Final project for SCC0251/SCC5830 - Image Processing - 1st Semester of 2020 at University of São Paulo.
- Eduardo Santos Carlos de Souza (Master's student, NUSP 9293481)
- Guilherme Hideo Tubone (Master's student, NUSP 9019403)
This project aims to build a system capable of, given two images, determine if both have the face of the same person or different people in them, known as the face verification problem. It uses image segmentation to separate the faces from the rest of the images, and image classification to determine whether the cropped faces belong to the same person. The images used are of photographic images of people, where their faces are visible, from the CelebA dataset. Possible applications revolve around security, where it is needed to verify someone's identity by an image of them, such as unlocking a phone and many surveillance systems.
As stated in the abstract, our objective is to create a system capable of verifying if 2 images of people have the face of the same person in them. Therefore the main objective can be broken down into two parts:
- A Segmentation Algorithm: Given a single image, crop out the location of the face in it.
- A Verification Algorithm: Given two already segmented faces, determine if they belong to the same person or not.
We limited our scope to only one face per image, and only photographic images.
To achieve our goals, we will need a large and varied dataset with two important characteristics:
- Annotation of the bounding box of the face present in the image.
- Annotation of the identity of the person present in the image.
The CelebA dataset has both of those characteristics, and is also extremely large, having 202,599 images. There are two versions of it, one with the raw image, the other with the face already mostly cropped. We will use the raw version, and initially intend to use it exclusively. All the images are photographs of celebrities, in a variety of conditions, with their faces visible.
However, there are other possibly useful datasets. We currently don't intend to use them, but we may later. They are:
-
- More varied them CelebA.
- It lacks identity annotation, so it would only be useful for the segmentation aspect of the project.
- Many images have more them one face in them, so filtering would be required.
-
LFW:
- Specialized for verification, having many images per person.
- It lacks bounding box annotation, so it would only be useful for the verification aspect of the project

Image 1.1 - Imaging containing mostly the head

Image 1.2 - Imaging containing entire body

Image 2.1 - First Image of Individual 1058

Image 2.2 - Second Image of Individual 1058

Image 3.1 - Image 2.1 segmented with bounding box annotation

Image 3.2 - Image 2.2 segmented with bounding box annotation
We added part of the data used to this GitHub repository, and the rest to a Google Drive folder.
To achieve our goals, we plan to take the following steps:
We will reorganize and reformat the original dataset to better suit our needs and improve usability. Importantly, for the face verification algorithm, we will only use individuals with more than 5 images of them in the dataset.
We plan to apply image processing techniques to facilitate the segmentation process.
We will, firstly, resize the image to a more manageable and constant size for our algorithms. We are going to use the Bicubic Interpolation to preserve the details.
Also, we will test changes to the color domain of our images, to see whether that has a positive effect on the results. We will test the Grayscale, RGB, and possibly the HSL domains.
Lastly, we intend to use manual edge detection algorithms, such as the Canny Edge Detector, to see if they improve our results.
After preprocessing, we will input the resulting image to a bounding box detection algorithm to segment the face from the rest of the image. We will compare traditional methods to a CNN based method that we will implement, both in terms of speed and accuracy. We will test Depthwise Separable Convolutions to reduce computational costs.
With the cropped face, we will create a CNN model that generates a feature vector for the face. Such vectors should be similar for different images of the same person. To achieve this, we will use a pre-trained VGG16 network, trained on a different but similar problem and dataset, and fine-tune the vectors generated by a hidden layer of it using the Triplet Loss.
With the feature vector extracted, a threshold applied to either the euclidian or cosine distance of 2 vectors should be enough to verify the individual.
As of the writing of this report, we have mostly focused on a codebase for later usage, and processing and organizing the dataset. The code is located on src, and the processed data on data and on Google Drive.
However, we do have some initial results. We ran a basic CNN model, with no hyperparameter optimization, no data augmentation, and no image preprocessing. We obtained the following results during training. The orange line is the training metric, and the blue one the validation metric.

Image 4.1 - Mean Squared Error of bounding box location throughout training

Image 4.2 - Mean Absolute Error of bounding box location throughout training
The resulting model was used to crop 100 images for visualization. Those are stored in sample_imgs/segmented/pred. We did the same process for comparison using the annotation data, and stored in sample_imgs/segmented/true. The resulting crops don't seem as precise as is expected from the metrics, so we will analize what may be occuring.

Image 5.1 - An instance where the model had a very good result

Image 5.2 - Ground Truth for Image 5.1

Image 6.1 - An instance where the model had bad but not terrible results. Most cases are like this

Image 6.2 - Ground Truth for Image 6.1

Image 7.1 - An instance where the model had terrible results

Image 7.2 - Ground Truth for Image 6.1
We also developed a notebook with the baseline face detection algorithm, located at sample_code/FaceDetectionCV.

Image 8 - Baseline Face Detection Sample
Finally, we implemented the canny edges detector, with a sample notebook at sample_code/CannyEdgeExample

Image 9 - Canny Edge Detection Sample
As stated in the abstract, our objective is to create a system capable of verifying if 2 images of people have the face of the same person in them. Therefore the main objective can be broken down into two parts:
- A Segmentation Algorithm: Given a single image, crop out the location of the face in it.
- A Verification Algorithm: Given two already segmented faces, determine if they belong to the same person or not.
We limited our scope to only one face per image, and only photographic images.
To achieve our goals, we will need a large and varied dataset with two important characteristics:
- Annotation of the bounding box of the face present in the image.
- Annotation of the identity of the person present in the image.
We decided to use the CelebA dataset exclusively. It has the annotations needed, and is also extremely large, having 202,599 images. There are two versions of it, one with the raw image, the other with the face already mostly cropped. We used the raw version. All the images are photographs of celebrities, in a variety of conditions, with their faces visible.
Image 13.1 - Imaging containing mostly the head
Image 13.2 - Imaging containing entire body
Image 14.1- First Image of Individual 1058
Image 14.2 - Second Image of Individual 1058
Image 15.1 - Image 14.1 segmented with bounding box annotation
Image 15.2 - Image 14.2 segmented with bounding box annotation
The data is too big for this repository, so we uploaded it to a Google Drive folder.
We reorganized and reformated the original dataset to better suit our needs and improve usability. Importantly for the face verification algorithm, we only used individuals with more than 5 images of them in the dataset. Also, for the bounding box annotation, we changed the way the data is represented. Originally, the data is given as the coordinates of the upper-left point of the bounding box, and the width and height of the bounding box. We changed it to the coordinates of the upper-left point and the bottom-right point of the bounding box. This resulted in better metrics.
Our model wasn't generating good results when the face was on the bottom or edges of the image. That is because in most images in the dataset, the face is on the upper part. To solve that, we augmented the data, by translating the image randomly, without taking the face bounding box out of the image. After the translation, the image would contain an empty part (the section that wasn't on the original image). To fix that we filled those parts with the closest edge color of the original image.

Image 1.1 - Original Image

Image 1.2 - Image 1.1 Augmented with Translation, Keeping the Correct Bounding Box
More augmentation examples can be found here.
Our CNN models only take inputs of a specific size. So we need to resize the image to the correct size. This resizing needs to be done for every batch of training, and when executing, so we decided to use the bilinear interpolation for its relatively low computational cost.
We tested changes in the color domain and the Canny edge detector to try to improve our results. They either made the results worse or didn't improve significantly, so they were not used. Here are their results (these metrics are better explained below):
| Set | Loss | Mean Absolute Error | Mean Bbox Iou |
|---|---|---|---|
| Train | 0.0005421281675808132 | 0.015870939940214157 | 0.8575448989868164 |
| Val | 0.0006855816463939847 | 0.01681641675531864 | 0.8516016006469727 |
Table 1 - Base Metrics
| Set | Loss | Mean Absolute Error | Mean Bbox Iou |
|---|---|---|---|
| Train | 0.00053440808551386 | 0.015981484204530716 | 0.8573797941207886 |
| Val | 0.0006816008244641125 | 0.016900835558772087 | 0.8512943983078003 |
Table 2 - Changing color from RGB to HSV
| Set | Loss | Mean Absolute Error | Mean Bbox Iou |
|---|---|---|---|
| Train | 0.0005476800724864006 | 0.016084963455796242 | 0.8568638563156128 |
| Val | 0.0007178573287092149 | 0.017143426463007927 | 0.8505929708480835 |
Table 3 - Changing color from RGB to Grayscale
| Set | Loss | Mean Absolute Error | Mean Bbox Iou |
|---|---|---|---|
| Train | 0.018834181129932404 | 0.10289715230464935 | 0.4456730782985687 |
| Val | 0.018753744661808014 | 0.10262654721736908 | 0.44477757811546326 |
Table 4 - Using the Canny Edge Detector
We used CNN's to predict the bounding box of the face. Our CNN's receive an unsegmented image as input, and return 4 real numbers between 0 and 1. Those numbers are the position of the bounding box, as fractions of the image shape. They are, in order, the left, upper, right, and lower edges of the bounding box.
We used 2 different versions of our CNN's. One used standard convolutions, and the other used depthwise separable convolutions. Depthwise separable convolutions are a different operation, similar to regular convolutions, but aiming to reduce the number of parameters and, especially, number of operations. They do so by breaking up the channels of the input image, them performing a single convolution on each channel. Them, they recombine the resulting filtered images and apply N regular convolutions, of size 1x1. The important aspect is that, by having only one filter per input channel, they greatly reduce the computational requirements. It is best represented by image 2.

Image 2 - Depthwise Separable Convolution Representation. Original Source of the Image
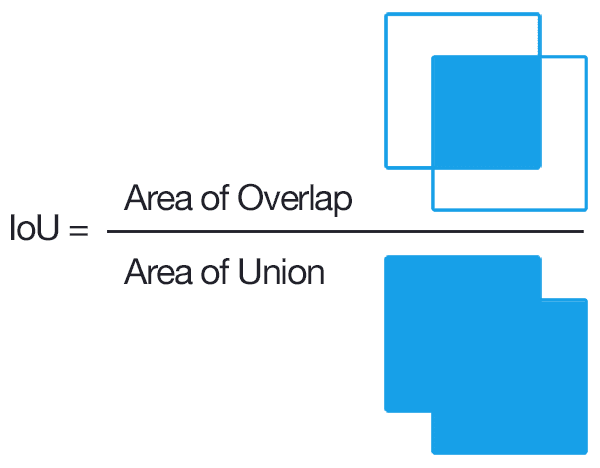
To evaluate our models, we decided to use the intersection-over-union metric. It works by dividing the area of the intersection of the two bounding boxes by the area of their union.

Image 3 - IoU Representation. Original Source of the Image
{kind=link}
For each type of convolution, we tried several different hyperparameters configurations, resulting in 54 experiments each. Here are the training graphs for the best models of each version.

Image 4 - Regular CNN IoU over training. Green line is validation data, and pink is training

Image 5 - Depthwise Separable CNN IoU over training. Red line is validation data, and blue is training
We then chose the best ones to improve with the data augmentation and image preprocessing described above.
To evaluate our models' results, we compared them to OpenCV's Face Detector. We used three different metrics: the Running Time, Intersection Over Union, and Mean Absolute Error. The Mean Absolute Error is the sum of the absolute differences of all points of the predicted bounding boxes and the original bounding boxes, divided by the number of points (4 times the amount of images).
The running time was obtained by running the algorithms on 500 random images from data/Img, belonging to the validation set. The metrics for OpenCV's algorithm were also obtained with these images. For our models, we used the metrics of the validation set obtained during training. We limited our models to run on a single CPU core, for a fairer comparison.
| Regular Model | Model using Depth-Wise Separable Convolution | Model with Augmented Data | Model with Augmented Data using Depth-Wise Separable Convolution | OpenCV | |
|---|---|---|---|---|---|
| Running time (seconds) | 45.81 | 29.28 | 57.07 | 31.03 | 55.82 |
| Mean of Intersection over Union | 0.85160 | 0.83353 | 0.83756 | 0.81453 | 0.70790 |
| Mean Absolute Error | 0.01681 | 0.01920 | 0.01832 | 0.02145 | 0.12914 |
Table 5 - Bounding Box Detection Comparison
With the face segmented, we need to generate a feature vector capable of differentiating people. To achieve that, we used a pre-trained CNN to extract such feature vector. We got the pre-trained weights from this link, originally provided on this webpage.
This CNN was originally trained on a classical classification problem, having to classify to whom, in a set of 2622 people, an image belonged. As such, we can't use it directly. To use it, we get the output of the last layer before the classification layer and use it as a feature extractor.
To fine tune the feature extraction, we trained the extractor using the triplet loss. Here is its equation:

Image 6 - Mathematical Equation of the Triplet Loss. Original Source of the Image
Where f is the feature extraction function, A is the anchor, P is the positive example (same person as A), and N is the negative example (different person than A), and alpha is a constant value. As such, as this loss decreases, the distances between images of the same person decrease, and the distances between images of the different people increase.

Image 7 - Graphical Representation of the Triplet Loss. Original Source of the Image
The distance function in this scenario is the euclidian distance, but other functions are also possible. We used as distance functions for our models the euclidian distance squared, and the cossine distance. Here are the training graphs:

Image 8 - Euclidian Distance Squared Triplet over training. Blue line is validation data, and orange is training
| Set | Pos Dist Mean | Neg Dist Mean | Triplet Loss Mean |
|---|---|---|---|
| Train | 0.5728581547737122 | 1.745187759399414 | 0.22523514926433563 |
| Val | 0.6698782444000244 | 1.7403087615966797 | 0.2757253348827362 |
Table 6 - Distances Using The Euclidian Distance Squared

Image 9 - Cosine Distance Triplet over training. Green line is validation data, and pink is training
| Set | Pos Dist Mean | Neg Dist Mean | Triplet Loss Mean |
|---|---|---|---|
| Train | 0.445333868265152 | 0.8501749038696289 | 0.595158576965332 |
| Val | 0.4381791949272156 | 0.8464183807373047 | 0.59176105260849 |
Table 7 - Distances Using The Cosine Distance
After training the feature extractor with the triplet loss, we simply set the average of the mean positive distances and the mean negative distances as a threshold. If two vectors have a distance smaller than the threshold, they are considered as belonging to the same person, and to different people otherwise. We used this as a classifier and extracted some metrics.
| Set | Binary Accuracy | Precision | Recall | True Negatives | False Positives | False Negatives | True Positives |
|---|---|---|---|---|---|---|---|
| Train | 0.8604687452316284 | 0.871737003326416 | 0.8453124761581421 | 14010.0 | 1990.0 | 2475.0 | 13525.0 |
| Val | 0.8305624723434448 | 0.8596084117889404 | 0.7892890572547913 | 13977.0 | 2058.0 | 3364.0 | 12601.0 |
Table 8 - Classifier Using The Euclidian Distance
| Set | Binary Accuracy | Precision | Recall | True Negatives | False Positives | False Negatives | True Positives |
|---|---|---|---|---|---|---|---|
| Train | 0.7213125228881836 | 0.7808796763420105 | 0.6143545508384705 | 13264.0 | 2755.0 | 6163.0 | 9818.0 |
| Val | 0.722406268119812 | 0.77568119764328 | 0.6221036314964294 | 13210.0 | 2865.0 | 6018.0 | 9907.0 |
Table 9 - Classifier Using The Cosine Distance
With regard to the segmentation aspect of the project, our final models showed good performance. They were both faster and more precise then OpenCV's. However, our models only detect a single face in an image, not multiple like OpenCV's. This is suitable for many situations, for example unlocking a phone, but not all situations, for example monitoring a street.
For the segmentation, we had 4 final models, as combinations of being trained using the translation augmentation, and using the depthwise separable convolutions. The augmented models had a worse performance in the dataset, but probably have a better performance in a real-world scenario, but we can't test it at this moment. The models using depthwise separable convolutions have slightly worse performance, but much lower computational cost, therefore they are more suited for situations where low computational cost and response time are more relevant, such as real-time segmentation, and embedded systems.
With regards to the verification aspect of the project, our final models showed good performance but could be better, with the euclidian distance model showing better performance. We focused more on the former aspect of the project, so our verification is not as refined. One major improvement would be to define the distance threshold in a more sophisticated way. The way we are currently doing doesn't take into consideration the distance distribution as a whole, just the mean. Still, the verification works quite well. One notable failure is with occlusion, as shown in the images below.
One major block in our project, especially for the verification part, was training time. We had many different models, and each one took very long to train and evaluate. The euclidian distance triplet model, for example, took more than 24 hours to train. As such, with more available time we would be able to do more experimentation and achieve better results.

Image 10 - Bounding Box Detection Example

Image 11.1 - Succesful Verification

Image 11.2 - Succesful Verification at an Angle

Image 12.1 - Unsuccessful Verification with Little Occlusion

Image 12.2 - Unsuccessful Verification with High Occlusion
These images were extracted using this jupyter notebook. It is a sample where our models are run using a webcam as input. For the notebook to work, the environment defined in env.yml must be installed, using conda, and the trained models must be downloaded separately.
We also developed a very simple sample jupyter notebook, just executing our models on a few images present on this README. Same as the previous one, the environment in env.yml must be installed, and the trained models must be downloaded.
All trained models are available at our Google Drive (the files were too big to add to this repository). All the metrics CSV's are available at experiments/results.
All the metrics obtained during training are visible through tensorboard, at experiments/tensorboard_logs. This jupyter notebook has the graphs already loaded.
-
Eduardo Santos Carlos de Souza (NUSP 9293481)
- Wrote model building code
- Wrote model training code
- Wrote data generators for training
- Organized the data
- Ran many experiments
- Wrote camera code sample
- Wrote tensorboard sample
- Wrote tests to several scripts
-
Guilherme Hideo Tubone (NUSP 9019403)
- Wrote face detection using OpenCV, and its code sample
- Implemented Canny Edge Detector and its code sample
- Created benchmarks to measure running time
- Measured intersection-over-union and mean absolute error for the OpenCV model
- Implemented data augmentation of translation and rotation
- Ran some training experiments
Keywords: Image Segmentation; Feature Learning; Deep Learning; Faces; Face Verification; Triplet Loss;