- 优化了背景剔除功能,原以正矩形为边界,现为任意四边形。
- 背景剔除时如果仅保留标点四点凸包区域效果不佳,建议尽量保留完整数字或图案。
- 添加了红点和大弹丸遮挡的数据增强
-
修复了使用mean均值计算最小外接正框中心点的错误
-
四点坐标八个位置同时参与最小外接正框iou损失和关键点回归损失,或会导致一些情况下很难收敛,例如矿石识别和矿石兑换框识别180°旋转增强下的训练(识别整个面,可能问题原因是目标大且少)。而收敛后或能提高回归精度,具体体现为,yolo-face格式下(四个位置负责最小外接正框iou损失,另外八个位置负责关键点回归损失),容易收敛(能做出兑换框(角标)),但点回归并没有本代码准。
主要修改了以下几个部分:
- 修复了不能进行 不选mosaic数据增强 的训练,目的:数据增强能出现更多大目标,结果:mosaic概率参数可调范围[0.0,1.0]
- 所有灰色像素[114,114,114] (出现于数据增强时填充空余区域) 均修改为coco负样本,目的:增加背景环境鲁棒性
- 添加edge_clip操作,将数据集中除装甲板外的背景全部剔除,目的:去除装甲板和车或前哨站本身之类的关联,结果:edge_clip概率参数可调范围[0.0,1.0]
- 删除augmentations.py->random_perspective函数中.clip(0, width)操作,使关键点可超出图像, 目的:适应未来调小roi的操作
- 重新使用了yolov5s尺寸的模型,模型训练收敛更快,连续帧关键点识别更稳定;在AGX及NX上均能稳100帧,NX需有功率模式8(刷机版本4.6.2+)
- 不使用int8部署(精度不正常)
针对robomaster装甲板自瞄修改后的YOLOv5-6.0目标检测网络,主要修改了以下几个部分:
-
将外接矩形表示的目标修改为用装甲板4个顶点表示目标。修改了loss函数,改成关键点检测。同时修改了数据集的加载方式。
-
将目标分类从多个类别分为一类改成从多个类别分为两类,即颜色分一次类,图案标签分一次类。
-
将COCO数据集作为负样本,加入训练数据中,可以起到降低误识别的作用。
-
使用了yolov5n尺寸的模型
-
不使用int8部署(精度不正常)
-
model/yolo.py Detect类中增加设置网络输出尺寸参数(在数据集yaml文件中设置),结果:废弃cut.py
-
export.py 输出两个onnx分别用于Tensorrt部署和openvino部署
数据集yaml文件
train: /cluster/home/it_stu3/Data/RM-keypoint-4-9-Oplus/images #图片路径
val: /cluster/home/it_stu3/Data/RM-keypoint-4-9-Oplus/images #图片路径
nc: 36 #class种类数:4*9
np: 4 #关键点个数
colors: 4 #颜色种类数
tags: 9 #标签种类数
names: ['BG', 'B1', 'B2', 'B3', 'B4', 'B5', 'BO', 'BBs', 'BBb',
'RG', 'R1', 'R2', 'R3', 'R4', 'R5', 'RO', 'RBs', 'RBb',
'NG', 'N1', 'N2', 'N3', 'N4', 'N5', 'NO', 'NBs', 'NBb',
'PG', 'P1', 'P2', 'P3', 'P4', 'P5', 'PO', 'PBs', 'PBb',] #种类命名
date: '2022/6/18' #最后修改日期训练
python3 train.py
--weights '' # 加载预训练模型(不建议使用官方预训练,有cfg就可)
--cfg 'models/yolov5s.yaml' # 网络结构定义
--data '~/Data/RM-keypoint-4-9-Oplus/armor.yaml' # 训练数据文件
--hyp 'data/RM.armor.yaml' # 训练参数文件
--epochs 500 # 训练500代(根据实际情况修改)
--batch-size 16 # 单次数据量(报错显存不足则需要降低)
--img-size 640 # 训练图片大小
--noval # 关闭模型评估(4点模型val的代码没有做修改,用不了)
--adam # 使用Adam优化器
--workers 16 # 16进程并行加载数据集(根据电脑的CPU量进行修改)
--negative-path ~/Data/COCO/unlabeled2017/ # 负样本文件夹(支持指定多个负样本文件夹,空格隔开即可)种类数裁剪(已废弃)
python3 cut.py # 对训练后的模型进行裁剪(修改cut.py中的.pt路径)测试/识别
python3 detect.py
--weights runs/train/exp/weights/best.pt # 训练后得到的权重文件
--source ~/data/images # 需要识别的视频文件
--img-size 640 # 输入网络的图片大小
--view-img # 实时显示识别结果模型转化/部署
python3 cut.py #(已废弃) 对训练后的模型进行裁剪(修改cut.py中的.pt路径)
python3 models/export.py
--weights runs/train/exp/weights/best.pt # 裁剪后得到的文件
--img-size 384 640 # 输入分辨率(a,b),(a,b)为_trt分辨率;(b,b)为_cv分辨率
# 到此得到两份onnx文件,最好在部署前能进行onnx-simplify进行简化
# 其中*_trt.onnx为用于Tensorrt部署的文件,*_cv.onnx为用于openvino部署的文件与YOLOv5-5.0的对比:
- 关键点回归精度更高
- 同尺寸模型,在AGX上进行trt部署后耗时缩减15%



YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.
See the YOLOv5 Docs for full documentation on training, testing and deployment.
Install
Python>=3.6.0 is required with all requirements.txt installed including PyTorch>=1.7:
$ git clone https://github.com/ultralytics/yolov5
$ cd yolov5
$ pip install -r requirements.txtInference
Inference with YOLOv5 and PyTorch Hub. Models automatically download from the latest YOLOv5 release.
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5l, yolov5x, custom
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.Inference with detect.py
detect.py runs inference on a variety of sources, downloading models automatically from
the latest YOLOv5 release and saving results to runs/detect.
$ python detect.py --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/NUsoVlDFqZg' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streamTraining
Run commands below to reproduce results
on COCO dataset (dataset auto-downloads on
first use). Training times for YOLOv5s/m/l/x are 2/4/6/8 days on a single V100 (multi-GPU times faster). Use the
largest --batch-size your GPU allows (batch sizes shown for 16 GB devices).
$ python train.py --data coco.yaml --cfg yolov5s.yaml --weights '' --batch-size 64
yolov5m 40
yolov5l 24
yolov5x 16
Tutorials
- Train Custom Data 🚀 RECOMMENDED
- Tips for Best Training Results ☘️ RECOMMENDED
- Weights & Biases Logging 🌟 NEW
- Roboflow for Datasets, Labeling, and Active Learning 🌟 NEW
- Multi-GPU Training
- PyTorch Hub ⭐ NEW
- TorchScript, ONNX, CoreML Export 🚀
- Test-Time Augmentation (TTA)
- Model Ensembling
- Model Pruning/Sparsity
- Hyperparameter Evolution
- Transfer Learning with Frozen Layers ⭐ NEW
- TensorRT Deployment
Get started in seconds with our verified environments. Click each icon below for details.
| Weights and Biases | Roboflow ⭐ NEW |
|---|---|
| Automatically track and visualize all your YOLOv5 training runs in the cloud with Weights & Biases | Label and automatically export your custom datasets directly to YOLOv5 for training with Roboflow |
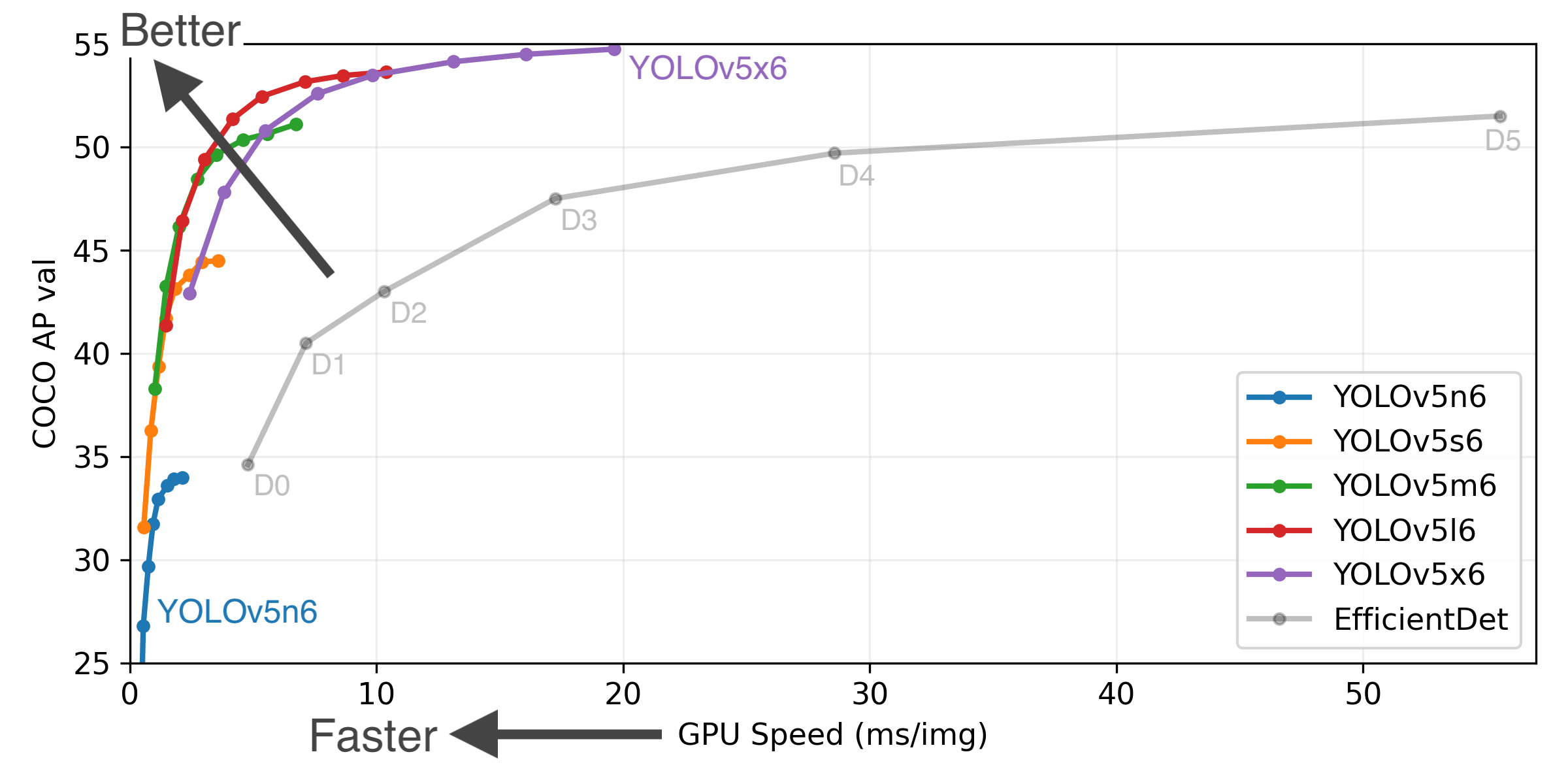
YOLOv5-P5 640 Figure (click to expand)
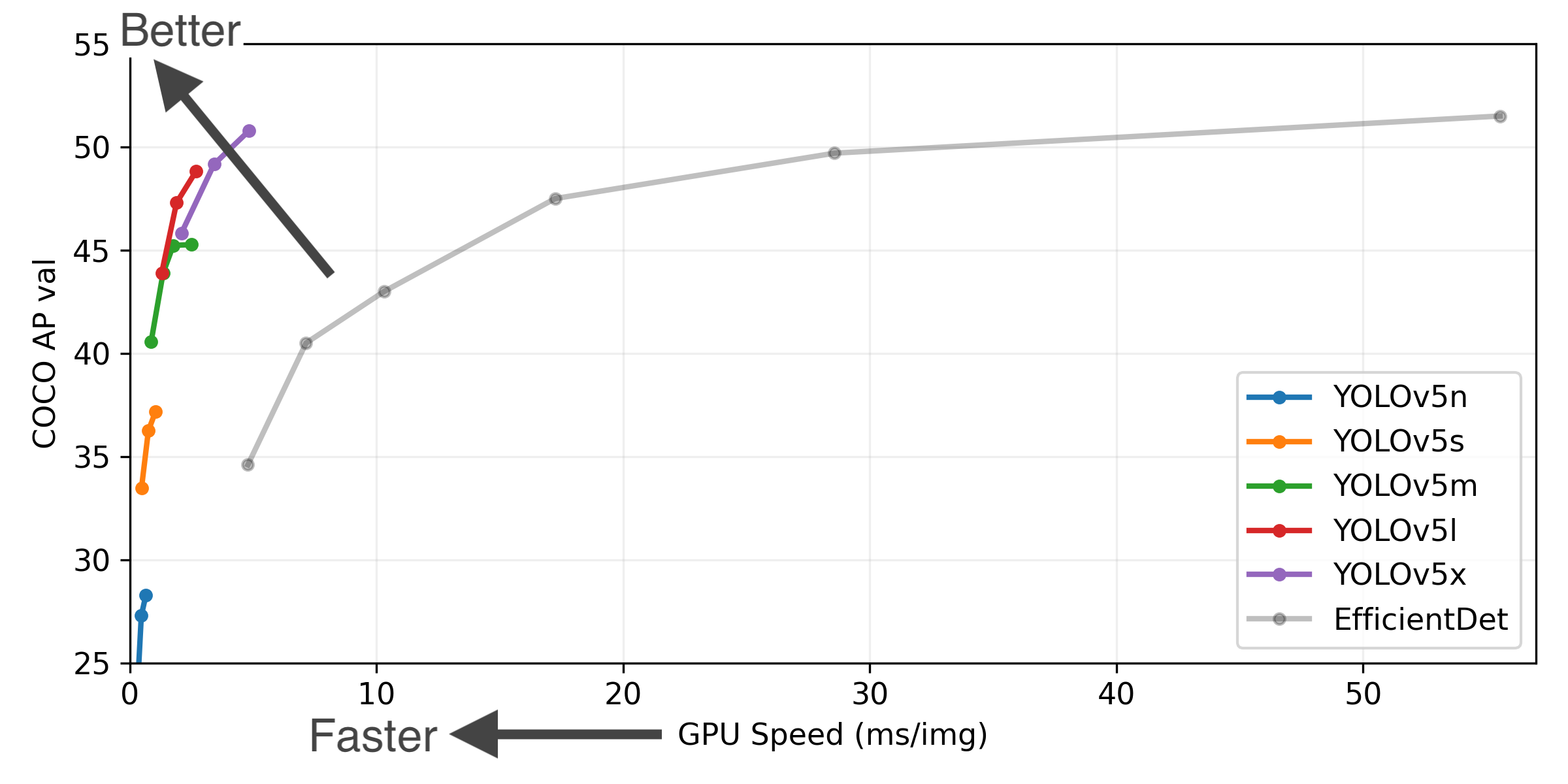
Figure Notes (click to expand)
- COCO AP val denotes [email protected]:0.95 metric measured on the 5000-image COCO val2017 dataset over various inference sizes from 256 to 1536.
- GPU Speed measures average inference time per image on COCO val2017 dataset using a AWS p3.2xlarge V100 instance at batch-size 32.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.4 | 46.0 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.2 | 56.0 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.2 | 63.9 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 48.8 | 67.2 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 34.0 | 50.7 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.5 | 63.0 | 385 | 8.2 | 3.6 | 16.8 | 12.6 |
| YOLOv5m6 | 1280 | 51.0 | 69.0 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.6 | 71.6 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA |
1280 1536 |
54.7 55.4 |
72.4 72.3 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
Table Notes (click to expand)
- All checkpoints are trained to 300 epochs with default settings and hyperparameters.
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - Speed averaged over COCO val images using a AWS p3.2xlarge instance. NMS times (~1 ms/img) not included.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45 - TTA Test Time Augmentation includes reflection and scale augmentations.
Reproduce bypython val.py --data coco.yaml --img 1536 --iou 0.7 --augment
We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible. Please see our Contributing Guide to get started, and fill out the YOLOv5 Survey to provide thoughts and feedback on your experience with YOLOv5. Thank you!
For issues running YOLOv5 please visit GitHub Issues. For business or professional support requests please visit https://ultralytics.com/contact.