로그스태시를 활용하여 로그분석을 통한 실시간 인기 검색어 순위

2023.12.15 ~ 2024.01.12 동안 "인터파크 티켓"을 타겟으로 하여 클론코딩을 진행하게 되었는데, "공연" 도메인을 맡게 되었다. 함께 도메인을 담당하게 된 팀원과 어떤 기술을 적용해보면 좋을까를 의논하던 중 "인터파크 티켓" 사이트 검색창에 실시간 검색어가 나오는 것을 볼 수 있었다. 검색 기능을 중점적으로 구현하는 방향으로 계획을 세웠고 기존에 JPA를 통한 검색 로직만 구현해보다가, 검색 기능에 특화된 Elasticsearch를 적용하여 키워드 검색 기능 + 실시간 인기 검색어 순위 기능을 구현해보자. 라는 결론이 나오게 되었다. 그래서 이번 포스팅에서는 Elasticsearch를 적용하여 실시간 인기 검색어 순위를 구현한 그 여정을 기록해보려고 한다.
먼저 엘라스틱서치를 도입하게 된 근본적인 이유를 살펴보자면, 해당 프로젝트에 사용하던 RDB인 MySQL의 특정 문자포함 검색기능인 Like 함수를 사용해도 키워드 검색을 충분히 구현할 수 있고, 실시간 인기 검색어 순위 기능 또한 연관지어 구현할 수 있을 것 같다고 생각했다. 하지만 다수의 사용자가 있다고 가정했을 때, Like 함수를 "%키워드%"와 같이 사용하게 되었을 때 Full Scan 방식으로 동작하기 때문에 성능상 문제가 있을 것 같다는 생각이 들었고, 검색 성능에 최적화 된 Elasticsearch를 이용하여 구현하자. 라는 결론이 나오게 되었다.
그렇다면 실시간 인기 검색어 순위 기능을 어떻게 구현할 수 있을까 ? 가장 처음 생각했던 방법은 Spring Batch를 이용하여 특정 시간마다 Job을 수행하여 인기 검색어를 분석하는 방식을 고안했지만 다른 방안으로 ELK 스택중 로그 수집이 가능한 Logstash를 이용하여 Elasticsearch에 애플리케이션 액세스 로그를 넣어주고 이를 분석하는 방식으로 구현할 수 있겠다고 생각하였다.
배포 환경에서 구현을 위해서는 Nginx, Logstash, Filebeat, Elasticsearch 구성으로 구현을 해야 하지만, 아쉽게도 해당 프로젝트는 배포를 하지 않기 때문에 우선은 로컬에서 기능이 돌아가도록 구현하기 위해 Spring Boot -> Elasticsearch로 로그를 전송하고 이를 특정 시간을 기준으로 top 10 검색어를 뽑아오는 것을 구현하기로 결정했다. 그렇다면 이제 구현 과정을 살펴보자. (ELK 스택 설치 및 세팅 과정은 생략하겠음.)
(1) 로그 설정
[ 의존성 추가 - build.gradle ]
implementation 'net.logstash.logback:logstash-logback-encoder:6.6'[ logback-spring.xml 파일 설정 ]
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
*<!-- Console -->*<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{10} - %msg%n</pattern>
</encoder>
</appender>
*<!-- Logstash -->*<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:5001</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
</encoder>
</appender>
<root level="info">
<appender-ref ref="CONSOLE" />
<appender-ref ref="LOGSTASH" />
</root>
</configuration>다음으로, 로그가 넘어갈 때 포맷을 지정하기 위해 logstash를 설정하도록 하자.
${압축푼경로}/config 경로에 exmaple.config를 다음 내용으로 만듭니다.
vi example.config
input {
stdin {}
}
output {
stdout {}
}다음으로, logstash의 config 파일도 변경해주자.
input{
tcp {
port => 5000
codec => json_lines }
}
output {
elasticsearch {
hosts => ["es:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}[ input ]
- tcp 설정으로 Logstash가 TCP 프로토콜을 사용해 데이터를 수신한다는 것을 의미
- port => 5000은 Logstash가 5000번 포트에서 TCP 연결을 기다리며 데이터를 수신한다는 것을 나타냄
- codec => json_lines 는 수신된 데이터가 JSON 형식이라는 것을 나타냄
[ output ]
- elasticsearch는 Logstash에서 Elasticsearch로 데이터를 전송한다는 것을 나타냄
- hosts => ["es:9200"]는 Elasticsearch 클러스터의 호스트 & 포트를 지정
- index => "logstash-%{+YYYY.MM.dd}"는 색인을 저장할 Elasticsearch 인덱스의 이름을 정의함
파이프라인까지 설정했다면, 거의 완료한 상태인데 이제 로그를 매핑할 클래스를 만들면 Spring Boot와 ELK 연동이 가능해진다. 이후 NativeQuery를 이용하여 실시간 인기 검색어 구현에 필요한 쿼리만 작성해주면 끝이다. (버전업에 따라 Deprecated된 Query 관련 클래스들을 찾아서 적용하는데 꽤나 시간이 많이 걸렸던 것 같다...ㅠ)
(2) 로그 저장
public Page<EventDocumentResponse> findByKeyword(EventKeywordSearchDto eventKeywordSearchDto) {
Pageable pageable = eventKeywordSearchDto.pageable();
NativeQuery query = getKeywordSearchNativeQuery(eventKeywordSearchDto).setPageable(pageable);
SearchHits<EventDocument> searchHits = elasticsearchOperations.search(query, EventDocument.class);
log.info("event-keyword-search, {}", eventKeywordSearchDto.keyword());
return SearchHitSupport.searchPageFor(searchHits, query.getPageable()).map(s -> {
EventDocument eventDocument = s.getContent();
return EventDocumentResponse.of(eventDocument);
});
}먼저 Elasticsearch에 로그를 저장하는 과정이 필요했는데, 키워드 검색 메소드가 실행될 때 "event-keyword-search, {keyword}" 형태로 로그가 저장되도록 하였다.
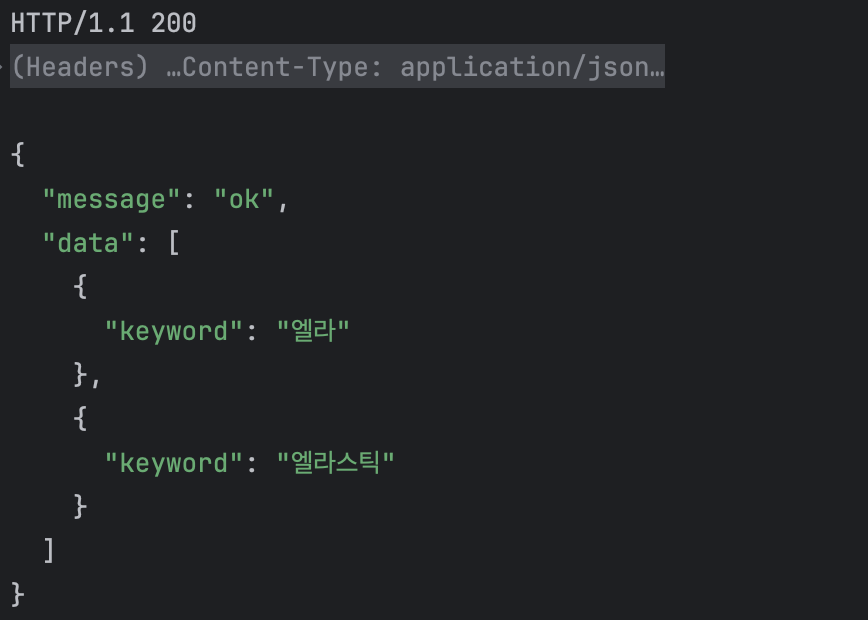
그럼 이제 로그가 잘 저장되는지를 확인해보자. (keyword = '엘라', '엘라스틱'으로 검색)
POST <index 명>/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "event-keyword-search"
}
},
{
"term": {
"logger_name.keyword": "com.pgms.coreinfraes.repository.EventSearchQueryRepository"
}
}
]
}
}
}애플리케이션 액세스 로그가 모두 저장되기 때문에 message와 logger_name으로 키워드 검색 로직 수행 시 저장되는 로그만 가져오도록 필터링 처리를 하여 검색한다.
[ 결과 ]
"hits": [
{
"_index": "logstash-2024.01.17",
"_id": "Ez5KFY0BPjGDOVSF6z37",
"_score": 17.531075,
"_source": {
"thread_name": "http-nio-8080-exec-1",
"message": "event-keyword-search, 엘라스틱",
"level": "INFO",
"@timestamp": "2024-01-17T02:40:47.801Z",
"@version": "1",
"logger_name": "com.pgms.coreinfraes.repository.EventSearchQueryRepository",
"level_value": 20000
}
},
{
"_index": "logstash-2024.01.17",
"_id": "Fj5LFY0BPjGDOVSFMz2Q",
"_score": 17.531075,
"_source": {
"thread_name": "http-nio-8080-exec-3",
"message": "event-keyword-search, 엘라",
"level": "INFO",
"@timestamp": "2024-01-17T02:41:05.932Z",
"@version": "1",
"logger_name": "com.pgms.coreinfraes.repository.EventSearchQueryRepository",
"level_value": 20000
}
}
]여기까지 우리가 의도한대로, 키워드 검색시 해당 키워드에 대한 로그를 저장하고 이를 잘 가져오는 것을 확인할 수 있다. 이제 Top 10 키워드를 뽑아오는 로직을 고도화하여 구현하는 작업을 진행하면 된다. 실시간 검색어 알고리즘 같은 경우 따로 구현하는 방식이 존재한다고 하지만, 우선은 사용자가 없기도 하고 로컬환경에서 테스트를 위해 간단히 키워드별로 집계하고, 검색 횟수를 카운트하여 10개의 상위 검색어를 반환하도록 로직을 구현했다.
(3) Top 10 인기 검색어 순위 구현
public List<TopTenSearchResponse> getRecentTop10Keywords() {
NativeQuery searchQuery = getRecentTop10KeywordsNativeQuery();
SearchHits<AccessLogDocument> searchHits = elasticsearchOperations.search(searchQuery, AccessLogDocument.class,
IndexCoordinates.of("logstash*"));
ElasticsearchAggregations aggregations = (ElasticsearchAggregations)searchHits.getAggregations();
assert aggregations != null;
List<StringTermsBucket> topTenBuckets = aggregations.aggregationsAsMap()
.get("top_ten")
.aggregation()
.getAggregate()
.sterms()
.buckets()
.array();
List<TopTenSearchResponse> result = new ArrayList<>();
topTenBuckets.forEach(topTenBucket -> {
TopTenSearchResponse topTenSearchResponse = new TopTenSearchResponse(topTenBucket.key().stringValue(),
topTenBucket.docCount());
result.add(topTenSearchResponse);
});
return result;
}-
getRecentTop10KeywordsNativeQuery() 메소드를 통해 검색 쿼리를 생성한다.
-
elasticsearchOperations.search 메소드를 실행하여 Elasticsearch에 쿼리 전송 및 결과를 얻어온다.
-
Aggregation을 이용해 상위 10개 검색어 그룹 및 통계치를 포함하는 StringTermsBucket 객체를 리스트로 가져온다.
-
topTenBuckets를 순회하며 각 검색어와 해당 검색어의 카운트 수를 기반으로 응답 객체로 변환하여 리스트에 추가한다.
private NativeQuery getRecentTop10KeywordsNativeQuery() {
NativeQueryBuilder queryBuilder = new NativeQueryBuilder();
Query matchQuery = QueryBuilders.match()
.field("message")
.query("event-keyword-search")
.build()
._toQuery();
Query loggerQuery = QueryBuilders.term()
.field("logger_name.keyword")
.value("com.pgms.coreinfraes.repository.EventSearchQueryRepository")
.build()
._toQuery();
Query rangeQuery = QueryBuilders.range()
.field("@timestamp")
.gte(JsonData.of(LocalDateTime.now()
.truncatedTo(ChronoUnit.HOURS)
.atZone(ZoneId.systemDefault())
.toInstant()
.toEpochMilli()))
.lte(JsonData.of(LocalDateTime.now().atZone(ZoneId.systemDefault()).toInstant().toEpochMilli()))
.build()
._toQuery();
Script script = Script.of(scriptBuilder -> scriptBuilder.inline(inlineScriptBuilder ->
inlineScriptBuilder.lang(ScriptLanguage.Painless)
.source("doc['message.keyword'].value.substring(22);")
.params(Collections.emptyMap())
));
Aggregation agg = AggregationBuilders.terms()
.script(script)
.size(10)
.build()
._toAggregation();
Query boolQuery = QueryBuilders.bool()
.must(matchQuery, loggerQuery, rangeQuery)
.build()
._toQuery();
ScriptedField scriptedField = new ScriptedField("search_keyword", new ScriptData(
ScriptType.INLINE,
"painless",
"return doc['message.keyword'].value.substring(22);",
"keyword_script",
Collections.emptyMap()
));
SourceFilter sourceFilter = new FetchSourceFilter(new String[] {"*"}, new String[] {});
return queryBuilder.withQuery(boolQuery)
.withSourceFilter(sourceFilter)
.withScriptedField(scriptedField)
.withAggregation("top_ten", agg)
.build();
}쿼리 생성 로직에서 핵심은
1. matchQuery : log message가 키워드 검색 로그와 일치하는지 확인
2. loggerQuery : term 쿼리를 사용하여 키워드 검색 로그와 일치하는지 확인
3. rangeQuery : @timestamp 필드에 대한 현재 시간을 기준으로 한 시간 단위의 범위 쿼리를 생성 및 적용
4. scriptField : event-keyword-search, {keyword} 로 저장되는 로그 메시지에서 keyword만 추출하여 별도 저장
5. aggregation : 결과를 바탕으로 키워드 별 집계 실행
쿼리까지 구현을 했으니, 이제 Top 10 인기 검색어 기능을 실행해보면 ? (엘라 2번, 엘라스틱 1번)
!https://blog.kakaocdn.net/dn/s5vsD/btsDxTP5X2n/hcoT6DKRPaKxK910sV2rD0/img.png
{kind=link}
검색 결과가 많은 순서로 인기 검색어 순위가 출력되는 것을 확인할 수 있었다.
구현하면서 가장 어려웠던 점은, 우선 ELK 8.5.3 버전을 사용하였는데 버전에 따른 문서를 찾는 것이 가장 힘들었던 것 같다. 6~7 버전의 문서들이나 자료들은 꽤나 많았던 것 같은데.. 생각만 하고 적용하지 못한 부분들도 많지만 이후에 개선해보려고 노력해봐야겠다.
[https://velog.io/@dktlsk6/Spring-boot-ElasticSearch-연동-하여-실시간-검색-순위-구현하기](https://velog.io/@dktlsk6/Spring-boot-ElasticSearch-%EC%97%B0%EB%8F%99-%ED%95%98%EC%97%AC-%EC%8B%A4%EC%8B%9C%EA%B0%84-%EA%B2%80%EC%83%89-%EC%88%9C%EC%9C%84-%EA%B5%AC%ED%98%84%ED%95%98%EA%B8%B0)