![]()
![]()
AmsterdamUMCdb is the first freely accessible European intensive care database. It is endorsed by the European Society of Intensive Care Medicine (ESICM) and its Data Science Section. It contains de-identified health data related to tens of thousands of intensive care unit admissions, including demographics, vital signs, laboratory tests and medications.
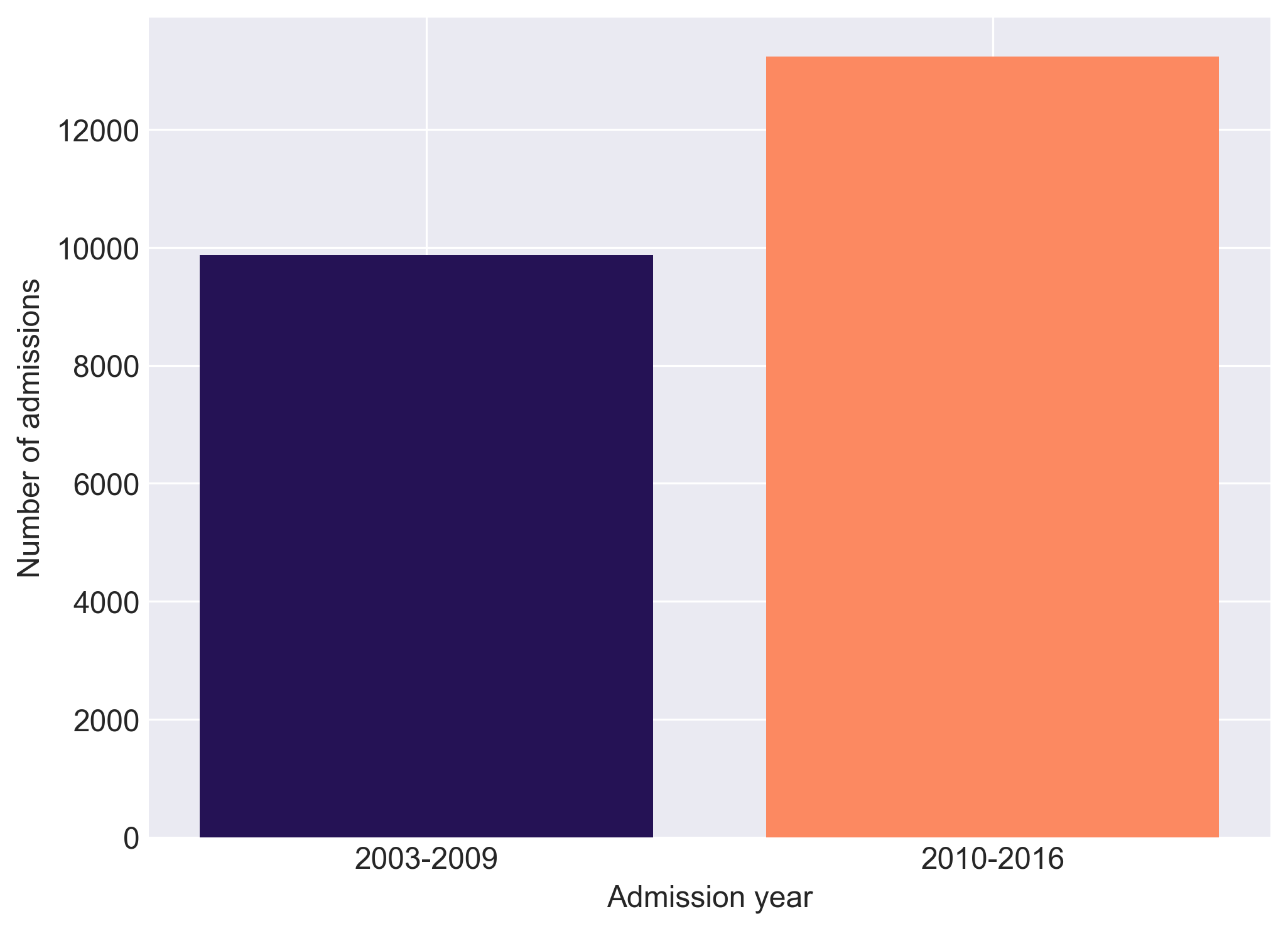
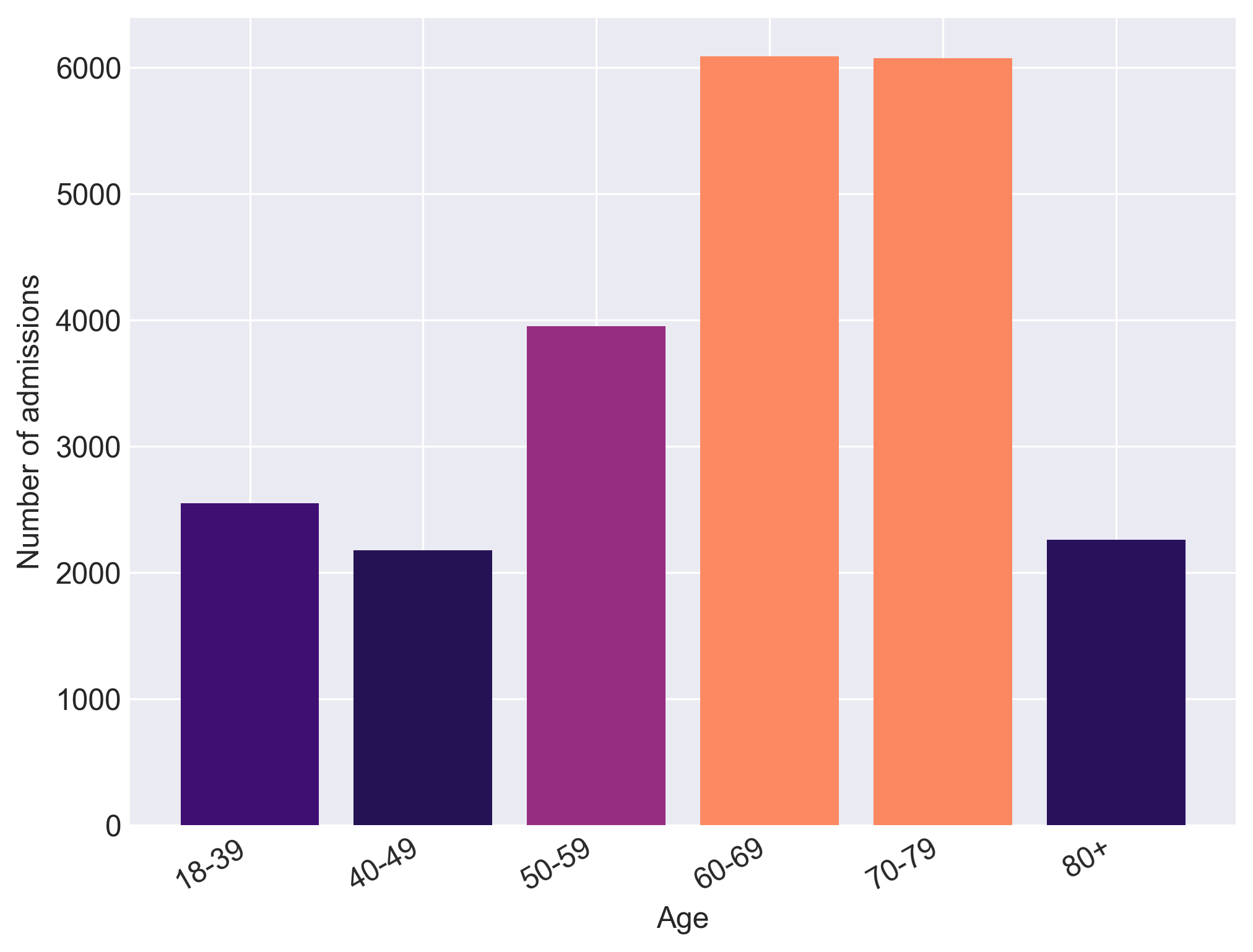
The current version of AmsterdamUMCdb is 1.0.2, released in March 2020. This version contains data related to 23,106 intensive care unit and high dependency unit admissions of adult patients from 2003-2016. The first version of AmsterdamUMCdb (1.0) was released in November 2019.
The database, although de-identified, still contains detailed information regarding the clinical care of patients, so must be treated with appropriate care and respect and cannot be shared without permission. To request access, go to the Amsterdam Medical Data Science website.
When using AmsterdamUMCdb in your research, please cite:
Thoral, P. J., Peppink, J. M., Driessen, R. H., Sijbrands, E. J. G., Kompanje, E. J. O., Kaplan, L., Bailey, H., Kesecioglu, J., Cecconi, M., Churpek, M., Clermont, G., van der Schaar, M., Ercole, A., Girbes, A. R. J., Elbers, P. W. G., on behalf of the Amsterdam University Medical Centers Database (AmsterdamUMCdb) Collaborators and the SCCM/ESICM Joint Data Science Task Force (2021). Sharing ICU Patient Data Responsibly Under the Society of Critical Care Medicine/European Society of Intensive Care Medicine Joint Data Science Collaboration: The Amsterdam University Medical Centers Database (AmsterdamUMCdb) Example. Crit Care Med. 2021 Jun 1;49(6):e563-e577. doi: 10.1097/CCM.0000000000004916. PMID: 33625129; PMCID: PMC8132908.
The current database contains data from the clinical patient data management system of the department of Intensive Care, a mixed medical-surgical ICU, from Amsterdam University Medical Center. The clinical data contains 23,106 admissions of 20,109 patients admitted from 2003 to 2016 with a total of almost 1.0 billion clinical observations consisting of vitals, clinical scoring systems, device data and lab results data and nearly 5.0 million medication records.
The table and field definitions are available from the AmsterdamUMCdb wiki and from Jupyter Notebooks in the tables folder.
| Table name | Description |
|---|---|
| admissions | admissions and demographic data of the patients admitted to the ICU or MCU |
| drugitems | medication orders including fluids, (parenteral) feeding and blood transfusions during the stay on the ICU |
| freetextitems | observations, including laboratory results, that are based on non-numeric (text) data |
| listitems | categorial observations, e.g. based on a selection from a list, like type of heart rhytm, ventilatory mode, etc. |
| numericitems | numerical measurements and observations, including vital parameters, data from medical devices, lab results, outputs from drains and foley-catheters, scores etc. |
| procedureorderitems | procedures and tasks, such as performing a chest X-ray, drawing blood and daily ICU nursing care and scoring |
| processitems | catheters, drains, tubes, and continous non-medication processes (e.g. renal replacement therapy, hypothermia induction, etc.) |
The amsterdamumcdb Python package contains common functions for working with the database.
Gets a dictionary of all items in AmsterdamUMCdb with translated medical concepts mapped to LOINC, SNOMED CT or ATC (work in progress).
- Returns:
- dataframe containing dictionary
Calculate the fluid balance (i.e. fluid input - fluid output) for a specific time interval. Typically this will be used to calculate daily fluid balances.
- Arguments:
- admissionid -- the admissionid of ICU admission
- from_date -- the start of the interval, expressed as the number of milliseconds from start of this ICU admission
- to_date -- the end of the interval, expressed as the number of milliseconds from start of this ICU admission
- con -- psycopg2 connection or pandas-gbq Google BigQuery config
amsterdamumcdb.outliers_histogram(data, z_threshold=4.0, lower=None, upper=None, bins=None, binwidth=None, maxbins=None):
Return a pyplot histogram, where the upper and/or lower outliers are binned together for a more even distribution plot. By default, the histogram will be created with bins that are on boundaries aligned with the pyplot axis ticks.
- Arguments:
- data -- dataframe to create the histogram for.
- z_threshold (Optional) -- number of standard deviations from the median to determine outliers
- lower (Optional) -- lower threshold for binning lower outliers together
- upper (Optional) -- upper threshold for binning higher outliers together
- bins (Optional) -- int or sequence or str, allows specifying the number of bins, the actual bins or a binning strategy (see: https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.hist.html)
- binwidth (Optional) -- forces a specified size of the equally sized bins between the lower and upper threshold
- maxbins -- the maximum number of equally sized bins to create
- unified PostgreSQL and BigQuery processing
- Fixed filtering based boolean indexing using
np.NaN(pandas default) andpd.NA(used by pandas-gbq since the default isInt64) leading to different results, particularly when finding the complement using negation. - Added unit tests for the cohorts. Forces
pd.Nato be consideredFalseduring comparisons. - By default, uses only validated data for
amsterdamumcdbfunctions for consistent PostgreSQL and BigQuery results. - Removed aggregation in SQL code of Glasgow Coma Scale (GCS) in line with other functions.
- Update SOFA GCS processing for more accurate scoring
- Added rounding to 1 decimal for conversions (from
kPatommHg) in SQL statements - Updated deprecated matplotlib style (
seaborn-darkgrid) - Update engine to SQLAlchemy for official pandas support instead of direct psycopg2 connection
- Moved code from Jupyter
reason_for_admission.ipynbnotebook intoamsterdamumcdb.cohortsmodule.
- added sample cohorts (sepsis-3, mechanical ventilation, shock) in
cohorts.py - added SOFA scoring to
scores.py - util functions for PostgresSQL to BigQuery translation
- move SQL code from notebooks to separate SQL files
- dictionary: as part of the
ICUnityproject in preparation for the The Dutch ICU Data Warehouse a number of commonly used items have been mapped to LOINC , SNOMED CT or ATC with data in thevocabulary_id,vocabulary_concept_code,vocabulary_concept_namecolumns. - dictionary: UCUM units added
- fixes binning in
outliers_histogram()when all values < 1
- Improves binning in
outliers_histogram()
- Allows negative dates in
get_fluidbalance()
- Fixes Google BigQuery
Project must be a stringerror.
- initial release for ESICM Datathon 2021