Deprecated
这是一个老版本的lofter 爬虫,当前版本已经无法使用
这是一个基于python的爬虫项目,它的目的在于抢救性保护同人tag和同人作者作品。
目前实现的功能:
- 两种模式
- 根据提供的lofter id保存所有blog
- 根据提供的lofter tag保存所有tag条目下可见的blog
- filter
- 热度阈值
- tag屏蔽
- title寻找
todo list
- 根据lofter id保存用户所有喜欢的blog
- 还在梦里的的GUI界面
- 智能助手抓取每日tag新增并整理为blog格式发送
测试阶段仍有很多bug,如果运行遇到问题请在issue区提出
不要用本项目代码做不好的事情!
pip install -r requirements.txt
使用任何文本编辑器打开config/test.yaml,修改配置。配置细节在下表列出。
| 配置选项 | 默认值 | 描述 | 示例 |
|---|---|---|---|
| OUTPUT_DIR | output/ | 保存存档的地址(绝对地址/相对地址都ok) | output/tag |
| TYPE | tag | 脚本运行模式,可选项有tag和USER,可以保存tag和保存user的blog | 'tag' |
| TAG | [] | 如果选择了tag运行模式,那么在括号里填入目标tag | ['tag1', 'tag2'] |
| USER | [] | 如果选择了USER运行模式,那么目标user | ['user1', 'user2'] |
| ------ | target细节部分 | ----------------- | ------- |
| HOT_THRE | 0 | 高于多少热度的文章被保存 | 50 |
| TITLE | [] | 标题中有什么内容的会被保存,这是list格式的配置,意味着可以有很多个与的目标 | ['论坛体', 'abo'] |
| TAG_PLUS | [] | 文章的tag中要有什么才会被保存。同样是list格式配置 | ['三十天挑战'] |
| TAG_MINUS | [] | 如果文章的tag有什么,就不会被保存。同样是list格式配置 | ['游戏截图', '日常'] |
需要注意的是,lofter id指的是网页版博客网址上的个人id,以https://coldiron.lofter.com/为例,则该blog的id为coldiron
lofter的blog名是自定义的,可以重名,但是lofter id是各不相同的。
python tool/crawler.py --cfg config/test.yaml
结果会产生很多html文件和一个log文件
- log文件的名字是
TYPE-name/id-时间.log - blog保存格式为html,名字是[
blogid]blog标题-blog作者名_lofter相对地址.html
测试blog:白的毛熊:https://coldiron.lofter.com/
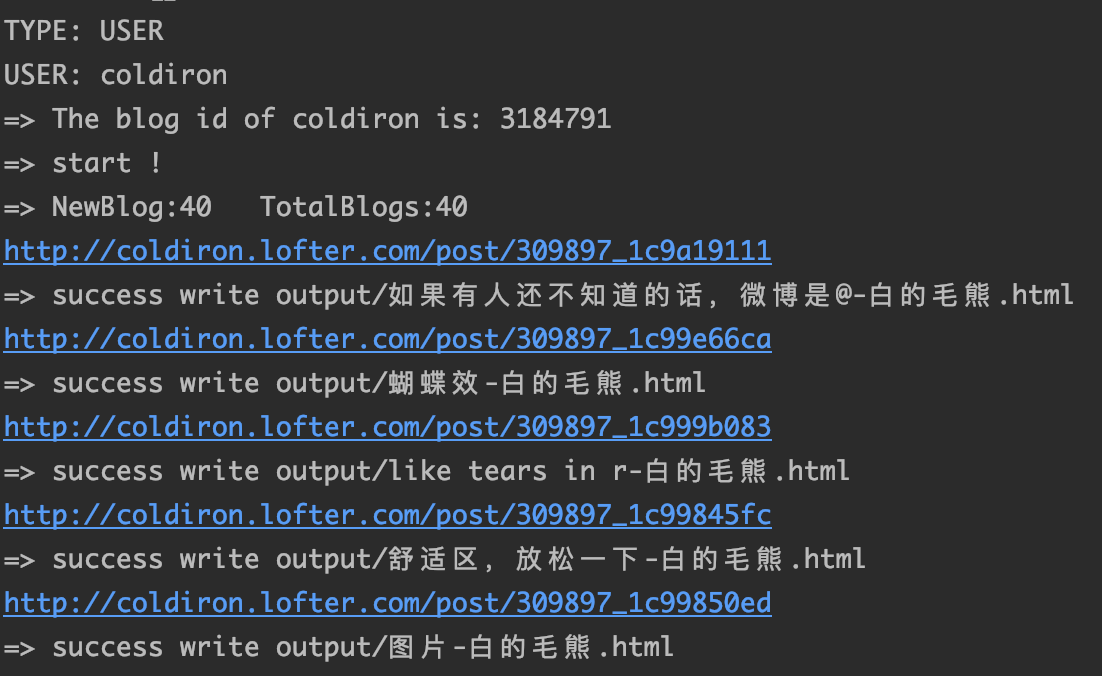
测试tag1:
432参与,实际爬得338
参与tag数是不算后面加入的tag,所以爬虫爬下来会少
测试tag2:
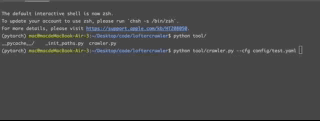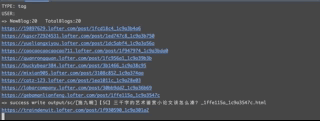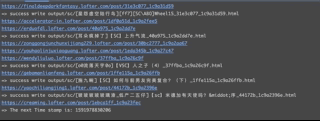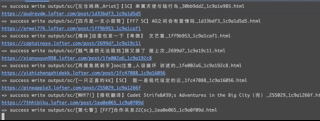
测试tag3:
主要测试了一下脚本爬取速度,这和各种因素都有关,脚本内也有设置随机睡眠时间。
10min~2000tag
据说如果爬到1w tag会出现lofter的反爬机制,尝试希望。