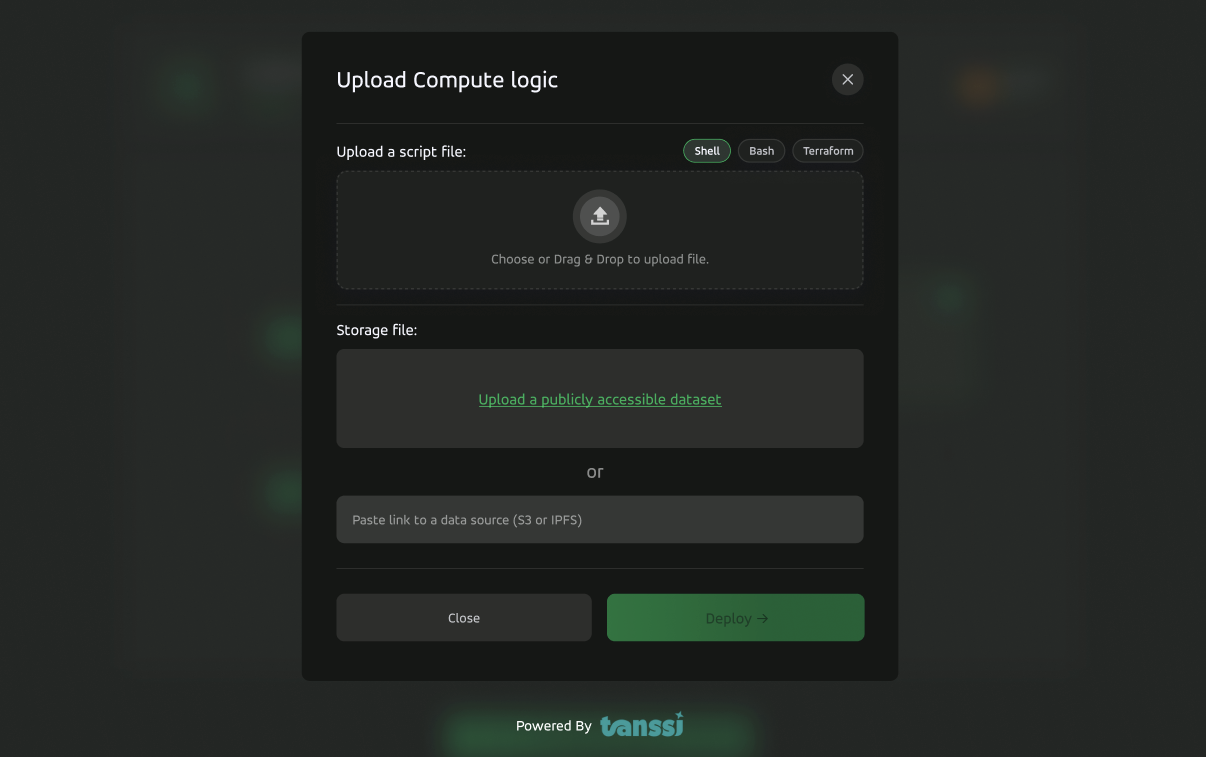
The objective is to upload a Docker configuration file and deploy the container inside one of the worker nodes of the K3s cluster. Before deploying the user's Docker image, the system will run a simulation to check for compilation failures or any startup runtime issues. If there are none, we will then proceed with the deployment.
Deployment will follow this pattern: The system will submit the job to 'N' clusters, with 'N' being selectable by the user. However, we will set a minimum value for 'N' to ensure a baseline of accuracy and high fault tolerance. Users can increase the value of 'N' if they desire greater accuracy and fault tolerance. Among the chosen 'N' clusters, 40-50% will be highly trusted nodes, with the remainder being general/new nodes. This strategy ensures that customers receive a valid output. Despite this, the executed computation results will be pushed to the Oracle, which will then feed it to the Cyborg substrate chain. Subsequently, if the baseline accuracy is achieved, the result will be added to the block, and if the output does not match or there are deployment failures, the system will attempt to re-execute the job from the beginning, with a maximum of 'X' retries. The value of 'X' will be adjusted based on the cost calculations for each execution, which are yet to be determined. If the job continues to fail even after 'X' retries, the system will notify the user of the failure by providing detailed logs and request them to assess the reason for the failure. In case of deployment failures, we will assess whether the issue is due to missed edge cases, configuration issues, network instability, or hardware limitations. Based on this assessment, the system will reassign the job to different workers