Home
- Intro to Machine Learning
- Defining and Differentiation Machine Learning
- Story of machine learning
- The data science process
- Types of data
- Tabular data
- Scaling data
The chapter covers the following items in the subtopics:
- The definition of Machine learning and How it's different from Traditional Programming
- Applications of Machine learning
- The historical context of machine learning The data science process The types of data that machine learning deals with The two main perspectives in ML: the statistical perspective and the computer science perspective The essential tools needed for designing and training machine learning models The basics of Azure ML The distinction between models and algorithms The basics of a linear regression model The distinction between parametric vs. non-parametric functions The distinction between classical machine learning vs. deep learning The main approaches to machine learning The trade-offs that come up when making decisions about how to design and training machine learning models
The Definition:
Machine learning is a data science technique used to extract patterns from data, allowing computers to identify related data, and forecast future outcomes, > behaviours, and trends.
Data science deals with identifying patterns in data and using it to make predictions or map relations between data points; Machine learning is a technique used by data scientists to forecast future trends using existing data and outcomes implementing various algorithms which learn and identify data patterns among the give data points.
The following image depicts data science and its multiple disciplines:
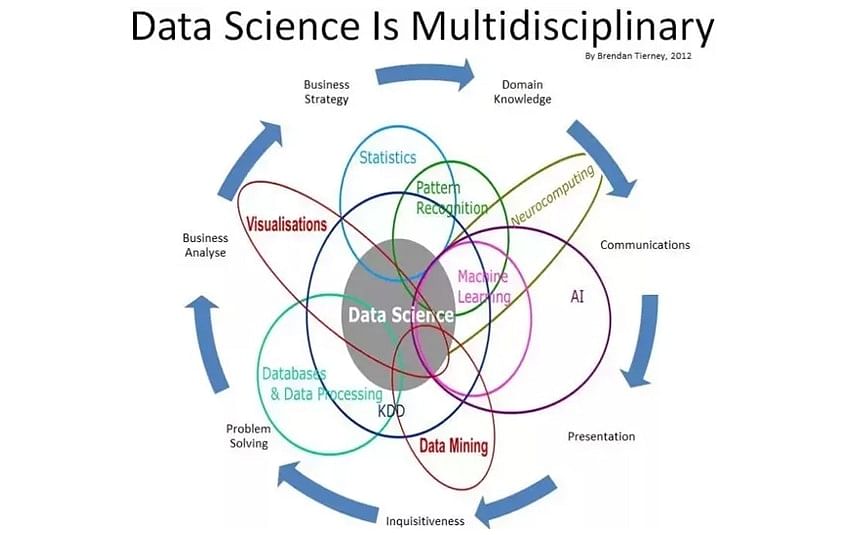

Artificial intelligence started in the 1950s which is all about writing algorithms that mimic human thought process. Machine learning then came to write programs which identify data patterns without explicitly being programmed. Deep learning with the discovery of neural nets is the breakthrough that drove the AI boom and also complex machine learning applications such as language processing and image classification.
Many hidden layers and hidden nodes made the field to be called deep learning.
- Collect Data - From various sources such as, but not limited to:
- Files
- Databases
- Webservices
- Scraping/Crawling webpages
-
Preparing Data - Data cleansing (removing undesirable values and biased data points from the data set) and Data visualisation (visualizing data using plots/graphs)
-
Training Model - setting up model pipeline by feature vectorization, feature scaling and tuning machine learning algorithm. evaluating mode performance through variance evaluation matrix to understand and evaluate the training cycles of the model.
-
Evaluate Model - Testing and comparing the performance of multiple trained versions of the model with the test data.
-
Model Deployment - As a part of DevOps which integrate training, evaluation and deployment scripts for respective builds and release pipelines.They make sure all the versions of the model deployments are versioned and artefacts are archived.
-
Retraining - Based on the business need, we might have to re-train our machine learning models going through the processes of Training-Evaluation-Deployment for the new re-trained version.
The form and structure of the data play a crucial role in deciding the machine learning algorithm to use, values of hyperparameters and problem-solving methodology.
It's all numerical at the end!
-
Numerical Data - Data that is in the numerical form or that has been converted from other data forms into numerical such as speech or image data converted into numerical data points.
-
Time-Series Data - Numerical values that can be ordered. Typically data collected over equally spaced points in time, and can also include data that can be ordered with a non-date-time column.
- Examples of non-date time column time series data: Real-time stock performance, demand forecasting and speech data that will be translated into a time-based frequency value.
-
Categorical Data - Discrete and limited set of values which doesn't add any sense of value to the data unless it is categorized/grouped.
-
Text - Transforming words and texts into numbers understandable by machine learning algorithms is a challenge by itself.
-
Image - Transforming Image into numeric form is a challenge similar to the text for developing machine learning algorithms.
The most common type of data available for most of the machine learning problems is the tabular data.
Defining the elements of tabular data:
Row: Item/entity in a table.
Column: Property of the item/entity. They can be continuous or discrete(categorical) data.
Cell: A single component of the table describing an item in the x-direction and its property in the y-direction.
Vectors- A vector is simply an array of numbers, such as (1, 2, 3) or a nested array that contains other arrays of numbers, such as (1, 2, (1, 2, 3)).
Scaling means transforming data within a scale (most commonly used are 0-1 and 1-100). As all of the data will be transformed uniformly to the required scale this won't impact the model's prediction outcome.
Scaling will be done to improve the performance of the models training process as the data is now scaled to a smaller value.
- When do we go with the scale of 1-100 in place of 0-1?
- Is it required to propagate the training scalar for predictions using the test data?
- If the outcome is not changing with and without scaling data - it seems its not necessary to propagate.