🇨🇳中文 | 🌐English | 📖文档/Docs | 🤖模型/Models


MedicalGPT trains a medical large language model using the ChatGPT training pipeline, implementing pretraining, supervised finetuning, RLHF (Reward Modeling and Reinforcement Learning), and DPO (Direct Preference Optimization).
MedicalGPT trains medical large models, implementing incremental pretraining, supervised fine-tuning, RLHF (reward modeling, reinforcement learning training), and DPO (direct preference optimization).

- The RLHF training pipeline is from Andrej Karpathy's presentation PDF State of GPT, video Video
- The DPO method is from the paper Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- The ORPO method is from the paper ORPO: Monolithic Preference Optimization without Reference Model

Training MedicalGPT model:
- Stage 1:PT(Continue PreTraining), Pre-training the LLaMA model on massive domain document data to inject domain knowledge
- Stage 2: SFT (Supervised Fine-tuning) has supervised fine-tuning, constructs instruction fine-tuning data sets, and performs instruction fine-tuning on the basis of pre-trained models to align instruction intentions
- Stage 3: RM (Reward Model) reward model modeling, constructing a human preference ranking data set, training the reward model to align human preferences, mainly the "HHH" principle, specifically "helpful, honest, harmless"
- Stage 4: RL (Reinforcement Learning) is based on human feedback reinforcement learning (RLHF), using the reward model to train the SFT model, and the generation model uses rewards or penalties to update its strategy in order to generate higher quality, more in line with human preferences text
-
[2024/09/21] v2.2 Release: Supports the Qwen-2.5 series of models. See Release-v2.3
-
[2024/08/02] v2.2 Release: Supports role-playing model training, adds new scripts for generating patient-doctor dialogue SFT data role_play_data. See Release-v2.2.
-
[2024/06/11] v2.1 Release: Supports the Qwen-2 series of models. See Release-v2.1.
-
[2024/04/24] v2.0 Release: Supports the Llama-3 series of models. See Release-v2.0.
-
[2024/04/17] v1.9 Release: Supports ORPO. For detailed usage, refer to
run_orpo.sh. See Release-v1.9. -
[2024/01/26] v1.8 Release: Supports fine-tuning the Mixtral Mixture-of-Experts (MoE) model Mixtral 8x7B. See Release-v1.8.
-
[2024/01/14] v1.7 Release: Adds retrieval-augmented generation (RAG) based file question answering ChatPDF functionality, code
chatpdf.py, which can improve industry-specific Q&A accuracy by combining fine-tuned LLMs with knowledge base files. See Release-v1.7. -
[2023/10/23] v1.6 Release: Adds RoPE interpolation to extend the context length of GPT models; supports
$S^2$ -Attn proposed by FlashAttention-2 and LongLoRA for LLaMA models; supports the embedding noise training method NEFTune. See Release-v1.6. -
[2023/08/28] v1.5 Release: Adds the DPO (Direct Preference Optimization) method, which directly optimizes the behavior of language models to precisely align with human preferences. See Release-v1.5.
-
[2023/08/08] v1.4 Release: Releases the Chinese-English Vicuna-13B model fine-tuned on the ShareGPT4 dataset shibing624/vicuna-baichuan-13b-chat, and the corresponding LoRA model shibing624/vicuna-baichuan-13b-chat-lora. See Release-v1.4.
-
[2023/08/02] v1.3 Release: Adds multi-turn dialogue finetuning for LLAMA, LLAMA2, Bloom, ChatGLM, ChatGLM2, and Baichuan models; adds domain vocabulary expansion functionality; adds Chinese pre-training datasets and Chinese ShareGPT finetuning datasets. See Release-v1.3.
-
[2023/07/13] v1.1 Release: Releases the Chinese medical LLAMA-13B model shibing624/ziya-llama-13b-medical-merged, based on the Ziya-LLAMA-13B-v1 model, SFT fine-tunes a medical model, improving medical QA performance. See Release-v1.1.
-
[2023/06/15] v1.0 Release: Releases the Chinese medical LoRA model shibing624/ziya-llama-13b-medical-lora, based on the Ziya-LLaMA-13B-v1 model, SFT fine-tunes a medical model, improving medical QA performance. See Release-v1.0.
-
[2023/06/05] v0.2 Release: Trains domain-specific large models using medicine as an example, implementing four stages of training: secondary pretraining, supervised fine-tuning, reward modeling, and reinforcement learning training. See Release-v0.2.
- Hugging Face Demo: doing
We provide a simple Gradio-based interactive web interface. After the service is started, it can be accessed through a browser, enter a question, and the model will return an answer. The command is as follows:
python gradio_demo.py --base_model path_to_llama_hf_dir --lora_model path_to_lora_dirParameter Description:
--base_model {base_model}: directory to store LLaMA model weights and configuration files in HF format, or use the HF Model Hub model call name--lora_model {lora_model}: The directory where the LoRA file is located, and the name of the HF Model Hub model can also be used. If the lora weights have been merged into the pre-trained model, delete the --lora_model parameter--tokenizer_path {tokenizer_path}: Store the directory corresponding to the tokenizer. If this parameter is not provided, its default value is the same as --lora_model; if the --lora_model parameter is not provided, its default value is the same as --base_model--use_cpu: use only CPU for inference--gpus {gpu_ids}: Specifies the number of GPU devices used, the default is 0. If using multiple GPUs, separate them with commas, such as 0,1,2
Based on the llama-7b model, use medical encyclopedia data to continue pre-training, and expect to inject medical knowledge into the pre-training model to obtain the llama-7b-pt model. This step is optional
sh run_pt.shBased on the llama-7b-pt model, the llama-7b-sft model is obtained by using medical question-and-answer data for supervised fine-tuning. This step is required
Supervised fine-tuning of the base llama-7b-pt model to create llama-7b-sft
sh run_sft.shRM(Reward Model): reward model modeling
In principle, we can directly use human annotations to fine-tune the model with RLHF.
However, this will require us to send some samples to humans to be scored after each round of optimization. This is expensive and slow due to the large number of training samples required for convergence and the limited speed at which humans can read and annotate them. A better strategy than direct feedback is to train a reward model RM on the human annotated set before entering the RL loop. The purpose of the reward model is to simulate human scoring of text.
The best practice for building a reward model is to rank the prediction results, that is, for each prompt (input text) corresponding to two results (yk, yj), the model predicts which score the human annotation is higher. The RM model is trained by manually marking the scoring results of the SFT model. The purpose is to replace manual scoring. It is essentially a regression model used to align human preferences, mainly based on the "HHH" principle, specifically "helpful, honest, harmless".
Based on the llama-7b-sft model, the reward preference model is trained using medical question and answer preference data, and the llama-7b-reward model is obtained after training. This step is required
Reward modeling using dialog pairs from the reward dataset using the llama-7b-sft to create llama-7b-reward:
sh run_rm.shThe purpose of the RL (Reinforcement Learning) model is to maximize the output of the reward model. Based on the above steps, we have a fine-tuned language model (llama-7b-sft) and reward model (llama-7b-reward). The RL loop is ready to execute.
This process is roughly divided into three steps:
- Enter prompt, the model generates a reply
- Use a reward model to score responses
- Based on the score, a round of reinforcement learning for policy optimization (PPO)
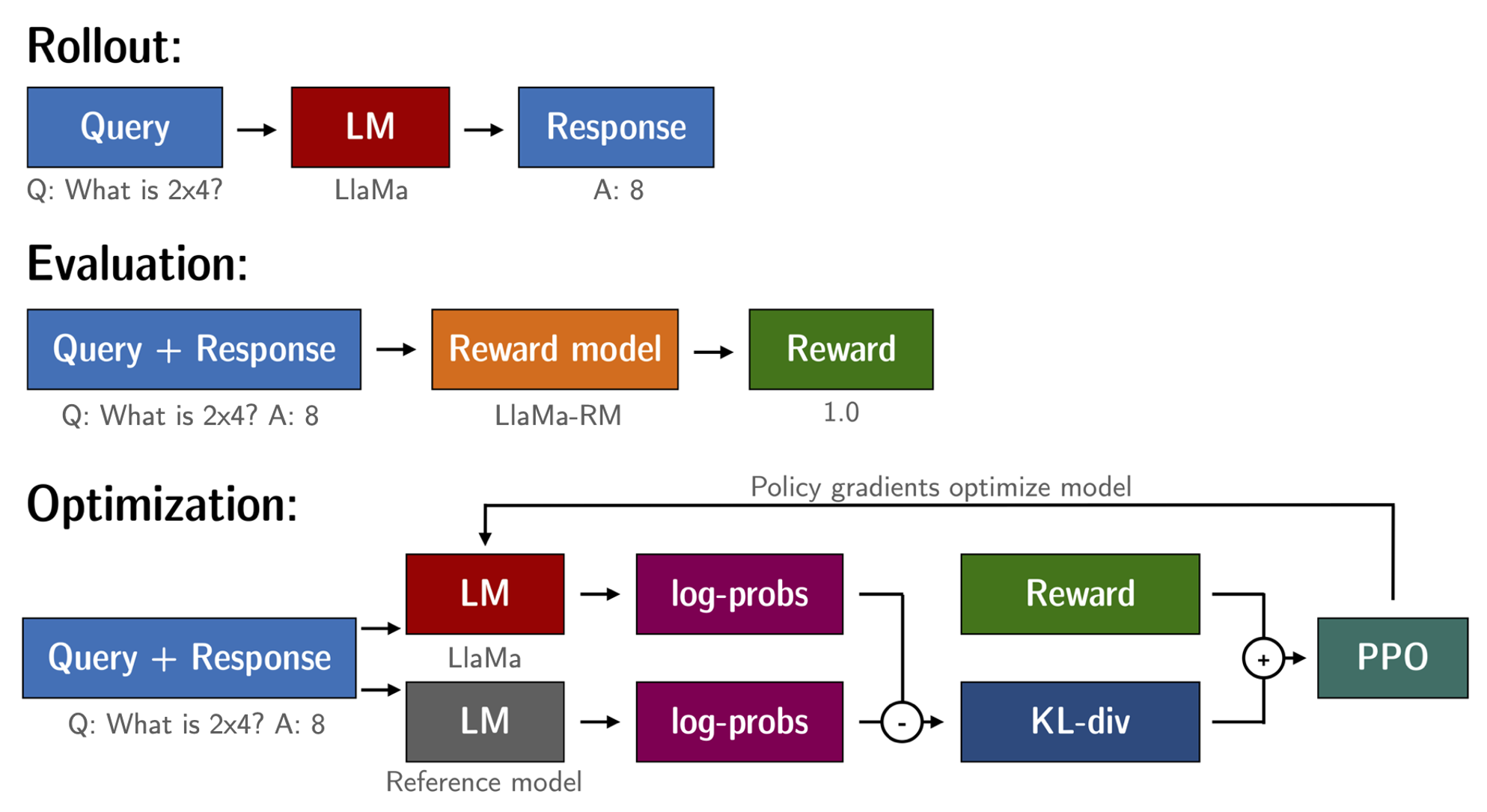
Reinforcement Learning fine-tuning of llama-7b-sft with the llama-7b-reward reward model to create llama-7b-rl
sh run_ppo.sh| Model Name | Model Size | Target Modules | Template |
|---|---|---|---|
| Baichuan | 7B/13B | W_pack | baichuan |
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | vicuna |
| ChatGLM | 6B | query_key_value | chatglm |
| ChatGLM2 | 6B | query_key_value | chatglm2 |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| Cohere | 104B | q_proj,v_proj | cohere |
| DeepSeek | 7B/16B/67B | q_proj,v_proj | deepseek |
| InternLM2 | 7B/20B | wqkv | intern2 |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | alpaca |
| LLaMA2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| LLaMA3 | 8B/70B | q_proj,v_proj | llama3 |
| Mistral | 7B/8x7B | q_proj,v_proj | mistral |
| Orion | 14B | q_proj,v_proj | orion |
| Qwen | 1.8B/7B/14B/72B | c_attn | chatml |
| Qwen1.5 | 0.5B/1.8B/4B/14B/72B | q_proj,v_proj | qwen |
| XVERSE | 13B | query_key_value | xverse |
| Yi | 6B/34B | q_proj,v_proj | yi |
From time to time, the requirements.txt changes. To update, use this command:
git clone https://github.com/shibing624/MedicalGPT
cd MedicalGPT
pip install -r requirements.txt --upgrade| Train Method | Bits | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | AMP | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| LoRA | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
After the training is complete, now we load the trained model to verify the effect of the model generating text.
python inference.py \
--base_model path_to_llama_hf_dir \
--lora_model path_to_lora \
--with_prompt \
--interactiveParameter Description:
--base_model {base_model}: Directory to store LLaMA model weights and configuration files in HF format--lora_model {lora_model}: The directory where the LoRA file is decompressed, and the name of the HF Model Hub model can also be used. If you have incorporated LoRA weights into the pre-trained model, you can not provide this parameter--tokenizer_path {tokenizer_path}: Store the directory corresponding to the tokenizer. If this parameter is not provided, its default value is the same as --lora_model; if the --lora_model parameter is not provided, its default value is the same as --base_model--with_prompt: Whether to merge the input with the prompt template. Be sure to enable this option if loading an Alpaca model!--interactive: start interactively for multiple single rounds of question and answer--data_file {file_name}: Start in non-interactive mode, read the contents of file_name line by line for prediction--predictions_file {file_name}: In non-interactive mode, write the predicted results to file_name in json format--use_cpu: use only CPU for inference--gpus {gpu_ids}: Specifies the number of GPU devices used, the default is 0. If using multiple GPUs, separate them with commas, such as 0,1,2
1. Get enough sleep. Make sure to get enough sleep every night.
2. Exercise more. Doing moderate aerobic exercise, such as jogging and swimming, can help improve your energy and stamina. 3. Eat healthy food. Choose protein-rich foods such as chicken, fish, and eggs, as well as fresh fruits and vegetables. 4. Reduce caffeine intake. Try to avoid drinking caffeinated beverages or eating caffeinated foods during the day.
5. Relax. Try meditation, yoga, or other forms of relaxation to reduce stress and anxiety. |
- 2.4 million Chinese medical datasets (including pre-training, instruction fine-tuning and reward datasets): shibing624/medical
Attach links to some general datasets and medical datasets
- Belle dataset of 500,000 Chinese ChatGPT commands: BelleGroup/train_0.5M_CN
- Belle dataset of 1 million Chinese ChatGPT commands: BelleGroup/train_1M_CN
- Alpaca dataset of 50,000 English ChatGPT commands: 50k English Stanford Alpaca dataset
- Alpaca dataset of 20,000 Chinese GPT-4 instructions: shibing624/alpaca-zh
- Guanaco dataset with 690,000 Chinese instructions (500,000 Belle + 190,000 Guanaco): Chinese-Vicuna/guanaco_belle_merge_v1.0
- 220,000 Chinese medical dialogue datasets (HuatuoGPT project): FreedomIntelligence/HuatuoGPT-sft-data-v1
- Issue (suggestion)
:
- Email me: xuming: [email protected]
- WeChat Me: Add me* WeChat ID: xuming624, Remarks: Name-Company Name-NLP* Enter the NLP exchange group.

The license agreement for the project code is The Apache License 2.0, the code is free for commercial use, and the model weights and data can only be used for research purposes. Please attach MedicalGPT's link and license agreement in the product description.
If you used MedicalGPT in your research, please cite as follows:
@misc{MedicalGPT,
title={MedicalGPT: Training Medical GPT Model},
author={Ming Xu},
year={2023},
howpublished={\url{https://github.com/shibing624/MedicalGPT}},
}The project code is still very rough. If you have improved the code, you are welcome to submit it back to this project. Before submitting, please pay attention to the following two points:
- Add corresponding unit tests in
tests - Use
python -m pytestto run all unit tests to ensure that all unit tests are passed
Then you can submit a PR.
Thanks for their great work!
- shibing624/ChatPilot: Provide a simple and easy-to-use web UI interface for LLM Agent (including RAG, online search, code interpreter).