-
Notifications
You must be signed in to change notification settings - Fork 2.1k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Hyperdot - Powerful data analysis and creations platform — RFP (#1815)
* add hyperdot rfc * fix: milestone compatibility and delivery shared dashboards * update: changed somethings in the rfc --------- Co-authored-by: alloctor <[email protected]>
- Loading branch information
Showing
1 changed file
with
192 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,192 @@ | ||
| # Hyperdot - Powerful data analysis and creation platform — RFP | ||
|
|
||
| - **Team Name:** Infra3 | ||
| - **Payment Address:** [0xDc2c1814639f113C6EB51b3D8d871372Da9e116A](https://etherscan.io/address/0xDc2c1814639f113C6EB51b3D8d871372Da9e116A) (Ethereum ERC20 USDC) | ||
| - **[Level](https://github.com/w3f/Grants-Program/tree/master#level_slider-levels):** 2 | ||
|
|
||
| ## Project Overview 📄 | ||
|
|
||
| This is a response for the [Analytics Website/Data Platform](https://github.com/w3f/Grants-Program/blob/master/docs/RFPs/Open/analysis-website-and-data-platform.md) RFP. | ||
|
|
||
| ### Overview | ||
|
|
||
| Crypto data is growing rapidly, and large data companies are not consider integrating them into their systems. However, multi-chain crypto data is of significant value to users. The hyperdot is a on-chain data platform for querying, analyzing, and creations, written in Rust. It provides users with powerful capabilities for data querying, analysis, and creations. | ||
|
|
||
| With hyperdot, users can easily query and analyze crypto data from **Polkadot**, **Kusama**, and other **parallel chains built on the Substrate Runtime**. Hyperdot separates the indexing and computation of on-chain crypto data from the off-chain data storage, analysis, and querying, addressing scalability issues present in many data analysis platforms. Hyperdot offers multiple data engines to adapt to different scenarios. | ||
|
|
||
| Hyperdot provides a dashboard similar to [Dune Analytics](https://dune.com/browse/dashboards) and [Chainbase](https://chainbase.com/), offering powerful data analysis and visualization features currently. Users can create queries using different data engines and generate visual data dashboards. Importantly, Hyperdot is dedicated to building a data analysis creations community where data engineers and data scientists can create and share their work based on Hyperdot's data, fostering collaboration and knowledge exchange. | ||
|
|
||
|
|
||
| ### Project Details | ||
|
|
||
|
|
||
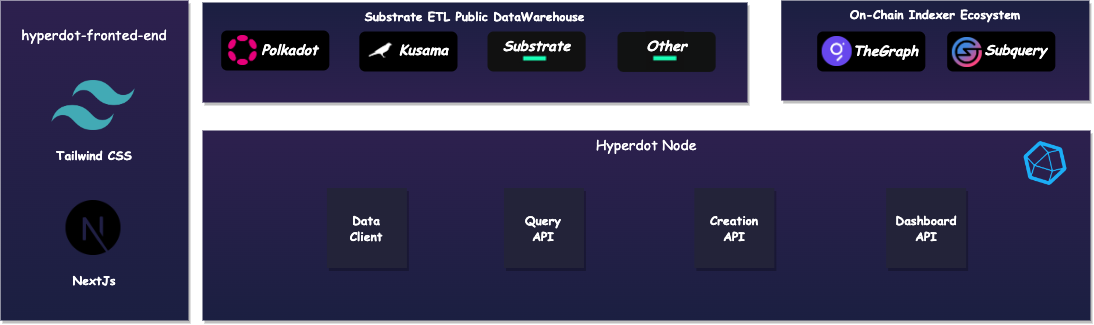
| #### The System Overview | ||
|
|
||
| The Hyperdot project consists of two main system: hyperdot-node and hyperdot-frontend-end. | ||
|
|
||
| hyperdot-Node will ideally integrate the data source of [substrate-etl](https://github.com/colorfulnotion/substrate-etl) to provide an crypto-data query api on the chain | ||
|
|
||
| hyperdot-frontend-end is built using [tailwind css](https://tailwindcss.com/) and [next.js](https://nextjs.org/), creating a modern web dashboard. While it works similar to Dune Analytics, it has its own unique features. Hyperdot-Frontend connects to Hyperdot-Node to provide users with user-friendly chain data analysis capabilities. Moreover, it aims to establish a data analysis community where data engineers and data scientists can create and share insights based on the data provided by Hyperdot. | ||
|
|
||
| #### The System Architecutre | ||
|
|
||
| Hyperdot will consider the success of the existing work of the integration community, for example, on the data source, we will choose to integrate [substrate-etl](https://github.com/colorfulnotion/substrate-etl) as the data of hyperdot-node-front engine, at the same time, in order to maintain good scalability, hyperdot-node will also retain other options. | ||
|
|
||
|
|
||
|  | ||
|
|
||
| The system is mainly divided into three parts | ||
| 1. substrate-etl provides the relevant data warehouse, other ecosystems allow us to customize the index, and we will integrate their data as the data source of the system on demand | ||
| 2. hyperdot-Node will integrate data from common bins provided by substrate etl and provide apis for hyperdot-front-end | ||
| 3. hyperdot-fronted-end provides a user-friendly front-end interface for data analysis, exploration, and collaborative data analysis creation. It is built using modern front-end technologies. The interaction between hyperdot-fronted-end and hyperdot primarily utilizes HTTP, while GraphQL is used for handling complex data queries. WebSockets are employed for subscription-based data updates. | ||
|
|
||
| #### The Live Demo | ||
|
|
||
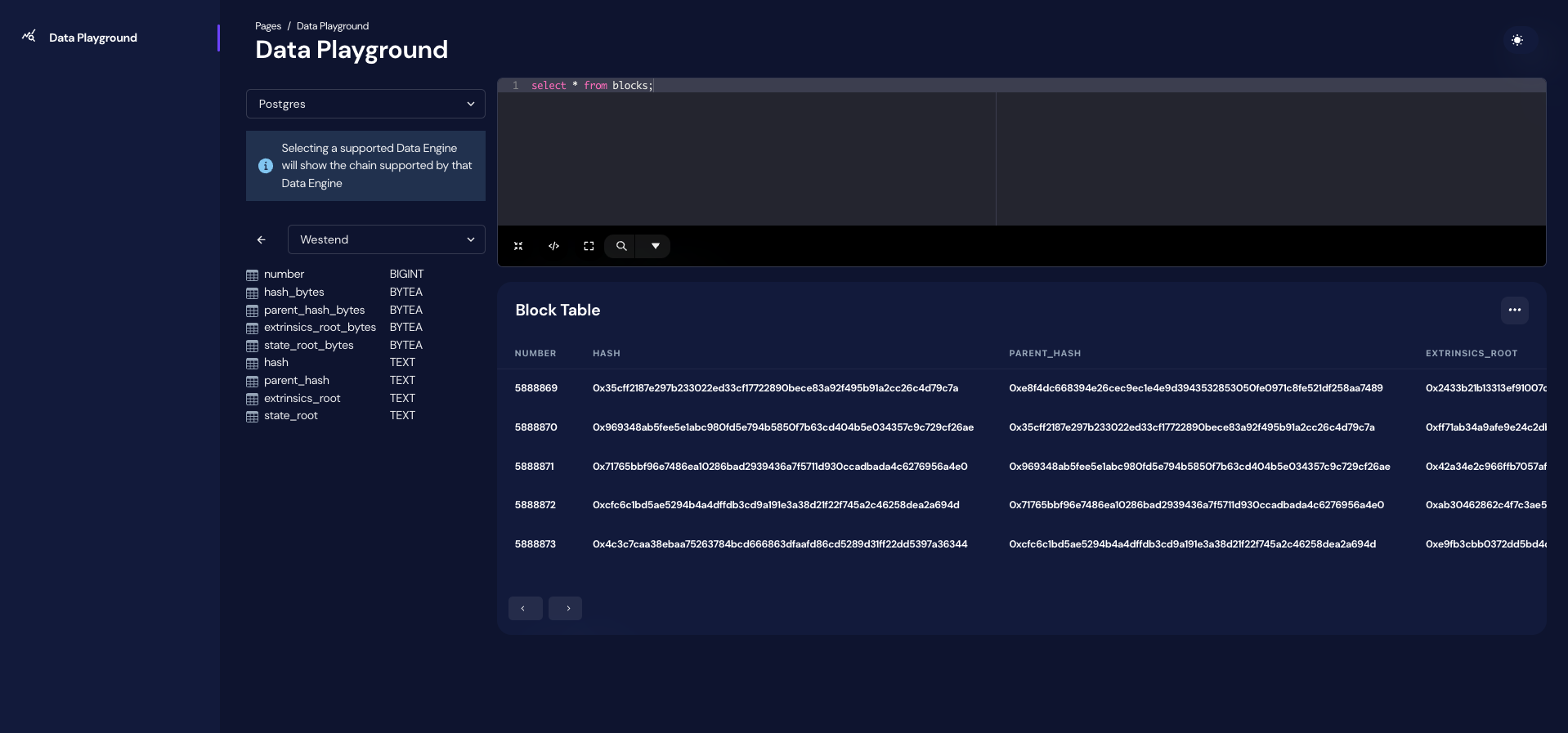
| We have deployed a small [live demo](https://playground.infra-3.xyz/) that you can play directly with. | ||
|
|
||
| Querying westend testnet block data | ||
|
|
||
|  | ||
|
|
||
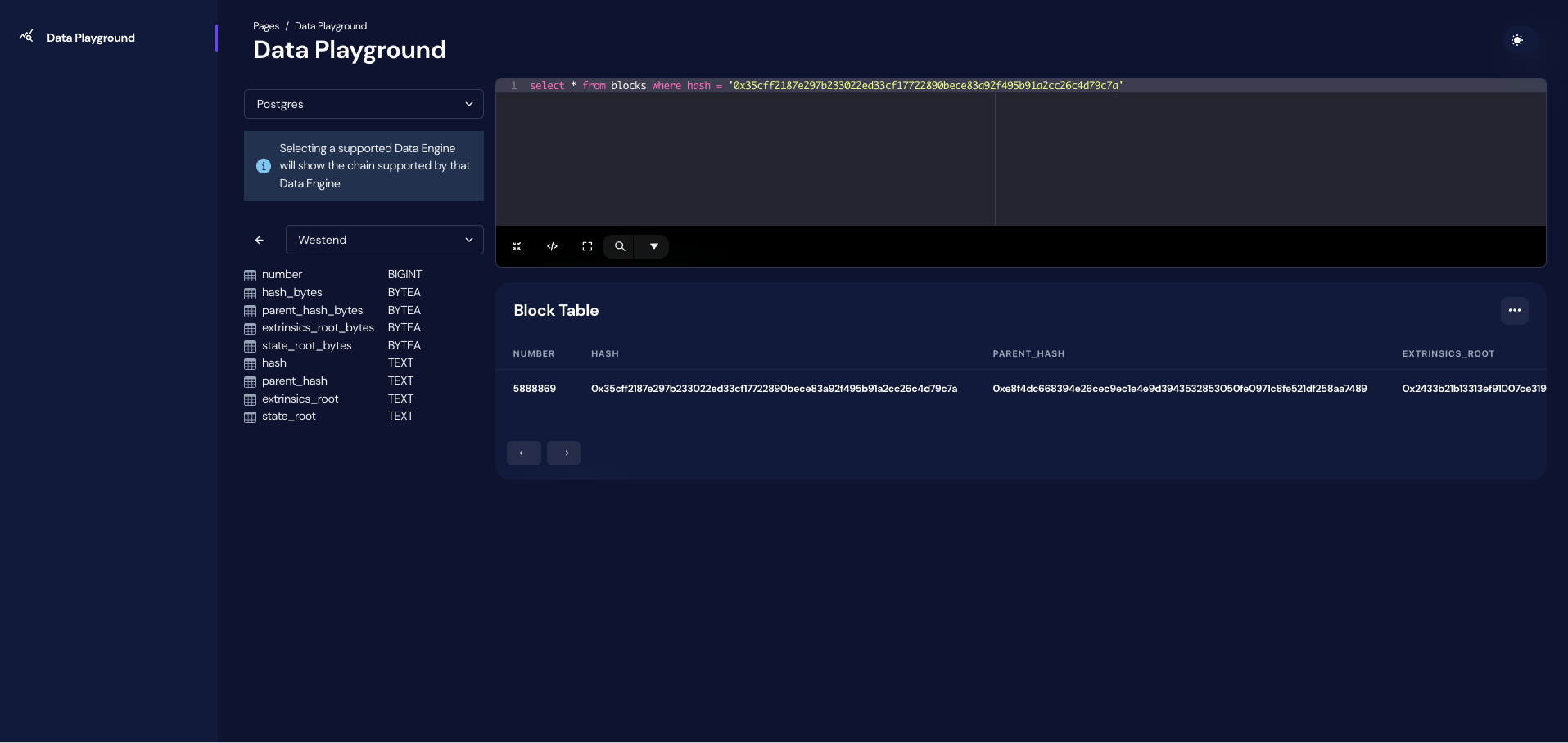
| Querying the westend block data uses the index | ||
|
|
||
|  | ||
|
|
||
| ### Ecosystem Fit | ||
|
|
||
| hyperdot will integrate data from Polkadot, Kusama, and Substrate networks by utilizing the infrastructure of substrate, substrate-etl, and other Parity technology communities. It will support multi-chain and multi-runtime environments. hyperdot will provide a dashboard that enables users to easily query on-chain crypto data using SQL language. Additionally, it will establish a community for data querying, analysis, creation, and sharing, allowing users to exchange insights. | ||
|
|
||
| hyperdot is a data querying, analysis, creation, and sharing platform targeting a wide range of users, including data analysts, data scientists, project managers, and anyone interested in analyzing on-chain crypto data using hyperdot. | ||
|
|
||
| Currently, we have not found similar projects in the Substrate/Polkadot/Kusama ecosystems. Moreover, data analysis systems that support multi-chain, multi-data engine integration with good scalability are rare in other ecosystems as well. We firmly believe that hyperdot will bring significant value to the community. | ||
|
|
||
|
|
||
|
|
||
| ### QA | ||
|
|
||
| **Q:** Come up with a value proposition to make it viable: "how would the project stay sustainable and capture value?" to sustain operating costs | ||
|
|
||
| **A:** | ||
|
|
||
| - **Sustainability:** First, technically, we have a team with a good web3 background, so we don't get stuck with technical issues. Second, we were able to reduce our storage costs by relying on other projects' data warehouses, which allowed our projects to grow healthier. | ||
|
|
||
| - **Capture value:** We believe that the ecosystem needs a "dune for substrate, but better" project that enables more powerful analytics for all users. | ||
|
|
||
| **Q:** Interview a few parachains/ecosystem teams & researchers on the top 3 "dashboards" or interactive data use cases they'd like to see and include how you would solve that as part of the analysis and data platform RFP. | ||
|
|
||
| **A:** We can't give a precise answer to this question, but we did a deep dive last week into existing data analytics projects in the ecosystem and, similarly, they always present data that users expect on top3. hyperdot is a little different, | ||
|
|
||
| 1. hyperdot allows anyone to create analytics dashboards using data provided by the substrate-etl repository, so the top3 ranking is not actually controlled by hyperdot | ||
| 2. However, we provide a favorites ranking for each dashboard, which can accurately show which data analytics dashboards are widely used by the community based on favorites | ||
|
|
||
|
|
||
|
|
||
| ## Team | ||
|
|
||
| ### Team members | ||
|
|
||
| - **Ryan Xiao** | ||
|
|
||
| - **Ming Dai** | ||
|
|
||
| - **Tania** | ||
|
|
||
|
|
||
| ### Contact | ||
| - **Contact Name:** Tania | ||
| - **Contact Email:** [email protected] | ||
| - **Website:** https://network.infra-3.xyz | ||
|
|
||
| ### Legal Structure | ||
|
|
||
| - **Registered Address:** N/A | ||
| - **Registered Legal Entity:** N/A | ||
|
|
||
| ### Team's experience | ||
|
|
||
| **Ryan Xiao** is a contributor to the Tendermint-rs and Postgres communities and. With nearly 10 years of software development experience, Ryan Xiao is an expert in Rust and C++ programming languages. He specializes in decentralized systems, large-scale distributed data systems, and cloud computing system development. Ryan Xiao has been involved in the development of the Tendermint-rs community and decentralized data systems based on Tendermint-rs and Postgres FDW. He has also contributed to multiple research-oriented databases at CMU, showcasing a deep understanding of databases. Ryan Xiao has conducted extensive research on Web3 consensus protocols and the Substrate framework, published several articles on Substrate development, and organized related presentations. He has been dedicated to helping more technologists become familiar with and understand Web3 development through Substrate. | ||
|
|
||
| **Ming Dai** has been working in decentralized exchanges for the past few years, focusing on data security. He has a strong passion for Rust and Substrate and has conducted extensive research on Substrate pallet and runtime development, backed by rich practical experience. Ming Dai has studied the design and implementation of Dune and has implemented a data analysis system for the company based on Ethereum's chain. Additionally, Ming Dai is familiar with smart contracts, dApps, frontend design, and developm | ||
|
|
||
| **Tania** has been involved in security audits and operational work at exchanges. She is also an excellent UI designer, dApp creator, and technical document writer. Tania has a deep love for Substrate and ink! and has been exploring the use of ink! to refactor previous smart contracts. | ||
|
|
||
| ### Team Code Repos | ||
|
|
||
| - https://github.com/Infra3-Network/hyperdot | ||
| - https://github.com/Infra3-Network/hyperdot-fronted-end | ||
| - https://github.com/Infra3-Network/hyperdot-data-playground | ||
|
|
||
| Please also provide the GitHub accounts of all team members. If they contain no activity, references to projects hosted elsewhere or live are also fine. | ||
|
|
||
| - https://github.com/pidb | ||
| - https://github.com/bytesleak | ||
| - https://github.com/cattania | ||
|
|
||
|
|
||
| ## Development Status 📖 | ||
|
|
||
| In 2022, Ryan started exploring Substrate and The Graph, and at that time, he attempted to add support for Substrate data on The Graph for private chains. This effort lasted for approximately six months. | ||
|
|
||
| Starting from March of this year, Ryan and Ming were inspired by Dune and Chainbase, and they thoroughly studied the architecture design and implementation of these projects. Subsequently, we discussed the feasibility of building a multi-chain, multi-runtime, multi-data engine, scalable platform for web3 data analysis, creation, and a community of web3 data enthusiasts. | ||
|
|
||
| We began designing and implementing Hyperdot, with Tania providing us with a simple data playground. Currently, we have achieved an MVP (Minimum Viable Product) validation of the core components, and they are functioning well. It is estimated that it will take another three months to make them work properly. Therefore, now is the time to apply for a W3F grant and introduce the work we have done to the entire Substrate community. | ||
|
|
||
| ## Development Roadmap 🔩 | ||
|
|
||
| ### Overview | ||
| - Total Estimated Duration: 3 months | ||
| - Full-Time Equivalent (FTE): 3 FTEs | ||
| - Total Costs: 19,000 USD | ||
|
|
||
|
|
||
| ### Milestone 1 — Completion of all components and core functionalities of hyperdot-node | ||
| - **Estimated duration:** 5 weeks | ||
| - **FTE:** 3 | ||
| - **Costs:** 9,000 USD | ||
|
|
||
| | Number | Deliverable | Specification | | ||
| | ------: | ------------------------- | ------------------------------------------------------------ | | ||
| | **0a.** | License | Apache 2.0 | | ||
| | **0b.** | Documentation | We will provide both **inline documentation** of the code and a basic **tutorial** that explains how a user can (for example) spin up one of our Substrate nodes and send test transactions, which will show how the new functionality works. | | ||
| | **0c.** | Testing and Testing Guide | Core functions will be fully covered by comprehensive unit tests to ensure functionality and robustness. In the guide, we will describe how to run these tests. | | ||
| | **0d.** | Docker | We will provide a Dockerfile(s) that can be used to test all the functionality delivered with this milestone. | | ||
| | **0e.** | Article | We will publish an **article**/workshop that explains [...] (what was done/achieved as part of the grant). (Content, language and medium should reflect your target audience described above.) | | ||
| | **1.** | SQL Query API | We will use the bigquery client to integrate substrate-etl from the data sources provided by substrate-etl and creating a data query api using the bigquery client and substrate-etl, including<br/><br />1. We will integrate the table schema provided by substrate etl to create interfaces for different query capabilities we provide, such as chain information, transaction information, etc.<br />2. Show the table-scheme of the associated chain<br/>3. Run and save sql queries | | ||
| | **2.** | Dashboard Editor | The apis needed to implement the dashboard, including<br/>1. Edit the visualization dashboard page by loading sql<br/>2. Save the dashboard you've edited | | ||
| | **3.** | Discovery | We will implement the apis required by the discovery feature for data analytics dashboards and data query sharing, including<br/>1. The dashboards list api<br/>2. dashboards item Detail api. Each dashboard item is clicked to show the user's previously edited dashboard<br/>3. queries List api<br/>4. queries item details api. After clicking each query item, it displays the sql data tables and other information that the user has saved and run before | | ||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
| ### Milestone 2 — Completion of all components and core functionalities of hyperdot-fronted-end | ||
| - Estimated duration: 7 weeks | ||
| - FTE: 3 | ||
| - Costs: 10,000 USD | ||
|
|
||
| | Number | Deliverable | Specification | | ||
| | ------: | ------------------------------ | ------------------------------------------------------------ | | ||
| | **0a.** | License | Apache 2.0 | | ||
| | **0b.** | Documentation | We will provide both **inline documentation** of the code and a basic **tutorial** that explains how a user can (for example) spin up one of our Substrate nodes and send test transactions, which will show how the new functionality works. | | ||
| | **0c.** | Testing and Testing Guide | Core functions will be fully covered by comprehensive unit tests to ensure functionality and robustness. In the guide, we will describe how to run these tests. | | ||
| | **0d.** | Docker | We will provide a Dockerfile(s) that can be used to test all the functionality delivered with this milestone. | | ||
| | **0e.** | Article | We will publish an **article**/workshop that explains [...] (what was done/achieved as part of the grant). (Content, language and medium should reflect your target audience described above.) | | ||
| | **1.** | Page Layout | We will provide the basic layout, which will <br />1. A basic header navigation and routing <br />2. Dashboard, Queries | | ||
| | **2.** | Data Creation - New Query Page | We will provide data analysis querying and creation on the Data Creation Page, and an interactive data analysis querying experience on the New Query Page:<br/><br/>1. New Query Page: This page will display the supported data engines and the associated tables for each engine.<br/>2. Playground Editor: Users will be able to input SQL queries in an interactive manner using the Playground Editor.<br/>3. Dynamic Table: The results of data analysis will be presented using a dynamic table.<br/>4. Visual Chat: We will incorporate a visual chat feature to enhance the objectivity of the data.<br/>5. Save and tag created data queries: Users will have the ability to save their created data queries and add tags to them. | | ||
| | **3.** | Data Creation - New Dashboard | New Dashboard allows users to create shareable dashboards that it will<br/>1. Create a Dashboard form<br/>2. Visualize the Query created by the user in the New Query Page | | ||
| | **4.** | Discovery - Queries | The Discovery Queries section will showcase data analysis queries created by users in the community. Each creation can be clicked to access the details, where the Playground Editor will explain the SQL syntax and display relevant visualized data tables. | | ||
| | **5.** | Discovery - Dashboards | The Discovery Dashboards section will show shared visual dashboards created by users in the community. You can click on each creation to access the details, and once inside you can load a dynamic dashboard based on your query. | | ||
|
|
||
|
|
||
| ## Future Plans | ||
|
|
||
| After completing hyperdot and releasing the first version, we will integrate more data engines, including time series data engines (influxdb), OLAP analytics engines (Clickhouse), and distributed query engines (Spark). | ||
|
|
||
| We will consider indexing more types of data, not just raw chain data, but also decoded dex and not data, as well as additional extrinsic data. Additionally, we plan to establish a mechanism where developers can propose data models they want to index through GitHub or the community. Once adopted, these data models will be incorporated into our data engines. | ||
|
|
||
| We will also consider **integrating ChatGPT to provide natural language querying capabilities (we are think it's something that's going to get the whole community excited about)**. Specifically, users will no longer need to be proficient in SQL and can run queries using natural language prompts. | ||
|
|
||
| We will introduce a P2P structure for storage nodes to make them decentralized. We also plan to optimize and upgrade the UI based on user feedback, such as adding more dashboards and improving the data creation process. Additionally, we will explore integrating Grafana for better data visualization dashboards. | ||
|
|
||
| Lastly, we expect to collaborate with foundations to promote our platform and showcase its value to more users. We will also engage with the community through platforms such as Twitter, YouTube, Medium, and others to introduce hyperdot. | ||
|
|