



![]()
The extension for ANTLR4 support in Visual Studio code.
This release includes fixes for latest Visual Studio Code changes and comes with fixed backend tests.
- Complete syntax coloring for ANTLR grammars (.g and .g4 files)
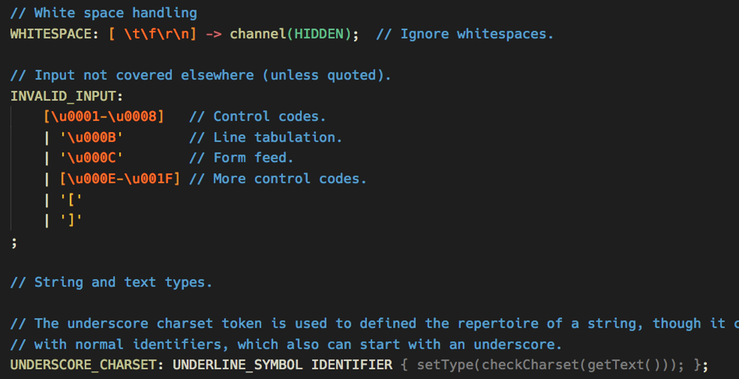
- Comes with an own beautiful color theme, which not only includes all the recommended groups, but also some special rules for grammar elements that you don't find in other themes (e.g. alt labels and options).
-
Code suggestions for all rule + token names, channels, modes etc. (including built-in ones).
-
Symbol type + location are shown on mouse hover. Navigate to any symbol with Ctrl/Cmd + Click. This works even for nested grammars (token vocabulary + imports).
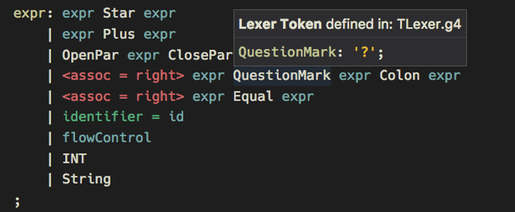
- Symbol list for quick navigation (via Shift + Ctrl/Cmd + O).
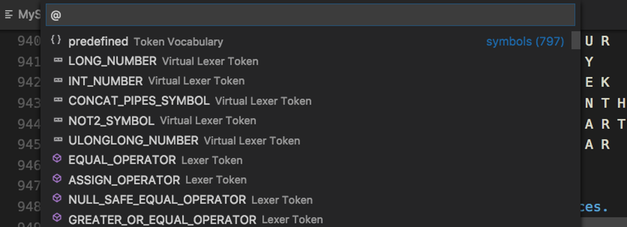
- In the background syntax checking takes place, while typing. Also some semantic checks are done, e.g. for duplicate or unknown symbols.
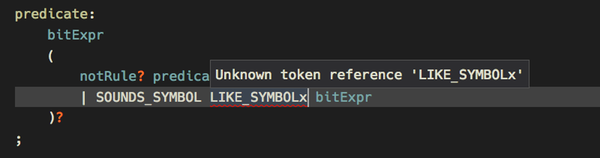
- When parser generation is enabled (at least for internal use) ANTLR4 itself is used to check for errors and warnings. These are then reported instead of the internally found problems and give you so the full validation power of ANTLR4.
- When enabled the extension creates parser and lexer files on each save of your grammar. This can either be used for internal operations only (e.g. to find detailed error information or to generate railroad diagrams and debugger data) or to generate these files for your own use. Furthermore, interpreter data is generated which is used to generate the ATN graphs or run the debugger. This generation process can be fine tuned by a number of settings (see below).
The extension supports debugging of grammar files (parser rules only). At least internal code generation must be enabled to allow debugging (which is the default and requires a usable Java installation). This implementation depends on the interpreter data export introduced in ANTLR4 4.7.1 (which is hence the lowest supported ANTLR4 version).
All of the usual operations are supported:
- Run w/o debugging - just run the parser interpreter (no profiling yet, though it's planned)
- Run with debugging - run the interpreter and stop on breakpoints
- Step into parser rules
- Step over lexer tokens and parser rules
- Step out of the current parser rule
Once the entire input is parsed, the parse tree can be visualized, either in the debug console as text or as graphical output in an own editor tab. This is configurable in the launch task setup.
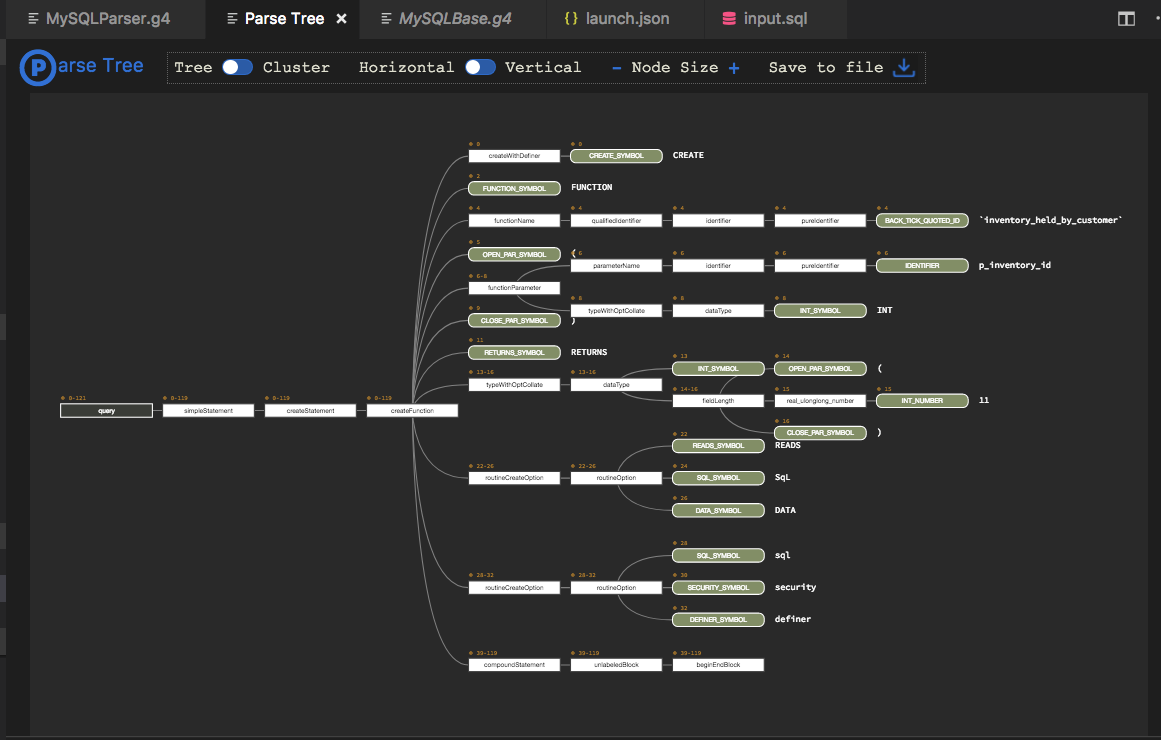
The graphical parse tree is interactive. You can collapse/expand parser rule nodes to hide/show tree parts. Both a horizontal and a vertical graph layout is supported and you can switch between the standard (compact) tree layout or the cluster layout, where all terminals are aligned at the bottom or on the right hand side (depending on the layout).
As with all graphs in this extension, you can export it to an SVG file, along with custom or built-in CSS code to style the parse tree.
Breakpoints can be set for rule enter and rule exit. Currently no intermediate lines are supported. Breakpoints set within a rule are moved automatically to the rule name line and act as rule enter breakpoints.
During debugging a number of standard and extra views give you grammar details:
- Variables - a few global values like the used test input and its size, the current error count and the lexed input tokens.
- Call stack - the parser rule invocation stack.
- Breakpoints - rule enter + exit breakpoints.
- Lexer Tokens - a list of all defined lexer tokens, along with their assigned index.
- Parser Rules - a list of all defined parser rules, along with their assigned index.
- Lexer Modes - a list of all defined lexer modes (including the default mode).
- Token Channels - a list of used token channels (including predefined ones).
Everything needed for debugging is included (except Java, which must be installed on your box and be reachable without an explicit path). You only have to configure the launch task to start debugging. Here's an example:
{
"version": "2.0.0",
"configurations": [
{
"name": "antlr4-mysql",
"type": "antlr-debug",
"request": "launch",
//"input": "${workspaceFolder}/${command:AskForTestInput}",
"input": "input.sql",
"grammar": "grammars/MySQLParser.g4",
"startRule": "query",
"printParseTree": true,
"visualParseTree": true
}
]
}As usual, the configuration has a name and a type, as well as a request type. Debugging a parser requires some sample input. This is provided from an external file. You can either specify the name of the file in the input parameter or let vscode ask you for it (by using the out-commented variant). Everything else is optional. If no grammar is specified, the file in the currently active editor is used (provided it is an ANTLR4 grammar). The start rule allows to specify any parser rule by name and allows so to parse full input as well as just a subpart of a grammar. If not given the rule at index 0 is used as starting point (which is the first rule found in your parser grammar). The parse tree settings determine the output after the debugger has ended (both are false by default).
The debugger uses the lexer and parser interpreters found in the ANTLR4 runtime. These interpreters use the same prediction engine as the standard classes, but cannot execute any target runtime code. Hence it is not possible to execute actions or semantic predicates. If your parser depends on that, you will have to modify your grammar(s) to avoid the need for such code. There are however considerations about using an answer file or similar to fake the output of predicates.
The interpreters are implemented in Typescript and transpiled to Javascript, hence you shouldn't expect high performance parsing from the debugger. However, it should be good enough for normal error search.
Even though ANTLR4 supports (direct) left recursive rules, their internal representation is totally different (they are converted to non-left-recursive rules). This makes it fairly difficult to match the currently executing ATN state to a concrete source position. Expect therefor non-optimal step marker visualization in such rules.
Parser rule context variables, parameters and return values cannot be inspected, as they don't exist in the interpreter generated parse tree.
This extension can create a number of graphical visualizations for you. All of them (except of the railroad diagram) share the same look and feel (they are all based on D3.js). You can click on a free area in the graph and drag the mouse, to move the graph's view port. The mouse wheel or track pad can be used to zoom in and out. Certain graphs allow for additional actions, see below.
All these graphs also allow to export them to an SVG file (or in the case of the full RRD list, to an HTML file). The export will also copy the internal CSS file, as well as all custom CSS files you have specified for a graph type (in the settings). SVG files always use the light theme style colors, while the HTML output follows the currently set vscode theme.
- Railroad Diagrams: Available from the editor context menu is a function to generate railroad diagrams for all types of rules (parser, lexer, fragment lexer), provided by the railroad-diagrams script from Tab Atkins Jr.. You can either do that for the rule under the caret (and the display changes as you move the caret) or for the entire grammar file. An export function allows to generate an SVG file of the graph on disk. Colors + fonts can be adjusted by using custom CSS file(s). See also the available options below.
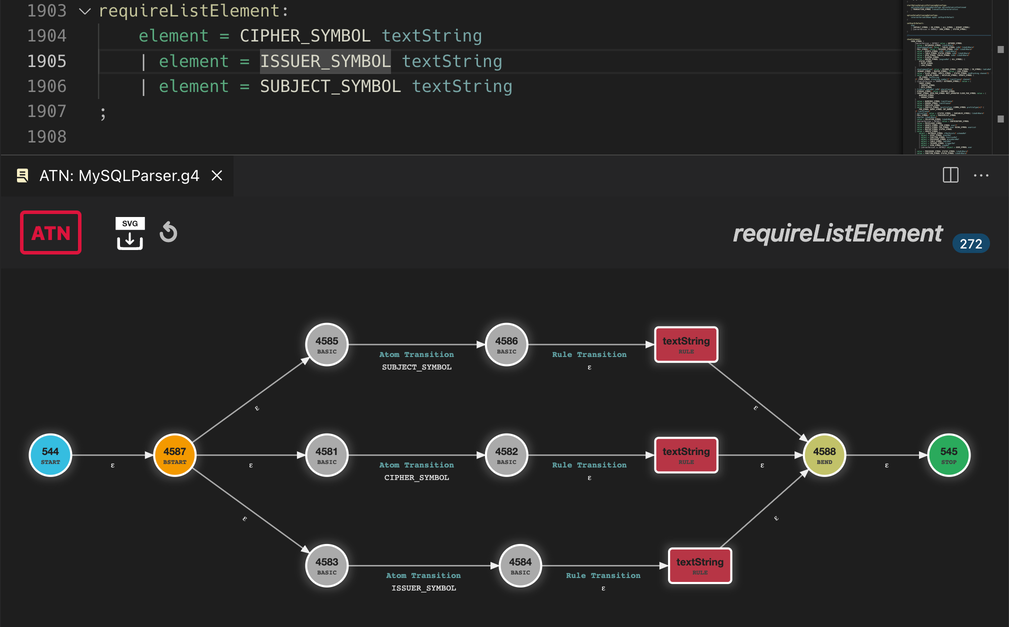
- ATN Graphs: Also available from the editor context menu are the ATN graphs. They are a visualization of the internal ATN that drives lexers + parsers. This graph uses a dynamic layout to find good positions for the nodes without overlapping. However, this is rarely satisfying. Therefor you can move nodes around to make the graph prettier. Moved nodes stick to their position, even if you close and reopen the graph. Double click a node to make it float again or click
Reset displayto remove all cached positions.
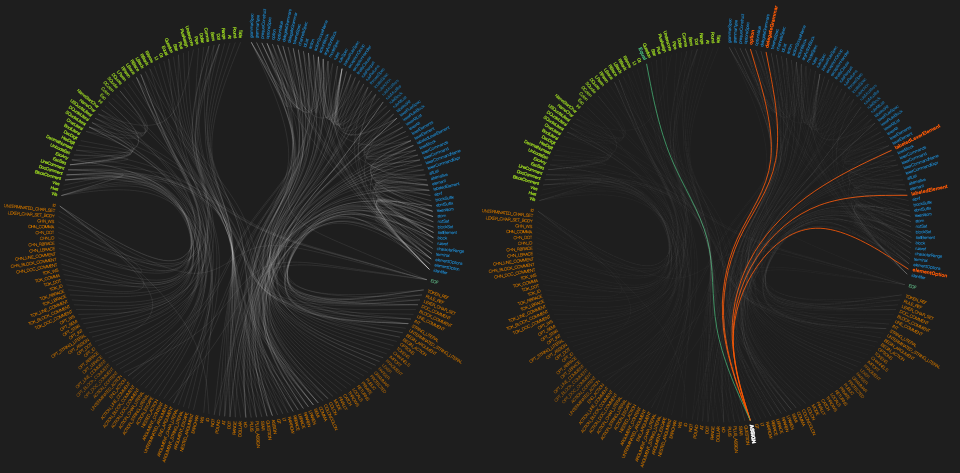
- Call Graph: In order to get an impression about the complexity of your grammar and visually find rule relationships there's a call graph (a dendrogram), also available from the editor context menu. It draws connections between rules (parser, lexer + fragment rules), for the current grammar as well as those used by it. The more lines you see, the higher the rules interact with each other. You can hover with the mouse over a rule name and it will highlight all relationships for that rule (while the rest is faded out). Red lines are drawn to callers of that rule, green lines for those called by it. Hence many red lines means this is a rule used by many others and hence a good candidate for optimization. Many green lines however indicate a high complexity and you should perhaps refactor this rule into multiple smaller ones.
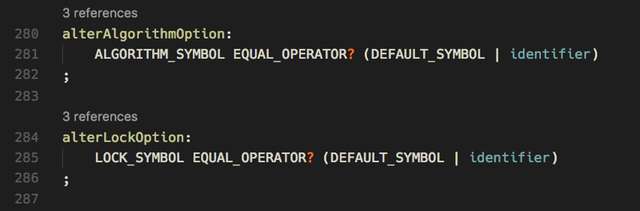
The extension is able to format grammar source code, considering a large set of options (see below). The clang-format tool acted as a model for option naming and some settings that have been taken over. Beside the usual things like block formatting, empty lines and comment formatting, there's a powerful alignment implementation. It allows to align certain grammar elements (trailing comments, lexer commands, alt labels, predicates and others) between consecutive lines that contain this grammar element (when grouped alignment is on) or for the entire file. There can even be multiple alignments on a line:

The formatting feature can be controlled by special comments, which allow to switch a setting on the fly. You can even completely switch off formatting for a file or a part of it. Below are some examples for such a formatting comment. You can use boolean values (on, off, true, false), numbers and identifiers (for word options). They are not case-sensitive.
// $antlr-format on
// $antlr-format false
// $antlr-format columnLimit 150
// $antlr-format allowShortBlocksOnASingleLine true, indentWidth 8
Don't put anything else in a comment with formatting settings. All comment types are allowed, but single line comments are read line by line and hence require each line to start with the $antlr-format introducer.
In order to set all settings to their default values use: // $antlr-format reset. This can also be used in conjunction with other options.
- There is an option to switch on rule reference counts via Code Lens. This feature is switchable independent of the vscode Code Lens setting.
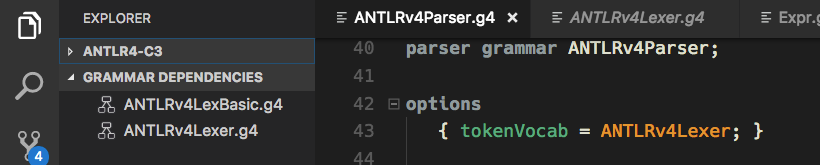
- For each grammar its dependencies are shown in a sidebar view (i.e. token vocabulary and imports).
- antlr4.referencesCodeLens.enabled, boolean (default: false), if true enables the reference count display via Code Lens
- antlr4.customcss, array of string (no default), list of custom css URIs for diagrams/graphs
- antlr4.rrd.saveDir, string (no default), default export target folder for railroad diagrams
- antlr4.call-graph.saveDir, string (no default), default export target folder for call graphs
- antlr4.atn.saveDir, string (no default), default export target folder for atn graph
- antlr4.atn.maxLabelCount, number (default: 3), max number of labels displayed on a transition in an ATN graph
This is a settings object named antl4.generation with the following members:
- mode, string enum (default: "internal"), determines what code generation pattern should be followed:
- none: don't generate any code, not even for internal use
- internal: allow code generation for internal use (e.g. for full error detection and interpreter data)
- external: generate code also for external use, depending on the other generation options
- outputDir, string (default: empty/undefined), determines the output folder where to place generated code (used only if mode is set to
external) - importDir, string (default: empty/undefined), location to import grammars from (relative to the grammar that is being saved, or absolute path), used also for internal code generation
- package, string (default: empty/undefined), package/namespace for generated code (used only in external mode)
- language, string (default: "Java"), specifies the target language for the generated code, overriding what is specified in the grammar (used only in external mode)
- listeners, boolean (default: true), also create listeners on code generation (used only in external mode)
- visitors, boolean (default: false), also create visitors on code generation (used only in external mode)
This is a settings object named antlr4.format with the following members:
- alignTrailingComments: boolean (default: false), if true, aligns trailing comments
- allowShortBlocksOnASingleLine: boolean (default: true), allows contracting short blocks to a single line
- breakBeforeBraces: boolean (default: false), when true start predicates and actions on a new line
- columnLimit: number (default: 100), the character count after which automatic line breaking takes place
- continuationIndentWidth: number (default: 4), indentation for line continuation (only used if useTab is false)
- indentWidth: number (default: 4), character count for indentation (if useTab is false)
- keepEmptyLinesAtTheStartOfBlocks: boolean (default: false), if true, empty lines at the start of blocks are kept
- maxEmptyLinesToKeep: number (default: 1), the maximum number of consecutive empty lines to keep
- reflowComments: boolean (default: true), reformat comments to fit the column limit
- spaceBeforeAssignmentOperators: boolean (default: true), enables spaces around operators
- tabWidth: number (default: 4), multiples of this value determine tab stops in a document
- useTab: boolean (default: true), use tabs for indentation (otherwise spaces)
- alignColons: string enum (default: "none"), align colons among rules (scope depends on groupedAlignments)
- none: place the colon directly after the rule name
- trailing: align colons in the alignment group, directly after rule names
- hanging: align the colon on the next line (with the pipe chars)
- singleLineOverrulesHangingColon: boolean (default: true), single line mode overrides hanging colon setting (applies also to alignSemicolons)
- allowShortRulesOnASingleLine: boolean (default: true), allows contracting short rules on a single line (short: < 2/3 of columnLimit)
- alignSemicolons: string enum (default: "none"), determines the alignment of semicolons in rules
- none: no alignment, just put it at the end of the rule directly after the last token
- ownLine: put it on an own line (not indented), unless allowShortRulesOnASingleLine kicks in
- hanging: put it on an own line with indentation (aligning it so to the alt pipe chars)
- breakBeforeParens: boolean (default: false), for blocks: if true puts opening parentheses on an own line
- ruleInternalsOnSingleLine: boolean (default: false), place rule internals (return value, local variables, @init, @after) all on a single line
- minEmptyLines: number (default: 0), determines the number of empty lines that must exist (between rules or other full statements)
- groupedAlignments: boolean (default: true), when true only consecutive lines are considered for alignments
- alignFirstTokens: boolean (default: false), align the first token after the colon among rules
- alignLexerCommands: boolean (default: false), align lexer commands (starting with ->) among rules
- alignActions: boolean (default: false), align action blocks + predicates among rules and alternatives
- alignLabels: boolean (default: true), align alt labels (only when a rule is not on a single line)
- alignTrailers: boolean (default: false), combine all alignments (align whatever comes first: colons, comments etc.)
See the Git issue tracker.
- Bug fixing
- Fixed Bug #36 "$antlr-format off" removes remaining lines in file
- Fixed Bug #37 Debugging gets stuck with visualParseTree set to true
- Updated tests to compile with the latest backend changes.
- Fixed a bug when setting up a debugger, after switching grammars. Only the first used grammar did work.
- Fixed Bug #28 ATN graph cannot be drawn even after code generation.
- Fixed another bug in interpreter data file names construction.
- Bug fix for wrong interpreter data paths.
- Implicit lexer tokens are now properly handled.
- Fixed a bug in the formatter.
- The extension and its backend module (formerly known as antlr4-graps) have now been combined. This went along with a reorganization of the code.
- A rename provider has been added to allow renaming symbols across files.
- Added grammar debugger.
- Added graphical and textual parse tree display.
- Added dependency graph.
- Added call graph.
- Added ATN graphs.
- Added SVG export for ATN graphs + railroad diagrams.
- Now showing a progress indicator for background tasks (parser generation).
- Added code lens support.
- Added code completion support.
- Finished the light theme.
- Rework of the code - now using Typescript.
- Adjustments for reworked antlr4-graps nodejs module.
- Native code compilation is a matter of the past, so problems on e.g. Windows are gone now.
- No longer considered a preview.
- Updated the symbol handling for the latest change in the antlr4-graps module. We now also show different icons depending on the type of the symbol.
- Updated prebuilt antlr4-graps binaries for all platforms.
- Quick navigation has been extended to imports/tokenvocabs and lexer modes.
- The symbols list now contains some markup to show where a section with a specific lexer mode starts.
- Fixed also a little mis-highlighting in the language syntax file.
- Added a license file.
Marked the extension as preview and added prebuild binaries.
- full setup of the project
- added most of the required settings etc.
- included dark theme is complete
For further details see the Git commit history.
The dependencies view icons have been taken from the vscode tree view example.