
這個知識庫包含許多 JavaScript 的資料結構與演算法的基礎範例。 每個演算法和資料結構都有其個別的文件,內有相關的解釋以及更多相關的文章或Youtube影片連結。
Read this in other languages: English, 简体中文
資料結構是一個電腦用來組織和排序資料的特定方式,透過這樣的方式資料可以有效率地被讀取以及修改。更精確地說,一個資料結構是一個資料值的集合、彼此間的關係,函數或者運作可以應用於資料上。
- Linked List 鏈結串列
- Queue 貯列
- Stack 堆疊
- Hash Table 雜湊表
- Heap 堆
- Priority Queue 優先貯列
- Trie 字典樹
- Tree 樹
- Binary Search Tree 二元搜尋樹
- AVL Tree ��AVL樹
- 紅黑樹
- 後綴樹
- 線段樹 或 間隔樹
- 樹狀數組或二叉索引樹
- Graph 圖 (有向跟無向皆包含)
- Disjoint Set 互斥集
演算法是一個如何解決一類問題的非模糊規格。演算法是一個具有精確地定義了一系列運作的規則的集合
- 數學類
- 集合
- 字串
- 萊文斯坦距離 - 兩序列間的最小編輯距離
- 漢明距離 - number of positions at which the symbols are different
- KMP 演算法 - 子字串搜尋
- Rabin Karp 演算法 - 子字串搜尋
- 最長共通子序列
- 搜尋
- 排序
- 樹
- 圖
- 深度優先搜尋 (DFS)
- 廣度優先搜尋 (BFS)
- Dijkstra 演算法 - 找到所有圖頂點的最短路徑
- Bellman-Ford 演算法 - 找到所有圖頂點的最短路徑
- Detect Cycle - for both directed and undirected graphs (DFS and Disjoint Set based versions)
- Prim’s 演算法 - finding Minimum Spanning Tree (MST) for weighted undirected graph
- Kruskal’s 演算法 - finding Minimum Spanning Tree (MST) for weighted undirected graph
- 拓撲排序 - DFS method
- 關節點 - Tarjan's algorithm (DFS based)
- 橋 - DFS based algorithm
- 尤拉路徑及尤拉環 - Fleury's algorithm - Visit every edge exactly once
- 漢彌爾頓環 - Visit every vertex exactly once
- 強連通組件 - Kosaraju's algorithm
- 旅行推銷員問題 - shortest possible route that visits each city and returns to the origin city
- 未分類
演算法的範型是一個泛用方法或設計一類底層演算法的方式。它是一個比演算法的概念更高階的抽象化,就像是演算法是比電腦程式更高階的抽象化。
- 暴力法 - 尋遍所有的可能解然後選取最好的解
- 貪婪法 - choose the best option at the current time, without any consideration for the future
- 未定背包問題
- Dijkstra 演算法 - 找到所有圖頂點的最短路徑
- Prim’s 演算法 - finding Minimum Spanning Tree (MST) for weighted undirected graph
- Kruskal’s 演算法 - finding Minimum Spanning Tree (MST) for weighted undirected graph
- 分治法 - divide the problem into smaller parts and then solve those parts
- 動態編程 - build up to a solution using previously found sub-solutions
- 回溯法 - 用類似暴力法來嘗試產生所有可能解,但每次只在能滿足所有測試條件,且只有繼續產生子序列方案來產生的解決方案。否則回溯並尋找不同路徑的解決方案。
- Branch & Bound
安裝所有必須套件
npm install
執行所有測試
npm test
以名稱執行該測試
npm test -- -t 'LinkedList'
練習場
你可以透過在./src/playground/playground.js裡面的檔案練習資料結構以及演算法,並且撰寫在./src/playground/__test__/playground.test.js裡面的測試程式。
接著直接執行下列的指令來測試你練習的 code 是否如預期運作:
npm test -- -t 'playground'
▶ Data Structures and Algorithms on YouTube
特別用大 O 標記演算法增長度的排序。
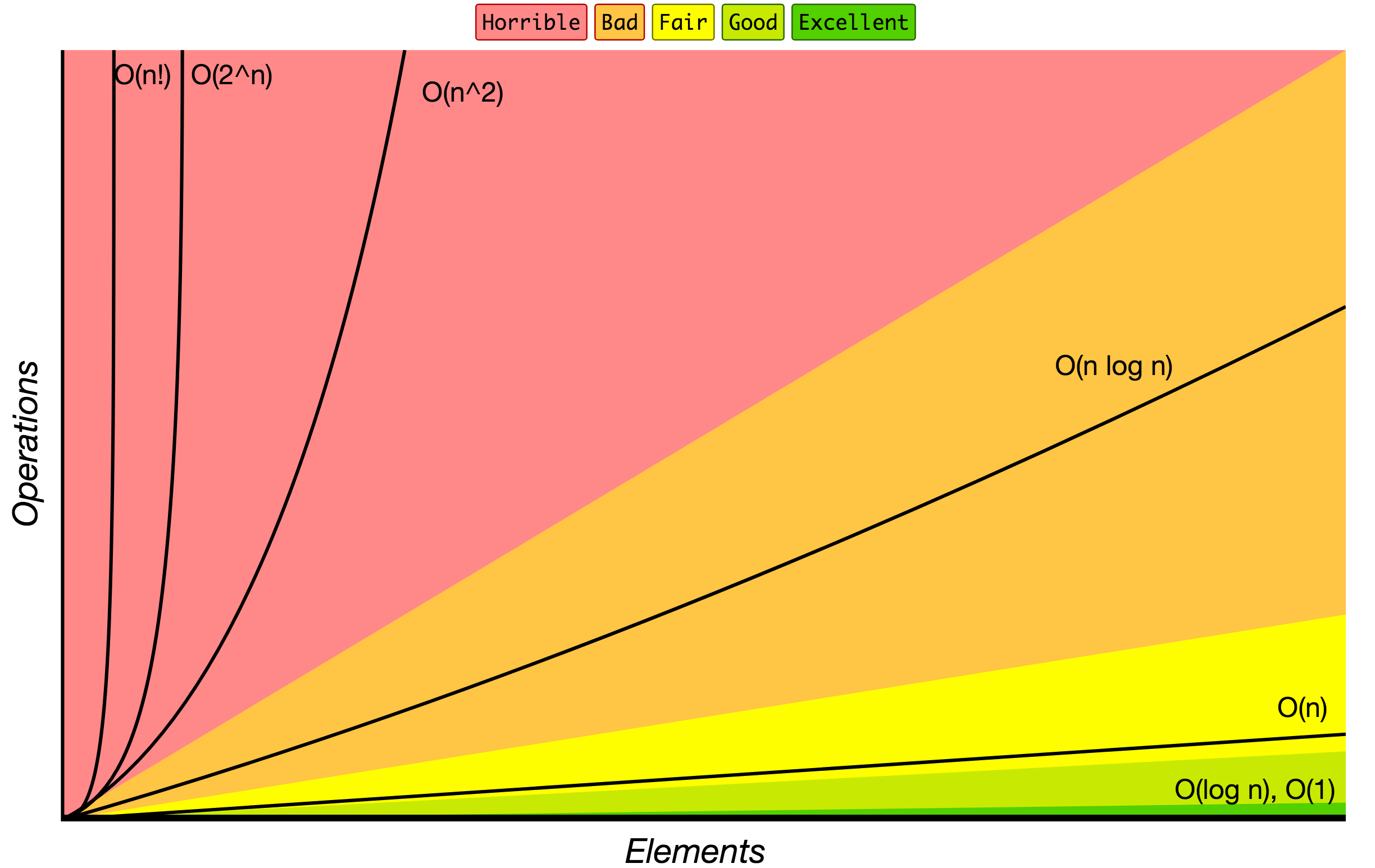
資料來源: Big O Cheat Sheet.
下列列出幾個常用的 Big O 標記以及其不同大小資料量輸入後的運算效能比較。
| Big O 標記 | 10個資料量需花費的時間 | 100個資料量需花費的時間 | 1000個資料量需花費的時間 |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
| 資料結構 | 存取 | 搜尋 | 插入 | 刪除 |
|---|---|---|---|---|
| 陣列 | 1 | n | n | n |
| 堆疊 | n | n | 1 | 1 |
| 貯列 | n | n | 1 | 1 |
| 鏈結串列 | n | n | 1 | 1 |
| 雜湊表 | - | n | n | n |
| 二元搜尋樹 | n | n | n | n |
| B-Tree | log(n) | log(n) | log(n) | log(n) |
| 紅黑樹 | log(n) | log(n) | log(n) | log(n) |
| AVL Tree | log(n) | log(n) | log(n) | log(n) |
| 名稱 | 最佳 | 平均 | 最差 | 記憶體 | 穩定 |
|---|---|---|---|---|---|
| 氣派排序 | n | n^2 | n^2 | 1 | Yes |
| 插入排序 | n | n^2 | n^2 | 1 | Yes |
| 選擇排序 | n^2 | n^2 | n^2 | 1 | No |
| Heap 排序 | n log(n) | n log(n) | n log(n) | 1 | No |
| 合併排序 | n log(n) | n log(n) | n log(n) | n | Yes |
| 快速排序 | n log(n) | n log(n) | n^2 | log(n) | No |
| 希爾排序 | n log(n) | 由gap sequence決定 | n (log(n))^2 | 1 | No |