In memory of Kobe Bryant
"내가 무슨 말을 할 수 있겠는가, 맘바 아웃." —코비 브라이언트, NBA 고별 연설, 2016

Image credit: https://www.ebay.ca/itm/264973452480
이것은 우리 논문에서 제안한 MambaOut의 PyTorch 구현입니다.MambaOut: 시력을 위해 Mamba가 정말 필요한가요?".
-
2024년 5월 20일: 24개의 Gated CNN 블록이 포함된 MambaOut-Kobe 모델 버전 출시이슈 #5.MambaOut-Kobe는 단 41%의 매개변수와 33%의 FLOP로 ViT-S보다 0.2%의 정확도를 능가합니다.. 보다모델.
-
2024년 5월 18일: 추가지도 시간Transformer FLOP 계산에 대해(논문의 방정식 6)
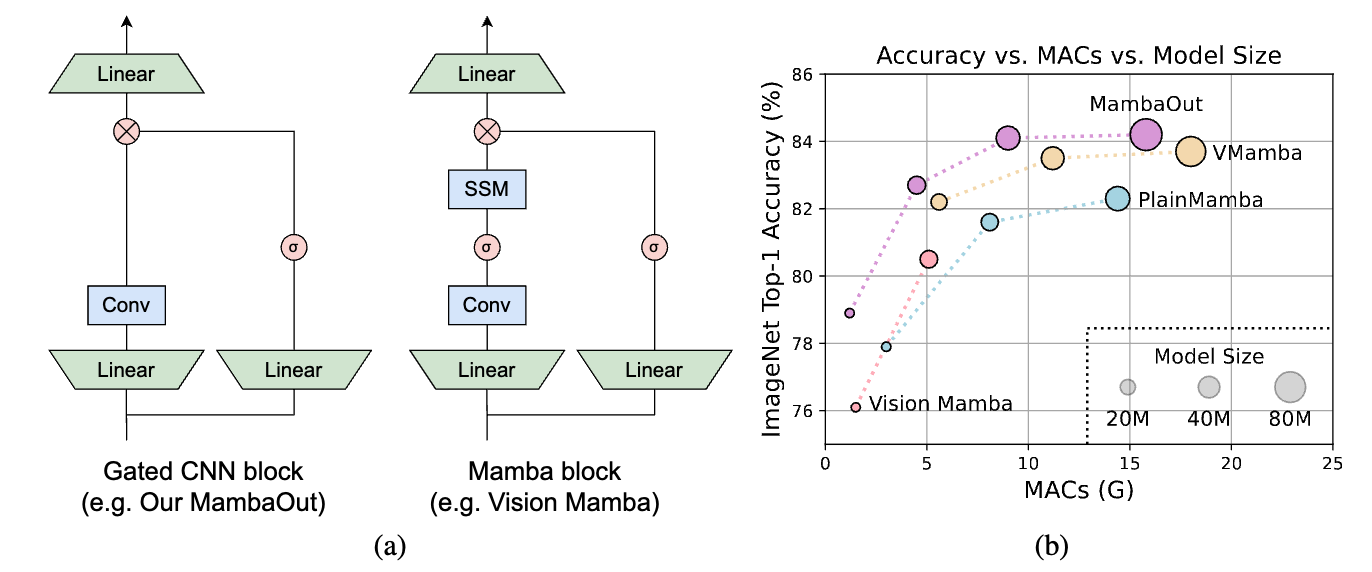 그림 1: (a) Gated CNN 및 Mamba 블록의 아키텍처(정규화 및 단축키 생략). Mamba 블록은 추가 상태 공간 모델(SSM)을 사용하여 Gated CNN을 확장합니다. 섹션 3에서 개념적으로 논의할 것처럼 SSM은 ImageNet의 이미지 분류에 필요하지 않습니다. 이 주장을 경험적으로 검증하기 위해 우리는 Gated CNN 블록을 쌓아 MambaOut이라는 일련의 모델을 구축했습니다.(b) MambaOut은 ImageNet 이미지 분류에서 Vision Mamhba, VMamba 및 PlainMamba와 같은 시각적 Mamba 모델보다 성능이 뛰어납니다.
그림 1: (a) Gated CNN 및 Mamba 블록의 아키텍처(정규화 및 단축키 생략). Mamba 블록은 추가 상태 공간 모델(SSM)을 사용하여 Gated CNN을 확장합니다. 섹션 3에서 개념적으로 논의할 것처럼 SSM은 ImageNet의 이미지 분류에 필요하지 않습니다. 이 주장을 경험적으로 검증하기 위해 우리는 Gated CNN 블록을 쌓아 MambaOut이라는 일련의 모델을 구축했습니다.(b) MambaOut은 ImageNet 이미지 분류에서 Vision Mamhba, VMamba 및 PlainMamba와 같은 시각적 Mamba 모델보다 성능이 뛰어납니다.
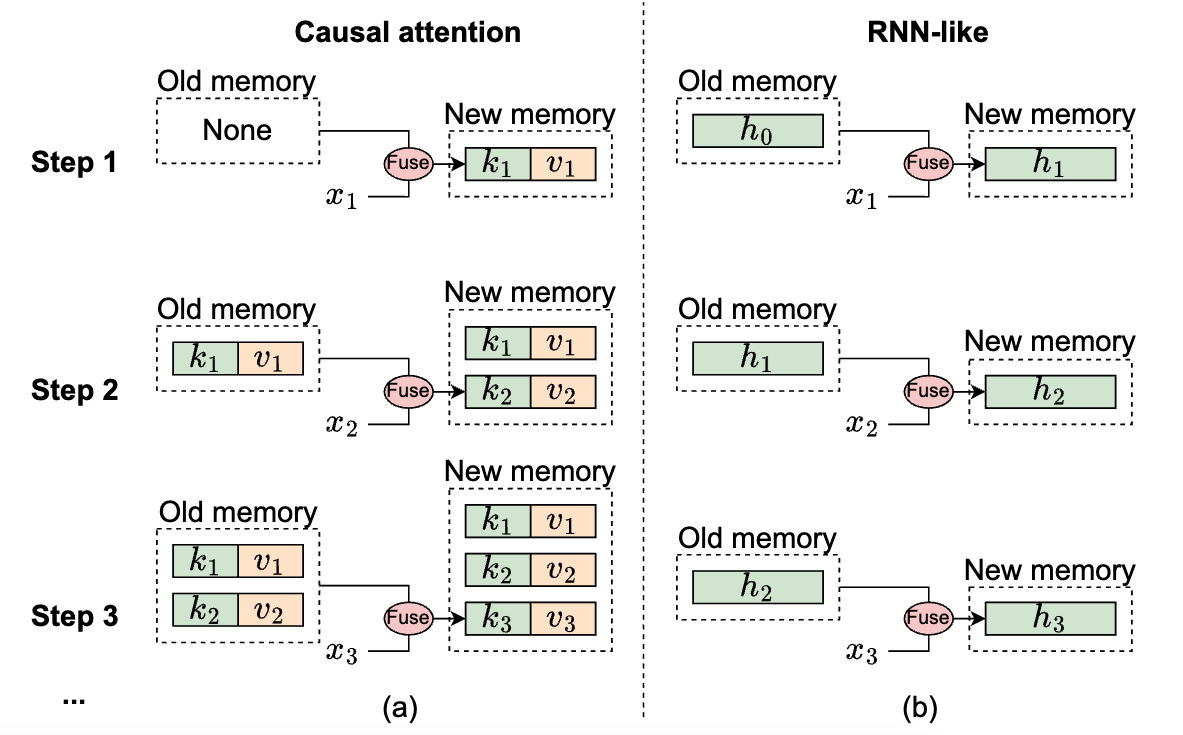 그림 2: 메모리 관점에서 인과적 주의 및 RNN 유사 모델의 메커니즘 설명. 여기서
그림 2: 메모리 관점에서 인과적 주의 및 RNN 유사 모델의 메커니즘 설명. 여기서
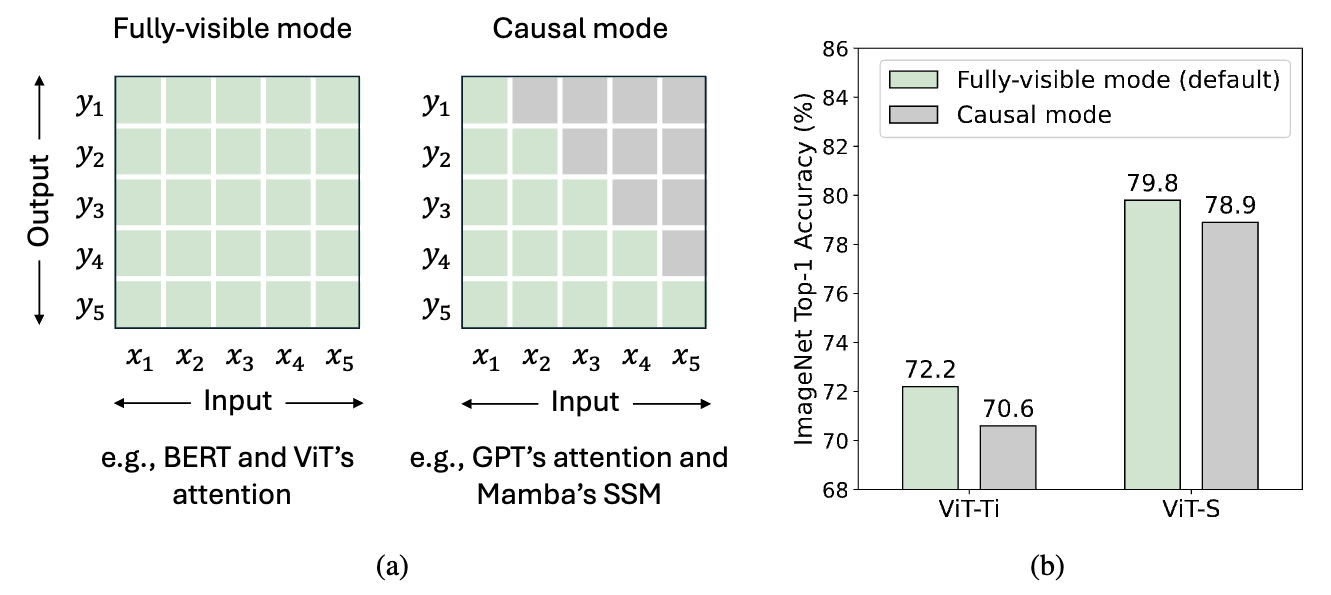 그림 3: (a) 토큰 혼합의 두 가지 모드. 총
그림 3: (a) 토큰 혼합의 두 가지 모드. 총
PyTorch 및 timm 0.6.11(pip install timm==0.6.11).
데이터 준비: ImageNet은 다음과 같은 폴더 구조를 가지고 있으며, 이를 통해 ImageNet을 추출할 수 있습니다.스크립트.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| 모델 | 해결 | 매개변수 | MAC | Top1 Acc |
|---|---|---|---|---|
| mambaout_femto | 224 | H. 삼촌 | 1.2G | 78.9 |
| mambaout_kobe* | 224 | 910만 | 1.5G | 80.0 |
| mambaout_tiny | 224 | 26.5M | 4.5G | 82.7 |
| mambaout_small | 224 | 48.5M | 9.0G | 84.1 |
| mambaout_base | 224 | 84. 댐 | 15.8G | 84.2 |
*고베 메모리얼 버전24개의 Gated CNN 블록이 있습니다.
또한 MambaOut으로 추론을 수행하는 단계를 실행하는 Colab 노트북도 제공됩니다..
웹 데모는 다음 위치에 표시됩니다.. 로컬에서 쉽게 그라디오 데모를 실행할 수도 있습니다. PyTorch 및 timm==0.6.11 외에도 Gradio를 설치하십시오.
pip install gradio, 그런 다음 실행
python gradio_demo/app.py모델을 평가하려면 다음을 실행하세요.
MODEL=mambaout_tiny
python3 validate.py /path/to/imagenet --model $MODEL -b 128 \
--pretrained기본적으로 배치 크기는 4096을 사용하고 8개의 GPU로 모델을 학습하는 방법을 보여줍니다. 다중 노드 학습의 경우 조정--grad-accum-steps당신의 상황에 따라.
DATA_PATH=/path/to/imagenet
CODE_PATH=/path/to/code/MambaOut # modify code path here
ALL_BATCH_SIZE=4096
NUM_GPU=8
GRAD_ACCUM_STEPS=4 # Adjust according to your GPU numbers and memory size.
let BATCH_SIZE=ALL_BATCH_SIZE/NUM_GPU/GRAD_ACCUM_STEPS
MODEL=mambaout_tiny
DROP_PATH=0.2
cd $CODE_PATH && sh distributed_train.sh $NUM_GPU $DATA_PATH \
--model $MODEL --opt adamw --lr 4e-3 --warmup-epochs 20 \
-b $BATCH_SIZE --grad-accum-steps $GRAD_ACCUM_STEPS \
--drop-path $DROP_PATH다른 모델의 훈련 스크립트는 다음과 같습니다.스크립트.
이것지도 시간Transformer FLOP를 계산하는 방법을 보여줍니다(논문의 방정식 6). 피드백을 환영하며 지속적으로 개선해 나가겠습니다.
@article{yu2024mambaout,
title={MambaOut: Do We Really Need Mamba for Vision?},
author={Yu, Weihao and Wang, Xinchao},
journal={arXiv preprint arXiv:2405.07992},
year={2024}
}
Weihao는 Snap Research Fellowship, Google TPU Research Cloud(TRC), Google Cloud Research Credits 프로그램의 일부 지원을 받았습니다. 귀중한 토론을 해주신 Dongze Lian, Qiuhong Shen, Xingyi Yang, Gongfan Fang에게 감사드립니다.
우리의 구현은 다음을 기반으로 합니다.pytorch-이미지-모델,풀포머,ConvNeXt,메타폼그리고시작다음.