{kind=link}
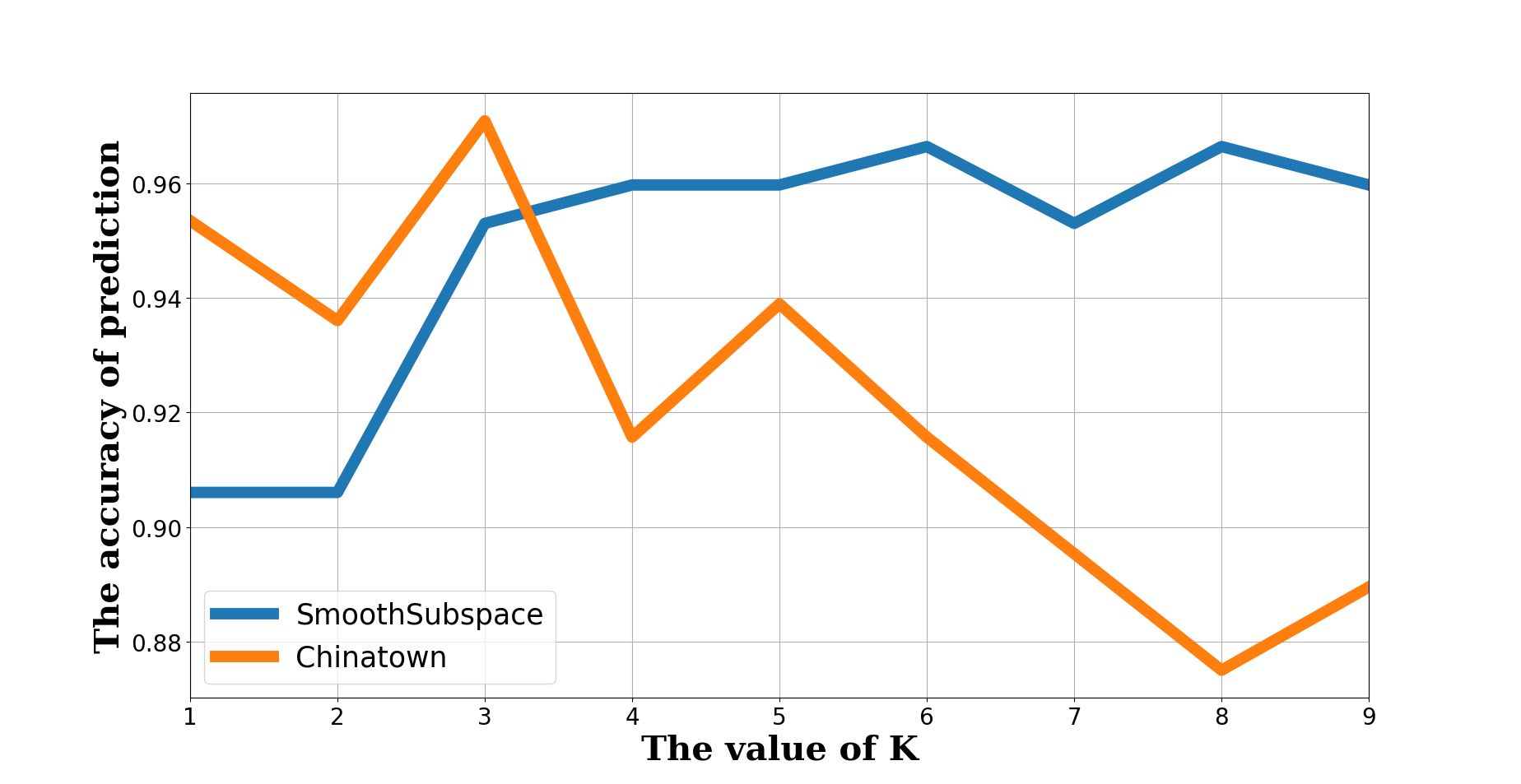
时间序列分类应用于各种各样的场合,与通常所分类的数据不一样,时间序列的特征就包含在它自身以内,包括振幅、频率、周期等。 这里使用了传统的机器学习方法K-NearestNeighbor结合Dynamic Time Warping(动态时间规整) 进行时间序列分析,针对开源数据集:UCR Time Series Classification Archive 最高精度可达97%
这是一种十分简单却很实用的聚类算法,KNN总的来说可以归结于一句话:物以类聚,人以群分。KNN的关键点在于如何度量物的相似度,尤其是当处理时间序列这一类由于时延、噪声等干扰因素所具有极其不稳定的特点的数据时。关于KNN的具体细节可以查看维基
DTW算法是用于求解两个时间序列之间的最大相似度,有关于它的细节可以查看这篇博文,在这里使用DTW来度量时间序列的相似度
以UCR Time Series Classification Archive的Chinatown和SmoothSubspace为例