Paddle对Pruning以及Mobilenet的支持
关于对pruning以及mobilenet的模型测试可以到 https://github.com/NHZlX/PaddleModelZoo 下载
Static pruning Dynamic pruning Sparse forward acceleration Mobilenet
Static pruning是对一个已经训练好的模型任务上进行fine-tune。对于一个带参数的层(
conv or Fc)指定一个稀疏度(sparsity_ratio)。在网络fine-tune开始前,将该层的参数的绝对值进行排序,根据稀疏度(sparsity_ratio)将较小的参数给剪切掉,然后进行fine-tune。整个pruning的过程分为多个阶段,因为sparsity_ratio是逐步递增的, 每变化一次sparsity_ratio, 网络都要重新启动。关于pruning的更多信息,可以查看https://arxiv.org/pdf/1506.02626.pdf. pruning 之后可以进行稀疏加速,或者zip后也大大减少模型大小。
import paddle.v2 as paddle
from paddle.v2.attr import Hook
from paddle.v2.attr import ParamAttr
def Net(img):
# 采用staic pruning,采用的稀疏度(0元占比)为0.3
hk = Hook('pruning', sparsity_ratio=0.3)
net = paddle.layer.img_conv(
input=net, filter_size=3,
num_filters=512, stride=1,
padding=1,
param_attr = ParamAttr(update_hooks = hk))
hk1 = Hook('pruning', sparsity_ratio=0.5)
out = paddle.layer.fc(
input=net, size=classdim, act=paddle.activation.Softmax(),
param_attr = ParamAttr(update_hooks=hk1))
return out
首先用vgg16在paddle上预训练一个cifar10的model,精度为91.5%,Static pruning在此pre-trained的model上测试效果如下:conv1-2的参数0元占比0.5(一般第一、二层卷积的变化对整个网络的影响较大,所以我们采用较小的sparsity_ratio),conv3-conv12 稀疏度为80%, 全链接稀疏度为99%, pruning后的精度损失在一个点之内,pruning之前原始模型zip后大小为55M,pruning之后的模型zip后为14M(Dense format)。
| vgg 16 on cifar 10 | sparsity_ratio |
|---|---|
| Conv1-2 | 0.5 |
| Conv3-12 | 0.8 |
| Fc1-3 | 0.99 |
| vgg16 with static pruning accuracy | without |
|---|---|
| 90.7% | 91.5% |
特点是,因为网络参数的sparsity_ratio是不断上升的,因此必须多次启动网络进行fine-tune, 很耗时
PR中,https://github.com/PaddlePaddle/Paddle/pull/2603
so,如果想试用的话,git clone https://github.com/NHZlX/Paddle.git
并且 git checkout auto_pruning和
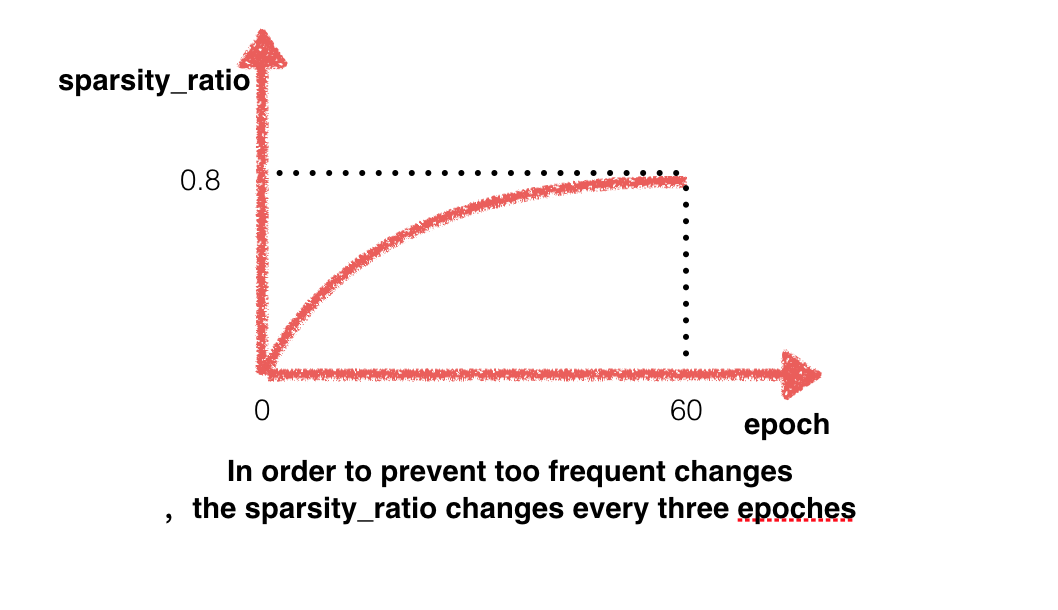
Static pruning不同的是,Dynamic pruning的整个fine-tune过程为一个阶段。Dynamic pruning是对一个已经训练好的模型任务上进行fine-tune。首先为每层指定一个稀疏度(sparsity_ratio)的upper_bound,表示该层最终要达到的稀疏度。从开始到训练结束,稀疏度从0逐渐增加到upper_ bound。为了避免稀疏度变化过于频繁, 每inter_pass个pass 变化一次(通过对一些数据集(flowers102 etc)测试,每次变化一次sparsity_ratio,inter_pass设置为3基本可以微调到好的效果,其他具体任务还得进一步测试),一共变化end_pass/inter_pass次,稀疏度(sparsity_ratio)变化的曲线如下
import paddle.v2 as paddle
from paddle.v2.attr import Hook
from paddle.v2.attr import ParamAttr
def Net(img):
#interval_pass=3 end_pass=60 为默认参数
#每interval_pass次pass变化一次稀疏度,一共变化end_pass/interval_pass = 20次, 最终达到稀疏度0.8
hk = Hook('dynamic_pruning', sparsity_upper_bound=0.8,
interval_pass=3, end_pass=60)
net = paddle.layer.img_conv(
input=net, filter_size=3,
num_filters=512, stride=1,
padding=1,
param_attr = ParamAttr(update_hooks = hk))
#表明最终达到0.95的稀疏度,inter_pass和end_pass采用默认值
hk1 = Hook('dynamic_pruning', sparsity_upper_bound=0.95)
out = paddle.layer.fc(
input=net, size=classdim, act=paddle.activation.Softmax(),
param_attr = ParamAttr(update_hooks=hk1))
return out
首先用vgg16在paddle上预训练一个cifar10的model,精度为91.5%,Dynamic pruning在此pre-trained的model上测试效果如下:conv1-2的参数0元占比0.6(一般第一、二层卷积的变化对整个网络的影响较大,所以我们采用较小的sparsity_ratio),conv3-conv12 稀疏度为83.1%, 全链接稀疏度为98.1%, pruning后的精度损失在一个点之内,pruning之前原始模型zip后大小为55M,pruning之后的模型zip后为13M(Dense format)。
| vgg 16 on cifar 10 | sparsity_ratio |
|---|---|
| Conv1-2 | 0.6 |
| Conv3-12 | 0.831 |
| Fc1-3 | 0.981 |
| vgg 16 with dynamic pruning accuracy | without |
|---|---|
| 90.93% | 91.5% |
首先用vggs在paddle上预训练一个flowers102的model,精度为95.3%,Dynamic pruning在此pre-trained的model上测试效果如下:conv1的参数0元占比0.5(一般第一层卷积的变化对整个网络的影响较大,所以我们采用较小的sparsity_ratio),conv2-conv5 稀疏度为81%, 全链接稀疏度为91%, pruning后的精度损失在一个点之内(Dense format)。
| vgg-s on flowers 102 | sparsity_ratio |
|---|---|
| Conv1 | 0.5 |
| Conv2-5 | 0.81 |
| Fc6-8 | 0.91 |
| vgg-s with dynamic pruning accuracy | without |
|---|---|
| 94.4% | 95.3% |
###Feature
特点是,sparsity_ratio变化程log曲线,前期变化较大,到后期网络参数都比较重要,如果后期大量的cut掉参数,网络比较难fine-tune到好的效果,所以后期cut参数幅度很小。第二,整个过程为一个阶段,中间不需要重新启动网络。
- FC 的稀疏度基本都可以达到90%以上,稀疏矩阵(
CSR format)乘法可以达到加速。
- 稀疏卷积加速: 对
“FASTER CNNS WITH DIRECT SPARSE CONVOLUTIONS AND GUIDED PRUNING”进行调研,稀疏度达到80%以上,direct convolution方式不同平台下可以有2.1-7倍加速。
特殊的convolution,其中groups == inputChannels, 传统的group convolution的方式很慢,需要对depthwise conv的实现加速 目前paddle 已经支持Depthwise Conv gpu训练加速
import paddle.v2 as paddle
### 和卷积同一接口, 如果num_groups == inputChannels 后台判断使用depthwise conv.
def depthwise_conv_bn_layer(input, filter_size, num_filters,
stride, padding, inputChannels=None, num_groups=None,
active_type=paddle.activation.Relu()):
"""
A wrapper for Depthwise conv layer with batch normalization layers.
Note:
conv layer has no activation.
"""
tmp = paddle.layer.img_conv(
input=input,
filter_size=filter_size,
num_channels=inputChannels,
num_filters=num_filters,
stride=stride,
padding=padding,
groups=num_groups,
act=paddle.activation.Linear(),
bias_attr=False)
return paddle.layer.batch_norm(
input=tmp,
act=active_type)
对Paddle下Mobilenet forwardbackward 性能进行了测试,其中Group convolution 为paddle原始的convolution的实现。Depthwise gpu convolution 为Gpu加速的版本,可以看出gpu加速明显。
| category | batch 1 forwardbackward (s) | batch 40 forwardbackward(s) |
|---|---|---|
| Group convolution | 0.75 | 29.23 |
| Cudnn convolution | 0.74 | 28.88 |
| Depthwise gpu acceleration | 0.052 | 1.27 |
在Paddle上对Mobilenet在flowers102上进行训练,精度如下
| mobilenet on flowers 102 | accuracy |
|---|---|
| 97.5% |
- cpu acceleration for mobilenet.