SS2019: Technologierecherche – Kommunikation: GraphQL Grundlagen
Diese Technologierecherche steht in starkem Bezug zu einem Projekt namens "Projekt Q", welches im Rahmen des Studien-Moduls "Projekt 2: Entwicklung" entsteht. Das Projekt befasst sich mit folgender Problematik:
Zahlreiche landwirtschaftliche Betriebe der Region sind in der Lage, marktfähige, regionale Produkte in großer Vielfalt herzustellen. Allerdings verfügen Sie weder über den Marktzugang noch über die Voraussetzungen, diesen ggf. erfolgreich zu gestalten ... Abhilfe soll daher ein tagesaktuelles, ständig wechselndes Frischesortiment auch für den Privatkonsumenten und anderen gewerblichen Abnehmern wie Gastronomie und Caterern eingeführt werden. Dieses soll online verfügbar stehen, worin a) Landwirtschaftliche Erzeuger Ihre Produkte und Produktüberhänge einer breiten Öffentlichkeit anbieten und direkt vermarkten können und/oder b) diese über die bereits vorhandene Logistik und angefahrene Routen der Bergisch Pur Vertriebsgesellschaft zu verwalten, fakturieren und auszuliefern um hof-ferne Verbraucher erreichen zu können.
Für den Technologiestack dieser Anwendung wurde GraphQL als fester Bestandteil gesetzt, sowie die Architektur in Form von Microservices angestrebt. Da die Teammitglieder jedoch noch nicht mit GraphQL gearbeitet haben, soll diese Recherche nun als Einstieg in die Technologie gelten, sowie Möglichkeiten der Implementierung von Microservices mit GraphQL aufzeigen.
- Heutige Anwendungen nicht ganz Stateless. Session in irgendeiner Art vorhanden.
- Keine unterschiedlichen Repräsentationen vorhanden (oft nur XML und/oder JSON)
- HATEOAS - nicht wirklich in Verwendung - man muss sich auf eine Semantik einigen
- Die meisten Schnittstellen im Web sind nur REST-like
- "Endpoint-Hell" mit N*M Endpoints (N = Anzahl der Entitäten, M = CRUD Operationen)
- Unterschiedliche Endpoints werden benötigt (starke Spezialisierung)
- " Tatsächliche REST-Konformität würde heutige Front-End-Anwendungen erzwingen, wie SAP-Anwendungen aus dem Jahr 2000 auszusehen."
Quelle: Working Draft - REST vs. GraphQL
Die ständige Weiterentwicklung von Web-Service-Technologien und Entwicklung von neuen, speziellen Anwendungsfällen entstand der Bedarf für einen neuen API-Ansatz. Facebook entwickelte also im Jahr 2012 aufgrund der Schwächen der bestehenden Architekturstile, wie REST und WSDL, und den derzeitigen Anforderungen GraphQL.
GraphQL ist eine Abfragesprache für APIs und eine serverseitige Laufzeitumgebung für die Ausführung von Abfragen unter Verwendung eines Typsystems, welches für die abgefragten Daten definiert ist.Serverseitig wird hierbei eine Schnittstelle erstellt, welche Datenstrukturen, sowie mögliche Operationen für Clients bereitstellt, welche nun über HTTP-Requests erreichbar sind.

GraphQL-Schnittstellen unterliegen hierbei folgenden Design-Prinzipien (Quelle: GraphQL-Spezifikation Overview (Juni 2018)):
-
Eine GraphQL-Schnittstelle ist hierarchisch aufgebaut. Datenstrukturen sind verschachtelt um ihre Zusammenhänge aufzuzeigen und logische Verknüpfungen herzustellen (im JSON-Format). Auch die Abfrage eines Clients ist dementsprechend hierarchisch aufgebaut, wodurch eine natürliche Datenüberführung erreicht werden soll.
-
Durch GraphQL soll eine produktzentrierte Herangehensweise ermöglicht werden. Der Aufbau einer Datenstruktur beginnt hier bei den Anforderungen des Front-Ends. Zudem sind diese Datenstrukturen stets auf neue Anforderungen überführbar.
-
Eine GraphQL-Schnittstelle ist stark typisiert. Es wird ein Kontext abhängiges Typensystem geschaffen, auf welches innerhalb von Requests zugegriffen werden kann. Dieses Typensystem gilt als Rahmenwerk der Interaktion, wodurch Requests schon vor der Ausführung auf ihre syntaktische Korrektheit und Validität geprüft werden können. Somit sind server- als auch clientseitig wenig bis keine Typ-Überprüfungen notwendig.
-
Bei einer Anfrage spezifiziert der Client selbst, welche Daten bzw. Attribute er von Entitäten / Ressourcen haben möchte (solange diese in den, vom Server vorgegebenen, Möglichkeiten liegen). Hierbei wird vom Client jeder Key angegeben, dessen Value er haben möchte. Als Rückgabe erhält er nun exakt diese Daten. Durch die Schachtelung der Datenstrukturen wird so eine minimale Anzahl von Anfragen benötigt, deren Datenmenge auf das minimal benötigte reduziert ist.
-
GraphQL ist introspektiv und das Typensystem eines Servers somit durchsuchbar. Hierdurch sind unterstützende Werkzeuge erstellbar, welche mit allen GraphQL-Schnittstellen interagieren können.
Das Typsystem der Schnittstelle beschreibt und definiert in GraphQL die Fähigkeiten einer API. Die Typen, welche über die API verfügbar gemacht werden, sind als Schema in der GraphQL (SDL) Schema Definition Language beschrieben. Das Schema dient als Contract zwischen Client und Server, um zu beschreiben wie ein Client Daten abrufen kann. Das Schema ermöglicht also eine unabhängige Arbeit am Client und Server, da der Austausch von Datenstrukturen bekannt ist. Frontend-Teams können mithilfe der SDL ihre Anwendungen einfach testen, indem sie die erforderlichen Datenstrukturen nachahmen. Sobald der Server bereit ist, können die Clients diesen nun als richtige Datenquelle nutzen.
Quelle: GraphQL vs REST - A comparison
type Product {
id: ID!
title: String!
description: String!
imageUrl: String
ratings: [Rating]!
averageRatingScore: Float
}
type Customer {
id: ID!
name: String!
ratings: [Rating]!
}
type Rating {
id: ID!
product: Product!
customer: Customer!
score: Int!
comment: String!
}
type Query {
getProduct(productId: ID!) : Product
}
type Mutation {
rateProduct(productId: ID!, customerId: ID!, score: Int!, comment: String!) : Rating!
}
Beispiel eines GraphQL-Schemas für einen Webshop
Quelle: Einführung in GraphQL - JAXEnter
GraphQL ist zudem nicht an eine bestimmte Art von Datenbanken oder anderen Speicher gekoppelt. Zu jedem Typen und jedem Attribut dieser Typen muss Serverseitig ein entsprechender Resolver geschaffen werden. Ein Resolver ist hierbei eine Funktion, welche bei einer Abfrage dieses Typen / Attributes entsprechende Daten beschafft und bereitstellt.
Anders als bei REST-Architekturen stellen GraphQL-Server lediglich einen Endpunkt zur verfügung, über welchen alle Abfragen statt finden. Zugriffe werden somit nicht über die URL, sondern den Body eines Requests definiert und finden somit stets in Form eines HTTP-POSTs statt (egal ob Daten angefragt oder verändert werden sollen). Auch der Statuscode unterscheidet sich nicht. Hier wird stets der Code 200 zurück gegeben, egal ob der Zugriff erfolgreich war, oder nicht (außer die Anfrage war syntaktisch nicht korrekt, dann der Statuscode 404).
Allgemein ist GraphQL vor allem auf die Web-Welt zugeschnitten. Gerade Projekte mit großen und verzweigten Datenstrukturen, sowie sich schnell ändernde Projekte profitieren von der hierarchischen und flexiblen Arbeitsweise.
-
Hierarchische Aufbau der Datenstrukturen reduziert die Anzahl der Zugriffe auf ein Minimum
-
Zugriffe sind sehr flexibel, wodurch eine lose Kopplung zwischen Client und Server erreicht wird. Somit kann eine große Anzahl von unterschiedlichen Clients mit der selben Schnittstelle abgedeckt werden
-
Fördert die Entwicklung gegen Schnittstellen. Front-End und Back-End können parallel arbeiten und müssen nicht stetig in Kontakt stehen um Anpassungen vorzunehmen. So werden schnelle und unabhängige Produkt-Iterationen ermöglicht
-
Clients können die erfragte Datenmenge reduzieren und nur die von ihnen benötigten Attribute anfragen (z.B. gut für mobile traffic). Die Kommunikation von Geräten mit schwankender oder schlechter Netzwerkanbindung wird somit ebenfalls stabiler
-
Erhöhung der Geschwindigkeit durch Reduzierung der Datenmengen und Anzahl von Abfragen
-
Schnittstellen bzw. Datenstrukturen können einfach erweitert werden, ohne die Funktionalität von Clients zu beeinflussen
-
Durch die introspektive können Werkzeuge geschaffen werden, welche auch Projektübergreifend nutzbar sind (z.B. Autovervollständigung, Schema-Prüfung, Static documentation etc.)
-
Die Typisierung reduziert den benötigten Code für Validierungen (gerade in einer untypisierten Sprache wie Javascript) und ermöglicht die syntaktische Überprüfung von Anfragen schon vor der Ausführung
-
Typen können in unterschiedlichen Datenstrukturen wiederverwendet / referenziert werden, wodurch eine Reduktion des Codes entsteht
-
Übersichtlichere Schnittstelle sowie Abfragen, da eine Abfrage die selbe Form wie die gewünschte Datenstruktur besitzt
-
Die Schnittstellen verschiedener Microservices können einfach in ein API-Gateway zusammengefasst werden
-
Einfache Überführung bestehender Architekturen auf GraphQL
-
Besseres Logging und genauere Interpretation der angeforderten Daten, da Nutzer genau angeben, was sie benötigen. Anhand dieser Informationen kann die Schnittstelle und der gesamte Server optimiert werden (z.B. bei Zugriffen auf bestimmte Ressourcen mehr Rechenleistung einplanen)
-
Automatische caches reagieren meist nur auf GET-Requests, sodass GraphQL hiervon nicht direkt profitiert (gerade browser- und mobile-caching)
-
Routing zu Microservices kann arbeitsintensiver sein (GraphQL-Query muss interpretiert und ggf. mit anderen Anfragen vereint werden, URL ist einfacher zu interpretieren / zerlegen)
-
Die Freiheit kann von Clients ausgenutzt werden, welche nun im schlimmsten Falle nahezu endlose Verschachtelungen in einen Request einbauen (soweit es die Datenstruktur erlaubt). Hier müssen spezielle Vorkehrungen getroffen werden
-
Die fehlende Varietät der Statuscodes nimmt Entwicklern ein entscheidendes Unterscheidungsmerkmal um auf Fehler zu reagieren. Hierdurch wird weitere Logik benötigt um Fehler zu kompensieren (clientseitig)
-
Viele Monitoring-Tools achten auf den Statuscode eines Response. Diese sind nun nicht mehr einsetzbar
-
GraphQL ist noch recht neu, wodurch die Auswahlmöglichkeiten zwischen Frameworks begrenzt sind
-
Undurchdachte GraphQL-Server können schnell unübersichtlich und überfüllt werden
-
Im Gegensatz zu REST ist GraphQL noch recht neu, wodurch die Akzeptanz und Verständlichkeit der API zunächst geringer ausfallen kann (jeder kennt REST und weiß wie es funktioniert)
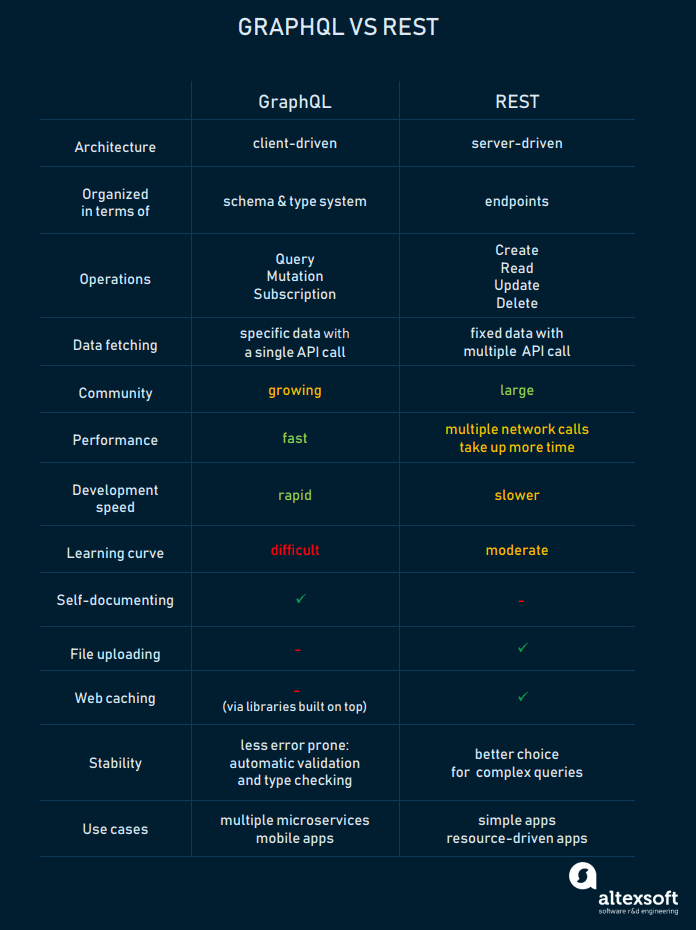
- Der Client spezifiziert, welche Eigenschaften einer Entität abgefragt werden / er benötigt (SQL-ähnlich). Hierbei greift er auf die von dem Server vorgegebene Schnittstelle und dessen Queries / Mutations zu, kann jedoch nicht benötigte Attribute und verschachtelte Objekte auslassen, um die Datenmenge auf das von ihm benötigte Minimum zu reduzieren.
- Der Client erstellt anhand der benötigten Anfragen und Attribute eine eigene, Kontext-spezifische Abfragesprache (ggf. sogar DSL), welche als Sub-Set des, vom Server, angebotenen Schemas gesehen werden kann.
Beispiel: Shopping Cart -> Items
- Desktop alle Produktinformationen
- Mobile eine Teilmenge (Bsp nur Titel, Bild und Preis)
- Der Server spezifiziert das Typsystem, also welche Entitäten vorhanden sind, wie diese zusammenhängen und wer auf diese zugreifen darf.
- Der Server stellt Resolver-Funktionen, welche die Logik hinter dem Schema darstellen (wie gelange ich an die angefragten Daten). Hierbei finden beispielsweise Zugriffe auf Datenbanken oder andere Services statt.
- Der Server interpretiert und dekonstruiert die Anfragen des Clients, um zu ermitteln, welche Daten von diesem benötigt / angefragt wurden (da eine Anfrage dynamisch vom Client auf dessen Bedürfnisse angepasst werden kann).
- Der Server stellt ermittelte Daten zu einem Objekt mit der vom Client angeforderten Struktur zusammen und übermittelt dieses an den Client.
[ Resolver implementieren. Bsp: Wie kommt man von Carts zu Items? (REST-Schnittstelle im Hintergrund - nur einen Endpoint mit einer GraphQL Library)
Backend einmal bauen Es muss nichts geändert werden, bei einem REST-Ansatz schon. Reduziert die Abstimmungsaufwände erheblich!
Eher untypisch mehrere Microservices direkt mit einem Client anzufragen (Gateway-Lösung) ]
REST-Schnittstellen vermeiden. An dieser Stelle eher GraphQL mit einer WebSocket/MessageQueue-Verbindung (als Broker) verwenden. Man formuliert per GraphQL die Query im Payload. Pro Service gibt es einen GraphQL-Endpoint.
Spezielle HTTP basierten Features und Authentifikation trotzdem auf REST-Endpoints auslagern.
Ausführliche Auflistung verschiedener Frameworks und Bibliotheken hier
Für aktuelle Informationen bezüglich GraphQL-Apollo lohnt sich stets ein Blick auf diese Seite
Für Mikroservices kann das Prinzip des Schema-Stitchings hilfreich sein (mithilfe von graphql-tools). Hierbei greift ein Gateway beim Startup auf die Schnittstellen aller zugehörigen Services zu und vereint diese (genauere Beschreibung siehe hier oder hier). Das Gateway ist weiterhin zuständig für die Erweiterung / Überarbeitung dieser Schemata. Innerhalb der einzelnen Services werden lediglich interne Typen verwendet und auf keine Typen anderer Services verwiesen (maximal durch Ids). Das Gateway übernimmt nun die Ergänzung / Komposition dieser Typen.
Beispiel: Wir haben einen User- und einen Produkt-Service. User können Produkte haben, jedoch wird dies noch nicht im Typensystem des User-Services vermerkt, da dieser Service nicht weiß, wie er an diese Produkte gelangen kann. Erst im Gateway wird diese Verbindung ergänzt (der User-Type mit einem Attribut products: [Product!] ergänzt), da dieses den Produkt-Service kennt und nun Anfragen für die Produkte eines Users an diesen Service weiterleiten kann, welcher nun anhand der UserID die entsprechenden Produkte ermittelt und liefert. Alternativ hätte auch der User-Service das Attribut products: [ID!] anbieten können, da er hierzu kein Wissen über den eigentlichen Produkt-Typen besitzen muss. Im Gateway wäre dann dieses Attribut überschrieben worden, um wirkliche Produkte zu bieten.
Eine Alternative zum Schema-Stitching findet sich in Apollo Federation, welches auf Architekturen mit unterschiedlichen Services ausgelegt ist. Federation basiert auf 4 Grundprinzipien (siehe hier):
- Building a graph should be declarative. Composing graphs declaratively in a schema replaces the need to stitch code imperatively.
- Code should be separated by concern, not by types. The definition of these types should be distributed across teams and codebases, rather than centralized.
- The graph should be simple for clients to consume. Federated services offers a product-focused graph that accurately reflects how it’s being consumed on the client.
- It’s just GraphQL, using only spec-compliant features of the language. Any language can implement federation.
Federation ist aufgeteilt in zwei eigenständige Apollo Server add-ons.
- @apollo/federation: Ergänzt die SDL um Primitive, welche für Kompositionen von GraphQL-Schemas genutzt werden können (Typen eines anderen Services können referenziert und ergänzt werden).
- @apollo/gateway: Für die Erstellung eines Gateways, welches die Typ-Kompositionen konstruiert und deren Queries bei der Ausführung an den zugehörigen Service weiter leitet.
Mit Federation können Services vollständig voneinander getrennt aufgebaut werden. Es werden Key-Attribute pro Entität angegeben, welche diese eindeutig identifizieren, sodass jeder andere Service lediglich dieses Attribut angeben muss um den vollständigen Typen nutzen zu können (der entsprechende Service bietet einen Resolver, welcher anhand des Keys nun die Entität zurückgibt, sodass die anderen Services keinen eigenen Zugriff definieren müssen). Hierdurch sind die Zuständigkeiten klar eingeteilt und die Microservices können dynamisch und isoliert erstellt werden. Das Gateway erkennt diese Zusammenhänge automatisch und stellt sie zu einem komplett funktionsfähigen Schema zusammen. Im Gateway selber muss der Nutzer lediglich die Urls zu den Services angeben, alles andere wird von dem Framework erledigt. Somit kann bei Änderungen eines Services einfach das Gateway neu gestartet werden und alles sollte ohne weiteren Aufwand funktionieren.
In der Theorie ist dieses Gateway sehr hilfreich. Leider ist es zu dem jetzigen Zeitpunkt (17.06.19) noch sehr neu und hat dementsprechend einige Bugs bzw. noch nicht die volle Funktionalität implementiert. Das Prinzip funktioniert für alle grundlegenden Typen wie Queries, Mutations, Types und Input Types. Weiterhin werden bereits Interfaces und Union Types unterstützt, Enums führen jedoch zu Problemen, da hier der Resolver nicht übernommen wird. Weiterhin werden noch keine Subscriptions unterstützt und auch in den bestehenden Funktionalitäten findet sich immer wieder eine kleine Form von Fehlverhalten. Somit ist diese Technologie zu dem jetzigen Zeitpunkt leider noch nicht produktiv nutzbar.
- GraphiQL
- GraphCMS (Backend mit Interface (vgl. Wordpress))
- Graphcool (Backend ohne Interface)
- GraphQL Server auch als API-Gateway?
- (Geringe) Nutzlast bei der Übertragung von Medien (Produktbilder) bei der Verwendung von GraphQL?
- Kollaboratives Arbeiten der Erzeuger ermöglichen mithilfe von asynchroner Kommunikation (Websockets)?
- HTTPS verwenden: wo werden die Microservices deployed?