-
Notifications
You must be signed in to change notification settings - Fork 435
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* ' * Update
- Loading branch information
Showing
4 changed files
with
100 additions
and
75 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -34,17 +34,6 @@ English | [简体中文](README_zh-CN.md) | |
| > | ||
| > **Star Us**, You will receive all release notifications from GitHub without any delay ~ ⭐️ | ||
| ## 📣 OpenCompass 2.0 | ||
|
|
||
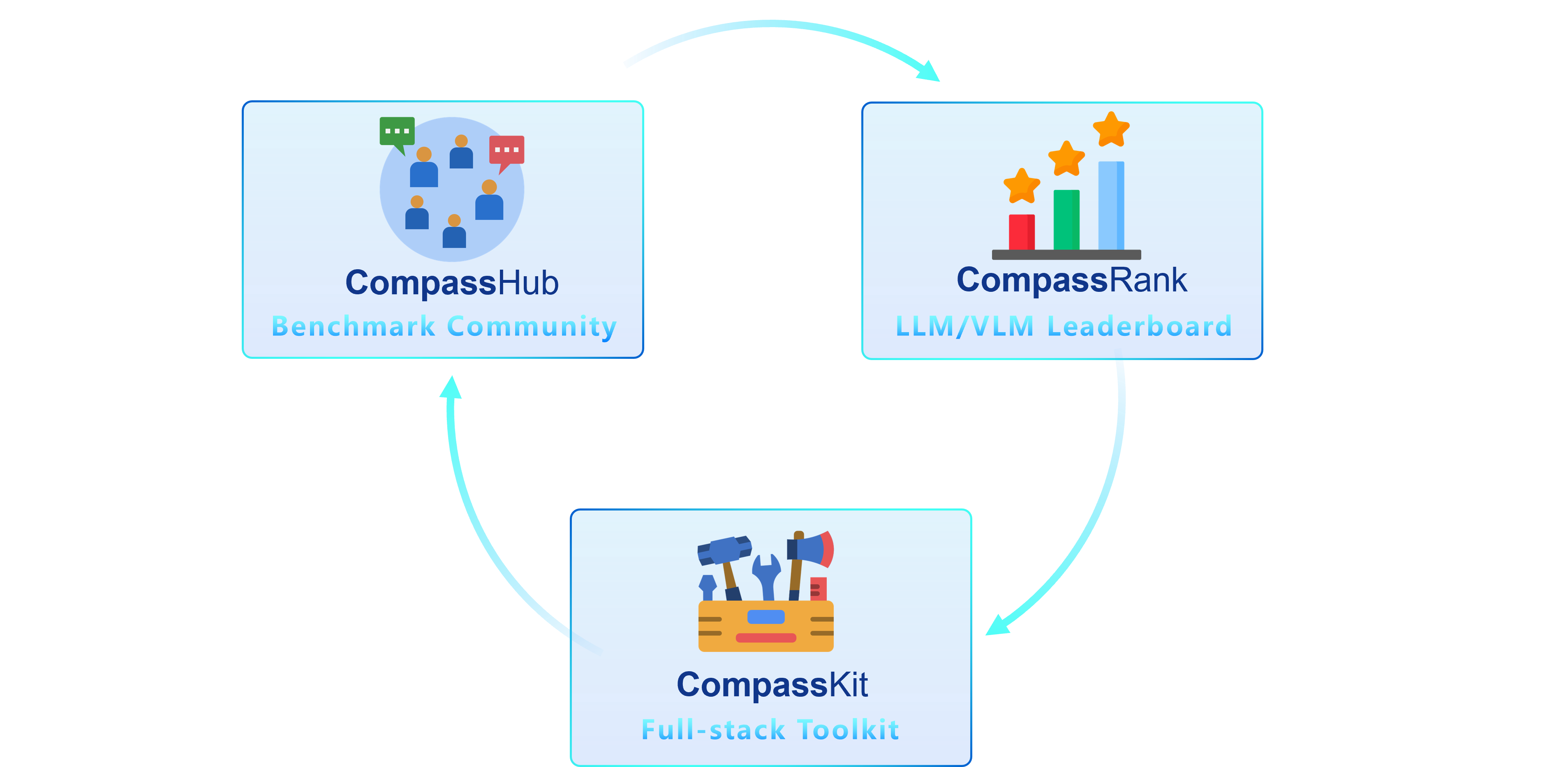
| We are thrilled to introduce OpenCompass 2.0, an advanced suite featuring three key components: [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home). | ||
|  | ||
|
|
||
| **CompassRank** has been significantly enhanced into the leaderboards that now incorporates both open-source benchmarks and proprietary benchmarks. This upgrade allows for a more comprehensive evaluation of models across the industry. | ||
|
|
||
| **CompassHub** presents a pioneering benchmark browser interface, designed to simplify and expedite the exploration and utilization of an extensive array of benchmarks for researchers and practitioners alike. To enhance the visibility of your own benchmark within the community, we warmly invite you to contribute it to CompassHub. You may initiate the submission process by clicking [here](https://hub.opencompass.org.cn/dataset-submit). | ||
|
|
||
| **CompassKit** is a powerful collection of evaluation toolkits specifically tailored for Large Language Models and Large Vision-language Models. It provides an extensive set of tools to assess and measure the performance of these complex models effectively. Welcome to try our toolkits for in your research and products. | ||
|
|
||
| <details> | ||
| <summary><kbd>Star History</kbd></summary> | ||
| <picture> | ||
|
|
@@ -79,33 +68,9 @@ Just like a compass guides us on our journey, OpenCompass will guide you through | |
| - **\[2024.07.17\]** We are excited to announce the release of NeedleBench's [technical report](http://arxiv.org/abs/2407.11963). We invite you to visit our [support documentation](https://opencompass.readthedocs.io/en/latest/advanced_guides/needleinahaystack_eval.html) for detailed evaluation guidelines. 🔥🔥🔥 | ||
| - **\[2024.07.04\]** OpenCompass now supports InternLM2.5, which has **outstanding reasoning capability**, **1M Context window and** and **stronger tool use**, you can try the models in [OpenCompass Config](https://github.com/open-compass/opencompass/tree/main/configs/models/hf_internlm) and [InternLM](https://github.com/InternLM/InternLM) .🔥🔥🔥. | ||
| - **\[2024.06.20\]** OpenCompass now supports one-click switching between inference acceleration backends, enhancing the efficiency of the evaluation process. In addition to the default HuggingFace inference backend, it now also supports popular backends [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm). This feature is available via a simple command-line switch and through deployment APIs. For detailed usage, see the [documentation](docs/en/advanced_guides/accelerator_intro.md).🔥🔥🔥. | ||
| - **\[2024.05.08\]** We supported the evaluation of 4 MoE models: [Mixtral-8x22B-v0.1](configs/models/mixtral/hf_mixtral_8x22b_v0_1.py), [Mixtral-8x22B-Instruct-v0.1](configs/models/mixtral/hf_mixtral_8x22b_instruct_v0_1.py), [Qwen1.5-MoE-A2.7B](configs/models/qwen/hf_qwen1_5_moe_a2_7b.py), [Qwen1.5-MoE-A2.7B-Chat](configs/models/qwen/hf_qwen1_5_moe_a2_7b_chat.py). Try them out now! | ||
| - **\[2024.04.30\]** We supported evaluating a model's compression efficiency by calculating its Bits per Character (BPC) metric on an [external corpora](configs/datasets/llm_compression/README.md) ([official paper](https://github.com/hkust-nlp/llm-compression-intelligence)). Check out the [llm-compression](configs/eval_llm_compression.py) evaluation config now! 🔥🔥🔥 | ||
| - **\[2024.04.29\]** We report the performance of several famous LLMs on the common benchmarks, welcome to [documentation](https://opencompass.readthedocs.io/en/latest/user_guides/corebench.html) for more information! 🔥🔥🔥. | ||
| - **\[2024.04.26\]** We deprecated the multi-madality evaluating function from OpenCompass, related implement has moved to [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), welcome to use! 🔥🔥🔥. | ||
| - **\[2024.04.26\]** We supported the evaluation of [ArenaHard](configs/eval_subjective_arena_hard.py) welcome to try!🔥🔥🔥. | ||
| - **\[2024.04.22\]** We supported the evaluation of [LLaMA3](configs/models/hf_llama/hf_llama3_8b.py) 和 [LLaMA3-Instruct](configs/models/hf_llama/hf_llama3_8b_instruct.py), welcome to try! 🔥🔥🔥 | ||
| - **\[2024.02.29\]** We supported the MT-Bench, AlpacalEval and AlignBench, more information can be found [here](https://opencompass.readthedocs.io/en/latest/advanced_guides/subjective_evaluation.html) | ||
| - **\[2024.01.30\]** We release OpenCompass 2.0. Click [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home) for more information ! | ||
|
|
||
| > [More](docs/en/notes/news.md) | ||
| ## ✨ Introduction | ||
|
|
||
|  | ||
|
|
||
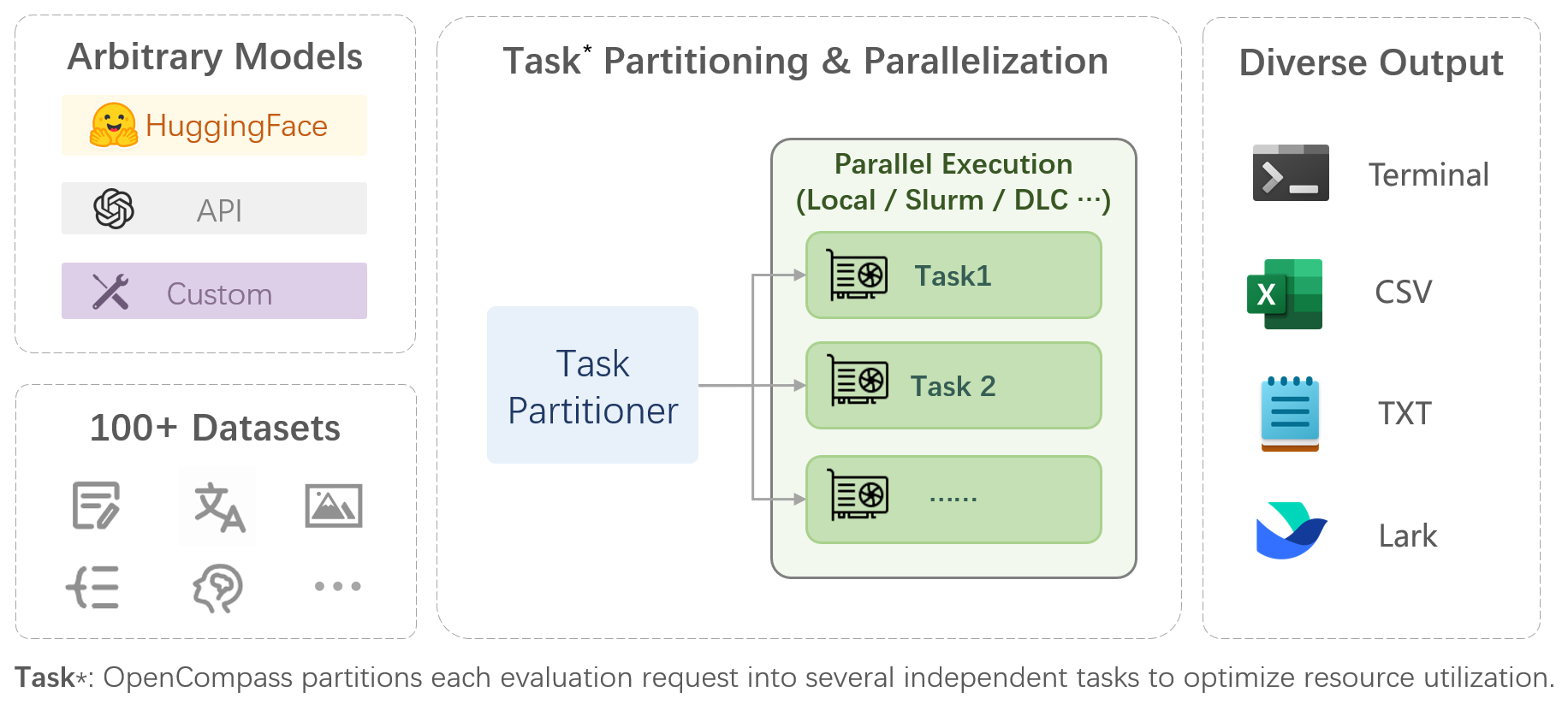
| OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: | ||
|
|
||
| - **Comprehensive support for models and datasets**: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. | ||
|
|
||
| - **Efficient distributed evaluation**: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. | ||
|
|
||
| - **Diversified evaluation paradigms**: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. | ||
|
|
||
| - **Modular design with high extensibility**: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! | ||
|
|
||
| - **Experiment management and reporting mechanism**: Use config files to fully record each experiment, and support real-time reporting of results. | ||
|
|
||
| ## 📊 Leaderboard | ||
|
|
||
| We provide [OpenCompass Leaderboard](https://rank.opencompass.org.cn/home) for the community to rank all public models and API models. If you would like to join the evaluation, please provide the model repository URL or a standard API interface to the email address `[email protected]`. | ||
|
|
@@ -257,6 +222,16 @@ After ensuring that OpenCompass is installed correctly according to the above st | |
| opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat | ||
| ``` | ||
| If you want to use multiple GPUs to evaluate the model in data parallel, you can use `--max-num-worker`. | ||
| ```bash | ||
| CUDA_VISIBLE_DEVICES=0,1 opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat --max-num-worker 2 | ||
| ``` | ||
| > \[!TIP\] | ||
| > | ||
| > `--hf-num-gpus` is used for model parallel(huggingface format), `--max-num-worker` is used for data parallel. | ||
| > \[!TIP\] | ||
| > | ||
| > configuration with `_ppl` is designed for base model typically. | ||
|
|
@@ -266,6 +241,33 @@ Through the command line or configuration files, OpenCompass also supports evalu | |
| <p align="right"><a href="#top">🔝Back to top</a></p> | ||
| ## 📣 OpenCompass 2.0 | ||
| We are thrilled to introduce OpenCompass 2.0, an advanced suite featuring three key components: [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home). | ||
|  | ||
| **CompassRank** has been significantly enhanced into the leaderboards that now incorporates both open-source benchmarks and proprietary benchmarks. This upgrade allows for a more comprehensive evaluation of models across the industry. | ||
| **CompassHub** presents a pioneering benchmark browser interface, designed to simplify and expedite the exploration and utilization of an extensive array of benchmarks for researchers and practitioners alike. To enhance the visibility of your own benchmark within the community, we warmly invite you to contribute it to CompassHub. You may initiate the submission process by clicking [here](https://hub.opencompass.org.cn/dataset-submit). | ||
| **CompassKit** is a powerful collection of evaluation toolkits specifically tailored for Large Language Models and Large Vision-language Models. It provides an extensive set of tools to assess and measure the performance of these complex models effectively. Welcome to try our toolkits for in your research and products. | ||
| ## ✨ Introduction | ||
|  | ||
| OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: | ||
| - **Comprehensive support for models and datasets**: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. | ||
| - **Efficient distributed evaluation**: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. | ||
| - **Diversified evaluation paradigms**: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. | ||
| - **Modular design with high extensibility**: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! | ||
| - **Experiment management and reporting mechanism**: Use config files to fully record each experiment, and support real-time reporting of results. | ||
| ## 📖 Dataset Support | ||
| <table align="center"> | ||
|
|
@@ -588,7 +590,7 @@ Through the command line or configuration files, OpenCompass also supports evalu | |
| ## 🔜 Roadmap | ||
| - [x] Subjective Evaluation | ||
| - [ ] Release CompassAreana | ||
| - [x] Release CompassAreana | ||
| - [x] Subjective evaluation. | ||
| - [x] Long-context | ||
| - [x] Long-context evaluation with extensive datasets. | ||
|
|
||
Oops, something went wrong.