Well maybe not but you can get close in some circumstances.
+
+
+
+
I've got a situation where when a timer ticks I want to change the background colour of a textbox on a windows form. Since I don't need to pass in any parameters if I was using c# I could use Control.Invoke and an anonymous method… especially since I know I'll always be accessing this control in this method from a different thread.
+
+
But VB .Net doesn't support anonymous methods. Now I've seen all kinds of verbose ways around this on the web… google it - I dare you.
+
+
But if you use Action as below you're pretty close to hardly any extra code…
+
+
Public Sub removeHighlight() Handles timer.Elapsed
+ timer.Stop()
+ If txtSingleCheck.InvokeRequired Then
+ txtSingleCheck.Invoke(New Action(AddressOf removeHighlight))
+ Else
+ txtSingleCheck.BackColor = Color.White
+ End If
+End Sub
+
+
+
So long as the delegate or action you are calling has the same signature as the method you're calling it in then you call InvokeRequired on the control in question and if true you call a new action with the AddressOf the method you're in otherwise you do what you wanted to do but on the appropriate thread.
+
+
Bot as powerful as anonymous methods I'll grant you but in situations like this it isn't that far removed… is it?
Over the last two days I've been researching using Windows Deployment Services with BDD. I've got 4 workstations to build so I may as well investigate it right?
+
+
+
+
I am also updating my main machine from build 7100 of Win 7 Ultimate to the RTM so I have a Win XP box on my desk that I've built to give me continuity and a new Win 7 install.
+
+
Both of which had Bing as the default search engine out of the box.
+
+
So I thought I'd run with it. After all I'm searching for Microsoft technologies…
+
+
The first hit from the string "BDD 2007 download" in Google is:
That's not the BDD 2007 page and I can't even see a BDD link on there.
+
+
Bad, bad, bad and bad. I think that's a reasonable search string when I want to download BDD 2007 and so does google whereas Bing seems to think I want to hit some generic front end and read lots of whitepapers…
+
+
That's why I think of Google as a productivity tool.
I've released a piece of software that I made for my 18 month old daughter on Codeplex http://qqstd.codeplex.com/.
+
+
It's a small dotNet app for Windows Mobile that creates sound-image pairs by scanning a resource folder and then randomly displays one of the images. When the image is touched the sound associated with the image is played.
+
+I developed it to occupy my daughter and teach her animal noises but the app doesn't care what if finds so you could use pictures of family and friends and their names said out-loud; Vehicles and their engine noises or anything that enters your transom.
+
+
+
+
Drop images and .wav files into the \My Documents\qqstd\resources folder and restart the app.
+
+
So if you want to add a leopard:
+
+
+
you'd add as many leopard pictures as you want named leopard1, leopard2, etc
+
you'd add as many leopard noise WAV files as you like named (yep you guessed it) leopard1, leopard2, etc
+
restart the app if it's already running
+
+
+
and you're good to go…
+
+
It should run on any WinMo 6.1 phone with compact dotNet 3.5 and a touchscreen. But feel free to file a bug report on codeplex if I'm wrong.
+
+
That said it's been tested by the toddler that managed to set my phone not to charge unless powered off which is three clicks deep in a system menu so I'm pretty confident that it'll withstand most baby-based screen bashing.
+
+
At the moment we spend a lot of time on Skype to our relatives in the far south west of the UK so I'm working on another baby-based screen bashing project that I'll release in a few weeks time (work allowing)
I've been meaning to get around to writing a good tutorial on c# background workers. Mainly because I use them to separate the GUI from all the heavy lifting and I always forget how to update things.
In a previous post I advertised an application I'd made for WinMo to entertain my toddler.
+
+
+
Having watched her play with it and having been reminded to K.I.S.S. I've fixed a bug that highlighted the difference in expectations between myself and a toddler.
+
+
+
+
No not the world-weary pessimism I'm practising instead when I tested and used the app I would click and then wait for something to happen… whereas my toddler would bash at the screen having got the link between doing so and stuff happening.
+
+
While the UI was blocking the OS would register all the clicks and then process them before updating the screen.
+
+
In the context of this application that meant that you could have a sheep on screen that was barking like a dog…. not teaching my kid the lessons I was hoping!
+
+
I moved the actual sound playing onto a background thread and set a boolean flag to try to control the click event
The astute among you (pat yourselves on the back) will notice that there's also a timer in there… I found that if I hit the screen 5 times (for example) during the sound playing the last one or two clicks would be picked up and their audio played
+before the image finally refreshed.
+
+
I guess the UI was blocking briefly as processing control passed from the spawned thread back to the UI thread.
+
+
So I added a short timer that is started by the refreshScreen method and which stops itself and resets the isPlaying flag on its first tick.
+
+
That might be a bit hacky and there might be a better way but since that seems to work I'm happy with it.
+
+
And now I have a slightly more toddler-proof toddler game.
+
+
At the time of writing you could view all of the source code and download an install cab at codeplex qqstd.codeplex.com but that site is unavailable now :( You can see it in the wayback machine
So anyway I learn about design patterns and begin to use the factory pattern. And much like many other people I settle into a world where there are no other patterns. All is comfortable and fluffy and instantiated from calling code much as it was in days gone by.
+
+
+
+
Then comes the day I need to handle the responses to a monthly mailing to over 70,000 email addresses and so I write this incredible code. Well maybe not incredible… what would be the right word - oh yeah "messy".
+
+
It all started out really nice and clean but then I realised I needed to handle a couple of more cases than I'd intended when I began… and lots and lots of mail servers have been configured to return non-standard responses to unsuccessful mailings which is great for a human but not so great for a piece of software trying to classify that response.
+
+
So time passes and I'm correctly responding to over 90% of the returns we get (all of which stops evil companies like Yahoo for blocklisting us because we're mailing to non-existent addresses) but my code has got really, really messy.
+
+
Really messy.
+
+
Oh, it's awful.
+
+
I decide to refactor but no matter what I think of I can't get a Factory to solve my problem. Yeah, yeah I know but if you're gonna have a hammer it might as well be shiny. Now, I could go ahead and invent my own solution but as far as I'm concerned writing software is about having to do less and that sounds like too much work.
+
+
A little thought later and I decide it's time to add the command pattern to my arsenal. After all, I'm categorising mail, potentially selecting from a database, potentially updating a database, potentially replying to or forwarding an email and then deleting that mail. Wrap that up and then bash out the various alternatives I need. Bazinga!
+
+
I also like to be sure about what I'm doing before I start. Well, sometimes… So I dig out Patterns in Java Volume 1 and do a little reading and what I saw was such a great idea I realised I had to do everything I could not to forget…
I dig separation of responsibility so I like to separate out a "manager" or "controller" class from the other classes who don't need the logic that it encapsulates.
+
+
But that pretty tightly couples everything together. If I manage to strip a lot of code out of something (as I did when I bought the excellent Outlook redemption library recently) then there's more to change.
+
+
Here all of the logic for the command is bound up within it even though CommandManager class is still separate. I like that and I hadn't realised you could do this kind of thing by declaring something as static… I like to find a nice little elegant bit of sugar like that.
I've got a mini 5101. A little HP netbook that I lurve. It runs Windows 7 and Ubuntu 10.04 with aplomb.
+
+
+
+
My one gripe is that (much like my mac keyboard) the Function key functions are the main action of that key… so in Windows if you hit F5 to refresh a web page the laptop actually sleeps.
+
+
If you hit F3 to search in chrome instead you dim the screen. Annoying, no?
+
+
So I travel the dusty highways to the BIOS settings and there's an option to switch the function, erm, function. Some BIOS' refer to this as switching "media keys". I switch this to enable, boot up and my function keys are my own again.
+
+
All is well…
+ …
+ …
+ …
+
+
except…
+
+If you let the laptop sleep then when it wakes up it prompts for a password which it rejects as incorrect. Now I typed my password * V * E * R * Y * carefully but no joy.
+
+
I discovered if I hit switch user and chose the same user then the log in screen displayed the user status as "logged in" instead of "locked". Type the same password here and I can log in… What the what!?
+
+
I didn't immediately connect these changes… in my defence this isn't my main machine and I only use it sporadically.
+
+
I created a new user… no change.
+
+
Then I reinstalled Windows… no change.
+
+
I jumped into Google feet first and found almost nothing. Lots of forum posts where nothing is discovered and everyone has a slightly different problem which they describe vaguely. In my experience this generally points to a problem between the chair and the keyboard and so I sat and thought until I had tied the two together in my head.
+
+
As a test I let the laptop sleep, checked it rejected my password and then I held down the function key and typed the password. Voila I could log in.
+
+
Now I have to decide which behaviour is most annoying
I've been using JetBrains Resharper for a while after a recommendation along the lines of "I can't stand to write code without it now" and…
+
+
I can't stand to write code without it now!
+
+
+
+
I've got a program that (in a moderately clunky way) gets all of the emails in a couple of mailboxes and checks to see if they are non-delivery reports, reports of address changes (which our customers consistently send in reply to newsletters), unsubscribe requests (despite a link in the mail) and so on…
+
+
+
+
The class that handled the matching of text against rules had grown to be a real behemoth if not actually a spaghetti monster it was at the minimum a noodle demon. I won't post the code here the internet isn't big enough!
+
+
But it consisted of an enum, five List<string> and then a set of methods that took an email object compared the body and subject to the 5 phrase lists and returned an appropriate result from the enum.
+
+
I realised that I didn't want a list per result…
+
+
_badAddresses.add("no user by that name");
+_outOfOffice.add("on my hols");
+
+
+
it was getting difficult to manage, there was no checking for duplication of the strings, there was no apparent way to keep the enum return and phrase list linked and all the looping was getting confusing.
+
+
So I went through two stages and Resharper helped by being awesome at supporting my laziness.
+
+
First I combined the many lists into one Dictionary<string, phrasecheckresult> to link my candidate strings with my enum result types.
+
+
I used a little of Notepad++'s Find and replace magic to wholesale convert my list initialisation into a Dictionary initialisation and ended up with
+
+
_phraseMap=newDictionary<string,phrasecheckresult>
+{
+ {"554 qq sorry, no valid recipients}",PhraseCheckResult.BadAddress},
+ {"user doesn't have a yahoo.co.uk account",PhraseCheckResult.BadAddress},
+ {"account has been disabled or discontinued",PhraseCheckResult.BadAddress},
+ {"550 recipient",PhraseCheckResult.BadAddress},
+ {"is invalid",PhraseCheckResult.BadAddress},
+ {"user invalid",PhraseCheckResult.BadAddress}
+};
+
+
+
+
+
cut short for brevity as there are nearly 300 phrases now… Using an object initialiser meant I had nowhere to go when the program failed at runtime adding duplicate keys to the dictionary. Catching the exception didn't help since I couldn't see what key was duplicated to tidy up my code.
+
+
So I highlighted all the rows of initialisation and what did I see?
+
+
+
+
Resharper's context menu lets me switch the object initialiser out to a series of .Add() calls. I could quickly find the duplicates and then switch back to an object initialiser. Yay!
+
+
I should be writing unit tests but then that's always being put off to the next project and could I check if I've added a key already during an object initialisers run? I guess not but…
+
+
Second I wrote a couple of if braces that checked the subject and body and returned the appropriate results… up pops Resharper and suggests I can convert that to a Linq expression and I get the end result of…
A little shift around of the enum was necessary to put None as the first option. That way when the SingleOrDefault method doesn't find any of the candidate strings in the mail item the default action to take is to do nothing and a person can look at it. If you wanted to always delete unidentified messages you could shift Delete to be first in the enum and your program's behaviour would change. Bonza!
I've resolved to learn more about linux and have been slowly boggling at how easy I find some tasks are in comparison to the MS world…
+
+
Recently I've been working on what was intended to be a small and straight-forward website that has rapidly grown to be a large behemoth that will take credit card payments.
+
+
+
+
So I need revision control.
+
+
Also, the site uses Drupal and Drupal use GIT for revision control. We're building a custom module and we'd like to contribute it back once it is done so we may as well use GIT now to make life easier.
+
+
Pretty exciting I can commit my changes and they are automatically pushed over to my test server on commit and then if I like them I can push them to my live server. Both pushes are by SSH and both times I have to type in a different, long, complex password.
+
+
Frustrating and inefficient for a god of business whose time is so important - no…
+
+
But the interwebs tell me that you can set up SSH so you don't need a password. They also tell me in a vaguely confusing manner… my resolve now is to add another vaguely confusing explanation to the interwebs.
+
+
+
+
The task is to set my client.local machine to be able to SSH onto server.remote without any passwords changing hands.
+
+
This was relatively straight forward on my Mac and on my ubuntu box but my main dev machine is Windows 7…
+
+
As an aside switching from Mac, to VMWare fusion Windows, to VMWare fusion, to Windows 7 and remoting between them means I *never* know which key is going to be @ and which " and the windows machines get reset to US keyboard every so often by the Macs which throws a spanner in the works.
+
+
On a linux or unix machine this turned out to be pretty straight forward
+
+
+
Login to client.local
+
run ssh-keygen -t rsa
+
alter the path offered to rename the file sensibly in my case ~/.ssh/rsa_server.remote
type ssh dinglehopper@server.remote -p 8901 and watch in awe and wonder
+
+Things aren't quite so straightforward on Windows but the basic steps remain.
+
+
+
On Windows I use the excellent PuTTy to enable all things SSHy and I'm going to behave as if you do to…
+
+
First things first ssh onto server.remote as the user you want to use in future eg dinglehopper@server.remote and:
+
+
on your Windows clinet.local fire up puttygen.exe and hit generate. As a bit of fun you are asked to wiggle your mouse in order to provide randomness (I wonder if this is placebo)
+
+
+
+
Once this is generated you'll see a box marked "Public key for pasting into authorized_keys file". Can you guess what that's for?
+
+
So grab that text in your clipboard, fire up ssh and connect to server.remote as the user you want to log in as.
+Then
+
+
run echo "YOURKEYHERE" ~/.ssh/authorized_keys
+
+
Now we need to configure PuTTy. So open PuTTy and either load a profile or start a new one. First we scroll down in the tree view to Connection > Data and put in the username we want to connect as…
+
+
+
+
Then you move to Connection > SSH > Auth and enter the private key file that puttygen created…
+
+
+
+
Now save this profile so you can fire up the connection in future and away you go…
+
+
Now my git push doesn't bother me for a password.
+
+
There are security concerns with passwordlessness so be mindful!
Twice recently I've hit the same problem with two different mobile phone vendor's websites. Vodafone (displayed here) and 3. When I type a phone number I split it into three sections using white-space. "nnnn nnn nnnn" that's how I remember numbers. That's not uncommon I don't think…
+
+
+
+
+
+
nor is it odd to use a dash.
+
+
So why do I need to learn how your website wants phone numbers formatted.
+
+
Whack some javascript on your page… you must be using it for something!
+
+
var correctedNumber = numberTypedOnForm.replace(" ","").replace("-","");
+
+
and with that massive development cost you aren't going to make someone type a number twice only to satisfy your database server. Yes, not everyone will have javascript turned on and it won't catch everyone's weird way of typing phone numbers
+
+
+
"(nnnn)-nn-nn-nn-n"
+
+
+
but it's about not introducing a pain point for customers when you don't have to
+
+
If you want to be really fancy you could
+
+
var correctedNumber = numberTypedOnForm.replace("/\D/g","");
+
+
Computers are supposed to make our lives easier but it's up to you website developers to help them help us.
We send out mail to 70,000+ members of our organisation. In theory they know they're getting it cos they're advised when they join the organisation that we'll send the email… yes, I know that implicit opt-ins aren't best practice… I want to polish up our email unsubscribe flow since the amount of mail we send out is steadily climbing as we move from paper to email for more things.
+
+
+
+
So first idea… you click a link = you get unsubscribed…
In short someone clicking a link can get information from the database but shouldn't update information.
+
+
The problem is that I think that is counter-intuitive. I know I don't click links hoping that the actions carried out are idempotent. I click a link expecting something to happen and if we confound a user's expectations then we get to do the same job at least one more time… and I'm lazy - so that isn't a solution for me
+
+
But what is the solution since people are not going to want to spend time reading the page. How do I make what someone sees work well?
Unsubscribing</span> A user must be able to unsubscribe from your mailing list through one of the following means:
+
+
+
A prominent link in the body of an email leading users to a page confirming his or her unsubscription (no input from the user, other than confirmation, should be required). 2) By replying to your email with an unsubscribe request.
+
+
+
+
So I think that we're going to shufty this all-around a bit.
When you hit the page you can click a big button to confirm the action (which ajax-ily updates your displayed state and we can track how many people hit the page without doing anything).
I know a lot of people are of the opinion that an unsubscribe link should unsubscribe you and require no further action and that the whole idempotency thing is software design flim-flam and I was tempted to agree until I was introduced to the concept of pre-fetching…
+
+
+
+
In short modern browsers and some email clients will try to speed up your experience by following links in the background so that when you click on a link it seems to launch lightening fast. Given the massive bandwidth lots of people have in this Buck Rogers-esque world we live in this is a "good thing". However, if you have recipients of emails with unsubscribe links that require no confirmation and those people are pre-fetching those links then they could be being unsubscribed without even knowing it.
+
+
This is a good example of why standards are worth following… an unsubscribe link made before the advent of pre-fetching that was idempotent on get doesn't need to worry when prefetching is invented because so long as the people implementing prefetching follow the standards too then your software will continue to work as expected.
+
+
As with lots of this stuff - it seems like more work now but it's always more work when it breaks!
Oh wait… this is awful. AWRUCHKA. Right dry heaving done with.
+
+
It's a good job so few websites want to authenticate users and collect data on them otherwise we'd constantly have to write the same code ove… what's that? Oh my! Everyone is going through this.
+
+
+
+
Jesus no wonder people bang on about RoR. It makes this easier in comparison
+
+
Anyway - I'll forget how to do this before I have to do it again
+
+
So
+
+
+
fire up a new MVC3 web application
+
Jump into nuget and Install-Package System.Web.Providers
+
Sort out a connection string for SQL CE
+
Add a key to make sure the login link always points to LogOn
+
+
+
Now my web.config looks like this (edited out parts I haven't touched for something approximating brevity)
Now start a debug session for the web app. Click logon. Click Register. Fill in the form. Register. Click Logoff and stop the debug session in Visual Studio
+
+
You can see the new SQL CE database and have a look at the schema. The Memberships and Users tables have a new row. The new user.
+
+
+
+
+
+
+
+
+
+
Hurrah - all the information you'll ever need is collected.
+
+
What?! You want to know more than name and email. Now that's a turn up for the books.
+
+
It turns out you can store key-value pairs in the profiles table. I think that anyone that wrote ASP dot Net websites will be old-hand at this but I've never had to do that or this…
+
+
While you can do magic up a key-value pair whenever you feel the need to in your code it's probably better to use one of these new fangled Class thing-a-ma-bobs
which makes the Profile Provider aware of the new Profile class
+
+
Next step is to find the RegisterModel (this could be the CreateModel or some other model) and add an Address field
+
+
publicclassRegisterModel
+{
+ [Required]
+ [Display(Name="User name")]
+ publicstringUserName{get;set;}
+
+ [Required]
+ [DataType(DataType.EmailAddress)]
+ [Display(Name="Email address")]
+ publicstringEmail{get;set;}
+
+ [Required]
+ [StringLength(100,ErrorMessage="The {0} must be at least {2} characters long.",MinimumLength=6)]
+ [DataType(DataType.Password)]
+ [Display(Name="Password")]
+ publicstringPassword{get;set;}
+
+ [DataType(DataType.Password)]
+ [Display(Name="Confirm password")]
+ [Compare("Password",ErrorMessage="The password and confirmation password do not match.")]
+ publicstringConfirmPassword{get;set;}
+
+ //Added Address field
+ [Required]
+ publicstringAddress{get;set;}
+}
+
+
+
and edit the Register method in the controller
+
+
+[HttpPost]
+publicActionResultRegister(RegisterModelmodel)
+{
+ if(ModelState.IsValid)
+ {
+ // Attempt to register the user
+ MembershipCreateStatuscreateStatus;
+ Membership.CreateUser(model.UserName,model.Password,model.Email,null,null,true,null,outcreateStatus);
+
+ if(createStatus==MembershipCreateStatus.Success)
+ {
+ FormsAuthentication.SetAuthCookie(model.UserName,false);
+ //Changes here
+ //Create loads or creates a profile based on searching for username
+ varuserProfile=ProfileBase.Create(model.UserName)asCustomProfile;
+ userProfile.Address=model.Address;
+ userProfile.Save();
+ //End of changes
+ returnRedirectToAction("Index","Home");
+ }
+ else
+ {
+ ModelState.AddModelError("",ErrorCodeToString(createStatus));
+ }
+ }
+
+ // If we got this far, something failed, redisplay form
+ returnView(model);
+}
+
+
+
and finally edit the view to add an editor field for the new property. (I'll leave that as an exercise for the reader)
+
+
Now we can go back to the Register page
+
+
+
+
Register and then have a look in the profile table.
+
+
+
+
Ta da!
+
+
So there's a mechanism for extending the default profile.
+
+
Honestly, it feels messy and since at this point if there's a need for any data access layer then since there'll be a link on user name or user id anyway it's likely a better idea to have the additional data in the DAL and fangle the authentication and user models together in a ViewModel.
+
+
+
+
Having gone away and checked some code committed on another project by the lovely OrangeTentacle that's what he's done. So having figured it out for myself I'll probably go and crib off that much tidier code
Disclaimer: I use and love an iPad (1). I've got an iPhone, mac mini, a MBP and an iMac. But I'm not an out and out fanboy - I'm a windows admin and nascent C# developer. I try to use Linux where it fits and find more places it fits all the time. And I've been developing an Android application.
+
+
TL;DR The transformer prime is a beautiful computer but it might be true there's an iPad market and not a tablet market.
+
+
UPDATE
+
+
And then today Google release Chrome for Ice Cream Sandwich. BEST. TABLET. BROWSER. EVAR.
+
+
+
+
I am fickle and this is enough to sway me to an evens opinion between the two OSs. The keyboard keeps switching back to upper case But it is chrome beta
+
+
One brill feature is when the browser isn't certain what link you meant to click
+
+
+
+
A pop-up is launched to give you a larger target. As always with Chrome impeccable attention to detail
+
+
+
I wanted to make a "proper", "empirical" comparison between Android and iOS. So I got a Transformer Prime.
+
+
Actually this is anecdotal and written at 5am <= YMMV
+
+
The prime is more powerful than the sum of the capabilities of all computers I was within a mile of before my twelfth birthday.
+
+
As such I ran it through a full suite of tests
+
+
Watching parrots talking on YouTube with my kids
Result: beautiful screen, speakers have a tendency to buzz, youngest thinks parrot and pirate are synonyms
Reading using Kindle
Result: The wide aspect screen makes a great portrait reader. The screen really is beautiful
Typing stuff into stuff
Android autocorrect isn't as good as iOS. iOS correct is so good that people stop checking it and so you get "damn you autocorrect". With Android I have to break out of my flow to pay attention to what it is suggesting.
Sending emails
Why can't I edit the body of the mail I'm replying to when in HTML?
Do I keep missing the space bar because of the task bar at the bottom of the screen
spoiler: yes
+
+
A) iOS is a consumer operating system in a way that Android isn't
+
+
+
+
The first time I was handed an iPad I fell in love. I immediately grokked how to use it. I bought one. My kids use it (18 months and 4 year old). They've tried but they haven't broken it. I've seen children and adults with little or no experience of computers pick iOS up super-fast.
+
+
+
+
I handed the Transformer to my 18 month old and with two-screen presses she had turned off wifi. This device isn't kid proof in the way that an iPad is. My eldest when she under three taught my Dad how to use YouTube on iOS.
+
+
But a lot of this ease of use isn't specific to iOS. Touch-screen visual metaphors more closely mimic how we interact with the physical world - so a touchscreen OS doesn't need explanation in the way that a traditional desktop OS does. And neither Apple nor Google invented touch-screen gestures. Although that's not say they haven't patented them.
+
+
Second) visual metaphors are really important
+
+
The first time I picked up an Android device I had to have it explained to me so I could navigate. At that point in time iOS won out with it's one big button approach.
+
+
But that was Honeycomb and in ICS Google (or whichever genius did it) have sorted the problem I had…
+
+
+
+
In Honeycomb my eyes didn't immediately get that metaphor. I read it as Left, Up, Windows. Not as; Back, Home, "Windows" i.e. multi-tasking. So I had a tiny barrier to using the system. And in the MTV-diseased, Radio-1-attention-span world a tiny usability barrier is actually a big usability barrier (you know what I mean - don't confound user's expectations)
+
+
I wanted to change application and my brain only knew how to do that in iOS mode.
+
+
+
Go back to the desktop 2) pick an application 3)???? 4) Profit < meme apology />
+
+
+
In ICS the home icon is much, much, much, much clearer. So the barrier to understanding of a new user and specifically to an iOS user is lower.
+
+
But once I was over that initial hump I do like the back button. Although it can take a second to figure out where it will take you. I've found three use-cases
+
+
Horizontally through an applications activities
Vertically between applications
In the browser it appears to function as a traditional back button and only jumps out of the browser back to the previous app when it hits the earliest page in the current tab's history <= I might be wrong here since I do still find it confusing
+
+
Using a tablet or phone you are interrupted by tweets, emails and the like and I do enjoy that in Android I can jump out of what I'm doing; check out the picture of a cat smoking a pipe and then quickly return to my previous task.
+
+
So in my scientific and empirical appraisal of ease-of-use iOS wins. The first iPad2 I bought for the organisation I work for I gave to a member of staff and said "You can have this for a week or two to try it out.". Two days later they came to work and said "Erm, I know you won't believe me but my laptop is broken can I keep the iPad?"
+
+
** IT departments want their staff constrained but enabled. **
+
+
You constrain them because you don't want them hacking away and inventing methods of doing things because that's when they delete all the files or map a share to some level of hell and release a demonic file-type that ruins your afternoon. On the flip-side constrain them too much and they will figure out the most convoluted and surprising mechanism for completing a task (almost always in Excel with VB macros) and then expect you to support the jawless hound they've created because (and here I'm stretching the metaphor): "My dogs tongue keeps getting muddy"
+
+
I'm really not sure which tablet OS (and yes there are only two players) has hit the right mix of constraining and enabling.
+
+
So guess what YMMV. Get the tablet that fits yours or your user's needs. There's not much between them - they're both usable. Why don't we all make web apps (spoiler: I don't know) If you already use and like Android and you want to buy a tablet - definitely get the transformer prime.
+
+
I'm not really sold on the clip-on keyboard but then I tend to plan my daily typing amount in advance and if I'll go over an arbitrary amount of typing I take a laptop.
+
+
The transformer is a gorgeous piece of hardware. Now to hack iOS onto it… what's that you can't do that kind of thing with iOS…
So it occurred to me that my kids might enjoy The Lion King (they like roaring). Our TV is really a computer and is hooked up to the internets allowing all kinds of iPlayer and similar streaming goodness.
+
+
I guess I'm not unusual in that when I want to find something I google it…
+
+
+
+
+
+
Notice anything about those results… yup, only one of them is legal (I guess). iTunes is in 6th place there. This means they're likely to only get about 4% of clicks on this result set.
+
+
+
+
This was taken from http://www.optify.net/inbound-marketing-resources/new-study-how-the-new-face-of-serps-has-altered-the-ctr-curve an Optify Study that is no longer available.
+
+
My aim here is to buy the film… not to pirate it. To buy it. Google gives me one option.
+
+
I get myself a stiff drink so I can wash away the taste afterwards and search using Bing (I refuse to use it as a verb) and it doesn't even have iTunes as an option…
+
+
+
+
Am I unusual in that I want to buy downloads of movies? Is it only my choice of search terms?
+
+
Or are the content owners getting it ass-backwards?
+
+
Surely if the content was available cheaply for single-use streams there would be at least hundreds of thousands of regular customers… do they not want that? Am I being naive?
+
+
+
+
Do people still have no way to hook the internet up to their TV?! Oh god - that might be true! What an awful, weird idea. My kids have absolutely no idea what is going on when we visit someone and they can't choose what to watch or adverts come on.
+
+
I'd love to be able to get content through a Netflix (or some other subscription). I'd pay more in order to get access to a wider range of content.
For years now I've not bothered buying a satnav because maps on my iPhone has been good enough… sometimes a bit dodgy (once taking a route more fitted for a mountain bike) but generally serviceable.
+
+
Taking a trip from Manchester to Kettering this weekend with only my iPhone on iOS6 and the missus' on iOS5 was eye opening. Also, bleedin' awful… - 'drive around a roundabout twice in confusion' awful.
+
+
I really did give it a good go but this image sums up the difficulty faced using iOS6 maps.
+
+
+
+
+
+
Above you can see the difference. Google's maps app on the left has natural features so you can navigate by looking at what is going on. It has contrast so tiny country roads are still visible and it has words on it so that you can… well… see what's going on.
+
+
Apple's maps app (on the right) let's me see I'm where I am… apparently a desert. And that I'm near the A14. Missing roads, very little detail and difficult to read.
+
+
On first sight I thought that iOS6 maps looked clean and fresh in comparison to Google maps and I bet a lot of people who don't really use it will never be disabused of that impression. Unfortunately it's clean and fresh because it doesn't have any stuff on it. And a map without stuff on it is a square.
+
+
This really is a dreadful setback to my one device dream.
Each thing has a name and a location. The one is, to some extent, meaningless without the other. What I want is that if you enter a name or a part of a name then you get a list of things whose names match. If you enter a place then you get a list of things sorted by distance from that place.
+
+
I'd like the search function to be as unobtrusive as possible and to my mind that means that the user shouldn't have to tell me whether they've entered a name or a place.
+
+
The problem I have is that sometimes the name of the thing is the name of a place. When you type in that text expecting to search in the context of it being a place I currently have no way of letting you override the context of it being the name of a "thing".
+
+
The question is do I catch only that scenario - as in this first set of mockups…
+
+
+
+
I like this because the intention is pretty clear and the UI doesn't contain elements to muddy the intention unless we're already in a situation where we might need to make additional decisions.
+
+
But if there's a use-case or an incorrect result state that we haven't accounted for the user could find themselves stuck - I can't think of it but that doesn't mean that it doesn't exist.
+
+
So we could add a toggle that allows people to tell us what they want to do - as in this set…
+
+
+
+
I worry that there's more to parse on this screen but also, I wonder if it makes the fact that you can search by address more discoverable.
I dealt with an unusual requirement over the last few days. And wish I'd understood some of the more unusual ways that big numbers are handled in C#, Entity Framework, MS SQL and Oracle
+
+
+
+
That requirement came about in the development of an App that will act as an API for a bunch of sales data. The data is provided by another 3rd party exported from their Oracle database.
+
+
That data ultimately ends up in pretty graphs on an iPad.
+
+
When I received the first set of demo data I noticed both negative IDs and 9 digit ids.
+
+
This immediately made me worry about whether we had the right data formats (everyone worries about data formats, right?) and I asked the question.
+
+
It turns out that the DB schema that the data is ultimately sourced from has the ID column defined as NUMBER(38).
These IDs are used in the MS SQL DB Schema that we're importing into so I can't ignore the possibility of an ID coming in with this massive value. So there're three distinct problems here…
+
+
+
How do I represent these numbers in .Net (C# 4.5 to be precise)
+
How do I have Entity Framework 6 map these potentially massive IDs
+
How do I represent these numbers in the schema
+
+
+
Representing a Vigintillion in Dot Net
+
+
A quick journey to MSDN and we can see that if we restrict ourselves to integral types then we have int and long… In short one of those will hold a lot, lot less than NUMBER(38) and the other a lot less.
+
+
All is not lost. Since .Net 4 we have had access to BigInteger which allows for arbitrarily large numbers.
+
+
OK, so we can actually import the number into memory… that's a start
+
+
Using BigDecimal as an ID in EF6
+
+
Let's fire up an EF project, create an entity model with a BigInteger ID, and add a DbSet for that model to a DbContext:
+
+
+
+
Having an integral type ID at this point and running Enable-Migrations from the console would work without complaint but with BigInteger as the Id an exception is thrown…
+
+
System.Data.Entity.ModelConfiguration.ModelValidationException: One or more validation errors were detected during model generation:
+
+HugeNumbers.Proton: : EntityType 'Proton' has no key defined.
+
+Define the key for this EntityType.
+
+Protons: EntityType: EntitySet 'Protons' is based on type 'Proton' that has no keys defined.
+
+
+
Adding the [Key] data attribute doesn't help.
+
+
How about fangling the ModelBuilder directly?
+
+
+
+
Progress! Kind of :
+
+
The property 'Id' cannot be used as a key property on the entity 'HugeNumbers.Proton' because the property type is not a valid key type. Only scalar types, string and byte[] are supported key types.
+
+
+
A negative result is still a result. So this is definitely progress! The scalar types in SQL include numeric which can hold 38 digits. Huzzah! And answers the question of how to represent the ID in the database.
+
+
So can we have a numeric ID in EF?!
+
+
So long as we can define a value type key we can have numeric in the DB. Ta da!
so unless there is some funkiness possible with NHibernate (which I've never used in anger) then I'm guessing they've made a similar design decision to the EF team. And it wouldn't be possible there either…
+
+
In conclusion
+
+
+
+
Entity Framework is not yet ready for storing an identifier for every proton in the universe and if you might want to be storing 38 digit identifiers (a phrase which I'm assured by my five-year old daughter actually kills int32.MaxValue fairies every time it is uttered) then you aren't going to be using Entity Framework and I'd guess you aren't going to be having a good time.
+
+
And straight from the Magic Unicorns mouth
+
+
+
@pauldambra As you concluded, it's not possible to map BigInt with EF. Easiest solution is probably to bypass EF for that data.
+
+ — Entity Framework (@efmagicunicorns) November 22, 2013
"open source, high-performance distribution of MongoDB".
+
+
+
On a current project we're using MongoDB and, as the system is likely to scale fairly heavily, worrying (primarily) about storage. So, I picked up a task to compare MongoDB and TokuMX.
+
+
+
+
My test machine was a MBP with an SSD and 16GB RAM (Hear me roar!). I created a Debian 7 VM using VMware Fusion with 2GB RAM and then cloned it so that I had two identical linux servers.
+
+
I installed MongoDB on one and TokuMX on the other.
+
+
A NodeJS script was used to repetitively insert 6000 records and then query over the data in a single collection while only one of the two servers was powered on. I didn't clear out the databases between runs although this didn't appear to impact on the results. The script used is available on GitHuband feedback on better tests or mechanism for performing them is welcome!
+
+
The tests were run using asynchronous queues with varying levels of concurrency in order to try and simulate a relatively realistic load.
+
+
Update 2021: The data gathered used to be found on Google Docs but the link is dead now. It must have been in my FootClicks google account :'( Sorry posterity
+
+
The first set of tests were run against a collection with no indexes set.
+
+
This first test showed that TokuMX query time was much better when searching on a non-indexed field.
+
+
+
+
+
+
This performance difference larger disappeared when querying an indexed property.
+
+
+
+
+
+
TokuMX was still slightly ahead and across all of these datasets was much less affected by the level of concurrency in use.
+
+
The real stand out difference here was looking at the amount of storage being used.
+
+
After the sets of tests against each server I ran du -shb /data/db to get the size of the entire database in bytes.
+
+
MongoDB was using 10303 bytes per record stored and TokuMX only 104 bytes per record stored.
+
+
These might not be the best measures to use or the best way to gather the data (and I'll gladly try other mechanisms) but on a first glance it appears there is a compelling case to consider using TokuMX over MongoDB
I was once complaining about having difficulty setting up a very slightly unusual feature in a Drupal site that was taking forever to achieve. The framework made so many assumptions about what I should do that it wouldn't let me do what I wanted to.
+
+
+
+
A freelancer commented that if he was quoting on a project that had a requirement that it use a given CMS he didn't quote any less than building from scratch. He had found it didn't make enough difference to the effort he'd spend…
+
+
This stuck with me and matches my experience so far. (yeah, yeah, confirmation bias. I know)
+
+
+
+
I spent this past week doing maintenance work on a Django website. The ceremony involved in the Django part has outweighed the time spent designing the new HTML and creating the new page significantly.
+
+
Some of that delay is that I'm new to Django (and Python), sure, but at points, even when I'd come to understand what Django wanted, I still had to spend time poking it with a stick before it would allow me to display HTML in a browser.
+
+
So?
+
+
My position is that a CMS can be overkill. They speed up the initial setup for a website but then can slow down subsequent features. I'd argue you can provide the features of most CMS with relatively little effort by embracing modularity and the capabilities of modern JS.
+
+
Edit/Addendum
+
+
As Dan points out in the comments Django != CMS either. I call out above that I'm not experienced with Django. I've worked with it twice. And both times Django had been used to build a CMS.
+
+
Importantly, both times I was able to deliver almost every necessary change by editing JS files.
+
+
I'm not saying that Django is bad per se (although Ireally didn't enjoy working with it). I'm not even saying that having a system to manage content on a website is bad - I can't be I'm suggesting building one!
+
+
Maybe that "heavy-weight" web frameworks may not be appropriate to build that system - on a large .Net project recently I'd argue most of the functionality the customer wanted was built with JS.
+
+
I'm primarily a .Net developer. I love C# - I think the language is powerful and expressive. I think MS are really pushing things with new language development. I grok how to build websites using it but I'm getting to the point where even my BFF language isn't necessarily my first choice.
+
+
Really all I'm saying is that I've discovered I heart JS for making web things because I've found it gets out of the way and lets me build things.
+
+
+
+
The basic idea for this blog series had been bouncing around in my head for a while… and the recent work with Django was the kick I needed to actually bother to write it.
+
+
Never say never but sometimes say no
+
+
So I wondered if I really could build an editable website
+
+
Proof, in other words, if proof be need be.
+
+
What is it?!
+
+
Wikipedia has a reasonable definition of a Web CMS (right now at least) as:
+
+
+
A web content management system (WCMS)1 is a software system that provides website authoring, collaboration, and administration tools designed to allow users with little knowledge of web programming languages or markup languages to create and manage website content with relative ease. A robust WCMS provides the foundation for collaboration, offering users the ability to manage documents and output for multiple author editing and participation.
+
+
+
+
Most systems use a content repository or a database to store page content, metadata, and other information assets that might be needed by the system.
+
+
+
+
A presentation layer (template engine) displays the content to website visitors based on a set of templates, which are sometimes XSLT files. Most systems use server side caching to improve performance. This works best when the WCMS is not changed often but visits happen regularly.
+
+
+
+
+
+
Administration is also typically done through browser-based interfaces, but some systems require the use of a fat client
+
+
+
+
A WCMS allows non-technical users to make changes to a website with little training. A WCMS typically requires a systems administrator and/or a web developer to set up and add features, but it is primarily a website maintenance tool for non-technical staff.
+
+
+
I'm not trying to build a CMS… something that could be packaged and distributed. I'm only interested in how long it would actually take me to build a web site that:
does anything not have server side caching these days?!
+
+
+
Can be used by someone non-technical
+
+
totally subjective…
+
+
+
+
+
(edited with links to the completed work)
+
+
So I'm going to imagineer a fake company called Omniclopse and build them a website from scratch. I'll try to provide what would be provided by a modern CMS and see how much effort that takes. And I'll blog about it as I go.
+
+
I may learn that it isn't quick to build those things (or that I'm not very good at them) but then a negative result is still a result…
+
+
I don't know what rate I'll manage to post at since I have one kid with a broken leg and one about to be born (and another not providing any more than the usual amount of rewarding distraction) but I'd like to practice using NodeJS, Mongo, and Angular. And to practice estimating my work before I begin.
This post is part of a series where I'm hoping to prove to myself that building a dynamic website with NodeJS is much more fun than using a CMS platform. See the first post for an explanation of why
I love Browserstack's awesome service. It allows you to test your websites on different browsers and operating systems. Helping reduce the need to have access to physical devices for testing and reproducing bugs.
+
+
Selenium WebDriver
+
+
BrowserStack allow automation using a Selenium web driver. You can access this with Python, Ruby, Java, C#, Perl, PHP, or Node.js. It is also possible to test publicly or locally available sites using BrowserStack.
+
+
+
+
However, after a couple of hours trying to write tests following the documentation and attacking Google I wasn't getting very far. I was able to run tests on Browserstack and take screenshots to prove the page was loaded but I couldn't assert against the page. Frustration had begun to build!
+
+
I haven't used Selenium before and I didn't grok how to assert against the page. I'm sure it was how I was reading the documentation but I wasn't moving forward. And then I discovered nightwatch (by reading to the end of the documentation but still…)
+
+
Nightwatch
+
+
Nightwatch is awesome! It only took a few minutes to get to the point where it was possible to run tests using it. The API is terse and expressive and it will output jUnit results so can be plugged into a CI pipeline.
+
+
A nightwatch test for the front page looks like:
+
+
module.exports={
+ "Test the home page":function (browser){
+ browser
+ .url("http://omniclopse-v0-1.herokuapp.com/")
+ .waitForElementVisible("body",1000)
+ .assert.elementPresent("#homeCarousel")
+ //must have at least one image
+ .assert.elementPresent("#homeCarousel .item img")
+ .end();
+ },
+};
+
+
+
This demonstrates a very clear API. Load the page, wait till the body is visible, then assert that the carousel is present.
+
+
How to run the tests
+
+
Running this at the terminal using:
+nightwatch -t end-to-end-tests/* -c end-to-end-tests/settings.json
Here the settings file sets the location of the tests folder(s), how and where to start Selenium and the capabilities of the browser to use for tests. Also my, fiendishly obfuscated, BrowserStack credentials
+
+
Passing in a settings file like this means that different browser settings can be setup and run separately. For example:
Which would allow running all of the nightwatch tests against different operating systems and browsers on BrowserStack.
+
+
Viewing results
+
+
+
+
Some more realistic tests for the home page
+
+
Switching out the test for carousel by id and instead testing by class (as this is less likely to change) and adding in some other tests for the page contents gives:
The combination of BrowserStack and Nightwatch made for a fantastic experience. This is definitely going to be something I wrap into my day-to-day work.
This post is part of a series where I'm hoping to prove to myself that building a dynamic website without a CMS is comparable to building one with a known CMS. See the first post for an explanation of why
In his awesome book, "Don't Make Me Think" (shameless affiliate link), Steve Krug drives home the message that time spent figuring out how your site is supposed to work is not time spent deciding to engage with your site. So, we're not going to do any ground-breaking design work for this company web page.
+
+
+
+
When people visit the site they should understand straight away how they're supposed to use it. An image search for 'company website' shows the same design over and over again - and, I expect, you'll be instantly familiar with it.
+
+
A logo, a navigation bar, a large carousel or image area, some content in columns below, and a footer.
+
+
){: loading="lazy"}{:loading="lazy"}
+
+
There are relatively few company websites that step away from this basic design. And this site for (the hopefully fake) 'Omniclopse' isn't going to stray from this format.
+
+
Layout
+
+
The site is going to use Twitter Bootstrap for layout and custom styling will be written with SASS instead of directly as CSS.
+
+
Twitter Bootstrap because I'm familiar with it, I can expect others to be familiar with it, and while there is a risk that the site ends up looking like every other site built with Bootstrap the intention is specifically not to worry about breaking design records - the site should aim to use a visual language that the visitor already speaks.
+
+
SASS because it is so much nicer writing SASS than CSS.
+
+
I like my HTML templates to actually be HTML so when Express is setup the default Jade view engine will be removed and a Handlebars view engine will be used instead.
+
+
I haven't used a Handlebars view engine with Express before so I'll need to do a touch of Google-Fu to find one.
+
+
So!
+
+
To grab bootstrap and jQuery (which bootstrap depends on) I'll use Bower. If you're playing along you can download them directly (but that's no fun, right).
+
+
At the terminal: bower install bootstrap -Sa
+
+
Which downloads bootstrap into the project and adds the dependency to the Bower file.
+
+
+
+
Bower, by default, adds everything into a bower_components directory so we tell Express about that in the Express app config:
This requires two layout files be added to the site:
+
+
+
+
Here main.handlebars is the default base layout and home.handlebars is rendered by the method that responds to the root route.
+
+
At this point what the site does hasn't changed how it does what it does so the single test (useless as it is) still passes.
+
+
Building out the Base Template
+
+
Starting to build out the page requires setup to use SASS.
+
+
Gulp
+
+
There is an express plugin that will transpile SASS files when CSS requests are served but, as I want to use Gulp for some linting and minification tasks later on, this is the time to plug Gulp into the project and set up a watch task to transpile SASS to CSS.
and after a bit of fangling to build out the (admittedly ugly) page:
+
+
+
+
The code for this page can be found tagged on github and at this point there's nothing groundbreaking (nor should there be). You can visit the site here on Heroku.
+
+
There are bits of the page HTML that I'm not happy with but that can be changed as the site work progresses.
+
+
The single test in the project still passes but that doesn't really prove anything. So the next post is going to be a short aside about using Selenium and Browserstack.
This post is part of a series where I'm hoping to prove to myself that building a dynamic website without a CMS is comparable to building one with a known CMS. See the first post for an explanation of why
There's quite a lot going on there if you haven't used Mocha or Supertest then head off and read about them. How they work is out of the scope of this post. But what we're asserting here is that if you ask our server application for the root route then you get some HTML and HTTP status 200.
+
+
The simplest express server that makes this test pass is:
I've been thinking about what people call the objects they pass around and whether they are the right names and why… and when… and I feel like the dog running behind the television to see where the onscreen dog went - on the verge of a paradigm shifting change in perspective but not quite getting it (and possibly a bit smelly)
+
+
+
+
DTO
+
+
The most common is DTO or Data Transfer Object. Fowler has a definition "An object that carries data between processes in order to reduce the number of method calls." He extends this clarifying it should be an object that can be serialised.
+
+
This out-of-date article from Microsoft also defines this as an object that is used to reduce the number of calls to a remote interface in a distributed system. I suppose Android's Intent are an example of serializable objects that communicate between processes without using the web - although I don't know enough Android to be sure about that.
+
+
However, in this MSDN article DTOs are defined specifically as objects with properties but no methods used to isolate presentation from the domain - what Fowler calls "localDTO".
+
+
LocalDTO i.e. using DTO to describe objects passed between layers of a single application is so common that Fowler has subsequently written to clarify:
+
+
+
Some people argue for them as part of a Service Layer API because they ensure that service layer clients aren't dependent upon an underlying Domain Model. While that may be handy, I don't think it's worth the cost of all of that data mapping. As my contributor Randy Stafford says in P of EAA "Don't underestimate the cost of [using DTOs]…. It's significant, and it's painful - perhaps second only to the cost and pain of object-relational mapping".
+
+
+
A relatively brief online search suggests there are more definitions that describe a DTO as between remote processes as opposed to between layers of an application (here for example or here).
+
+
Of the ten hits for "Data Transfer Object" on Google right now eight agree with Fowler's definition, one is Fowler's Value Object page, and one is a J2EE definition for a transfer object which specifies that it can be used for transferring data between tiers - in PoEAA Fowler tells us that the Java community have since moved away from calling these classes Transfer Objects.
+
+
So it appears that while it is common to call objects passed between application tiers (at least in MS circles) DTOs it isn't technically correct but grew out of an out-of-date J2EE usage of DTO including in its definition moving data between tiers.
+
+
Domain Model
+
+
In the quote above local DTOs are used instead of passing Domain Models. Fowler defines a Domain Model as "An object model of the domain that incorporates both behaviour and data." In Patterns of Enterprise Application Architecture (shameless affiliate link) he expands and in describing a Domain Model says:
+
+
+
+
As a result I see two styles of Domain Model in the field. A simple Domain Model looks very much like the database design with mostly one domain object for each database table. A rich Domain Model can look different from the database design, with inheritance, strategies, and other Gang of Four patterns, and complex webs of small interconnected objects.
+
+
+
Further Fowler describes the anemic domain model where the domain model objects have little or no behaviour. This anemic model seems to be a good fit for the local DTOs described above. The solution to this anti-pattern seems to be to have read Eric Evan's DDD (shameless affiliate link) and where to implement as rich a domain model as appropriate for the application being built.
+
+
Value Object
+
+
I have a tendency to call local DTOs "value objects" but using Evan's definition this isn't strictly true. I had missed that a value object isn't only about representing the value. It's more than that. Value objects should be immutable and any two value objects are only equal when their properties are equal. As such they don't map to the local DTOs described above.
+
+
However, I've been experimenting recently with passing structs around as immutable value objects when traversing layers (and at a colleague's suggestion have amended my R# auto property shortcut to create a private setter). I prefer these immutable objects as responses from queries into the domain but I haven't done any reading around whether that's a bad idea lots of people have already had.
+
+
In conclusion…
+
+
…it seems that I really need to read DDD and maybe that the job isn't to find the correct name for an object passed between tiers but to start passing the domain model and lose the "DTOs" entirely
Yarn is a new JS package manager that promises to be fast, secure, and reliable. My initial experience is that it is fast. I'm excited about making time to use it for real at work. Kudos to the developers!
Anyone that uses NPM has probably been hit by their build suddenly failing because a dependency of a dependency of a dependency has introduced a breaking change in a patch version update. To be fair to the JS community these issues tend to be fixed quickly but that's no use while it is broken. So the fact that Yarn includes npm shrinkwrap without me having to figure out how shrinkwrap works is a boon.
+
+
Fast builds
+
+
But the biggest reason I'm excited is that yarn has a cache of downloaded packages. Because people don't check node modules into source control and npm doesn't cache them we all download lodash and its friends over and over and over again. The build for the main project I work on at the moment spends 5 minutes downloading npm packages. I resent each of those 5 minutes. each. and. every. one.
+
+
How to convert an existing project
+
+
you type:
+
+
yarn
+
+
+
seriously that's it!
+
+
and you'll see something like this
+
+
+
+
There you can see that the first run for this project with few dependencies was 2.25s but subsequent runs are more like 0.75s
+
+
NPM is consistently around 4 seconds for the same project.
+
+
+
+
If the difference was really only between 4 and 0.75 seconds I wouldn't be too excited (although not relying on other people's infrastructure to build and deploy is a big deal™)
+
+
But setting up a project with fifteen dependencies had a much more striking improvement. NPM took over a minute, yarn a little under 5 seconds.
+
+
+
+
I'm excited to get our build agents set up to see what yarn turns the five minute plus npm run at work into.
+
+
evolution
+
+
So yarn made a sensible decision. It doesn't reinvent the wheel, doesn't ask us to abandon things that work. But it promises to reduce impact of changing dependencies, reduce necessity of an external network when building software, and reduce the time spent building software. Those are really great things to improve.
I suggested that I might expect to have to make code dirtier on the road to making it cleaner. Being of the opinion that sometimes you need to add duplication in order to see your way to removing it.
+
+
As I am a creature of bad habit I jumped immediately into tortuous metaphor.
+
+
+
+
Brace yourselves
+
+
If I'm concreting in a post in my garden there's a period of time where there's a big pile of soil. I have to get rid of that to finish the job but I can't do the job without making the pile.
+
+
The thing is…
+
+
…even though it occurred to me in the moment I actually quite like this metaphor.
+
+
+
The reason the mess is there is understood by almost anyone that sees it
+
The path to clearing the mess is understood by almost anyone that sees it
+
For each additional uncleared pile of soil next to a post it becomes more obviously important to think about whether it's time to start finishing the work by almost anyone that sees it
+
+
+
Also, this only holds for a task I can complete in a day or two. If we're laying a foundation then we should probably know where the soil is going and clear it as we go.
+
+
If you were to go into somebody's garden and there were tens of posts still with a pile of soil next to each. You'd be tempted to either help them clear up or sit them down and ask them why they hadn't. Either way it would be clear it was wrong and unfinished as it was.
+
+
Can you stretch the metaphor too far?
+
+
Easily :) but I'll try not to. It is common to use physical engineering, building, and DIY metaphors for software but they often fall down because the link between one block of code and another is nowhere near as viscerally clear as the link between a hole in the ground and a pile of soil.
+
+
This is where naming, patterns, conventions, context, and physical position can be used to communicate to the future developer. And where jumping in to version control history can let you see what other files changed when this file was created or amended into its present confusing state.
+
+
But what does it look like?
+
+
I started writing up an example and then remembered that the best possible example already exists!
+
+
Sandi Metz covered this wonderfully in this talk from RailsConf 2014. It's a little under 40 minutes and well worth your time with a worked and brilliantly explained solution to the Gilded Rose kata.
+
+
refactorings are small steps
+
+
The road to clean code is not paved with many-day blocks of work. Those aren't refactorings they're only redesigns (which are fine but should probably be infrequent).
+
+That means it can be OK to add something dirty on the path to something better because you know how and when it's going to be cleaned up.
+
+
Remember to look around the garden for yesterday's mess before you start a new job
I've spent a great first day at Agile Manchester 2017. One of the slides at a talk from Anna Dick was the stand-out point of the day for me.
+
+
"Find a common language, don't rely on agile jargon"
+
+
+
+
+
+
+
George Washington was the first to say that "the hardest problem in computer science is naming things and cache invalidation" (citation needed).
+
+
However, often where we do focus on getting a name right in the code (and it's really important that we do that) we don't focus on making sure that name comes from a language that everyone understands and uses.
+
+
As a trivial example don't call something ChangeJobTitle when your users are looking for Promote.
+
+
This reminded me of…
+
+
A recent job where I was at a startup working with maths wizards to try and track shoppers around physical retail stores using only their smartphones.
+
+
The shoppers' phones not the wizards'.
+
+
The maths wizards had a complex language and so did retailers and we wanted to make sure that the retailers and shoppers didn't have to care about or understand the maths wizards' language in order to use the system.
+
+
We spent time trying to track our language use even publishing an "ubictionary". A portmanteau of 'Dictionary' and 'Ubiquitous language'. It didn't always work but we felt we were doing ok.
+
+
As we were dealing with physical retail one of the names we struggled with was 'site' vs 'store'. The maths wizards didn't need to think about the outside world so they called the indoor shopping area the 'site'. Whereas we cared about the physical location of the 'store' which we called the 'site', using 'store' to mean the indoor shopping area.
+
+
Arguably more communication sooner could have avoided this confusion but we treated these as separate bounded contexts. So we documented the two usages and moved on pleased that we'd got the name right.
+
+
Another thing we struggled with was that we could only really talk to customer proxies so the language we were trying to capture didn't come to us first-hand. Several months after putting the site/store schism to bed we managed to arrange time with two retail contacts to pick their brains and I used the word 'site'.
+
+
They knew what I meant but there was a clear moment of friction as they had to translate in order to follow me. We dug into that and they then spent five or ten minutes discussing whether it was a 'plot' or a 'lot'.
+
+
Five minutes with an actual customer had invalidated one of our most basic uses of language.
+
+
That's why I was really pleased to see this talk call out not only that we should avoid jargon and find the right language but that it needs to be a common language.
+
+
In other words (pun intended)
+
+
If you aren't talking to your users and customers and you aren't absorbing how they think and talk about the things you're working on then you're putting up barriers to communication and usability that don't need to exist.
A few years ago while waiting for a user group to start at the Manchester ThoughtWorks office I bothered a couple of the devs there about their board. That conversation, after a bit of fangling, led to my convincing the team I was on at the time to use a radar board to represent our backlog.
+
+
It allowed us to combine a fluid representation of the business's priorities with a physical representation of the cost of reorganising those priorities. But also, in a way you don't get with a columnar board, gave an immediate feedback mechanism when too much work had been proposed or accepted.
+
+
Apologies to the two ThoughtWorks devs if I misrepresent any of their good ideas as mine or my bad ideas as theirs.
+
+
+
+
+
The board was really simple. At the top right there was a small quarter circle labelled "now". Then a slightly larger one labelled "next". After that a slightly larger one labelled whatever you like to mean not-next-but-after-that. We experimented with a fourth quadrant but it covered ground so far away in time that it didn't add much distinction to the plan.
+
+
By chance I still have a photo I took as we drew an early version of the quadrants on the board.
+
+
+
+
You can see it's very straight-forward.
+
+
The radar board had the kanban board alongside it so you could see work getting closer to "now" until it was promoted onto the kanban board. We called it: radarban
+
+
+
+
Several points here:
+
+
+
+
+
I am well known for my incredible artistic skills and ability at writing clearly. As this diagram shows.
+
Bugs are a separate stream of work. You pull preferentially from that row running across the top of the board.
+
The radar doesn't have to be huge. We had room for hand-recorded metrics alongside.
+
The 'value' column is an obsession of mine. We didn't always have it. We didn't really get it to work. I think it's probably the most important thing most teams don't do.
+
+
+
What is it?!
+
+
Now
+
+
When there is capacity the team commits to work on something and moves it into 'Now'. For the team in question that's when we'd have the kick-off meeting and split it out into various tasks and stories (see below).
+
+
The quadrant represents in broad brushstrokes (what some would call 'epic' level) what the team is working on right, erm, now.
+
+
If someone has been out of the office they should be able to see at a glance what's happening.
+
+
Next
+
+
The 'Next' quadrant is whatever the business has prioritised to happen as soon as any current piece of work is signed off. Something getting into 'Next' is not a commitment to work on it.
+
+
Tracking cycle time let's you see when the tickets in Next should start.
+
+
Later / Maybe / Possibly / Probably
+
+
The third quadrant is weeks if not months out (all depends on your flow). And these tickets should be very vague because items here might never be worked on, or might change significantly before they start. If you're spending effort in this part of the board then something is wrong.
+
+
So far, so exactly like a backlog column, right?
+
+
What goes on it?
+
+
Everything goes on this board. Recruitment, holidays, business trips, when the new printer is arriving… (the list by virtue of being everything could keep going).
+
+
… …. Well, not everything, if nobody cares that a particular thing is on there stop putting it on.
+
+
Why a radar?
+
+
Physical feedback
+
+
The 'Now' quadrant is small. Those three tickets in the image above are pretty high-level and they're all that will fit in there. If somebody tried to add more work to that quadrant they'd have to overlap tickets, or crowd then together, turn them sideways… In other words they get immediate, visceral, physical feedback that they are overloading the team.
+
+
** So it would promote the conversation about the cost of a change to work in-flight or a higher load on the team. **
+
+
Expresses fluidity
+
+
+
+
It seemed that there was less mental barrier to reorganising proposed work when it was a set of concentric clouds of tickets than when it was a series of columns.
+
+
We had two. whole. whiteboards. of. backlog. at one point - guess how many people cared about the backlog when it was that big… In contrast it was a frequent sight to see the CEO and CTO stood by the radar reorganising the quadrants based on what had changed for them since it was last looked at.
+
+
Because there wasn't the implied (or explicit) priority of something being at the top of a column of tickets we avoided effort prioritising or discussing work until we were ready to move one or more of the tickets closer to 'now'. When we were ready to move a ticket we only moved whichever was best right now.
+
+
** So it would promote the conversation about what the priorities were. **
+
+
Not every idea is equal
+
+
Backlogs have a tendency to attract ideas that will never be worked on (for one reason or another). Limiting the amount of space for the backlog. And as a result limiting what can go in it forces you to maintain the backlog.
+
+
Keeping it incredibly low fidelity means people aren't invested in the idea as much and makes this process easier
+
+
** So it would promote the conversation about whether we need to or would ever work on an item **
+
+
It always works!
+
+
No, there are no golden bullets (or boards).
+
+
The context where I propose it helps is when business priorities are fluid, where they're not clear to everyone, or where the business doesn't feel the cost of changing work in-flight.
+
+
It's ok for needs and priorities to change but when they change frequently making sure everybody knows what is going on can be very difficult.
+
+
It's (sometimes) OK to drop everything because of emergencies or opportunities but it can also become the norm. It can be hard to notice that happening and to communicate the cost of that to the people asking for the changes. Walking over to the radar to say "we can move it in but we have to move something out" helps clarify this and let's everyone make a concrete decision.
+
+
Kick-off and split - as an aside
+
+
That 'kick-off and split' process was moving us towards a single-piece flow approach introduced to us by one of our colleagues Michael Dickens. There's an example here on Twitter where you can see in the centre the various tasks required to finish this piece of work stuck over a diagram of the moving pieces.
That should give you an idea of the scope of the tickets in now. Up to several pieces of work for several developers for several days.
+
+
At one point we did erase the kanban board, draw a complex process flow we needed to implement in its place, and stick post-its over that. It worked really well!
+
+
What do you absolutely need?
+
+
You need lots of space.
+
+
We had more than one whiteboard per person. So could afford three boards to describe our current and upcoming work. We were also colocated so we didn't need an electronic board (although we did have to have one and it was never up-to-date :/)
+
+
I've tried this recently with a different team. We have very little whiteboard space. We were trying to convey a lot of information in one place - it didn't work for everyone so we've moved away from it
+
+
+
+
It's a shame we couldn't make it work because even with a lack of space it was great for communicating what was coming towards the team, focussing on what we were working on, and promoting conversation about the things we were doing.
+
+
You need to talk to each other
+
+
Ultimately that's what this is about - if I haven't laboured that point enough.
+
+
This is a planning mechanism intended to force the right people to stand next to each other and agree about what is happening.
+
+
If you try this…
+
+
… I'd love to hear about it.
+
+
Tell me what worked and didn't, send me a picture, ask me questions.
(originally posted on the code computerlove blog. At the now unreachable link: https://lean.codecomputerlove.com/a-retrosperiment/)
+
+
Experimenting with a "new" retro format
+
+
For our team's most recent retro we decided to try a new format to see how it affected our discussion. We thought we'd share it here in case it has value for other teams.
A practice which has an XP team asking itself, at the end of each iteration : What went well ?
+What could be improved ?
+What could we experiment with ?
+
+
+
We've recently had several discussions trying to focus on the real and perceived progress of our work and thought it would be beneficial to run the retro with a focus on the impact of our team's principles and practices. Specifically how they relate to delivery of value and speed of delivery.
+
+
+
+
We first drew axes on a white-board
+
+
+
+
Since any and all software communication must take the form of some set of quadrants…
+
+
+
+
Then the whole team wrote on post-it notes what they thought our principles and practices were and put them on the board.
+
+
The faster that practice helps us move the further right the post-it goes. The more value it lets us deliver the higher it goes.
+
+
So what did this look like in practice?
+
+
+
+
This let us see straight away where we had different opinions across the team
+
+
+
feature flags
+
estimates
+
road-maps
+
Slack / comms
+
+
+
And where, when we agreed roughly on position, we needed to focus on if we could speed-up or get more value
+
+
This was a very different discussion than we would usually have. Anchored more in what we could change and how we might change it than how we feel about things…
+
+
+
+
It's still important to address the team's morale and individual concerns but this list of discussion points felt more focused, as we'd hoped, on what we can change to deliver more value faster.
+
+
Retroception
+
+
After a retrospective of the retrospective format the team members felt that it might have been useful to constrain the number of things we were allowed to put on the board. Or to dot vote on the items before discussing them to allow us more time to dig in to the discussion.
+
+
Why not try it and let me know if it works for you too?
…made a toot-storm about using construction as a metaphor for software engineering.
+
+
+
I've never really got on with construction metaphors for software. The cost of mistakes and rework is high in construction
+
+
+
+
+
This isn't saying that Software isn't putting things together but rather I've seen people justify not 'being agile' by using construction metaphors.
+
+
+
+
For example
+
+
+
we have to agree up front what we're going to do so that we know we're building the right thing… now go plan 19 sprints
+
+
+
(guess whether the client was certain they knew what they wanted)
+
+
So, why, do we have to agree up front what we're doing?
+
+
The builders pouring the foundations in the image in that toot were really careful they got things right before they started pouring concrete. If you pour that concrete and it's wrong, it's a big deal. Doing it twice would be an expensive problem. It isn't inconceivable that you make a mistake where it might be impossible to recover from the cost.
+
+
The bricklayers that built on top of the foundations couldn't start before the foundations were ready. Once they could start they went really, really slowly until the first few rows were in and true. After that it is amazing how fast they can add new rows of bricks.
+
+
+
They have to work in series.
+
They have to be incredibly intolerant of mistakes
+
+
+
In short they have to agree up front what they're doing.
+
+
In comparison I could run infrastructure scripts to create complex utility computing environments, test the results, tear down the infrastructure, and repeat. All for the cost of the compute time. AWS recently started billing by the second so if that only takes minutes to run it's even cheaper than before.
+
+
+
+
I can reset the state of the software to just about any point in history to see what it was like. I can experiment with swingeing changes cheaply and without impacting other people's work.
+
+
+
We don't have to work in series
+
We can be tolerant of mistakes
+
+
+
So, we don't have to agree up front what we're doing?
+
+
Also…
+
+
…I saw a few folks tweet that Allan Kelly makes the point that renting compute in the 70s cost the equivalent of 1.25 million dollars monthly but a similar amount of compute can now be bought for something more like $35.
+
+
In the context of the 70s pricing planning was cheap. But planning is now comparatively expensive.
+
+
+
+
That's all the confirmation bias I need :)
+
+
And so…
+
+
… in construction the cost of the work, or the cost of the work being wrong is higher than the cost of planning the work. Measure twice, cut once is still good advice.
+
+
That was true in Software but isn't anymore.
+
+
Because the cost of planning is comparatively expensive it is now the item to minimise. Software systems can be put together by taking many small, cheap, reversible steps. What Deng Xiaoping would have described as "crossing the river by feeling the stones."
+
+
If your software development still spends a high proportion of time planning then you need to be sure that is an unavoidable aspect of what you are doing and not a signal that you're falling into obsolescence.
+
+
For example if you're writing the software that determines whether to insert or remove the control rods in a nuclear reactor then, yes, you probably need to be very sure you know every edge case is handled correctly or successfully passed off to a human before it goes into production.
+
+
What can I do..?
+
+
For most software development now we need to be asking what the measurable outcome is, ensure we're measuring it, and start doing as fast as possible.
+
+
The harder work then is using user research to determine what direction to head in. Followed by more user research and the telemetry coming out of the application to stay on course or make appropriate corrections.
AMP or Accelerated Mobile Pages is a Google-backed project that allows you to use restricted HTML to delivery static content quickly. Since AMP HTML is restricted it isn't a fit for every site.
+
+
Since this blog is published as static HTML articles it is a good candidate for publishing an AMP version. An open source AMP jekyll plugin was amended to add AMP versions of pages.
+
+
The major discovery was that the validation tooling around AMP is awesome. Compare that to Facebook Instant Articles where there is almost no validation tooling (that I could discover at least)…
+
+
This didn't feel like a topic that justified several posts so to avoid taking too long this is a bit of a whistle-stop tour of adding AMP pages to this blog.
So, there's an <style amp-boilerplate/> element which has to be included and the <html amp lang="en"> declaration.
+
+
+
+
script elements are declared async. Not just any javascript can be included. Here the amp-analytics script is loaded to allow adding google analytics to the page.
+
+
Currently the AMP validator considers including an unnecessary script a warning and not an error but that could change in future. So the amp-twitter script is loaded but only if there is an embedded tweet in the page.
+
+
Styles
+
+
All styles are included in the head in the <style amp-custom/> element. It was found to be easier to load all styles that way even on non-AMP pages. There was no measurable difference in page rendering with styles in a linked stylesheet versus in a style tag in the head.
+
+
Previously the site used bootstrap v3 for styling (which is burned into my muscle memory). But assessing how much of bootstrap was being used (hardly any) vs. how much was being copied into the head of the page (oodles) for AMP made bootstrap a difficult choice to keep.
+
+
Bootstrap is MIT licensed so only the used styles were copied into the site's scss file. Mixed in with the custom styles there are only c400 lines of styles.
+
+
Presumably it is not true for all sites that there is no performance difference between an in-page style element and a linked sheet but there's only 12Kb of SCSS to be compiled for this site… and a third of that is for syntax highlighting of code blocks.
All images have to be fed to the amp_images filter (see below).
+
+
Structured data is apparently not required for AMP but Google's webmaster tools were unhappy if it was not present so the structured data include is added.
+
+
The main content is also passed through the amp_tweets filter as well as the amp_images filter.
+
+
+
+
+
` {{ page.body
+
markdownify
+
amp_images
+
amp_tweets }} `
+
+
+
+
+
So far so straightforward
+
+
Adding a generator
+
+
Jekyll generators run as part of Jekyll's build and "create additional content based on your own rules".
+
+
This generator is almost exactly the same as found on Github.
+
+
require'thread'
+require'thwait'
+
+ # Generates a new AMP post for each existing post
+ classAmpGenerator<Generator
+ priority:low
+ defgenerate(site)
+ dir=site.config['ampdir']||'amp'
+ threads=site.posts.docs.mapdo|post|
+ Thread.newdo
+ index=AmpPost.new(site,site.source,File.join(dir,post.id),post)
+ index.render(site.layouts,site.site_payload)
+ index.write(site.dest)
+ site.pages<<index
+ end
+ end
+ ThreadsWait.all_waits(*threads)
+ end
+ end
+end
+
+
+
For each of the posts in the site this initializes an AmpPost as a copy of that non AMP post and adds that new post into an amp folder in the output.
+
+
Site build was taking around 18 seconds after adding this generator (and the image and twitter filters). Amending the generator so that it creates a new thread for each AmpPost and then waits for all of those threads to finish reduce build time to around 7 seconds!
+
+
Adding an 'amp_images' filter
+
+
AMP images must be given an explicit size. And this filter, which is unchanged from that found on github, uses nokogiri to find each img element and convert it to an amp-image element.
The necessity to manually remember to wrap the embedded tweets in a div with the correct class is the least nice part of this whole process (but it's not the worst thing in the world).
+
+
+
+
(the tweets aren't really wrapped with florp-wrapper but using the real class meant the script was included and so failed AMP validation :/)
+
+
AMP Validation
+
+
The AMP validator is fudging awesome! It was invaluable in figuring out if I'd set this all up correctly and then identifying old posts which were only imported HTML and not Markdown that Jekyll was building. Those old posts held the majority of the AMP issues identified.
Google webmaster tools are also, slowly, picking up that the AMP pages are present. Highlighting warnings and errors and linking out to the validator.
+
+
And so…
+
+
If you're already generating articles using Jekyll it's well worth investigating a little time to get this setup. Either because it'll be interesting to do or because you believe you enough traffic from mobile devices to justify not making those readers wait before they can consume your awesome content.
One of the benefits of generating a site as a static artefact (here using Jekyll but there are a gazillion tools) is that the finished product is a known quantity. Anything that's a known quantity can be tested!
+
+
A previous post in this series looked at testing the generated HTML for technical correctness… Things like if the HTML is well-formed or that links go to real destinations.
+
+
This post describes testing the meaning of the text in the generated HTML. Checking spelling, and keeping myself honest in my attempt to use more inclusive language.
+
+
+
+
Test the markdown itself
+
+
Since the HTML is generated from markdown. Is that markdown valid?
+
+
node_modules/.bin/remark . --use lint --frail
+
+
+
Remark is a tool that allows the use of more than one plugin for processing markdown.
+
+
Here the --use lint adds the linting plugin. --frail set it to exit with a non-zero code on warnings as well as errors.
+
+
This doesn't help test the meaning. But, it does help ensure that other errors that are found are located in the meaning and not in a typo. There are still old posts I grabbed from Blogger that are very messy HTML. Periodically I'll switch one to MarkDown and this helps catch errors fast.
+
+
Even better - test the spelling in the markdown
+
+
After yet another occasion where I proofread a post, published it, read it, and immediately saw a spelling mistake. It was time to automate the solution.
The tool has a report mode which outputs spelling errors and then exits with a non-zero code. And an interactive mode that pauses on each potential mistake allowing you to choose to ignore, add to a dictionary, or to correct.
+
+
+
+
The interactive spelling mode can be pretty slow at checking the dictionary. There is an open issue about this.
+
+
As you train this tool, it populates a .spelling file so that you don't have to keep teaching it the domain-specific language you use. Mine's already hundreds of lines long.
+
+
Testing for inconsiderate language…
+
+
Alex is a tool for catching inconsiderate or insensitive language.
+
+
There is very little cost to modifying your language (replacing "guys" with "everyone" or "his" with "their"). And compared to the cost of excluding even one person, I consider it a worthwhile thing to try to improve.
+
+
Alex is run using this command: npx alex _posts --why
+
+
+
_posts tells alex which directory to start in
+
--why tries to output a source for the warning
+
+
+
+
+
he-she rule
+
+
_posts/2014-06-01-promises-part-2.md
+ 197:160-197:162 warning `he` may be insensitive, use `they`, `it` instead he-she retext-equality
+
+
+
In that text I am referring to a man. So, I could ignore the warning. By adding an HTML comment to the markDown <!--alex ignore he-she-->. In each case replacing he-she with the reported rule in the output.
+
+
Or spend the (literal) second to convert that reference to they.
+
+
A file with more errors
+
+
_posts/2010-05-08-theres-more-in-them-that-hills.md
+ 17:123-17:130 warning Don’t use “bitchin”, it’s profane bitchin retext-profanities
+ 17:153-17:160 warning Don’t use “bitchin”, it’s profane bitchin retext-profanities
+ 19:229-19:235 warning Be careful with “failed”, it’s profane in some cases failed retext-profanities
+ 25:4-25:7 warning Reconsider using “God”, it may be profane god retext-profanities
+ 31:360-31:365 warning `idiot` may be insensitive, use `foolish`, `ludicrous`, `silly` instead
+Source: http://www.autistichoya.com/p/ableist-words-and-terms-to-avoid.html
+
+
+
Here's another example of the importance of context but also the unthinking use of language.
+
+
I wrote that post in 2010. I don't use that voice any more. But, I'm ok with bitchin' in the context it was used in. But it isn't about what I'm ok with. I don't know the reader and can rephrase without it.
+
+
Next failed is profane in some cases… in this post it's talking about software failing to send emails. I think it's ok. But I can also see how to rephrase the sentence. This is about trying to include as many people as possible. It takes seconds to rephrase the sentence.
+
+
Then a warning about "Oh God it's awful" - and there I'm talking about software I wrote :/ If you've worked with me, you may recognise the feeling :p
+
+
I feel relatively strongly that blasphemy is allowed. We should have freedom from religion as well as freedom of religion. I also feel strongly that I don't go out of my way to blaspheme.
+
+
So I might choose to set Alex not to warn me about the word 'god'
+
+
I can set my .alexrc file to contain
+
+
{
+ "allow": [
+ "god"
+ ]
+}
+
+
+
Or to rephrase the sentence. There's always another way to make yourself clear.
+
+
I use words like Idiot less and less since it takes little effort to replace them. On reading the paragraph it was in so many years after writing it doesn't add anything to the post at all. So I remove the entire paragraph.
+
+
And so…
+
+
These are small changes that help make writing more accessible. I am an imperfect human and find great value in automation that helps me avoid mistakes.
+
+
Update 2021: This has been in my drafts for four years. I am going to publish it with minimal editing in the interest of progress over perfection
One of the benefits of generating a site as a static artefact (here using Jekyll but there are a gazillion tools) is that the finished product is a known quantity. Anything that's a known quantity can be tested!
+
+
+
+
Test the generated HTML
+
+
I chose a wonderful tool called htmlproofer which, since it has a CLI, can be invoked as part of the build.
Running ["HtmlCheck", "FaviconCheck", "ImageCheck", "LinkCheck", "ScriptCheck", "OpenGraphCheck"] on ["_site"] on *.html...
+Checking 310 external links...
+Ran on 55 files!
+- _site/2017/testing-static-sites.html
+ * External link http://pauldambra.github.io/2017/testing-static-sites.html failed: 404 No error
+ * External link http://pauldambra.github.io/amp/2017/testing-static-html failed: 404 No error
+ * image foo.png does not have an alt attribute (line 678)
+ * internal image foo.png does not exist (line 678)
+ * internally linking to /does-not-exist, which does not exist (line 680)
+ <a href="/does-not-exist">invalid link</a>
+htmlproofer 3.5.0 | Error: HTML-Proofer found 5 failures!
+The command "./htmltest.sh" exited with 1.
+
+
+
Three of these were expected:
+
+
+
that the image element doesn't have an alt attribute
+
that foo.png does not exist
+
and that the internal link to /does-not-exist does not, erm, exist
+
+
+
ruh roh
+
+
Interestingly this also reveals a bug in the setup.
+
+
* External link http://pauldambra.github.io/2017/testing-static-sites.html failed: 404 No error
+ * External link http://pauldambra.github.io/amp/2017/testing-static-html failed: 404 No errors
+
+
+
Grepping the generated html for those two external links finds them in the HEAD of the document.
+
+
I'd only run this process on existing, published blog posts since adding it. This is the first time that it has run against a repo with a new, unpublished blog post and it's correctly highlighting that the open graph URL for this article and the amphtml link rel for this article don't exist. Because they don't - this article hasn't been published yet.
so that the HTML test only runs after the deploy has occurred. Ideally any published documents would be tested before deploy and could fail the build and newly published documents only after their first deploy as a smoke test. But this will do for now.
+
+
Test the generated AMP
+
+
An AMP version of the site is generated at build time too. HTML-Proofer can't test the AMP site so these pages could be broken and that test doesn't protect us.
+
+
AMP is a dream to work with because the AMP debugger is well built and provides clear, actionable errors. Brilliantly that online debugger is available as an NPM package so as can be seen above there is an amp-validate.sh as part of the build.
+
+
#! /bin/bash
+
+set -eu
+
+npm install -g amphtml-validator
+
+for f in `find _site/amp -type f -name '*.html'`; do
+ amphtml-validator $f
+done
+
+
+
Because the AMP debugger was so helpful when adding AMP generation the only warning this generated when it was added to build was many instances of
+
+
+
_site/amp/2009/05/anonymous-methods-when-invoking-in-vb/index.html:633:6 The extension 'amp-twitter extension .js script' was > found on this page, but is unused (no 'amp-twitter' tag seen). This may become an error in the future. (see https://www.ampproject.org/docs/reference/extended/amp-twitter.html)
+
+
+
Each AMP page had the amp-twitter extension included whether or not there was a tweet embedded in the page. This was fixed.
+
+
And a single, old page which the AMP generator couldn't handle and so
+
+
+
_site/amp/2011/04/ssh-without-password/index.html:636:3 The attribute 'style' may not appear in tag 'span'.
+_site/amp/2011/04/ssh-without-password/index.html:667:15 The tag 'paste' is disallowed.
When these two types of test were added there were 237 HTML errors and 9 AMP warnings and 2 AMP errors. From as little as missing a favicon through to genuinely malformed pages. Adding these tests was straight-forward, added value to the CI for this blog, and is another good indication of the benefits of statically generated sites.
A way of measuring the progress being made by a software team. Not all teams use velocity. I've been on quite a few that do. So at least some teams still use it as a measure.
+
+
+
+
+
Velocity is the number of story points completed by a team in an iteration.
+scrum alliance 2014
In fact both of those articles go on to expand on the physical metaphor…
+
+
+
How do you measure your velocity while driving? (Imagine the speedometer is broken.) You've been driving for the last two hours, you've gone 160 kilometers, so you know your average velocity is 80 km per hour. scrum alliance 2014
+
+
+
A little physics
+
+
Notice that in the quote above there is a switch between "velocity" and "speedometer".
+
+
If you were driving too fast you don't get a velociting ticket for exceeding the velocity limit.
If you are told someone is moving 30mph can you tell me how long it will take them to get to your house?
+
+
No! You don't know where they are and you don't know which way they're travelling. You need to know they are, for example, due south from your house and travelling north.
+
+
You can't say anything about when and where they will arrive only from their speed.
+
+
So, what do we need?
+
+
Simplistically (let's not stretch the metaphor to routing on a map) you need:
+
+
+
a destination
+
a starting point
+
a direction of travel
+
a speed
+
+
+
Let's, for now, assume we're talking about a fixed destination and starting point (spoiler: we're not).
+
+
(Most?) Teams that measure velocity do so as if direction doesn't exist. It's a count of the work completed… it assumes you know where you are, where you're going, and that you're heading in the right direction.
+
+
It assumes that every (task|story|ticket|feature) you are asked to complete is the correct thing to do.
+
+
Do we care? Should we care?
+
+
High speed with no progress
+
+
+
+
So logically you can have a high speed system with low progress. And you can have a low speed system with high progress.
+
+
Let's labour the point…
+
+
Take two cyclists and start them at the same place with some desired destination for them to travel to. Point one of them in the right direction and the other randomly. No matter how fast the randomly pointed cyclist travels they are far less likely to reach the destination at all.
+
+
Mix in a closer to reality metaphor. Make it a journey of many legs and the likelihood that the randomly directed cyclist will ever reach the destination approaches zero pretty quickly. The other cyclist could be travelling at any speed but is guaranteed to get to the destination.
+
+
+
+
So, what
+
+
I assume a few things:
+
+
+
you want to achieve something to solve a problem
+
you want to get better at doing that
+
you don't want to waste your own or somebody else's time or money
+
+
+
In which case you have to regularly measure
+
+
+
where you are
+
where you're going
+
the direction you're travelling
+
that your speed isn't zero
+
+
+
Otherwise, like the cyclist that chooses random directions you can't expect to ever reach your destination.
+
+
In reality you aren't given random tickets to work on (or at least for your sake I hope not). Instead, with what we all know right now some group of us choose what to work on next.
+
+
You're not being pointed randomly but instead in roughly the right direction.
+
+
Taking the cyclist example again - If you can stop and re-assess your roughly correct destination you'll get there eventually but you'll still take longer than a cyclist that has better directions provided than you.
+
+
So, ok, direction is important.
+
+
But why regularly measure
+
+
Because the landscape you're building software in probably doesn't look like this:
+
+
+
+
Since we're generally operating under imperfect conditions. Trying to figure out where we are is more like being in the fog:
+
+
+
+
A friend was for a while a member of mountain rescue (who are incidentally incredible - you should give them money). They once described to me how they navigate when they have very low visibility.
+
+
+
+
In pairs:
+
+
+
use the map to figure out where you are
+
use that information to figure out what direction to go
+
using a compass one of you slowly walks in that direction
+
the other stays still and calls out when the walker is about to disappear into the fog
+
then that person catches up with the walker
+
repeat
+
+
+
Looking at the context of where they are against what they know about the world. Working together to understand what that means, right then. Watching each other and relying on communication. Chopping the journey into many safer parts.
+
+
Can this apply to software teams? (spoiler, yes, I think so.)
+
+
I've tried a number of times to work this out during sessions at Co-op Digital and XP Manchester. Many thanks to the people who shared their time and brains with my confused grasping at an idea.
We can use tools like the Cyenfin framework, Wardley mapping, and user research to understand where we are and how we want to get to our destination.
+
+
+
We can remember that we have low visibility and work closely together to make sure we aren't trying to move too far in one go. Slicing work as thinly as our context tells us makes sense.
+
+
+
We can use data from people using our software and more user research as our compass to check whether we strayed from our desired path.
+
+
+
+
TL;DR
+
+
We can and should care if we're being asked to do something meaningful. And we mustn't treat it as somebody else's work to check where we should go or whether we got there.
+
+
The number of tickets you complete is not a measure of progress by itself. Start by measuring value and only then, if ever, start counting tickets or points
Anyone who knows me knows that I like to talk about Event-driven systems. And that I'm very excited about serverless systems in utility computing.
+
+
I started my career in I.T. having to order network cables, care about fuses, and plan storage and compute capacity. It was slow, frustrating, and if you got it wrong it could take (best case scenario!) days to correct.
+
+
Over a few articles I hope to communicate what serverless is, why you should find it exciting, and how to start using it.
+
+
Let's start by defining our terms…
+
+
+
+
Utility Computing
+
+
As a name, "The Cloud™️" is terrible. It's meaningless. It totally fails to communicate what it is. Maybe it's a place you put computers? Maybe it's because applications can "scale" there?
+
+
Far better to think of "Utility Computing". United Utilities provides water as a utility to properties. Their customers know, vaguely, that there are water mains, and reservoirs, water treatment plants, and more but don't have to care. They don't think about that detail, they turn on a tap.
+
+
That's the cloud. Computing as a utility. You don't have to care if the provider is running servers or containers, if they have enough fuses in stock, or what model of switch they bought. You turn on your application and let it run.
+
+
Event-driven systems
+
+
Events are facts. They are things that happened so they are immutable. An application can store the events.
+
+
In systems that are not event driven the events are still there only they are ephemeral, implied in the API call, the change in state, the UI interaction, etc. In the event-driven system they are central to what happens.
One system registers with another. That system raises an event: PersonChangedAddress. If the "subscriber" cares it takes some action. In a system where events are notifications they might carry no information. So the subscriber still needs to call an API or in some other way load the information it needs to take an action.
+
+
+
+
+
Event Carried State Transfer (should obvs be "Event Assisted State Transfer" or E.A.S.T.)
+
+
+
One system registers with another. That system raises an event: PersonChangedAddress and includes at least the new address and the identifier for the person. The subscriber now has all the information it needs to respond to the event.
An application that separates writing to the system (commands) from reading from it (queries).
+
+
Arguably not an event-driven architecture since it can be achieved without events. But Greg Young asserts it was a necessary step to a world that has EventSourcing (in this video IIRC).
+
+
Here one application receives the command ChangeAddress. It acts on it. That action might raise an event, write to a queue, write to a database… the mechanism doesn't matter for CQRS.
+
+
Another application (or the same one in a different code path) has the responsibility for querying the system. It lets people view a list of addresses but the work of reading an address for display is much simpler (generally) than the work of accepting, validating, transforming, and storing the address on the command side.
An application can now read all three of those events to generate the state of the order.
+
+
Or it could read all of the events of type PersonChangedAddress and generate a list of all addresses in the system.
+
+
+
+
The event-driven approach has a number of benefits. Most strikingly flexibility to changes in business logic, the ability to audit what has happened, and composability. Imagine we need to report on stock and accounts changes - we don't even need to change any deployed module.
+
+
+
+
This additive approach means that every application that only reads from the stream can never add defects to existing applications!
+
+
Ok, never say never, the chance of introducing a defect at the system level exists but is far, far lower than in a change that directly affects the already deployed application's code.
Storage, database, queues, and more can be provided in such a way that they are distributed, highly available, elastic, and you don't have to manage, or maintain any infrastructure. Well, ish, you have to create the serverless components and their connections… but not the infrastructure they're going to run on (and it's patches, and new versions, and foibles, and …)
+
+
So that last system diagram could be rewritten:
+
+
+
+
Globally distributed, resilient, highly available, scalable, event-driven system. And somebody else manages all the pieces while you fill it with code.
+
+
I'm sold!
+
+
Let's use a toy system to explore it?
+
+
I love building event-driven systems but they're not the norm so it's a long time since I've had one in production. While I was off work recently I thought I'd practice. Since Serverless is the future I decided to make a serverless system. Because I know how to have fun.
+
+
+
+
Finding somewhere to take your kids can be difficult and, since it was half-term, was on my mind. It seems like there are no websites that are aware of where you are, where you could go, and what the weather might be like when you get there…
After describing event-driven and serverless systems in part one it is time to write some code. Well, almost. The first task is a walking skeleton: some code that runs on production infrastructure to prove we could have a CI pipeline.
+
+
I think I'll roll my AWS credentials pretty frequently now - since I can't imagine I'll get through this series without leaking my keys somehow
+
+
¯\_(ツ)_/¯
+
+
Putting authentication and authorisation to one side, because the chunk is too big otherwise, this task is to write a command channel to allow editors to propose destinations on the visitplannr system.
+
+
This requires the set up of API Gateway, AWS Lambda, and DynamoDB infrastructure and showing some code running. But doesn't require DynamoDB table streams or more than one lambda.
+
+
That feels like a meaningful slice.
+
+
+
+
The moving pieces
+
+
+
+
Infrastructure as Code
+
+
We use terraform at work so it would be quite productive to use that - but I wanted to try out SAM local to understand its local development story and deployment using CloudFormation.
+
+
From the docs: "SAM Local can be used to test functions locally, start a local API Gateway from a SAM template, validate a SAM template, and generate sample payloads for various event sources."
+
+
The Serverless Application Model or SAM is based on CloudFormation. With the aim of defining "a standard application model for serverless applications".
+
+
CloudFormation is an AWS specific infrastructure as code resource letting you author entire application stacks as JSON or YAML. That let's you launch "application stacks", in this case: API Gateway, Lambda, and DynamoDB.
+
+
Code as Code
+
+
AWS lambda now runs many awesome languages (NodeJS, Python, C#, Java, and Go). I 💖 JavaScript and have already experimented a few times over the last few years with NodeJS in Lambda. So will write the application in Node.
+
+
There are a number of frameworks that sit on top of AWS Lambda and API Gateway. Such as Claudia.js or Serverless. But I didn't want any of the details hidden away from me so haven't investigated them at all (which may be cutting off my arm to spite my face).
+
+
The eventstream
+
+
It is common to use dynamodb as the storage mechanism for Lambda. "Amazon DynamoDB is highly available, with automatic and synchronous data replication across three facilities in an AWS Region."
+
+
Which highlights one of the benefits of the serverless model - geographically distributed HA database by default.
+
+
It can read and write JSON, and allows you to subscribe to the stream of changes for a table. So most likely fits the needs of this application.
+
+
The SAM template
+
+
The SAM template is (once you're used to the syntax) pretty straightforward.
+
+
A header describing this template and the versions of the language used:
+
+
AWSTemplateFormatVersion:"2010-09-09"
+Transform:AWS::Serverless-2016-10-31
+
+Description:|
+ A location and weather aware day-trip planner for parents
+
There are two types of primary key in dynamodb. And this is the first design decision which will need validation in future. In fact in a "real" project this would need a lightweight architecture decision record. So let's add one here.
+
+
The first kind of primary key in DynamoDB is having only a partition key. The partition key is hashed and determines where on physical storage the item is placed. The partition key must be unique.
+
+
The second kind is a composite primary key. It consists of a partition key and a sort key. The partition key no longer needs to be unique in isolation. Rather the sort key/partition key pair must be unique.
+
+
In a real system this would probably push towards StreamName as the partition key: so that events that logically live together physically live together. And EventNumber in the stream as the sort key. So that the order of items as they are stored on physical media matches the order they are likely to be read.
+
+
This would introduce a bunch of complexity in code for tracking event numbers so for now instead of an EventNumber as the sort key the decision is to introduce a UUID EventId. This will need performance testing to check that there is no significant impact of the items being sorted by UUID.
+
+
The "ProvisionedThroughput" setting show where the abstraction starts to leak and the fact that these services run on infrastructure bleeds through. Under the hood AWS is reserving capacity for dynamodb - after all they definitely do have to capacity plan their infrastructure so that we don't have to.
"One read capacity unit = one strongly consistent read per second, or two eventually consistent reads per second, for items up to 4 KB in size.
+
+
One write capacity unit = one write per second, for items up to 1 KB in size."
+
+
So the system needs to be sized against the expected read and write throughput.
+
+
The AWS SDK has retries built in for if the AWS service throttles your reads or writes when you are over capacity. This would be an area that would need testing and monitoring in a real system.
+
+
It's important to note that the "cost" of managing that capacity setting is probably lower than the cost of creating, managing, and maintaining your own distributed, highly-available, (potentially) multi-master database cluster.
This sets a lambda function with a given handler, and runtime. The handler is the code that will run when the event is received. And sets an environment variable to reference the created dynamodb table.
+
+
Finally sets that this lambda function will be triggered by an API POST to /destination. Which is all SAM needs in order to create an API gateway to trigger the lambda.
+
+
With 39 lines of YAML SAM will provision an API gateway, a lambda function, and a dynamodb function. All highly available, elastic, and distributed geographically - that's pretty funky!
standardjs - I don't agree with all of standardjs' decisions but I do recognise that since they're largely arbitrary I shouldn't care.
+
+
+
This is a lambda function. It's about as small a function as you can write to respond to an event from API gateway. First it logs the received event. Then it tells API gateway to return a http status 200 with the body 'OK' to the client.
+
+
Anchors away!
+
+
After incurring the incredible cost of $0.02 because I kept forgetting to strip chai and mocha from the bundle I wrote a deployment script.
npm install all of the non-dev dependencies (there aren't actually any yet!)
+
make sure there's an s3 bucket to upload the code into
+
run sam package which translates to CloudFormation and uploads the code to s3
+
run sam deploy which launches the application stack
+
+
+
Running that creates everything necessary in AWS. Looking at the created stack there are more pieces created than needed to be specified.
+
+
+
+
This includes the IAM roles to allow these resources to talk to each other. These at least in part result from the config line: Policies: AmazonDynamoDBFullAccess applied to the lambda function.
+
+
This is much more access than we need. But in the interest of not getting diverted the necessity for finer grained access goes on the to-do list - it's possible but not necessary right now.
+
+
The wider than necessary access can be seen in the lambda console which lists out the resources the function can access and the policy that makes that access possible.
+
+
+
+
The API Gateway console shows the new endpoint
+
+
+
+
The endpoint can be tested right in the console:
+
+
+
+
and the results are logged in the page
+
+
+
+
And finally, the cloudwatch logs show the output from running the lambda.
In fact, increasing the RAM actually increases the underlying compute, network, threads, and more. In some experiments at Co-op Digital we saw that scaling for a network and compute bound workload was pretty important.
+
+
DynamoDB
+
+
+
+
The table has been created and is ready to be used. The config we've used doesn't actually setup the table for autoscaling. But we'll loop back around and tidy that up later. It's another detail that doesn't need nailing right now.
+
+
Let's review
+
+
With 39 lines of YAML we've created a walking skeleton to prove we can write code locally and deploy it to AWS.
+
+
We've had to learn a little about the details of dynamodb and AWS lambda where they leak their underlying infrastructure into our worlds - although presumably there's a setting equivalent to "I care less about how much I spend than how much resource you use - charge me what you like and don't bother me again". I don't want to turn that on (yet).
+
+
All the code for this stage can be found on github
+
+
And we're finally ready to write some tests. In the next post we'll look at some tests, talk about the final state of the handler, and look at how to set up locally to run integration tests.
This tells AWS to delete everything since I don't want to pay money for an application stack that nobody is using and only exists for my (unashamedly very low readership) blog.
Part One - describing event-driven and serverless systems
+
+
Part Two - Infrastructure as code walking skeleton
+
+
In this post we will look at how SAM local let's you develop locally and write the first lambda function. To take a ProposeDestination command and write a DestinationProposed event to the eventstream.
+
+
"SAM Local can be used to test functions locally, start a local API Gateway from a SAM template, validate a SAM template, and generate sample payloads for various event sources."
+
+
+
+
SAM Local
+
+
You have to have Docker running locally and then you can npm install -g aws-sam-local.
+
+
To start the API Gateway and Lambda example from part two navigate to the directory containing the template.yaml file and run sam local start-api
+
+
This starts lambda in Docker and shows what endpoints are mounted:
+
+
+
+
You can then POST to the endpoint curl -H "Content-Type: application/json" -X POST -d '{"geolocation":"xyz", "name":"test"}' http://127.0.0.1:3000/destination
+
+
Which outputs the same information as you would see in cloudwatch logs:
+
+
+
+
DynamoDB
+
+
This took several attempts to get running - mostly because of unfamiliarity with Docker - AWS were super helpful on twitter despite my silliness. Without that confusion this would have been very straightforward.
+
+
There are three steps to this:
+
+
1) Start dynamodb
+
+
DynamoDB needs to be run as a named container and on the same Docker network as SAM local
+
+
docker network create lambda-local
+sam local start-api --docker-network lambda-local
+docker run -d-v"$PWD":/dynamodb_local_db -p 8000:8000 --network lambda-local --name dynamodb cnadiminti/dynamodb-local
+
+
+
2) Create the DynamoDB table
+
+
SAM local can't create DynamoDB tables from the template.yaml in the way that CloudFormation will when the SAM application is deployed so the table needs manually creating.
+
+
The following AWS CLI command will create the table as defined in the template.yaml:
This module exposes a connect method that lazily initializes the db client.
+
+
SAM local sets an AWS_SAM_LOCAL environment variable so the code checks for that and if it is present sets the endpoint URL to http://dynamodb:8000. This is the container name and the port it exposes.
+
+
For the production code you don't need to set any endpoint and can let lambda figure out what to connect to.
+
+
The propose destination handler
+
+
The handler should act as a composition root. It creates the application's object graph and lets the parts do the work. This allows unit tests to inject fakes. If those tests were to exercise the handler directly the code would run the dynamoDbClient and timeout waiting for dynamodb.
Here the handler converts the API gateway event to a ProposeDestination command. It then either uses the existing stream repository or creates one currying the dynamodb client and guid generator.
+
+
+
+
The command handler is then called. It either converts the command to a destinationProposed event and returns an HTTP 200 success. Or fails and returns an HTTP 400 invalid request.
+
+
Testing this with SAM local
+
+
I haven't wrapped this up into something useful that could be run in a CI pipeline but as a sense check before deployment this is a good starting point.
+
+
First ensure SAM local is running:
+
+
AWS_REGION=eu-west-2 sam local start-api --docker-network lambda-local
This is not a great example of a test for a number of reasons but it does demonstrate that the running system can receive an HTTP post after which there is one more item in the dynamodb table.
+
+
+
+
The devil is always in the detail so this test wouldn't be good enough for a real system. But it does show that the lambda functions can be integration tested locally with real HTTP calls, writing to a local dynamodb.
+
+
Unit testing
+
+
The composition root approach means that the handler can be unit tested without relying on the dynamodb client. As an example testing the behaviour in the repository against a fake dynamodb, here the test locks in that the repository adds a correlation id to the item written to the stream:
Writing to the event stream can be tested with a guid generator that always generates the same guid, and a dynamodb client that doesn't connect to dynamodb. This lets other behaviour be tested without those dependencies complicating or slowing down the tests.
+
+
Testing in AWS
+
+
The integration test above is bound to querying dynamodb using the AWS CLI. It would not take a lot of fixing to have that test run against an actual API Gateway endpoint and dynamodb instance.
+
+
At this point the code is still coming together but demonstrates that there is a local dev story, the system could be tested in CI, and can run in AWS.
+
+
Extending the system
+
+
So now POSTing to Lambda can write events to dynamodb. In the next post we will look at subscribing to and responding to that event stream.
+
+
All the code for this stage can be found on github
Part One - describing event-driven and serverless systems
+
+
Part Two - Infrastructure as code walking skeleton
+
+
Part Three - SAM Local and the first event producer
+
+
In this post we start to see how we can build a stream of events that lets us create state. We'll do this by adding an event subscrber that waits until a user proposes a destination to visit and validates the location they've provided.
+
+
+
+
+
+
Overview
+
+
This slice will prove that the system can subscribe to events occurring, react to them, and write new events back to the stream. That would only leave authentication, and a read model website to build to provide all the parts needed.
+
+
Subscribing and reacting to events demonstrates one of the benefits mentioned in part one. That these systems are composable. The additional code added here won't need any changes to the existing deployed applications. But can still add new behaviour to the system as a whole.
+
+
+
+
In part three we added a command handler that could write ProposedDestination events. Here a user is saying they think there is a place that parents would like to take their kids. The application accepts this to smooth their experience (and capture any proposal) and then responds to that event by checking the provided details before listing the new destination.
+
+
+
+
So:
+
+
+
+
+
one or more ProposedDestination events occur
+
The Location Validator is subscribed to those events
+
It reads each one and validates the provided location
+
Writing the success or failure event to the stream
+
+Notice here that the validator doesn't need to know what happens in case of success or failure. It doesn't even need to know whether there are applications that do something - there's no coupling of config or orchestration.
+
+
+
Twee Example
+
+
The first iteration will be a validator that confirms that an event has a geolocation key which has a numeric latitude and longitude.
This is a bit silly but the point here isn't to see what useful location validation looks like. Think of it as a walking skeleton into which more realistic geolocation like checking the coordinate is in the UK could be placed.
+
+
Infrastructure Changes
+
+
As discussed in part two DynamoDb already has the concept of streams of changes to tables as triggers for lambdas. Updating the SAM template to add the stream changes the definition to:
This change to add the StreamSpecification YAML key sets the stream of changes to only include the new version of the item. The valid options for StreamViewType are:
+
+
+
KEYS_ONLY - Only the key attributes of the modified item are written to the stream.
+
NEW_IMAGE - The entire item, as it appears after it was modified, is written to the stream.
+
OLD_IMAGE - The entire item, as it appeared before it was modified, is written to the stream.
+
NEW_AND_OLD_IMAGES - Both the new and the old item images of the item are written to the stream.
+
+
+
Referring back to Fowler's four types of event driven systems from part One:
+
+
+
KEYS_ONLY works for "Event Notification": the receiver knows a property changed and whether it wants to act (but not what changed).
+
NEW_IMAGE could map to "Event Assisted State Transfer" (EAST) unless the receiver needs access to the old version of the data. For example to write to your old and new address when your postal address changes. And could map to CQRS where the new_image could be either the command or the result of accepting the command
+
OLD_IMAGE doesn't map to any type but would be great for an audit log or system where data mustn't be lost.
+
NEW_AND_OLD_IMAGES maps well to EAST and CQRS.
+
+
+
25 characters to add the change. Over 1200 to disect it.
+
+
The Lambda…
+
+
… is again a composition root to allow unit testing without the external dependencies.
Again some dependencies are initialised in the handler but memoised outside of it to reduce start-up time when a lambda is re-used.
+
+
It maps from the list of DynamoDB events received to a list of domain events and then passes those off to an eventSubscriber. The event subscriber has the validator and the resulting events writer injected.
+
+
The event subscriber is only interesting because it does some Promise fangling:
Both the validator and the event writer return promises. The validator only to provide a nicer API. The writer because it is IO. Because of JavaScript's single-threaded "helpfulness" this could mean that your code finishes before the promises finish handing back to the Lambda's callback and terminating your code before it can complete.
Instead each Promise is captured and Promise.all is used to convert that list of promises into a single promise that only completes when they have all completed.
+
+
Testing that takes a bit of juggling but is relatively straight-forward:
This is fantastic. All of the pieces for the event-driven back-end now exist.
+
+
It's not all golden. There's still quite a bit of manual testing necessary to check that the lambda's dependencies are declared correctly and wired together as expected. And to check that the system hangs together as expected.
+
+
At the moment that's not enough pain to stop moving forwards with the broad-brushstrokes implementation but it is getting close.
+
+
Next time we will add a read model and (depending on the length of the blog post that generates) view it via HTML.
+
+
All the code for this stage can be found on github
+
+
An aside on cost
+
+
So far this blog series has cost $0.09 in AWS charges relating to vistplannr. Almost all of which has been avoidable S3 charges.
DRY, in software development, stands for Don't Repeat Yourself. This is often taken to mean remove any duplication of lines of code. See the anti-example in the wiki page comparing to WET code - which stands for Write Everything Twice. This reinforces the idea that this is about the amount you type.
+
+
Below we're going to look at what the impact of removing duplication of lines of code does to some software, hopefully demonstrate that it isn't desirable as an absolute rule, and show what the better way might be.
+
+
+
+
We're making an internet cafe and so we need software to make internet drinks
Pretty soon after deployment disaster strikes! Barista Mike Acawfe reports
+
+
+
this latest software version is a disaster. It's adding lemon to hazelnut coffee and chocolate sprinkes to tea ordered with lemon.
+
+
+
ugh, I knew we should have tried that new fangled unit testing. All the code compiles but the position of the parameters matters in how they get from the Coffee and Tea classes to the base Drink class.
But, something is bothering you. It was hard to spot this bug because even though there's no duplication of code there's actually lots of duplication of names. This lovely DRY code uses the word milk nine times. In fact each of the ingredients is mentioned nine times. So any new ingredient means edits in nine places.
+
+
And the call through to the base class constructor duplicates the constructor on the line above. Any changes to the ingredients and you'll need to change both constructors.
+
+
You meet a friend for coffee and, since it's on your mind, ask how they would remove this last duplication?!
+
+
Each idea once and only once
+
+
Your friend explains that DRY isn't about code. It's about ideas! The reason you're struggling is that the idea that some drinks have milk and others lemon is hidden because you've treated removing lines of code as an absolute rule.
+
+
They offer to help you rewrite your code with that in mind.
+
+
The first idea that's missing is that there are types of ingredients.
+
+
The second idea is that each drink is a collection of ingredients that should be printed out for the baristas.
+
+
So you start with a marker interface and a set of data classes. Each drink then allows you to add a subset of the possible interfaces and prints out the barista's instructions.
+
+
At the same time you add the concept of temperature to milk so you don't have to have implicitly cold milk separately from warm milk.
+pour a Coffee(Milk(glugs=1))
+pour a Coffee(Sugar(spoons=3))
+pour a Coffee(WarmMilk(glugs=2),Sugar(spoons=3))
+pour a Coffee(WarmMilk(glugs=2),Sugar(spoons=2),ChocolateSprinkles(pinches=4))
+pour a Coffee(WarmMilk(glugs=2),Sugar(spoons=2),ChocolateSprinkles(pinches=4),HazelnutSyrup(shots=2))
+pour a Tea(Milk(glugs=1),Sugar(spoons=3))
+pour a Tea(Lemon(squeezes=1))
+
+
+
+
Notice the awesome toString output that Kotlin's data classes give you for the Ingredients.
+
+
Now the word milk is only in the code three times. Once when it is declared and once in each drink.
+
+
But there is still duplication of the idea that a drink can have ingredients added. In fact each drink has almost the same method repeated for each ingredient. All to avoid being able to put chocolate sprinkles in tea.
+
+
So the idea that chocolate sprinkles aren't a tea ingredient is implicit in the fact that there's no method for it. It isn't represented once and only once.
+
+
One option is to accept any ingredient to the method but explicitly refuse ones that shouldn't be added
+
+
+classCoffee{
+ classItIsNotOKToPutLemonInCoffee:Throwable()
+
+ privatevalingredients:MutableList<Ingredient>=mutableListOf()
+
+ funwithIngredient(ingredient:Ingredient):Coffee{
+ if(ingredientisLemon){
+ throwItIsNotOKToPutLemonInCoffee()
+ }
+
+ ingredients.add(ingredient)
+ returnthis
+ }
+
+ overridefuntoString()
+ ="pour a Coffee(${ingredients.joinToString(",")})"
+}
+
+classTea{
+ classItIsNotOKToPutThisIngredientInTea(ingredient:Ingredient)
+ :Throwable("It is not OK to put $ingredient in tea")
+
+ privatevalingredients:MutableList<Ingredient>=mutableListOf()
+
+ funwithIngredient(ingredient:Ingredient):Tea{
+ if(ingredientisHazelnutSyrup
+ ||ingredientisChocolateSprinkles){
+ throwItIsNotOKToPutThisIngredientInTea(ingredient)
+ }
+
+ ingredients.add(ingredient)
+ returnthis
+ }
+
+ overridefuntoString()
+ ="pour a Tea(${ingredients.joinToString(",")})"
+}
+
+
+
+
But there's still duplication of the idea. You'll have to change Tea or Coffee any time you add a new ingredient. And even though the withIngredient method only knows about the marker interface in its signature it has to know about concrete implementations of the interface to work. Yuk!
This means that new ingredients that are added shouldn't need any modifications to the drinks.
+
+
Now Drink as an abstract class reappears. The individual drinks now only need to have a type for the canBeAddedTo(drink:Drink) check. It's ok to allow code to get more complex while you're working on it as happened here when the withIngredient methods were exploded into Coffee and Tea.
+
+
+abstractclassDrink{
+ classIsNotFitForConsumptionWithThisIngredient(ingredient:Ingredient,drink:Drink):Throwable("It is not OK to put $ingredient in ${drink.javaClass.simpleName}")
+
+ privatevalingredients:MutableList<Ingredient>=mutableListOf()
+
+ funwithIngredient(ingredient:Ingredient):Drink{
+ if(!ingredient.canBeAddedTo(this)){
+ throwDrink.IsNotFitForConsumptionWithThisIngredient(ingredient,this)
+ }
+
+ ingredients.add(ingredient)
+ returnthis
+ }
+
+ overridefuntoString()
+ ="pour a ${this.javaClass.simpleName}(${ingredients.joinToString(",")})"
+}
+
+
+
+
I'm still confused by Java allowing methods in interfaces. Ingredient can be an interface but because Drink wants to override ToString it has to be an abstract class. Without that it could be an interface too ¯\_(ツ)_/¯
+
+
One idea that is still implicit is that the ingredients are printed out for the barista. So let's add an OrderPrinter and take the need to descibe itself out of the Drink
+
+
We can also take the opportunity, since we're exposing the drink's ingredients, to make them an immutable list.
This is about twice as much code as the original DRY version. But is much more flexible for adding new ingredients without changing existing code. What DRY misses is the much more expressive four rules of simple design.
+
+
+
Runs all the tests
+
Has no duplicated logic. Be wary of hidden duplication like parallel class hierarchies
+
States every intention important to the programmer
+
Has the fewest possible classes and methods
+
+
+
These are in order of importance. The code in this article is manually tested but doesn't pass this as the rule is runs all the tests. Before fixing anything else my fictional friend should have made me write tests.
+
+
Rules 2, 3 and 4 are in tension with each other. If I want to state every intention to the future reader I can't only remove as many classes and methods as possible. The wonderful design pressure as I tried to show here is that you want the smallest amount of code to communicate the largest amount of the ideas it represents.
+
+
So, stop looking for duplicated lines of code. Stop automatically making every string a constant. And start having empathy for the future reader of your code. Leave as little of the information needed to change the code in your brain as possible by putting it in the code.
OK, four months since part four. I got a puppy and have written the code for this part of the series in 2 minute blocks after sleepless nights. Not a productive way to do things!
+
+
+
+
Getting ready to make some HTML
+
+
Now that the API lets clients propose destinations to the visit plannr the home page for the service can be built. It's going to show the most recently updated destinations.
+
+
In a CRUD SQL system the application would have been maintaining the most up-to-date state of each destination in SQL and you'd read them when the HTML is requested. But this application isn't storing the state of the destinations but the facts that it has been told about the destinations.
+
+
+
As an aside a lot of people don't realise that CRUD SQL stands for C an we R eally not U se SQL D atabases they may S eem familiar but all the ORM stuff is well over our Q uota for comp L icated dependencies.
+
+
+
In an event driven system applications subscribe to be notified when new events occur. They can create read models as the events arrive. Those read models are what the application uses to, erm, read data. So they're used in places many applications make SQL queries. Now this visit plannr application needs a read model for recently updated destinations.
+
+
+
+
What even is a Read Model?
+
+
+
The query (or read) model is a denormalized data model. It is not meant to deliver the domain behaviour, only data for display (and possibly reporting).
+
+
+
+
CQRS-based views can be both cheap and disposable … any single view could be rewritten from scratch in isolation or the entire query model be switched to completely different persistence technology
+
+
+
+
both from Page 141 Implementing Domain Driven Design by Vaughn Vernon
+
+
+
A CQRS system (see part 1) separates the parts of the application(s) that receives commands to change from those that receive queries for data. Read models are the data models for the read side of the application. This lets you optimise different areas for their specific tasks.
+
+
Read models are a representation of the data built for a particular query. You can reuse read models. However in a CQRS or eventsourced system you tend to make many read models.
+
+
If Sam and Jamie both come to my house to help me garden my eventstream would be:
So each read model in a system is a different way of representing written data in order to serve a particular need. Think of them as different SQL projections or views over tables. They aren't the data they're something built from the data that lets you show it to someone.
+
+
A wonderful thing about read models (in an eventsourced system at least) is that you can throw them away. Imagine a SQL database that you can delete once you don't like its shape. In a system with read models you can change your code, reset the system that builds the read model to start at the beginning of history, and let it create the new read model.
+
+
Work an example
+
+
+
+
Let's imagine an eventsourced ecommerce application with no events. Sales and fulfilment teams need to know how much money we've made, how many orders we've taken, and what products have been sold.
+
+
We've deployed 3 separate applications that are subscribed to the empty event stream.
+
+
+
+
Big day - the first sale! myshop.com writes an event to the stream that we've sold a t-shirt. The sales, order count, and products sold read models update and any UI or report being generated using them can update accordingly.
+
+
+
+
Many days and events have passed and after the most recent cancelled order the fulfilment team let you know that it's really hard for them to figure out what's happening when an order is cancelled. They'd like a view to help them manage cancellations.
+
+
+
+
So a new read model is built and deployed to track order cancellations. The existing read models are all up-to-date on event 300. When the new application starts its read model isn't showing any cancelled orders and it has read 0 events.
+
+
(important to note that no other applications had to change at all to support this!)
+
+
+
+
+
+
The new application reads through the event stream until it has caught up. There's a period of time where it is reading through the event stream and performing any calculations or running any logic where it isn't caught up with the other read models or with the write side of the applications.
+
+
This is 'eventual consistency'. An event sourced system embraces the benefits of not trying to force all the parts of the application to stay exactly in sync with each other all the time.
+
+
+
+
As the website gets more popular storing the products sold in an array is limiting what business intelligence the sales team can gather. You can add a consumer that stores products sold in a graph database.
+
+
As your new data science capability learns what structure they want in this new data store it is possible to keep deleting the graph store and letting it recreate from the event stream. Again this is an addition that doesn't need changes to the existing applications.
+
+
Why a Read Model now?
+
+
The system has a command channel to propose destinations, and an event subscriber that validates the proposed destination. Now a new event subscriber can respond to each event in a destination stream and create or update a read model used to let people view the destinations on the website.
+
+
How to make a read model in this system?
+
+
If this system was a long running process it would start, read all the events from the beginning of time (or the last snapshot), build a read model in-memory, and start serving requests once the read model was up-to-date with the event stream.
+
+
It also subscribes to the event stream so each subsequent event written to the stream is applied to the read model store. Even with millions of events in a stream once the system has caught up it is only applying one event at a time. Only applying one event can be incredibly fast!
+
+
And as in the graph database example above read models don't have to be in-memory. They can be pretty much anywhere. You can run graph databases, document databases, sql databases, and flat files side-by-side as read models for different uses.
+
+
Serverless systems only run for the lifetime of each request and so need to start as fast as possible. Building the read model from scratch on-start can be treated as too slow and we'll decide to store the read model in dynamodb.
It initialises a stream reader and a model writer then curries a handler function which receives the event that triggered the lambda. Accepting a terminalEventType so destinations that shouldn't be shown to users yet can be filtered out. Finally waiting for any dynamodb writes to be gathered and passes those promises back to the executing environment so it can wait for them to complete.
Remember each event is appended onto the end of a stream of events that represents an instance of a particular domain concept. So each destination has its own stream of events that make up the history of that destination. This code reads the stream name from each of the events that triggered the lambda and reads all of the events from each of those streams from dynamodb.
each stream of events is applied to a destinationReadModel which are filtered to keep only those with the desired status. Those models are then written to dynamodb so other applications can query them.
Building the read model involves taking each event and updating a model based on the event type. Here you can see how this code is tolerant of events it isn't expecting - it will ignore them.
+
+
There's no validation that the data being read from the events is present. Whether there should be validation at this stage is context dependent. Here we wrote the event producers and know that for there to be a geolocationValidationSucceeded event both name and geolocation have to be present. We can trust that the read model will be good enough for now.
+
+
What's next?
+
+
Now that read models are being stored in dynamodb the next step is to generate a home page. Because the read models are writing to a dynamodb table they can be treated as a projection (read models that can be treated as an eventstream and subscribed to) and we can generate static HTML when the read models change.
In part 5 the code was written to make sure that whenever a destination changes the recent destinations read model will update. Now that read model can be used to realise a view that a human can use. We'll add code to create a HTML view behind AWS cloudfront. This will demonstrate how event driven systems can be created by adding new code instead of changing existing code.
+
+
+
+
Where were we?
+
+
+
+
The system so far allows an API call to propose a destination someone might want to visit. When that ProposeDestination command is received after a little validation a DestinationProposed event might be saved to DynamoDB. A lambda is subscribed and when that event is raised validates the location of the destination - you can't visit somewhere that isn't anywhere after all. That lambda saves either a geolocationValidationSucceeded or geolocationValidationFailed event to DynamoDB.
+
+
Right now there are no consumers of the geolocationValidationFailed event. When one is necessary, for example to let the destination proposer know we need their help to correct the record, nothing already written has to change. A new subscriber would be added alongside.
+
+
The last change was to add a subscriber to any event in the stream. An event being received is a strong indication that a destination changed so its job was to make sure that destination is stored or updated in DynamoDB.
+
+
Most systems only save that final data and throw away all the other lovely information. Maybe they come pretty close to saving the same information because they write it as log messages. A form of event stream that is very difficult to consume.
+
+
ReadModels are Projections are ReadModels
+
+
If you're familiar with SQL then you've typed something like Select name, thing, clink, andStuff from myTable before now. That list of properties is the projection. The structural representation of the data in the store that will be the query result.
+
+
Since a read model is a representation of the data that is provided for one or more reads or queries then a read model is a projection.
+
+
Generally speaking you can say either ReadModel or Projection. Some people distinguish between ReadModel as a set of data and Projection as a stream of that data which might be a useful distinction.
+
+
Where does this change take us?
+
+
This set of changes puts the system in a position to be able to serve a HTML home page that shows the most recently changed destinations. Get the champagne on ice this start-up is heading to exit.
+
+
+
+
This change adds two new lambdas (or subscribers, or consumers).
+
+
Creating HTML
+
+
The destination stored to DynamoDB is our read model but in the beauty of an event driven system can also be subscribed to. This means we don't have to read from DynamoDB when somebody wants to put that data into HTML to display to a user.
+
+
+
+
Because the system is event driven we know whether the data has changed so we have an hook for cache invalidation. That means the system can generate HTML whenever the set of destinations changes.
It acts as the composition root, gathers dependencies, injects the dependencies into the system, and handles the event. So the code can be tested completely decoupled from the dependencies.
+
+
The actual code is straight forward. Read something from one place, transform it, and write it to another
So now whenever there's an event the HTML is templated and written to S3.
+
+
Invalidating the Content Delivery Network's Cache
+
+
The bucket that the templated HTML is written to is being served as a static site behind the CloudFront CDN. A CDN is a bunch of computers that cache a copy of your content close to the edge of the network so that it can be delivered to users as quickly as possible.
+
+
Because the HTML is behind a CDN writing to the bucket isn't enough. The CDN carries on serving the old cached content. So writing to S3 will also need to invalidate the CDN's cache.
+
+
That could be done in the same lambda as writes the event to S3 but writing to S3 is itself a lambda trigger. So we can encode the behaviour "when the static content changes invalidate the cache" instead of "when this particular reason for the content to change happens invalidate the cache".
+
+
Having a separate lambda continues to demonstrate you can take advantage of the additive nature of an event driven system.
In what should be a familiar pattern now the dependencies are gathered, curried into the actual application code, invoked, and the results passed back out to the lambda environment to signal success or failure.
+
+
+
+
The notable difference here is the introduction of a new AWS dependency: AWS SSM. Simple Systems Manager (SSM) is a wide set of services to let you manage and configure Amazon AWS systems. The piece being used is Parameter Store.
+
+
This is a service that allows you to store plain text or encrypted config. Used here to store and provide the cloudfront distribution id. Why Parameter Store is being used is covered below.
+
+
The handler then uses the timestamp and the event to make a unique(ish) id for the invalidation and shapes the correct call to CloudFront to invalidate the cache.
+
+
+
+
What made this a fast change?
+
+
Almost everything necessary already existed
+
+
+
test mechanism
+
event streams
+
CloudFormation templates
+
+Continuing to bang the drum for why event driven systems are so productive… Almost the entire change was the functional code to read, transform, and then write. Because the system complexity has been pushed up to the architecture the individual blocks can be simple.
+
+
+
Both lambdas were written in an evening.
+
+
What blew up and stopped it being a fast change?
+
+
CloudFormation was not happy with what I was trying to do… In setting out the template to add the CloudFront distribution, static site bucket, policies allowing public read from the bucket, and the two lambdas I created a circular dependency.
+
+
And had no idea what to do next :(
+
+
+
+
Luckily I know how to toot! And the lovely Heitor Lessa from AWS gave me some pointers. I particularly love that he laid out part of the path without giving me the solution - I didn't have the tools to investigate myself but will do next time now.
+
+
In the CloudFormation template the cloud front distribution ID was being set as an environment variable on the lambda that would need it. But from the help provided
+
+
# This Environment block creates the circular dependency
+## CF needs S3 to be created first
+#### Lambda needs CF and S3 to be created first
+##### S3 needs S3->Lambda permission to be created first
+###### [Fails] S3->Lambda permission needs Lambda to be created first
+###### --> This circles back to point 2
+
+
+
This seems to be an unavoidable effect of how CloudFormation works partly because I couldn't use an S3 bucket as an event source for a lambda if it wasn't defined in the same template. So I couldn't split the templates and pass data as identifiers from one to the other.
+
+
My colleagues were particularly helpful
+
+
+
+
The best solution (we could think of) was to put the ID into parameter store from the cloudformation template to break the circular dependency.
+
+
+
+
I've been avoiding abstractions like terraform or the confusingly named serverless framework while writing this series so that I understood the nuts and bolts and this was the first time I came close to regretting this decision. Always frustrating to have things broken without knowing what to do next :'(
+
+
Two standout pieces of advice I received:
+
+
+
The SAM template will generate additional CloudFormation resources for you (to save you typing them). You can reference them in the template.
The !Ref CloudfrontInvalidatingFunctionRole is referencing a role in the template that isn't in the template until SAM has converted it to a full CloudFormation template o_O.
+
+
I think this is confusing but it's good to know.
+
+
+
You can use cfn-python-lint to lint CloudFormation templates. It gives much better output than you get elsewhere!
+
+
+
Cost
+
+
There was a lot of CloudFormation stack creation and deletion as a result of all of this. So I was very disappointed to see that it had pushed my monthly bill up gigantically.
+
+
+
+
This might seem like a silly point but creating a similarly resilient application with a serverful architecture would probably be
+
+
+
1 load balancer and 2 virtual machines for the application
+
3 virtual machines for the eventstore
+
1 load balancer and 2 virtual machines for an API gateway
+
+
+
(yep, and networks and security groups and and and)
+
+
That gives a monthly cost of at least $100 standing idle. I'm much happier to be stung for 6 cents.
+
+
What's the TODO list now?
+
+
We have most of the basic building blocks but only someone comfortable calling an API directly can propose a destination. The next steps from a system behaviour perspective will be to start to add a UI to propose destinations. This will start to call out the need for authentication and authorisation if it doesn't demand it outright.
+
+
From a developer's health perspective we've got quite a lot of code now. There's no bundling so the upload to S3 contains more than it needs to and it's JS - I love JS - but there're no types which can start to get confusing.
+
+
Also any system level testing is all manual at the moment which isn't good enough. There needs to be a way to visualise what is there, what it is doing, and that it works.
At the 2019 Manchester Java Unconference I attended a discussion on "Cloud Native Functions". It turned out nobody in the group had used "cloud native" but I've been working with teams using serviceful systems.
+
+
I have a bad habit of talking more than I should but, despite my best efforts, the group expressed interest in hearing what teams at Co-op Digital had learned in the last ten months or so of working with serviceful systems in AWS.
+
+
We defined some terms, covered some pitfalls and gotchas, some successes, and most of all our key learning: that once you can deploy one serviceful system into production you can move faster than you ever have before.
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
Seeking to build "a constellation of high-quality projects that orchestrate containers as part of a microservices architecture."
+
+
So, cloud native functions are (container based) systems that allow you to run functions as a service (Faas).
+
+
Function as as a Service (FaaS)
+
+
These are compute environments that let someone deploy a function that will run in response to events triggered by the environment.
+
+
AWS, Azure, and Google Cloud Platform all have a FaaS offering. There are systems like kubeless that let you run infrastructure (or rent it from someone else) and run your own FaaS environment on top of that.
If I only convince you of one thing in this post I want it to be this: none of the items in the "installable platform" section are Serverless. Doesn't mean they aren't potentially valuable to someone but…
Boil it down to this: there is no installation, configuration, or maintenance of servers for the owners, and builders of a service in a Serverless system.
+
+
In most cases your team (or worse a different team in your organisation) will provision, manage, patch, security scan, and deploy servers either physical or virtual. Unless you sell the compute those servers represent then you don't make money only by running those servers.
+
+
+
+
In this image we can see that adding containers or kubernetes might make your systems "Serverless" to a traditional development team, one that has no access to or responsibility for infrastructure. But it increases the amount of infrastructure to provision, patch, and scan for vulnerabilities for your organisation. It increases the amount of things to manage that don't directly add value.
+
+
It's only as you move to a system like EC2 fargate or GCP cloud run where you only bring the containers that you start to reduce the amount of infrastructure management you need to carry out.
+
+
I'm partly excluding managed kubernetes from that or at least withholding judgement. A little because I'm not familiar enough to say if it meets this definition but also partly because in Amazon EKS you are still responsible for bring the machine images that kubernetes worker nodes run on. So you're still responsible for the scanning and patching of those images.
+
+
+
+
On the right you then have what most people think of when you say Serverless which is something that should probably be called "Serverless with FaaS compute". Serverless has existed (if not named) since tools like S3 became available. FaaS allows you to more obviously include your business logic to tie together the various available serverless services.
+
+
Here you tradeoff not being able to bring your own application framework with the freedom of having an almost zero maintenance load. So long as you scan your dependencies, and perform some static or dynamic analysis of your code you can offload the responsibility for the rest of the maintenance and management of the system to the utility provider.
Instead of concentrating on not having servers. Concentrate on making best use of services. The example my colleague uses is that if you want a file system you almost certainly want NFS because it's an excellent file system. But that generally speaking you don't really want a file system you only want somewhere it is easy to put files. As a result you should use S3 (if you're in AWS) because that's a really easy way to store files.
+
+
In a serviceful system you should default to consuming the service. The service doesn't come with the provisioning and maintenance burden of the not-service. Even if the not-service is in some way better it needs to be a lot better to justify its cost.
+
+
+
Yes, NFS is great but use S3
+
Yes, RabbitMQ is great but use SQS
+
Yes, ${MVC Framework of choice} is great but use API Gateway and Lambda
+
etc
+
etc
+
+
+
Technical debt vs Accidental complexity
+
+
To aid some of the below…
+
+
Technical Debt
+
+
Most teams call an awful lot of things "technical debt". I like to restrict it to one particular thing… decisions we made on purpose to do something with a poor level of technical correctness because it let's us get to production faster. Technical debt is not a bad thing - so long as you are disciplined about replacing the bad thing with a better version once you've proven the need for it.
+
+
Accidental Complexity
+
+
A lot of teams call this "technical debt" without distinguishing it from "technical debt". Accidental complexity (defined by Brooks in 1986 in the "No Silver Bullet" paper) is complexity that we add that doesn't need to be in the system. As distinct from essential complexity that does need to be in the system.
+
+
E.g. we wrote a tax processor which handles complex tax rules… and we wrote our own queueing software to do it. The essential complexity of the tax rules might be swamped by the accidental complexity of the home grown queue.
+
+
Or we repurposed the existing Oracle analytical DB to support our website because it already handled the complex business logic. The essential business logic complexity might be outweighed by the workrarounds needed to make an analytical DB look like an online transaction processing DB.
+
+
(not that I've been burned by inheriting decisions that look like either of those two ;))
+
+
Blimey charlie that's a lot of definition of terms!
+
+
Let's see if it helps…
+
+
Background / Context for my experiences
+
+
I work with a team that build customer, member, and offers systems for the Co-op. At one point the team was 200 people from 3 different consultancies. It's now only a few more than 20.
+
+
200 people working to a short deadline even bringing their best selves every day can introduce an awful lot of technical debt and accidental complexity.
+
+
Dealing with that debt while adding to and fixing our systems was making us very slow. We chose the principle of preferring immutability and composability at every level. Choosing serviceful systems has enabled that and meant that we make most things such that they can be added alongside what already exists. That means we can work without adding to the already high maintenance burden of the serverful systems that exist.
+
+
That lets us deal with technical debt and accidental complexity at a different cadence than we deal with our sponsors' and users' needs. We already run in AWS so we chose to use AWS lambda for FaaS and DynamoDB for (sort of) key-value storage. We were already using SQS (queue), SES (email), and S3 (storage).
+
+
Event driven and asynchronous or GTFO
+
+
The first thing to accept is that this is an event-driven approach. You have to approach the design of your system as lots of little things talking to each other by raising events (albeit implicitly). If you can't or don't want to then you're not going to get on with this way of building things.
+
+
Where something is synchronous (e.g. an API call) you have to know that you can process and respond in a short enough time or that you can fake a synchronous system. For example if you can always succeed (at least after retry) then return 20x to the calling client, put their request into SQS, and move on.
+
+
In most cases you should already be thinking of your system as little, independent things talking to each other by sending messages. However, it was fascinating to have someone in the JManc discussion group that worked at Elastic on ElasticSearch. Such a different development context and you could see that things that were absolutely true for them didn't make sense for me and vice versa.
+
+
(Always important to remember that we all say "pattern" a lot and that means: a problem, a solution, and a context. Here we saw how a change of context meant a good solution in one context was a bad solution in the other)
+
+
Empowering if you empower
+
+
When I joined this team only QAs were allowed to deploy to production and only platform engineers made any infrastructure changes. It was inherited behaviour and it was debilitating for productivity. It also meant that folk with deep expertise in important tasks were snowed under with trivial tasks that didn't require their expertise. Because they were siloed the different groups sat separately and worked separately so shared very little understanding of each others needs and difficulties.
+
+
+
+
The stability, reduced complexity, and reduced attack surface of Serviceful systems has helped give us the confidence to collapse those silos. Software engineers now regularly write terraform, platform engineers and QAs join the mob, and folk sit together.
+
+
We also noticed people starting to thank each other as they got to know each other and understand the work being done. Of all the things we've achieved together this is the one I'm most proud of. So while I wouldn't argue the behaviours are unique to serviceful systems I wouldn't want to leave out the contribution they made.
+
+
Cheap and fast and slow
+
+
Cheap
+
+
Cost isn't the most important thing - developers can cost much more than infrastructure. But we've been building entirely servicefully for more than a year now and our systems do more than they used to but at worst our AWS bill has been flat over that year. We use cloudability to track our spending and that predicts a 10-20% drop in bill over the next 12 months based on change over the last year.
+
+
+
+
In fact one of our engineers has paid his salary in cost reductions on our inherited Serverful systems. That almost certainly means we've invested upwards of $200,000 since the team was launched that could have been avoided. Engineers are more expensive than infrastructure so let's guess that we invested $1.5M to create that avoidable $200k. Arguably, that's going on for $2M invested not to achieve any value at all. At best it was scaffolding that enabled the valuable work. At worst, avoidable in its entirety.
+
+
Serviceful systems were less mature back when that investment was being made so it may well have been the right investment then… but they're much more mature now. To the point that it should be your default choice. Your context might force a different choice. But my assertion is that teams should assume they're building Servicefully and discover where they can't.
+
+
S3 and dynamo are our highest serverless cost. Lambda is effectively free still despite running production workloads and underpinning the majority of our scheduled infrastructure tasks.
+
+
DynamoDB was rising in cost. We discovered this was because we were setting tables to fixed provisioned capacities. In order to fix a performance issue we set Dynamo to "on demand" i.e. serverless mode. Not only did that fix our performance problems but also reduced cost by about 80%. The moral of the tale here is you get forensic visibility into the cost of what you're running. But you have to make sure you're using a service like cloudability and are checking what you're spending.
+
+
+
+
You have to make sure you are looking at the cost profile of the services… AWS Cognito is cheap as chips, AWS Cognito with Advanced Security suuuuupeeerrrrrr expensive.
+
+
AWS API Gateway is super cheap and has per request pricing. While Azure API Management service you pay to reserve capacity so at much lower traffic levels (comparitively) you could end up spending more than running an API gateway yourself. You can't assume Serviceful is cheaper but when you cut with the grain there's a good chance it is.
+
+
and fast
+
+
These services are (in our experience, in AWS) rock-solid, stable, and fast. But they're also fast to build. Once you know how! The group building Offers took two weeks to get their first API Gateway > Lambda > DynamoDB system into production. They took one day to get the second out.
+
+
It's now faster for the team to create two competing designs of a thing and then measure them than to research which might perform better. As you build capability at this way of working your pace can grow much more easily.
+
+
and slow
+
+
But you are also accepting that you are leaning on a framework that you can't play around with. We use a number of existing dependencies that live inside a VPC (a private network in AWS) and so we have to deploy some lambdas inside that VPC.
+
+
At the time of our first implementations cold start of a lambda function in a VPC took a pretty consistent ten seconds. For an offline batch process that doesn't really matter but if you connect that up to an API that's abysmal.
+
+
Since that JManc discussion AWS have released a fix to that performance issue. But it's a great example of how you may have to accept the tradeoff of not being able to build exactly what you want in the way you want in order to get the benefits of the serviceful approach.
+
+
It's also a great example of why I'd recommend AWS for Serviceful/utility hosting. The speed at which they iterate and improve based on customer feedback is startling.
+
+
Commit to learning
+
+
This is a relatively new way of making systems and pushes you into less familiar approaches. If you start down this road you should make a point of introducing protected time for individual and group learning. We definitely missed a trick here and it took longer than necessary to get good at this.
+
+
You should have protected learning time anyway but especially while you introduce something so new to everyone.
+
+
One of the things that helped fantastically was the team's practice of preferring to mob on work. That's helped keep everyone moving their understanding along at the same rate.
+
+
The next steps the team needs to take are to start to formalise and describe some of what we did so that other teams can start to take advantage of it.
+
+
This is forking awesome
+
+
We're doing more, with fewer people, at greater value, and lower cost. And it's been a genuinely joyful process.
+
+
I'm more than happy to stick my flag in the ground and repeat from above that serviceful systems are more than mature enough and more than valuable enough that you should have to justify why you're not using them.
Since October 2017 I've been keeping week notes. I've found them a fantastic tool to track my focus and to remember to reflect on success (or lack of it).
+
+
Some colleagues and sometooters have written year notes as 2019 ends. And here are mine… It feels egotistical… but hopefully it's useful to me in the future even if it isn't to anyone else.
+
+
+
+
Being a Principal Engineer
+
+
+
+
I spent 2018 seconded into this role and 2019 officially in it. The teams I work with are achieving great things: reduced complexity, reduced cost, increased stability and throughput, and regularly deliver same day fixes (down from 10 days for simple fixes). Check the Customer and Member section in this Co-op blog. But even two years in I find it hard to see the value I'm providing and to unlearn a lot of the not-principal-engineer habits I'd worked hard to learn.
+
+
The biggest being…
+
+
Feedback loops
+
+
My feedback loop is really long - months sometimes. Maybe that was always the case and I didn't see but it makes tracking impact hard. It feels like this got better over the year but large organisations tend towards silos and I've found that tends to increase the length of and decrease the quality of feedback loops.
+
+
This is important to me and I can't think of a goal… that's worrying.
+
+
Staying out of the way vs getting in the way
+
+
Making a balance between letting the team get on with things and stepping in to influence, coach, and set guide rails is really hard. A lot of my experience was working solo as the only tech person at a not-for-profit or in roles where I was embedded as a member of a team. Acting alongside several teams is very different…
+
+
As an example from recent months: remembering to care that we lint our JS and not which linter we use was hard (although no semicolons 4 life obvs). Then noticing that folk kept replacing the linter and that I need to step in and make the arbitrary choice and let them get on with smashing it is important. (maybe growth would be knowing that somebody needed to step in and helping someone else do it)
+
+
Knowing which gear to change into so I'm letting the teams be creative but keeping them on track is something I have no idea how to measure if I'm doing well… So I suppose my goal is to start 2021 with a better relationship with being a "leader" (I still put that in air quotes every time I say it).
+
+
Making time to write code
+
+
Making time to write code with the teams has been critical for my sanity (and I think my effectiveness). Recently I spent time with the folk building offers.
+
+
Partly because a tight opportunity/deadline needed support, partly because it was fun, partly because my instinct was that was the next important thing for me to do.
+
+
+
+
But it gave me space to talk to them about the four rules of simple design, get confidence in their abilities, help them get used to a new (to them) codebase, and expand some of our design decisions while in context. Plus I 💖 cutting some code.
+
+
I have to figure out a way to make this a regular part of my role without using it as a mechanism for procrastination. And I should ask that group for feedback on how it felt for them!
+
+
WeekNotes
+
+
I've really valued the focus on reflection. Particularly around trying to find a new feedback loop I can lean on. I started them without any plan and now realise it's a shame they're images on twitter. I can't even find the first one :(
+
+
+
+
At the moment they're really in google docs. Cos I can make them on the train home. I need to find a train-friendly way to be able to write and publish them easily without relying on a walled garden.
+
+
+
+
Being part of a big organisation
+
+
Sometimes you can get a glimpse of how a tiny improvement in a big organisation can have a huge impact and that keeps me going. Things like visiting one of our food distribution centres and realising the massive technological and human effort that we're a tiny supporting player to. Or being part of the systems that have helped Co-op members give £17m to local causes.
+
+
We started a monthly conference instead of our weekly community of practice. I was worried that the extra time commitment would mean people didn't attend and I was so wrong. There are enough of us that the monthly unconference is one of the best things about working at Co-op. Kudos to Gemma Cameron for having the vision and making it happen.
+
+
+
+
But, despite the openness and willingness to improve we see in colleagues across this massive beast of a company, large organisations are inherently pathological. Some groups work in such a way that shows they see the plan as the goal. A thing being on-time and on-budget becomes more important than it being valuable. And that thing being valuable is a side note. Things are made that are either not measurable or not measured.
+
+
+
+
I'm not sure how best to contribute to improving that. It's easy to fall into an agile echo chamber - thinking if you turn up with some post-its, a whiteboard, and a jenkins server everything is solved. It'll be hard, but important, to hold true to our principles while showing the same willingness to listen and change that we're asking of folks in the "Enterprise" (disappointingly not a spaceship).
+
+
For now I'll concentrate on moving to a place where we deliver frequently and show commitment to measuring value. Tidying our own house before we complain about someone else's.
+
+
Talking
+
+
2019's Week 1 weeknotes mentioned a colleague Graham Thompson saying: "we're aligned because we talk". That turned out to be the theme for the year. Over and over we discovered our problems by talking and solved them by talking.
+
+
But multiple times we also saw that the team spent less time fixing or building something than we'd spent talking about whether we should.
+
+
This year I want to try to swim against the current of our meeting driven organisation and focus on face-to-face communication as part of what we're working on.
+
+
I also have a 140+ day streak on duolingo learning Italian. Non c'è un serpente nei miei stivali. I'll aim to practice every day this year.
+
+
Go-live is marketing
+
+
In 2016 I went to watch James Jeffries talk at the leanmanc usergroup and the other speaker, Andy Mayer, said something along the lines of "because you're releasing to production and learning constantly go live should be driven by marketing".
+
+
We've seen the value in that approach over and over in 2019.
+
+
Week 4: "🍾 “Legacy” DB System we've been replacing has now been strangled away and nothing uses it anymore"
+
+
Week 40: "🦄 team's third significant "go live" that was so smooth it was almost an anti-climax"
+
+
Week 45: "💪 Deployed a new system to replace part of another system while that system was under sustained load. Bold and seamless"
+
+
That week 4 release was the end of 9 months and more of at least two people working full time. It was a significant change and affected multiple business units.
+
+
Go-live was announced at standup with: "oh yeah, MODS is primary for reads and writes now". Running in production as soon as and as meaningfully as possible is a forking super power.
+
+
+
+
Master, Black list, Guys, and more
+
+
+
+
I've consistently spent time trying to refocus my use of language this year. Things like using primary or trunk instead of master, exclusion list instead of blacklist, folk or skipping the word instead of guys.
+
+
This seems like the least I can do to promote inclusion. It's not enough but it's something.
+
+
For a while we had a non-binary colleague who used they/them as pronouns. I definitely wasn't good enough at managing that. It was such a clear example of how unconsciously I use gendered language. I tend to speak in a stream of consciousness style and I need to practice speaking purposefully.
+
+
Even if I only make one person feel included or avoid excluding them then the effort has been worth it.
+
+
Running
+
+
I used to cycle 1000km a year plus. I don't now. Largely because cycling in Central Manchester is a horrible experience. But I still snack as if I'm cycling twice a week all year :(
+
+
So I decided I needed to step up my game. I ran 35 weeks of the year. And averaged 6.5km in those weeks. Better than I expected. And a good start. But I want to double that this year.
+
+
Which suggests my maths need to improve since there aren't 70 weeks in the year. Let's say: 10km average over 40 weeks of the year.
+
+
I'll also give up shaming myself for not cycling 27km to work and aim to go for some rides for fun when the weather picks up.
+
+
Walking
+
+
+
+
This is the first full year I've had a dog since I was a teenager. Best decision in a long time. As much work as having a baby but it adds joy to life.
+
+
dog on new years day 2019
+
+
+
+
dog on new years day 2020
+
+
+
+
+
+
Kids
+
+
+
+
+
+
+
+
All three kids have said they don't want to be on social media so I won't mention much here. Watching them growing into sensible, curious, wonderful, talented nerds despite my terrible parenting is the most incredible thing.
+
+
They also have learned to amuse themselves by saying: "blink and I'll be in college" when I'm distracted by my phone and they want my attention.
+
+
They deserve my attention. We used to have "family screen-free day" once a week. That's coming back!
+
+
What writing this taught me I want to do in 2020
+
+
+
+
+
decide what feedback loops I want to shorten
+
find others that want to do that and work with them
+
expect to find better ways of doing it by including others
+
read about leadership and get over myself
+
make time to write code and find out from the teams how they'd like me to do that
+
figure out how I can write weeknotes as easily without images in twitter being the main record
+
move to a place where we regularly measure and report on our work
+
speak face-to-face with individuals instead of in big meetings
+
practice Italian every day
+
use the unfair super power of being a white, middle-class, middle-aged, straight man to lift others up
Since October 2017 I've been keeping week notes. I've found them a fantastic tool to track my focus and to remember to reflect on success (or lack of it). I didn't write them for most of 2020. When pandemic hit it seemed too self-centered. I wish I'd kept them up now.
+
+
I wrote year notes last year. Surprisingly that was the only blog post I wrote last year 😱
+
+
Here are mine for 2020… It feels egotistical… but it's intended to remind me to reflect. Hopefully it's useful to me in the future even if it isn't to anyone else.
+
+
+
+
Goals from last year's year notes
+
+
and whether I achieved them or not
+
+
+
❌ decide what feedback loops I want to shorten
+
½ find others that want to do that and work with them
+
✅ expect to find better ways of doing it by including others
+
½ read about leadership and get over myself
+
½ make time to write code and find out from the teams how they'd like me to do that
+
+
✅ figure out how I can write weeknotes as easily without images in twitter being the main record
+
❌ move to a place where we regularly measure and report on our work
+
🤣 speak face-to-face with individuals instead of in big meetings
+
½ practice Italian every day
+
+
❓use the unfair super power of being a white, middle-class, middle-aged, straight man to lift others up
+
✅ 10km running on average over 40 weeks of the year
Maybe measuring goals once a year is a bad way to achieve them 🤔
+
+
Running and Cycling
+
+
I went for 1 bike ride. I could easily have made time to do more.
+
+
I ran 644km in 2020. That's 12.4km a week on average. I'm really pleased with that. I bet I wouldn't have managed that if it wasn't for…
+
+
…Lockdown
+
+
I suppose it would be weird not to mention lockdown and COVID this year. I'm lucky to live close to the countryside, in a house with space, and to have a job I can do remotely. Not everyone is that lucky but lockdown has been nice for me. Instead of 2 hours a day crammed on a train I've seen my family, played the guitar, or walked the dog.
+
+
+
+
Because I'm in the house I could help with the kids more. We realised that because I could do the school run my wife could work more.
+
+
It's definitely affected the "speak face-to-face" with individuals goal 🤣. But I've been for a walk a couple of times with colleagues who live nearby and both times that was golden.
+
+
Working remotely has been pretty great despite a background of massively increased anxiety. Given I shouldn't expect to live every year with the worries of this one I think I'm sold.
+
+
Being a Principal Engineer
+
+
I'm still uncomfortable with saying I'm a leader. Less so than in the past. But I think it's because culturally we have a hierarchical view where the leader is important and has all the power and ideas. I don't think I behave like that. I certainly try not to. I can see the pressure towards and ease of becoming an ivory tower architect.
+
+
In a world where the leader is there to help, to have a wider viewpoint, to join things together, and to lift people up, then I'm not uncomfortable. Then I'm scared. That sounds hard. It is hard.
+
+
In 2020 I worked with the Co-operate, and the Customer & Member teams and we all contributed to a "membership evolution" programme. You can read about what we achieved in our end-of-year blogpost. That meant I was working across five teams and with a programme group. At times it was too much.
+
+
Doing too much
+
+
COVID massively reduced what we were asked to do. That was such a gift.
+
+
As a result of doing less we did things better. We did (probably) the important things. And at the end of it all we still celebrated. We still achieved goals. Nobody was mourning the missed things. The company turned a profit.
+
+
Every year we should routinely chop a third out of what we aim to do. (obvs people would start to include sacrificial work to game the system but…)
+
+
Context, direction, and measurement
+
+
I need to get better at clarifying and measuring things. And at talking to people about that. My colleague Nathan Langley was incredible at that this year. They stuck at it. From day-to-day influencing, to rolling their sleeves up and making prototypes, months locked in a room working to make things better. Finally pushing through adoption of a way of communicating strategy and vision and linking them to concrete activities. Such a cool thing. And now other teams are picking it up. It is scary how rare it is for people to communicate the basics. And it's amazing how powerful it is.
+
+
+
+
For most of my time on Membership there was no communicated and agreed vision. Many of us believed we knew what it was, some of us even agreed. But we couldn't write it down and point at it. Nate changed that. 🔥💖 (like, loads of people were involved but he was influential and consistent)
+
+
I'm joining a new team in the new year. Finding a way to orient myself, choose action, and check the outcome is still going to be as important. But will be even more in a new (to me) business where I don't have years of context.
+
+
I need to remember it's new to me… not to the folk already there. I'll bring my perspective but before that I need to bring my ears
+
+
(which is a clunky way of saying I need to remember to listen)
+
+
A slight aside to say what I think "the basics" are
+
+
+
Why would I start?
+
When do I stop?
+
How do I know it is working?
+
+
+
I see so much work that can't answer those questions. Any framework or process that doesn't remind you to answer those questions should be yeeted into the sea.
But if you're not measuring value then you don't need the accelerate metrics. They might help you do the wrong thing faster.
+
+
+
+
Black lives matter
+
+
Supporting and growing inclusion is the most important thing I can do
+
+
+
+
This year was already raw. And then George Floyd was murdered by the police in America and something broke. He wasn't the first or last person killed by America's racist system but something caught fire. Doing nothing, saying nothing wasn't ok. I said something about it at our weekly show and tell. I wanted folk on the team to know that their BAME colleagues hurting and for those BAME colleagues to know that if they needed time or support we'd try to help them. It was the hardest public speaking I've ever done.
+
+
+
+
A couple of times over the last few years I've been asked to come to a meeting to repeat something a woman has been trying to have heard with my man-voice so people will hear it. I'd not given the feedback to the people not listening. I promised myself I'd used up my feeling-too-awkward-to-say-something credit and the next time I saw misogyny or exclusion I'd say something. And the next time I saw misogyny it was on a call with hundreds of other people. So, I said something… I nearly didn't because I wasn't comfortable. Luckily I was able to "say something" with text which made it easier. But I'm glad I did. It was the right thing to do.
+
+
I'm not claiming some expertise or moral high ground on this. I'm sharing some of the small things that I have done cos I want a world where we all do the small things. They add up to impact if enough people do them.
+
+
I know I'm not doing enough, I know I need to learn more, you almost certainly need to as well.
+
+
Things I've thought about more thoroughly than this blog post
+
+
Since I joined Co-op I've worked on Membership. I've been there three and a half years. This year I move to work with Funeralcare. This year has been characterised by knowing that I was likely to move but not when or where to. Figuring out how to work so that the things important to me might carry on when I'm not there is hard.
+
+
I'll be watching to see what happens and trying not to judge myself too harshly
+
+
There are two bits of writing as a result of leaving membership that it felt right to record here
Today's my last day on Membership at Coop Digital. After three and a half years I move to funeralcare in the new year. I thought I'd reflect on my time…
+
+
lines of code is a terrible metric: was the opinion I held until I checked and discovered that since July 2017 I've deleted more code than I've added. Overall, I've deleted 1.5 million lines of code. That makes me happy even though I know it's a terrible metric
+
+
Kindness and empathy are key. When I've got that right it's been 💯. When I've got it wrong it's been 💩
+
+
This year we made 600 changes, at a higher change success rate, and with better availability. And the systems we built and work we did had more value for the business. We've more than doubled the rate we deploy changes over the last few years
+
+
We used to have very slow deploy pipelines and joke we could deploy in-between visits to our sites. In an emergency we can now get (some) changes tested and to prod in minutes. And we have hundreds of thousands of active users
+
+
I still feel a bit uncomfortable thinking of myself as a leader but I'm not (completely) scared of it any more. Maybe time to stop winging it and learn something. I'm lucky to have great peers to learn from
+
+
+
+
I'm increasingly convinced that giving positive feedback is a super power, and that it pays back much more than negative feedback. But I can see times where I've avoided giving negative feedback and things have been much harder than just having the "difficult conversation"
+
+
shutting up and asking questions is really hard (for me). knowing when to stop asking questions and make statements is even harder. But the times when I've got that balance right have been incredible
+
+
Twice in the last few years people have told me they feel safe on the team. Very few things feel as good as that
+
+
Once someone was brave and told me how I was achieving my goals made their job harder. That didn't feel good, but I value it as much, if not more
+
+
+
+
leadership (maybe just how I do it) magnifies your reach but so also your mistakes. A bad decision I made in Jan of 2018 is still sat in need of defuckulation now. It's hard not to obsess about those mistakes
+
+
Building a culture of celebration and sharing is really hard and really, really important
+
+
Drawing diagrams is a super power.
+
+
The best thing has been learning how much I still have to learn. I had no idea what I was getting into when I took the Principal role, how hard the shift would be from working in a team to working with teams. I'm so glad I did it, I'm so proud of what the teams have achieved
+
+
+
+
slacking about my time on Membership
+
+
I wrote some words in our slack channel when I left the membership team (which I can't completely recreate here cos of secrets and intrigue)
+
+
+
+
keep up the kindness
+
+
When someone does something well, tell them.
+When you wish someone had done something better, tell them.
+When someone breaks something, tell them it’s ok, tell them about when you broke something. Have I told you about the time I deleted the record of every insurance sale at The BMC?
+
+
We have to have a job, it’s up to us to make sure we enjoy it
+
+
people and interactions over process and tools
+
+
Process isn’t a good in and of itself. scrum, kanban, user stories, squads, and more are all attempts by people to describe what worked for them. There’s a risk you’re taking advice from a pastry chef while making a casserole.
+
+
We should be being agile not doing it.
+
+
keep releasing small pieces of things
+
+
We made almost a third of Co-op Digital’s recorded changes in 2020, at higher availability, and with better success than the years before. There are few engineering practices more effective than ensuring that changes to code and config make it, safely, to production in the shortest possible time.
+
+
Aim for minutes from commit to prod! What is needed to make that possible?!
+
+
The things you need to do to make this possible are what good engineering is.
+
+
Slow down
+
+
I see us regularly spend all week smashing out feature work. It’s wonderful that we’re committed to what we’re working on. But we have to force ourselves to make time for socialising, learning, and tidying up.
+
+
There’s a good chance we’re moving faster than sponsors, users, and the team can maintain. It’s time to slow down a little and find a more sustainable pace. You have to weed the garden as well as growing plants.
+
+
We’ve seen over the last year folk giving the teams space to make things in the right way. It’s on us to take that time and use it well.
+
+
Take part in service and support
+
+
Our work is not only about making great things, it’s about keeping them great. Learning from and reacting to what really happens is a super power
+
+
Take part in design
+
+
+
+
We have an incredible design team. If you haven’t worked somewhere that doesn’t value design you might not realise what a wonderful gift it is. Take every opportunity to work with the designers in the team. When there’s user research go along and take notes. Ask them about the designs. The nuance and depth that goes into seemingly simple things is fascinating and can help you understand why you should put in the extra effort (cos sometimes that detail is hard engineering)
+
+
There aren’t many investments guaranteed to pay back but this is one that will pay back.
+
+
Keep being amazing
+
+
3 or 4 years ago Membership systems broke frequently, cost Co-op money, and were an isolated island of functionality. Now we’re rock solid at 10x usual traffic, turn a profit, and support some of the most important things Co-op are working on.
+
+
I hope it’s not egotistical to say that I know I contributed to that and feel pride in what we’ve achieved. But I know that you all contributed to it far more than I did. I’m so excited to see where you go from here.
+
+
I don’t know what I’m talking about…
+
+
…or at least I often feel I’m making it up as I go along. I get the impression that’s true of lots of people, if not everyone. So if you disagree with any or all of this that’s fine. Decide what you think is important and work with people to make that happen.
+
+
+
+
Walking
+
+
This is the second full year I've had a dog since I was a teenager. Best decision in a long time. As much work as having a baby but it adds joy to life.
+
+
dog on new years day 2019
+
+
+
+
dog on new years day 2020
+
+
+
+
dog on new years day 2021
+
+
+
+
Note that in all three photos the dog is soaking wet.
+
+
Kids
+
+
+
+
All three kids have said they don't want to be on social media so I won't mention much here. I continue to be amazed that my bad influence isn't reducing the kids well-rounded, excitement at the world.
+
+
What writing this taught me I want to do in 2021
+
+
+
read about leadership and get over myself
+
make time to write code for days at a time
+
start weeknotes again
+
by March understand what business and team goals I'm contributing to
+
meet one-on-one with everyone on my team at least once
+
keep those meetings going with some of them
+
practice Italian every day
+
use the unfair super power of being a white, middle-class, middle-aged, straight man to lift others up
Here is something I had to write down at work. Something I've tried to say (with varying success) more than once. That I'm publishing here so I can refer back to it in future and in case it is useful for someone else
+
+
When I am thinking about this, I am thinking about three things
"Argh, the young apple tree is being choked by bindweed again."
+
+
+
+
look at the consequences of your decisions as the plants grow
+
+
+
+
"hmmm, the apple tree is healthier now that I moved it, but it means it's grown a low branch across the path."
+
+
+
+
deal with the consequences of decisions made before it was your garden
+
+
+
+
"I would never have put an apple tree that near to the path."
+
+
+
+
delay work based on your context
+
+
+
+
x: "The apple tree is growing too large but, I can't prune it until late winter."
+y: "It could make the tree ill. But, we could tie the branch back until we prune it."
+
+
+
With tech debt, too, there are four things, not one
+
+
People say tech debt and mean more than one thing.
+
+
+
Mess
+
Things we did that we no longer like
+
Things someone else did that I do not like
+
Classical technical debt
+
+
+
That means we can think we agree when we're talking about different things. I have seen multiple people and teams (including myself) struggle with this.
+
+
TL;DR
+
+
You don't need permission for making incremental improvements in the course of work. That's engineering. It should be included if and when you estimate. When estimating think of both the ideal day and the most horrible day. We tend to think of the ideal but rarely experience it. Meaning our estimates fall short
+
+
Any technical improvement that can be done in the course of your work, should be done.
+
+
We don't budget time for writing tests or searching StackOverflow. Many small changes will have a large cumulative impact. The waves shape the beach by moving the sand a tiny amount.
+
+
The team should work with the Principal Engineer to determine the direction of travel and then follow it. This is particularly true for category one below: mess
+
+
Any technical improvement that can't be done in the course of work should be described, proposed, and measured.
+
+
Anything else is often "something the team wants to do". See categories 2 and 3 below. They should be described and capture the impact of doing or of not doing that work. They can then be prioritised, and reported on. In other words, it is treated the same as a request from outside of the team.
+
+
The team should work with the Principal Engineer and the Product Manager. To determine how to measure the desired improvement. And how to propose it for prioritisation
+
+
And you should switch between those two modes
+
+
Sometimes you start what you think is a quick task. And discover it isn't. You should stop, write it down and treat it as a separate piece of work.
People solve problems by adding things far more than they do by removing them. That's what hoarders do. Nobody set out to create the room in the image. They kept adding things that they thought were useful. The hoarder is used to it. It becomes their normal. Anyone new to the hoarder's home can't imagine how they can live there.
+
+
At some point, the software industry started calling this technical debt. It isn't. It's mess. The only response to mess. Is to accept it is inevitable and to tidy up at a faster rate than we add mess.
+
+
In the physical world when the mess is particularly bad we have no choice but to stop everything, hire a skip, and throw everything away. Sometimes this is the right choice for software but we aren't constrained by mess in the same way that we are in the physical world.
+
+
How do we react?
+
+
In the software world we deal with this mess by refactoring. One of the XP rules is to refactor mercilessly. Modern IDEs have tooling to help make this safe. A great guide to this is to use code smells as a guide to what to do next.
+
+
This is a constant activity. You consider this for every task you complete. You are, however, allowed to be pragmatic. You may say: "I won't fix that now because I know folk are waiting for this bug fix so we can start making money again". But you watch for always choosing the pragmatic path. The road to hell is paved with good intentions.
+
+
Some people have had success putting "golden" tickets in the backlog and everyone has to play a golden ticket in ever iteration. One person may use theirs to learn, another to go back and refactor to remove the code smell that had bugged them in some recent work.
+
+
You may not know where to start. If you haven't been tidying enough you should start anywhere rather than worry about which is the best bit of tidying. You will learn what to do by trying to do it.
+
+
What to watch out for?
+
+
If you find yourself pulling new tickets into your iteration, time-box, or sprint that is a good signal that you are rushing through implementing without tidying.
+
+
It is tempting to try to put value on individual pieces of tidying. But the value is in the constant application of effort. Not in any one individual piece of tidying.
+
+
What we would have to put value on is if we want to treat tidying as a task separate to our work. "I want to stop doing other things for M days, in order to tidy up. I believe this is necessary because X, Y, and Z". Here you have to put value on it because you are asking other people to stop and wait while you tidy.
+
+
You may not know where to start. If you haven't been tidying enough you should start anywhere rather than worry about which is the best bit of tidying. You will learn what to do by trying to do it.
+
+
Related XP values
+
+
"courage" to make the changes you believe will improve the code, no matter how big they are. Modern tooling makes large changes safe. If you find you can't make large changes safely, that's a new signal of how to improve your testing.
+
+
And "respect". Firstly, respect that your team mates are right to try and tidy this*now.* And secondly, respect for others working in or with the team. Tidying might mean they're waiting longer than they expect. Tell them what is happening.
+
+
2 Things we did that we no longer like
+
+
I loved that coat. A genuine first world war camel hair trench coat. It kept me dry and warm through many an Oldham winter snowstorm. I thought it was great. As time passed I had to come to terms with the fact that when it was wet it smelled like a dead dog.
+
+
What I had thought was a great coat, was actually a smelly coat. It served me well until I realised it stank.
+
+
+
+
What is it?
+
+
We are always growing and learning. Decisions we make that we are proud of eventually become decisions we wish we hadn't made. Sometimes it is easy to change the decision. Other times it is hard.
+
+
It is tempting for this to be treated as concrete ("Monoliths are bad now") when it is often preference ("We would like to use Webpack that we don't understand instead of Gulp that we don't understand")
+
+
How do we react?
+
+
In one of two ways.
+
+
1) slowly applying a direction of travel
+
+
We choose a direction "we will more carefully apply the interface segregation principle". Maybe we run sessions to get or keep the team aligned on the direction. And then we fix the thing as it falls in front of us.
+
+
In this specific case:
+
+
+
every time we edit a file,
+
if the interface is too large,
+
we use our brains and our IDE tools to break it into smaller interfaces
+
+
+
As these are in the moment changes we don't even tell people we're doing it. It's a part of the work
+
+
2) clearing the slate
+
+
Sometimes the change is too large to be done in tiny pieces or would take so long to complete in small pieces you may as well never start.
+
+
In this case:
+
+
+
we figure out why it is a problem
+
+
e.g. every time we make a particular ten minute config change (X times per year) we lose 3 hours of time for at least two people.
+
+
+
and we say what happens if we fix it
+
+
e.g. If we spend 10 days fixing this we will save 15 days this year, and 20 days every year after that
+
+
+
+
+
Similarly to the need for respect for other people's time when dealing with mess. When clearing the slate we are asking other people to wait while the engineering team seemingly achieves nothing. We don't always have to be right that we should stop and spend time changing our minds but we do have to be careful
+
+
What to watch out for?
+
+
Watch out for fads! Yes, SvelteJS might be getting lots of social media traction but do we want to invest tens of thousands of pounds changing JS frameworks.
+
+
Watch out for swapping a known set of problems for almost the same problems in different clothes. You may hate Dropwizard and wish we were using Spring. Or think we shouldn't use Jenkins because GoCD is better. etc etc. There's much more to adopting a technology than the text files.
+
+
Replacing "Things we did that we no longer like" with "things we now like" can cause your products and systems to stand still while you do the work. Watch out for replacing things without knowing when to stop or how to measure it
+
+
Equally, watch out for never replacing decisions you've outgrown. There's a lot of room for manoeuvre between "never replace existing tech" and "OMG we should use Rust!"
Because of how the brain works, the people that made a thing in a particular way are often too slow to accept they should have made it a different way (see Things we did that we no longer like). And, people that are fresh to the thing are often too quick to suggest that it should have been made in a different way. Not being present when the context forced your hand, or when mistakes were made, mean you are less willing to accept the current state.
+
+
How do we react?
+
+
It is good to take advantage of fresh perspectives. At a minimum we use this to help set long-term direction. E.g. "I found it very confusing to onboard and there are four different ways of deploying the applications. I can't see a reason for having more than one. But the work to reduce the number of ways we have looks complicated"
+
+
And we should also be looking for low-hanging fruit. E.g. "I see we're using CloudFront but not setting cache-control headers. I've seen cache-control headers have positive impact in multiple systems. I reckon I could add them in less than two days"
+
+
What to watch out for?
+
+
We always under-estimate the effort required to replace something and over-estimate the effort required to understand it.
+
+
Also watch out for justifications based on something being best or current practice. All practice is context dependent. One person's best practice is another's terrible idea. Use tools like Wardley Mapping and Cynefin to help determine what practice to apply.
+
+
4. Classical Technical Debt
+
+
Technical debt is the purposeful decision to defer some necessary work in order to meet a deadline. The debt metaphor is well chosen for descriptive purposes. As the impact of the debt gets worse over time, particularly if we pay back the minimum charge or less. But, engineers always talk about debt as if it is bad. Businesses don't think of debt as bad. There is always debt in running a business and you are always choosing what debt to ignore.
+
+
Tech debt has been short hand for so long now that everyone means a different thing but thinks they agree. It may be better to talk about whether we are keeping scope and delaying implementation or reducing scope and managing consequences.
+
+
+
+
What is it?
+
+
Technical debt is a purposeful choice to make a version of something that is working from the perspective of the customer. But that is either made badly or missing necessary work that means it is hard to maintain or change.
+
+
It is only bad when the work to add technical debt is more common than work to remove it. Think of each piece of debt as a new credit card and not a single purchase on one card.
+
+
It isn't reducing scope with no intention to pay back the debt.
+
+
How do we react?
+
+
We track it. Ideally we keep a ticket in Jira or whatever equivalent is in use. That ticket is assigned to the business person that made the decision to incur the debt. As the cost of the debt becomes apparent the ticket is kept up-to-date so prioritisation can occur.
+
+
Technical debt is deferred work not avoided work. If you already can't pay off your monthly debt bills you should think very hard about taking on more debt. At some point you have to defer spending instead of accruing debt.
+
+
What to watch out for?
+
+
Treating technical debt as avoiding work instead of deferring work. It is common to say "if we do X this way that accrues technical debt". People hear "I want to gold plate this but you can invest less and still have it". Better to talk about whether to delay the implementation (and to when!). Or whether to cut scope with no inferred expectation the thing will still be done.
+
+
Repeating the tl;dr
+
+
Avoid saying technical debt. Instead, say what you mean.
+
+
Subsequently:
+
+
Any technical improvement that can be done in the course of your work, should be done.
+
+
We don't budget time for writing tests or searching StackOverflow. Many small changes will have a large cumulative impact without needing others working in or with the team to wait.
+
+
Any technical improvement that can't be done in the course of work should be described, proposed, and measured.
+
+
Anything else is often "something the team wants to do". See categories 2 and 3. They should be described and capture the impact of doing or of not doing that work. They can then be prioritised, and reported on. In other words it is treated the same as a request from outside of the team.
I've finished at the Co-op after four years. I was feeling emotional and wrote some "wise words". I thought I'd record them here. In the future, when I'm reminiscing, they can transport me back to this feeling.
+
+
+
+
+
keep being kind to yourselves and each other
+
keep being bold but stay humble
+
people and interactions over processes and tools (that's one of the best bits of the agiles)
+
keep releasing small things
+
+
then try and release smaller
+
+
+
slow down, start less, and you'll finish more
+
ask three questions
+
+
why should I start this work
+
how will I know when to stop
+
how will I know if it is still working tomorrow
+
+
+
make the loosely coupled version of the service or system
+
make the simpler version of the service or system
+
delete things
+
help everyone take part in service and support
+
help everyone take part in design and user research
+
keep being amazing
+
as long as you are being kind to yourself, you are allowed to hold yourself to a higher standard (but be kind first!)
Tony Benn once said: "I have divided politicians into two categories: the Signposts and the Weathercocks. The Signpost says: 'This is the way we should go.' And you don't have to follow them but if you come back in ten years time the Signpost is still there. The Weathercock hasn’t got an opinion until they've looked at the polls, talked to the focus groups, discussed it with the
+spin doctors."
+
+
I heard this quote recently and it has really struck me…
+
+
Having changed problem domain, work environment, stack, and programming language this last year I'm wondering what signpost I want to be.
+
+
+
+
+
+
In ASP .Net I was a sign post for feature folders. In flaccid scrum teams for less planning and more measuring. In BLOBs (boring line of business applications) for an event-driven core. But having changed environment so completely some days I feel like a weather-vane.
+
+
What are things you are a signpost for? Or what are the things about which you are a weather vane on purpose or by accident?
+
+
Click "ask a question" below to sign in and tell me what you're a signpost for
We've had photovoltaic (PV) solar panels generating electricity on our roof for exactly 5 years. I've explained the impact a few times privately or on the tooter website. I'm writing it down here so that I don't have to re-remember all the details each time. And since electricity prices are in the news at the moment and it might be useful to some folks.
+
+
We had 14 panels installed on 25th August 2017. It cost £4,793.25 which included 5% VAT. Our house is south facing at the rear. They've generated 17.06MWh of electricity in the last five years.
+
+
That's 17,060Kwh or a little over 17,000 "units".
+
+
And that represents around 4 tonnes of CO2 "saved".
+
+
+
+
What we have
+
+
We have 11 panels on the south facing roof.
+
+
+
+
And 3 on the east facing roof.
+
+
+
+
You can see the lifetime generation of each panel in those images. The south-facing panels have each generated around 1.3MWh and the east-facing panels around 1MWh.
+
+
There is an inverter in the attic and a generation meter alongside our gas and electricity meters in the hall. The inverter from SolarEdge emits some metrics over wi-fi and we have an app that lets us see them.
+
+
+
+
Solar Energy sales people behaved horribly. It was like the worst experience of buying a car. We were lucky that we found "Just Energy Solutions" who seemed trustworthy and had soft-touch sales. They drove up from Bristol and completed the installation in a day. I would happily recommend them but they aren't trading any more.
+
+
Generation
+
+
We did lose some data when I changed my wifi network and forgot about the metrics for a few weeks. So we've generated an unknown amount more than 17.06MWh. You can see the drop in Q3 2019 below. Which suggests we've actually generated closer to 17.5MWh.
+
+
+
+
We don't have a battery. So we do still draw from the grid. Because, while we generate almost as much as we use, we don't always generate electricity when we are using it. :)
+
+
A battery was at least £3000 at time of installation. And this was already an expensive luxury. We chose a slightly more expensive inverter. So that we could still add a battery in future.
+
+
Feed-in-tariff
+
+
We receive some payments from the UK feed-in-tariff. Roughly 5p for every KWh we generate and another 5p for every KWh we export. For small installations you aren't required to meter generation and export. So the tariff assumes that we export 50% of what we generate.
+
+
Since Nov 2018 (I don't have all the records available online and I'm too lazy to find the paper records) we've received £950.21. Naively that's an interest rate of around 4%.
+
+
Immediate use
+
+
Our generation meter shows 16,655KWh. So I think that represents 405KWh that have been consumed within the house before making it to the meter (or possibly that the panels metrics don't match production exactly ¯\(ツ)/¯ )
+
+
At 18.9 p/kWh that's another £76.54 we've not had to spend on electricity
Our usage is around 3100kWh annually. Not all of that difference will be due to the panels - we're super careful about energy use - but that's up-to £200 a year more that we're "saving".
+
+
Price rises
+
+
+
+
The UK is having a terrible time of absent government and unrestrained, self-interested capitalism after an extended period of government by money-vampire. So, electricity is expected to soon be 52p/KWh. That potential 1200KWh a year less is then £600 a year.
+
+
## Payback time
+
+
Payback time is the time it takes for income and savings to pay for the cost of installation. Before Solar PV installation we had other work done on the roof. The payback time of that investment in the roof was… … infinity. No part of our house generated income before we got the panels.
+
+
We were in the lucky position to care more about offsetting our environmental impact than the financial return on investment.
+
+
However, based on the last five years and assuming (despite what's happening right now) that electricity prices rise with inflation then the payback time is 15-20 years.
+
+
Over the coming years prices will rise, my kids will move out (🙏), and our electricity demand will fall. So I'd expect payback to be more like 10-15 years.
+
+
But I'm not relying on it!
+
+
Would I recommend you get panels?
+
+
Having £4k to invest is a privileged position. If you have that money, a south or east facing roof, and can expect not to move house for at least 5 to 10 years. Then I think this is a fantastic way to do something positive with your money.
+
+
However
+
+
Insulate, insulate, insulate. Then do more insulation. You should reduce the need to heat your home as much as practically possible before doing anything else. Both for income and eco- reasons.
+
+
Angry moralising
+
+
It is very hard to avoid angry moralising while writing about this. There is such a failure of vision about how we could build and use energy infrastructure. Leaving those most in need with the least support. All the while the shiny-faced suits-full-of-piss in government squeeze the system of every penny for their friends and family.
Forgive me, for I have sinned, it's been 2 years since my last year notes 👼
+
+
I wrote year notes for 2019, and 2020. I've been super un-inspired to write for the last few years. Which is a shame - because it's a a great way to learn.
+
+
So much happened last year that it feels way longer than a year. So, discipline over motiviation - here are my 2022 year notes. Or at least as much as I can write while the house is empty of other people.
+
+
+
+
Goals from 2021 year notes
+
+
and whether I achieved them or not
+
+
(slightly reogranised since I see themes with hindsight that I didn't at the time)
+
+
leadership
+
+
+
❓ read about leadership and get over myself
+
❓ by March understand what business and team goals I'm contributing to
+
😅 meet one-on-one with everyone on my team at least once
+
😅 keep those meetings going with some of them
+
+
+
In retrospect I was struggling with a role that was poltical and not technical. 2021 saw me move teams, see that the grass wasn't greener, realise that the garden was (for me) poisoned, and move jobs to a technical role.
And the move (back) to a technical role was harder than I anticipated. New stack, new org, new culture. But I wouldn't change the decision for all the money in the world (well, maybe all the money)
+
+
myself
+
+
+
❌ start weeknotes again
+
✅ practice Italian every day
+
❌ 15km running on average over 40 weeks of the year
+
+
43 runs totalling 168km = 3.9km per run
+
I ended up struggling with achilles pain in 2021 and hardly running at all in 2022
+
but physio is helping
+
+
+
✅ 4 leisurely cycle rides
+
+
not in 2021, but I did in 2022
+
+
+
+
+
I'm more who I want to be, but there's more to do
+
+
my world
+
+
+
+
+
👀 use the unfair super power of being a white, middle-class, middle-aged, straight man to lift others up
+
+
+
This is the least I could do. I should take it for granted and figure out the answer to "Great, you want to help others, so what?"
+
+
So, 2022
+
+
Travel
+
+
Working at PostHog comes with a number of benefits. Freedom to travel because the work is remote, and travel for the work, is one that I've been loving!
+
+
+
+
In 2022 I visited 6 countries
+
+
+
Barcelona, Spain
+
+
for the engineering offsite
+
+
+
Reykjavik, Iceland
+
+
for the all company offsite
+
+
+
Forte Di Marme, Italy
+
+
because I wanted to take the kids to Italy with their Nonno
+
+
+
Pescara, Italy
+
+
for ten days because my family are wonderful and I wanted to spend time in Italy
+
+
+
Rome, Italy
+
+
for the product analytics team offsite
+
+
+
Paris, France
+
+
because I wanted to take the kids to Paris
+
+
+
Lisbon, Portugal
+
+
because we have a budget to meet each other,
+
my colleague let us use their house for free,
+
so Ben/Paul super-fun-time could happen to make real user monitoring.
+
I've never worked anywhere where we are as free to choose our own goals
+
+
+
+
+
I spent nearly 20 days in Italy in 2022. More than I've spent there for 20 years. The older I get, the more I value my heritage (#SoCliche). My spoken Italian has progressed from "Nouns and pointing" to "Hangry three year old".
+
+
Travelling for work has been an incredible thing. Lisbon was superb. It was fun to have a goal, work hard all day, and then have food and chat in the evenings. Barcelona, Rome, and Reykjavik were amazing. I'm convinced that intermittently coming together is one of the things that makes remote work, erm, work. Not only that though. Having a budget to meet and socialise is a super power.
+
+
Pescara was like breathing out. It's only the second time in my life I've travelled overseas by myself. And it's the longest I've spent not needing to parent for a decade and a half. I'm incredibly lucky that my family put up with me being away.
+
+
Work
+
+
+
+
Interestingly, there's a step change in my GitHub contributions around the time I went to Pescara too. And, without wanting to seem big-headed, I think, a step change in my performance at work too.
+
+
Changing back from a leadership role to a typey-typey-software role, at the end of 2021, was way more of a change than I anticipated. Alongside going all-remote and discovering which habits that helped in an office job that don't help anymore. It's amazing how much engineering you can forget in four years of talking to people about engineering.
+
+
What do I think has helped 🤔
+
+
+
cadence
+
+
I like to have a large(r) spike PR where I can experiment and gather feedback
+
and then splitting smaller pieces of work from that
+
the smaller pieces are easier to engineer well
+
and way more safe to release
+
aiming for merging more than one PR a day
+
+
+
stopping and thinking
+
+
decide a goal, figure out how to get there, figure out how much of your time to give it
although I struggled with the "yee-haw shoot people" presentation of extreme ownsership
+
+
+
"This isn't going to happen until I make it happen! -> How do I make it happen? -> How do I remove things stopping it happening?"
+
+
+
improvements accrue if you let them
+
+
this is maybe a corollary of "stopping and thinking"
+
I had a great pairing session where a colleague made (to them) a throw away comment about how React works
+
it changed the model of how I think about it.
+
Spotting that, I asked myself how that should change how I approach work
+
the last three months I've been working with another colleague on application performance (the back-end of the back-end)
+
they're incredible, if I can learn 1% of their skill I'll consider it a success
+
but now I want to find other work I can prioritise to practice what I think I've learned so I can trick my brain into storing the knowledge
+
+
+
talking to users
+
+
I've spent time supporting users
+
joining video calls to help them
+
running user interviews
+
understanding the users and seeing the struggles they have is 💯
+
I've been working a lot on our dashboards, not because I thought it was important but because they did.
+
+
+
+
+
Annoyingly, I not sure I know what made the difference. I really want to figure it out so I can take advantage of it well. I'm surrounded by amazing people and finding that wonderfully motivating.
+
+
### Open Source
+
+
A brief aside about working on open source software. An unexpected (for me) side-effect has been how incredible it is to be able to share exactly what I mean when talking to people about software. "I think it is good to do X" becomes "Here's a PR (or set of them) that I think demonstrate a way to do X well".
+
+
I think that's awesome.
+
+
Also, sometimes in remote work I miss the power of someone looking over your shoulder while you work. It's way harder to cut corners when someone is watching. Remembering that anyone can watch my work helps remind me to take the step from "make it work" to then "make it right"
+
+
+
+
For example, I fixed a bunch of bugs in our dashboards product (I think more than I introduced 😅). In doing that we learned about what made it easier to introduce those bugs than to avoid them. I could have moved back on to my main priority… but the world is watching, so I figured out a way to make it harder to introduce the bugs than to avoid them ("four rules of simple design" for the win) https://github.com/PostHog/posthog/pull/13630
+
+
Kids
+
+
+
+
Since last year notes I've graduated from three kids to four kids. It's still incredible. I'm still always very tired. So amazingly worth it. They have said they don't want to be on social media so I won't mention much here.
+
+
And now they're home… so I'm going to publish without editing and procrastinating.
Cancelled a trip to Genoa because our next offsite is in Aruba the same month (hard life).
+
+
But added a trip to Rome with the kids.
+
+
So, still need to figure out what my second trip will be
+
+
8 leisurely cycle rides
+
+
0 cycle rides in Jan.
+
+
The weather in the peak district and leisurely have not overlapped this month 🤣
+
+
train at the gym at least twice a week
+
+
Managed 3 times a week. I ache everywhere all the time 🥵
+
+
But I went for a short jog with the dog yesterday. It felt light and effort-free. First time both achilles have been pain free in a long time. So, I'm hopeful that I'll be able to get back to running soon. Although I need to not do my common failure mode and ramp up to 3 hour runs with the dog too soon and injure myself again 🤣
+
+
Practice Italian every day
+
+
✅ only a few minutes at a time, but I did it every day.
+
+
+
Still trying to get my Dad to talk to me in Italian habitually. 🇮🇹
+
+
Continue becoming a better engineer and team-mate
+
+
I didn't think about how I'd measure this 🙈
+
+
I've done a lot of solo-work this month. So arguably not being a great team mate. But it has been soaking up bugs and customer issues so the others on the team can focus.
+
+
Have also managed to stick to small PRs. Despite working on a bunch of tricky frustrating things that lend themselves to sprawling PRs that never get merged… So, I'm pleased with that discipline.
I'm still figuring out when Italy #2 will be. I'd love to take daughter #1 to Sicily and then catch the train back up through the country. I can work, she can study, and we can both enjoy the food and culture. Maybe a pipe-dream…
+
+
8 leisurely cycle rides
+
+
0 cycle rides in Feb.
+
+
Lots of parenting and responsibilities this month, so very little time for myself. And the bags under my eyes are proof of that 🙈
+
+
train at the gym at least twice a week
+
+
We were away in Cornwall for half term and so I managed 3 times a week while I was at home. And 2 times a week the 2 weeks that the trip overlapped with. But the dog and I went for a long run while in Cornwall and I accidentally went for a very long walk there. Turns out South West and South East are not the same direction 🤣
+
+
Here I am just after turning around, trying to figure out how to get back on track. At this point in time I thought I was all the way on the right-hand edge of that map segment 😅
+
+
+
+
I don't ache everywhere all the time anymore. And, actually, feel pretty good. Plus time at the gym is uninterrupted pod-cast time. So, I'm happy with that.
+
+
Practice Italian every day
+
+
✅ only a few minutes at a time, but I did it every day.
+
+
+
Still trying to get my Dad to talk to me in Italian habitually. 🇮🇹
+
+
Continue becoming a better engineer and team-mate
+
+
I've been concentrating on this more this month. We joke a lot about being a group of lone wolves and in sprint planning I was described as "wolfing with everyone". I guess that's a good thing 😅
+
+
My GCSE physics teacher told us to always start solving a problem with a diagram. This month's work was tricky, slow, and frustrating. But when I took the time to draw a diagram or two, and then go for an accidentally long walk, my brain was prepared, and my subconscious figured out how to make the complicated thing much, much less complicated.
Excitement building this month because "Italy Trip Number One" is in April…
+
+
8 leisurely cycle rides
+
+
0 cycle rides in Mar.
+
+
train at the gym at least twice a week
+
+
✅ Three times a week even while in the Caribbean with work. Still enjoying it.
+
+
Practice Italian every day
+
+
✅ only a few minutes at a time, but I did it every day.
+
+
Continue becoming a better engineer and team-mate
+
+
This was my last month on team product analytics. I'm moving to team session replay. Ben and I built network performance monitoring in December and had a great work vibe - exciting to be building more monitoring tools.
+
+
It makes sense to move teams now because there's a natural gap… 1 week in Aruba with work, and then 2 weeks in Italy. So, I can start fresh when I get back.
+
+
Yep, that's right - Aruba
+
+
We had our annual offsite in Aruba this month. It was a ridiculously beautiful place.
+
+
+
+
The highlight is always the hackathon. This year I worked on a team building issue tracking into PostHog.
+
+
+
+
Hackathon always reminds me of how powerful it is to start work together and excited.
+
+
My new favourite planning method is "post-it notes on a table with food and drink".
Between the end of 2019 and when I left the Co-op on Sep 18th 2021 I used Office 365 and never found a single redeeming feature.
+
+
Well, maybe one, a small set of Co-op employees had access to slack and g-suite in Co-op Digital. But in the rest of Co-op they were using installed (i.e. local only) old versions of Office (without video-conferencing and chat). For them, maybe Office 365 was an improvement - and certainly it made remote work during the pandemic possible.
+
+
But for me, it was a constant source of frustration.
+
+
I'm sure that there are great people working on Office with care and attention but I didn't experience that. It was like being haunted and losing your mind all in one go. I had a habit of tooting my frustrations. I'm aware of them having been submitted as evidence in one procurement process. I don't think they swung the decision.
+
+
If the tooter-web dissappeared they'd be the one thing I missed and so I've copied them here.
+
+
+
+
I didn't start the thread until after I had already made several of the toots. So the initial few dates might appear out of order. I've kept the order that I added them to the thread instead of listing them in date order.
+
+
+
10:20AM Oct 20, 2019
+ My life with office 365 is not richer
+
+
+
+
+
+
+
+
3:52 PM Oct 8, 2019
+ Me (a person at work): I'd like to import* a calendar
+Office 365: "YOU MUST WANT SPORTS!"
+
+This should not be the default behaviour of anything
+
+* I want to view a calendar
+
+
+
+
+
+
+
+
+
+
7:46PM Sep 26, 2019
+ Interesting to learn that all one time password apps should behave the same because it's described in an RFC...
+
+And yet Office 365 can only use Microsoft authenticator
+
+#NewMicrosoft
+
+#VeryStaringFace
+
+
+
+
+
+
+
+
12:01PM Oct 18, 2019
+ Hey @office365 can you opensource? It would be quicker for me to contribute code to fix Word than to figure out how to amend a numbered list in this garbage fire
+
+
+
+
+
+
+
+
+
+
8:33PM Oct 9, 2019
+ In word you click "Give feedback to Microsoft".
+
+ 3 apps, 3 different feedback mechanisms.
+
+that gives me a sad
+
+
+
+
+
+
+
+
7:41PM Oct 9, 2019
+ Where's the approprate place to report that the visual affordance for giving feedback is different in Outlook, Word, and Powerpoint (in the browser)?
+
+
+
+
+
+
+
+
4:48PM Oct 8, 2019
+ Hey @office365 what is going on with pasting into lists in Word in Chrome?!
+
+(gif: MS Word in the browser being very odd about lists)
+
+
+
+
+
+
+
+
+
+
4:29PM Oct 4, 2019
+ Me: "a new Word document just look many times already in the last couple of days"
+O365: "Please just this time but not the others could you mindlessly click this box accepting a certificate"
+Me: *just wanting to write some text *clicks OutlookO365: "H! Psyche! Nothing happened . Lol"
+
+
+
+
+
+
+
+
6:03PM Oct 9, 2019
+ I just selected a time for an invite in outlook calendar in a browser on my phone.
+
+Great example of why you should use native inputs instead of building your own
+
+(Spoler that was not a native input and it was too hard)
+
+
+
+
+
+
+
+
10:20AM Oct 20, 2019
+ And today, I found a uservoice entry for snoozing email (blimey do I miss @inboxbygmail)
+
+I can sign in using google or facebook but not office 365
+
+I have twice given consent for storage of PII but my vote hasn't registered
+
+
+
+
+
+
+
+
+
+
10:24AM Oct 20, 2019
+ I've just realised that I can "like" an email in Outlook
+
+What am I supposed to imagine happens when I do that?!
+
+Does the other person get an email saying that I've liked a different email? What is it for?
+
+
+
+
+
+
+
+
10:39AM Oct 20, 2019
+ Outlook: "try the new focussed inbox. we'll stop moving messages to the 'Clutter' folder"
+Me: "What's the clutter folder?" Where is that?! Ugh I guess I'll learn more"
+Outlook: "lol video is unavailable. psyche!"
+
+
+
+
+
+
+
+
+
+
+
+
10:41AM Oct 20, 2019
+ Nope, no clutter folder :/
+
+
+
+
+
+
+
+
+
+
1:39PM Oct 21, 2019
+ Listening to someone use Outlook for the first time
+
+"this isn't nice"
+"that's unexpected"
+
+#UX
+
+
+
+
+
+
+
+
8:00PM Oct 21, 2019
+ Insert a picture with the cursor in a cell in excel. Adds image at full size.
+
+Insert a picture in a powerpoint slide. Adds image as small as it feels it can get away with.
+
+As a user
+I want adding images to be as frustrating as possible
+So that I close my laptop and go outside
+
+
+
+
+
+
+
+
11:10AM Oct 24, 2019
+ Me: *I wonder if I can book a meeting with someone
+Calendar: I WILL SHOW YOU MYSELF HORZONTL SO ALL TEXT IS HIDDEN. I HALP YOU MAKE A DECIDE
+
+
+
+
+
+
+
+
+
+
8:35PM Oct 29, 2019
+ Calendar: "Don't worry some of what you need to click on is off th ebottom of the screen but despite it being lierally the default behaviour of a web page you can't scroll to it"
+Calendar: *holds up hand for high five
+
+
+
+
+
+
+
+
+
+
1:00PM Nov 6, 2019
+ Presented without comment #calendar #search
+
+
+
+
+
+
+
+
+
+
9:58AM Nov 25, 2019
+ The two states of opening an email in Outlook on poor signal
+
+(NB I have gmail open in another window in the same browser. Guess whether it can open my mail)
+
+
+
+
+
+
+
+
+
+
+
+
11:42AM Dec 3, 2019
+ Me: find this document
+OneDrive: here are some results... including the folder they are in...
+Me: oh, useful can I open that folder from here
+OneDrive: No!
+
+
+
+
+
+
+
+
+
+
11:44AM Dec 3, 2019
+ And just randomly someone else's name is the title of the left hand column of the OneDrive page.
+
+Really is the least discoverable UI I've worked with for quite some time.
+
+
+
+
+
+
+
+
+
+
12:56PM Dec 3, 2019
+ When the browser tab has this red thing it's Outlook making it look like you've new mail when actually you haven't
+
+
+
+
+
+
+
+
+
+
9:28AM Dec 12, 2019
+ Me: navigates to a week in the calendar
+Me: "yep, that's the one" *clicks new event
+Office 364.5: Ah, you must want to default to today not the week you're looking actually
+
+
+
+
+
+
+
+
+
+
6:58PM Dec 19, 2019
+ My office 420 session just expired *while* I was typing into a Word document.
+
+It told me to refresh the page.
+
+I did.
+
+3 paragraphs of text gone.
+
+I have literally never lost a character of text in over a decade of using Google.
+
+
+
+
+
+
+
+
12:23PM Jan 28, 2020
+ Today in my-life-editing-word-documents-in-chrome the cursor moves around while I'm typing and so every sentence is a battle
+
+
+
+
+
+
+
+
+
+
10:17AM Feb 11, 2020
+ Me: fuck it, ok, I'll open Outlook as a native app
+Outlook: you have to quit word first, Lol"
+
+
+
+
+
+
+
+
+
+
10:21AM Feb 11, 2020
+ Outlook (native app): log in twice now please.
+Outlook (native app): click allow or deny on this meaningless tech message.
+Outlook (native app): and now here are two appointments in the past that nobody has asked about
+
+#FuckingHell
+
+
+
+
+
+
+
+
10:55AM Feb 11, 2020
+ Outlook (native app): here're 1664 reminders for the past, human I am halp
+
+
+
+
+
+
+
+
9:05AM Feb 12, 2020
+ Even though the cursor is in it I can't type in the box to thell them what I don't like...
+
+I don't feel like my feedback is valued.
+
+
+
+
+
+
+
+
+
+
6:36pM Mar 2, 2020
+ Me: "please save this spreadsheet with this password to open it"
+Me: *pastes password into box
+Excel: "please confirm the password into this new box"
+Me: *pastes password into box
+Excel: "they are not the same"
+Me: "I feel like you have secret password format restrictions"
+
+
+
+
+
+
+
+
+
+
2:27PM Mar 24, 2020
+ Searching in GMail: "did you mean this email that doesn't actually have the words you typed into search but we had a feeling you might actually want?"
+
+Searching in Outlook:
+
+
+
+
+
+
+
+
+
+
9:21AM Jun 7, 2020
+ The mail icon on the left has no little notification. That means I don't have mail. If it had a little notification it would mean I had mail
+
+The mail icon on the right has a little notification. That rarely means I have mail. How is even that little detail so badly implemented?!
+
+
+
+
+
+
+
+
+
+
9:30AM Jun 7, 2020
+ I checked. There was no mail. Now, there's a notification on twitter. I checked. There was something new.
+
+Twitter can get it right and they've made showing a list of snippets of text complicated.
+
+
+
+
+
+
+
+
+
+
7:50PM Jun 15, 2020
+ Me: *signs in to Word desktop app
+Word: you have to sign in
+Me: *clicks sign in
+Word: *with no feedback "you have to sign in"
+Me: *clicks sign in
+Word: *with no feedback "you have to sign in"
+...
+Me: *clicks sign in
+Word: "seventh times the charm" *saves changes
+
+
+
+
+
+
+
+
7:54PM Jun 15, 2020
+ Me: *highlights line of text
+Me: *paste
+Word: "Don't worry, I've stuck this pasted text as the start of the next nearest heading in the document."
+
+
+
+
+
+
+
+
+
+
12:18PM Jun 16, 2020
+ Me: *clicks a calendar appointment in O365 web calendar
+O342: "here's your little white diamond"
+Me: "no, that's not what should happen" *clicks again
+O213: "yep, little white diamond, as requested"
+Me: *waits a minute and clicks again
+O420: "your diamond, good sir"
+
+
+
+
+
+
+
+
+
+
10:18AM Jun 19, 2020
+ wait, so teams works in the app or in chrome?
+
+sorry, I was late for the meeting. I foolishly thought having two browsers on my computer would be enough
+
+
+
+
+
+
+
+
12:02PM Jun 26, 2020
+ me: scroll down please
+word in the browser: I DoNT sCroLl An1m0r
+me: it's just a browser window
+word: I DoNT sCroLl An1m0r
+me: refreshes window
+word: NO SCROLL ONLY RENDER
+
+
+
+
+
+
+
+
+
+
12:08PM Jun 26, 2020
+ Ha, forking hall MS, One instance of firefox, all tabs scroll except for MS Word tabs. even newly opened ones.
+
+This has happened to multiple open tabs (and now any new tabs) at the same time.
+
+Office 365 must be a burning nightmare of a code base.
+
+
+
+
+
+
+
+
12:10PM Jun 26, 2020
+ Oh, my bad, it was Chrome not firefox. Teams can't do video in Firefox so I have to run two different browsers.
+
+
+
+
+
+
+
+
+
+
1:04PM Jun 26, 2020
+ I have the outlook calendar integration in Slack now. It's great except...
+
+slack: you have a meeting!
+me: * clicks link
+link: * opens in my default browser
+teams: I can't a video in this browser
+me: * copies link from browser URL bar
+me: * pastes into Chrome
+
+1/2
+
+
+
+
+
+
+
+
1:04PM Jun 26, 2020
+ teams: You want to open in app or browser?
+me: IN THE BROWSER
+teams: would you like to join this call
+me: * clicks join now
+
+in another timeline
+
+me: * clicks link
+zoom: * want to join call?
+me: * clicks join now
+
+2/2
+
+
+
+
+
+
+
+
11:52AM Jul 15, 2020
+ Me: highlights text at the beginning of a bullet point and presses delete
+Outlook: I R DELETE THE BULLET POINT AND NOT THE WORDIES AS PER YOUR RECENT REQUEST
+
+
+
+
+
+
+
+
11:37AM Jul 16, 2020
+ ORGANISE WHAT MESSAGES, OUTLOOK?! YOU ARE LITERALLY TELLING ME THERE ARE NO MESSAGES AND THAT I SHOULD ORGANISE THEM
+
+
+
+
+
+
+
+
+
+
8:16PM Jul 16, 2020
+ How I make a line chart in excel (web version) where the first column should be the Y axis values.
+
+1) copy data to google sheets
+
+
+
+
+
+
+
+
8:57AM Jul 29, 2020
+ me: open the next email, please
+outlook: here you go
+me: close email
+me: oh, actually, open email again
+outlook: I can't display that email
+me: but... but...
+
+
+
+
+
+
+
+
10:31AM Aug 6, 2020
+ powerpoint: "Here's how text selection works"
+me: "Yes, that is what I expected"
+narrator: "It was not what he expected"
+
+(look at the difference in the same key commands when the cursor is on "predictable" vs. when it is on "Not")
+
+
+
+
+
+
+
+
+
+
10:36AM Aug 6, 2020
+ After I stopped recording the screen I deleted the text by holding down backspace. Sometimes the cursor moved left without actually removing the character to its left.
+
+This is fine becuase text editing is new
+
+NB it is not new and not fine
+
+
+
+
+
+
+
+
+
+
8:48AM Aug 21, 2020
+ me: *typing in box
+teams: wHy NoT rEfErsH teH paJ
+
+
+
+
+
+
+
+
+
+
8:50AM Aug 21, 2020
+ Let's not worry about the fact that while Teams wants me to refresh the page cos I'm not connected to the internet. I can toot from the same computer.
+
+TIL: https://Twitter.com runs on my laptop
+
+Turns out it's called teams cos it's teeming with bugs
+
+
+
+
+
+
+
+
+
+
2:53PM Sep 2, 2020
+ Me: ...
+Me: ...
+TeAmS: I HAVE ANTICIPATED YOUR NEEDS AND MUTED THE LIVE STREAM AGAIN FOR YOU HUMAN. NO NEED TO THANK ME
+
+
+
+
+
+
+
+
5:16PM Sep 2, 2020
+ This isn't just an Office 365 complaint. But look at all that unused space... What are all of those buttons?!
+
+Can we just all agree that icons need to have text alongside them?
+
+
+
+
+
+
+
+
+
+
10:37AM Sep 9, 2020
+ I don't have the energy for snark today
+
+fucking teams!
+
+
+
+
+
+
+
+
11:18AM Sep 15, 2020
+ I've edited text in probably 10 applications already today. In all bar one of them the only thing that has caused mistakes is my fat fingers
+
+I'm on my fourth attempt trying to edit a line of text in powerpoint and whole blocks of the text keep disappearing
+
+
+
+
+
+
+
+
+
+
9:00PM Sep 15, 2020
+ Award for the most value-less interruption ever goes to...
+
+*opens golden envelope
+
+message to say that you clicked on a link for content you have access to and would you like to go to that content?
+
+
+
+
+
+
+
+
+
+
3:54PM Nov 9, 2020
+ Kid in the same room playing an online game, I'm watching a video, and using Slack. My house couldn't currently have more internet.
+
+Me: * clicks a link in Teams
+Teams: "I don't feel too well"
+
+
+
+
+
+
+
+
+
+
7:42AM Nov 9, 2020
+ me: "I'd like to edit this bulleted list"
+outlook: "gotcha"
+me: "new line please"
+O: "starts with a bullet"
+me: *tab
+O: *move the bullet in
+me: *repeats 3 times
+me: "new line please"
+O: "starts with a bullet"
+me: *tab
+O: "move the cursor leave the bullet, gotcha"
+
+
+
+
+
+
+
+
+
+
11:16AM Nov 24, 2020
+ Teams: works on chrome desktop but it turns out not on chrome mobile. Works in Firefox including video for live events but not video for meetings
+
+#NewMicrosoft my arse
+
+
+
+
+
+
+
+
+
+
11:12AM Dec 4, 2020
+ So, you can close the Teams app window on Mac by pressing CMD + W when you think another window has focus and not be able to get it back without restarting
+
+What I like in a tool is when there are multiple sharp edges to cut myself with when I use it
+
+
+
+
+
+
+
+
+
+
11:13AM Dec 4, 2020
+ And, yes, it's possible in other applications.... but they also don't dump you in a dead end.
+
+
+
+
+
+
+
+
+
+
10:42AM Dec 11, 2020
+ 1. open email
+2. save to onedrive
+3. view in onedrive
+4. download
+
+Thanks O3.65 I'm glad there's not a download attachment button
+
+
+
+
+
+
+
+
10:42AM Dec 11, 2020
+ I googled yammer, got to a website, clicked start using yammer, I am logged in to O3.65 and have access to Yammer
+
+
+
+
+
+
+
+
+
+
11:05AM Dec 14, 2020
+ Oh, forking hell. Joining a teams call UI is like the space shuttle
+
+join teams call without audio
+
+means literally without audio, it doesn't mean "join muted" which is a useful setting but instead "join without being able to hear" which doesn't seem useful to me
+
+
+
+
+
+
+
+
14:23PM Jan 15, 2021
+ me: *cmd + tab
+teams: "your invisible notification window, as requested"
+me: "that's not right"
+me: *clicks "calendar" in the window menu
+teams: "your calendar, you should have said first time, here you go"
+
+(nb if I move my mouse around I get the calendar items' hover text)
+
+
+
+
+
+
+
+
+
+
6:08PM Jan 29, 2021
+ Me: presses space
+Almost every program playing video: *toggles play/pause
+MS stream not full screen: *toggles play/pause
+MS stream in full screen: I AM EXITING FULL SCREEN AS ANYONE WOULD EXPECT
+
+
+
+
+
+
+
+
+
+
2:57PM Feb 8, 2021
+ Me: *I wonder if @HollyDonohue01 is on this call?
+Teams: *offscreen "Calling her in to this meeting for you"
+Teams: "Hey Holly, Paul is inviting you to join these 85 people on a call"
+Me: "Argh, that's not what I meant! How do I cancel this?"
+Teams: "What is a cancel?"
+
+
+
+
+
+
+
+
+
+
5:37PM Feb 22, 2021
+ Me: *signed into teams and using it
+Me: *clicks a button
+Teams: YOU HAVE TO SIGN IN INSIDE THE WINDOW EVEN THOUGH YOU HAVE TO SIGN IN TO SEE THE WINDOW. I AM A SECURE
+
+
+
+
+
+
+
+
+
+
12:42PM Mar 23, 2021
+ For three weeks I've been off work and I didn't notice the feeling cos it was an absence of a thing
+
+The absence of being amazed at how bad something is... I've not noticeably waited for a computer to do something
+
+And now? "Crashing" back into using O3.65
+
+
+
+
+
+
+
+
+
+
12:43PM Mar 23, 2021
+ Me: please open this spreadsheet
+Teams: allow me to present an onboarding journey you don't need and can't interact with that freezes your browser
+
+
+
+
+
+
+
+
+
+
12:53PM Mar 23, 2021
+ Oh nice, no option to mark all as read in Teams. Thank fork there are only 26
+
+As a business owner
+I want to pay my staff to have to click on every conversation
+So that I know they are engaging
+
+pro tip if you click through them quickly they don't actually get marked as read
+
+
+
+
+
+
+
+
+
+
8:40AM Apr 6, 2021
+ I have six applications that are using the internet successfully. But not Outlook 🤬
+
+I'm lucky my calendar and mail aren't trapped in that burning building of a system, eh?
+
+
+
+
+
+
+
+
+
+
10:59AM Apr 6, 2021
+ Thanks powerpoint
+
+
+
+
+
+
+
+
+
+
2:43PM Apr 6, 2021
+ Office 3.64 spell check now takes my northern accent into account
+
+
+
+
+
+
+
+
+
+
10:57AM Apr 12, 2021
+ Every Monday Outlook does a "cute" thing where it recreates a meeting series for me so that I can say I don't go to it anymore.
+
+It takes maybe 30 seconds. If it's doing that for 1% of employees that's 5 hours a week.
+
+That'd be 8 weeks FTE over the year. #HiddenCosts
+
+
+
+
+
+
+
+
+
+
10:00AM Apr 14, 2021
+ For weeks now Teams has been "opening" a "notification" window on my Mac. It isn't viewable and only has the effect that I can no longer CMD+Tab to Teams cos that invisible window gets "shown"
+
+The "fix" is to restart Teams when I notice it
+
+(lifehack: just close it instead)
+
+
+
+
+
+
+
+
+
+
12:22PM Apr 26, 2021
+ Sharepoint: THIS IS NOT SAVED
+Also Sharepoint: YOU SHOULD REFRESH TEH PAGE
+Me: *please save the page
+Sharepoint: HAVE A FREE STACK TRACE. I AM A WEB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
12:23PM Apr 26, 2021
+ And, yes, reader, when I refreshed the page all my edits had gone. Sharepoint has one purpose and cannot do it
+
+It's like Wordpress having a bad trip
+
+
+
+
+
+
+
+
4:47PM Mar 10, 2021
+ I "like" the new "why not in a fortnight" scheduling feature
+
+here's me suggesting a meeting that the invitee is free for and Office helpfully pointing out we're both also free two weeks later than that
+
+
+
+
+
+
+
+
+
+
3:35PM May 13, 2021
+ Teams: DONUT WORRY HUMAN, FOR THIS MEETING YOU ARNE"T ALLOWED TO ATTACH FILES IN TEH CHAT
+
+
+
+
+
+
+
+
+
+
9:07AM May 14, 2021
+ Outlook: DO NOT WORRY HUMAN, IF I NEVER FINISH LOADING THESE SCRIPTS YOU CANNOT SEE YOUR MAIL AND GET SOME FOCUS TIME
+
+
+
+
+
+
+
+
+
+
1:56PM May 24, 2021
+ outlook *showing me an invite: "no conflicts 👍"
+me *looking at the calendar: "do you know what a conflict is?"
+outlook *starting to sweat: "yes?"
+
+
+
+
+
+
+
+
+
+
+
+
9:44AM Jul 7, 2021
+ PP: morning
+me: "open a deck, please"
+PP: here you go
+me: "open this one from the browser"
+PP: I AM FROZEN
+me: *ugh, force quit
+O3.7: DON'T WORRY WE HAVE A CUSTOM WAY OF HANDLING ERRORS
+me: is it good
+O3.7: I don't know, I've never seen it work
+
+
+
+
+
+
+
+
+
+
+
+
9:45AM Jul 7, 2021
+ me: maybe if I sign out
+"Power"point: "worth a shot, guv"
+me: *sign out, please
+PP: done it
+me: *and sign back in, please
+PP: NOT A THING I CAN DO, PYSKE!
+
+
+
+
+
+
+
+
+
+
11:58AM Jul 12, 2021
+ me: *has a 30-minute meeting with one other person
+Teams: HERE IS AN ATTENDANCE REPORT. THIS IS A HELP IF YOU DON'T KNOW IF YOU ATTENDED OR IF YOU NEED TO CHECK IF YOU JUST SPENT THRITY MINUTES ALONE OR NOT"
+
+
+
+
+
+
+
+
+
+
4:57PM Sep 7, 2021
+ CISO: "Hello, I'd like to implement security"
+O365: "It's already done. The steps for downloading an attachment are: 1) click save to one drive 2) click view in one drive 3) download. Security!
+
+WHY CAN I NOT DOWNLOAD AN ATTACHMENT FROM AN EMAIL
+
+
+
+
+
+
+
+
+
+
1:42PM Sep 17, 2021
+ One final disappointment from O3.6
+
+Because I insist on the unexpected browser choice of Chrome on an Android. I can't join a meeting when I find myself caught away from home.
+
+Obvs Teams isn't supported on desktop Chrome
+
+
+
+
+
+
+
+
+
+
9:06AM Sep 18, 2021
+ And in a perfect bit of poetry, I can end this thread, let down by technology, and frozen in Teams.
+
The average human brain has 2.5 petabytes of memory (source: random google result). 2.5 Petabytes is equal to 2,500,000 Gigabytes. Or 2,500 terabytes. The u-12tb1.112xlarge instance on AWS has 13TB of memory.
+
+
So, conclusively, 193 u-12tb1.112xlarge instances are equivalent to one brain. Or your brain could run in AWS for 15,305,472.00 USD per month. Therefore, I've saved 183 million dollars by not moving my brain to the cloud in the last year alone.
+
+
There seem to be a fashion for writing articlesclaiming that some company has saved hundreds of millions of dollars by not moving to the cloud.
+
+
I managed phyisical servers for more than a decade. For the UK Magistrates Courts and for the British Mountaineering Council. I was pretty good at it. But, I absolutely jumped at the chance to move to the cloud. Why?
+
+
+
+
I really don't miss running my own kit (colocated or directly owned).
+
+
I don't miss cycling around Manchester on a Bank Holiday weekend because I'd miscalculated how much network cabling I'd need for an upgrade.
+
+
I don't miss keeping a spreadsheet of storage so I knew when to order disks, negotiating with suppliers for cost of new disks, because I was buying a slightly smaller bulk than AWS.
+
+
I don't miss having to explain to folk in datacenter support that they could take the disks out of my failed server and put them in a new server if they had one available.
+
+
I don't miss the day the single point of failure in the rack failed and everything was offline while I waited for a new doohickey to be shipped to me because it didn't make sense to keep spares of everything on hand.
+
+
I don't miss trying to figure out if some new generation of server hardware would work for or would fit in my rack as manufacturers stopped making the kit we did use.
+
+
I don't miss hacking at a multi-thousand pound HP Proliant server with a breadknife because it was the only way to make the thing fit together due to a manufacturing error. And I couldn't wait for a replacement.
+
+
However,
+
+
The problem with all those articles isn't that they say you should or shouldn't run in the cloud. But that they make bold claims about what everyone should do.
+
+
I'm not going to say every workload should run in the cloud (cliche nod to StackOverflow) but it certainly isn't free to get all of the benefits.
All new build tools are better than what came before. Until they are able to solve all of the problems of the thing they replaced and then they're at least as bad. A new tool will then replace them
+
+
+
+
Anyone who remembers the mad rush to replace every build tool in your JavaScript projects with Grunt, to have to replace that with Gulp only days later, will know what I mean.
This post is part of a series where I'm hoping to prove to myself that building a dynamic website with NodeJS is much more fun than using a CMS platform. See the first post for an explanation of why
A traditional CMS framework or website has an admin section for logged in users. That section has a menu showing them which sections the user can edit and each section has a list of the pages they can edit and then the user can edit the text or upload images using a WYSIWYG editor.
+
+
Don't fix it if it aint broken but… but… HTML5 includes the contenteditable attribute which makes (the text of) almost any element editable.
+
+
If the admin section exists (in large part) to allow editing of content and editing of content can be completed in the page itself could this replace the admin section?
+
+
+
+
Could it?!
+
+
The benefit I can see here is that your edits are in place. They're immediately reflected on screen so the editing user can see the impact they're having. A user may not grok why a developer has put a 25 character limit on a title field. But if they only change a title and it pushes the rest of the page out then it's their call whether that's OK.
+
+
I can think of two problems with this:
+
+
1. Users expect an admin interface.
+
+
They don't expect to edit in the page
+I've previously referenced "Don't Make Me Think" (shameless affiliate link) and that approach would drive the position that there's no point confusing a user only to be funky. This may be doing that…
+
+
2. Is it discoverable?
+
+
The visual affordance to indicate that a user is able to edit an element needs to be worked in to the design.
+
+
If the user can't find what to edit then this doesn't work. Also, since part of the benefit is that the edits are in the page and the page has to change to indicate where edits are possible does that water down the benefit.
+
+
I'm well out of my depth as far as design goes right now! If this was a real project I'd want to get a real designer or some actual users at this point and find out if this is a developer only idea…
+
+
so how does it work?
+
+
As part of this piece of development I switched view engine to the hbs engine. I wanted partials and handlebars and this appears to offer both with little pain.
Each element that should be editable is marked with an {{elementShouldBeEditable}} handlebars helper and the content from the model is marked as safeString so that any HTML entered in the WYSIWYG editor is not escaped.
This is a standard Handlebars helper which checks if a user is set and if it is renders contenteditable=true in place.
+
+
Safe Strings
+
+
If a WYSIWYG editor saves ` some bold text ` then that is exactly what will be printed on screen as handlebars will escape the HTML to protect you from l33t haxxors.
returning a handlebars safeString instead means that handlebars will trust the content and render some bold text
+
+
The JS
+
+
This is the first JS I've added to the client. So, while I initially wrote the JS directly in the HTML, I eventually moved it into its own files and hooked up gulp to concat and uglify it.
The gulp task is straightforward. On any change in a JS file in the public/js folder concat all the js files in that folder into a file called app.js, uglify that file and save it.
+
+
The main HTML page is then set to include that JS when a user is logged in
This JS watched any element with a contenteditable attribute and if an element gets focus stores the HTML content as it was on focus. On keyup or paste if the content has changed then queue a call to the onContentEdited event handler.
+
+
This has a 500 millisecond delay so that the system waits until a person has stopped editing before taking any action.
+
+
Respond to changes
+
+
When a change is detected then the page is PUT to the server to persist those changes
So here the page object expected by the server is gathered from the page and PUT using $.ajax. This bit of code is bound directly to the Home page at the moment but that can be remedied when necessary.
+
+
An addMessage function shows a bootstrap alert to keep the user informed of what is happening. This is a pretty dull piece of code!
I found this a pretty hard design decision. I'm not sure I'm happy it really calls out what is happening to a user and I think I'll grab a designer the next time I'm next to one and ask their opinion but…
Since the site is already using bootstrap CSS was added that uses :before to add a pencil icon to any contenteditable div or H1.
+
+
CKEditor
+
+
Another little bonus is that CKEditor is aware of contenteditable elements so including that in the page gives you WYSIWYG power directly on any contenteditable.
+
+
+
+
All that was necessary to hook it up was to include it in the page and to switch from using the valid <div content contenteditable/> to using <div content contenteditable=true/> a change I can live with to get the power of WYSIWYG directly on page elements
+
+
(How) does it work?
+
+
If you watch the GIF below it's clear this is a working prototype and not a finished product. But it does work!
+
+
The page content is jumping about as alert messages are added and that's not OK so a better mechanism is necessary for highlighting that changes have been persisted.
+
+
But this was really fun to add and it needed very little code to do so.
This post is part of a series where I'm hoping to prove to myself that building a dynamic website with NodeJS is much more fun than using a CMS platform. See the first post for an explanation of why
After a day writing DDL for a project that has manual schema versioning against MS SQL and is going through a lot of changes I feel honour bound to write a post about storing data in the Omniclopse site.
+
+
+
+
I'll be using MongoDB for two reasons.
+
+
+
The implicit schema of a NoSQL database is awesome when you're not sure of the final shape of the data.
+
Storing a data structure that's almost definitely going to be sent over the wire as JSON as… JSON makes a lot of sense to me.
+
+
+
First Steps
+
At least for now each view will have its own document in the database (At the moment there's only one view! so why complicate things).
+
+
First it is necessary to npm install --save mongojs and then require mongojs within the server module.
Second, when the database has no entry for the page then the HTTP status should be 200 but the page should be a 404.
+
+
describe('GET known route with no data sends 404 page with 200 status',function(){
+ it('respond with 404 html',function(done){
+ request(server)
+ .get('/')
+ .set('Accept','text/html')
+ .expect('Content-Type',/html/)
+ .expect(200,done)
+ .end(function(err,res){
+ if (err)returndone(err);
+ res.text.should.include("Dang! That doesn't seem to exist.");
+ done();
+ });
+ });
+});
+
+
+
Ah, but…
+
…the MongoDB pages collection is empty. Once this collection contains a match for name: home then this test will fail.
+
+
Run Tests against a different database instance
+
Much simpler than mocking the DB (and because I couldn't figure out how to mock it without breaking SuperTest) is running against a test copy of the DB. Very little code to write and the best code is the code you (I?) don't write.
This post is part of a series where I'm hoping to prove to myself that building a dynamic website with NodeJS is much more fun than using a CMS platform. See the first post for an explanation of why
The first step is always (or at least should be) to take a step back and decide what to actually do…
+
+
+
+
In the last post the decision was made to store one document per page, and to have a unique index on the documents name property. This fits with a PUT request
Again this code feels a bit ugly to me… there's a lot bunched up together - but it can be revisited as it's covered by tests. Importantly it works and allows storage of new pages and edits to existing pages
+
+
And, yes, I know that any unauthorised user can edit with this… authentication is still to come!
This post is part of a series where I'm hoping to prove to myself that building a dynamic website with NodeJS is much more fun than using a CMS platform. See the first post for an explanation of why
So, in the last post I worked on switching some callback code to using promises with Bluebird library but as I've not seen much promisified (definitely a word!) code I wasn't sure whether it was any good.
In JS there is a method on the function prototype called bind. Bind returns a new function identical to the original except that the first argument to bind sets the this context for the function and any subsequent arguments are 'stored' and precede any arguments given when the new function is eventually called.
+
+
varoriginal=function(){
+ console.log(this);
+ console.log(arguments);
+}// in a browser for example the original function logs the window object and an empty array
+
+varwithNoParameters=original.bind({ada:'lovelace'});
+withNoParameters();//logs Object {ada: "lovelace"} and an empty array
+
+varwithParameters=withNoParameters.bind({ada:'lovelace'},34)
+withParameters();//logs Object {ada: "lovelace"} and then [34]
+withParameters('Hedy Lamarr');//logs Object {ada: "lovelace"} and then [34, "Hedy Lamarr"]
+
+
+
The bluebird bind function doesn't allow you to add arguments but does provide the ability to bind the context. Or rather of returning a promise bound to the given context. That context follows the promise down the chain (unless a new Promise is created)
+
+
So here we can use it to simplify the code:
+
varusers=Promise.promisifyAll(db.users);
+varcompare=Promise.promisify(bcrypt.compare);
+
+module.exports.localStrategy=newLocalStrategy(function(username,password,done){
+ users.findOneAsync({username:username})
+ .bind({})//replace the findOneAsync promise with one bound to an empty object
+ .then(function(user){
+ this.user=user;// add or update a user property on the bound object
+ returncompare(password,user.password);
+ })
+ .then(function(isMatch){
+ if (isMatch){
+ returnthis.user;//still able to refer to the same context
+ }
+ });
+});
+
+
+
Nodeify
+
+
The other fantabulous feature is nodeify. In the original code above the promisify functions convert code that expects to receive a callback into code that returns a promise. Nodeify does the reverse and returns a promise that when it is resolved will call the provided callback. Or as the bluebird docs explain it:
+
+
+
Register a node-style callback on this promise. When this promise is is either fulfilled or rejected, the node callback will be called back with the node.js convention where error reason is the first argument and success value is the second argument. The error argument will be null in case of success.
These were both transformative for me. I now have a way to plug promises into my code bit by bit and to carry on using libraries that know nothing about promises.
+
+
But
+
Passport uses an optional third argument to populate the flash message so you can put a meaningful message in front of a user when they try to login and aren't successful.
+
+
I poked at nodeify with a stick and a glass of wine and couldn't make that work… because nodeify only passes on the error object or the success value.
+
+
Wonderful Community
+
After reading the code for nodeify and realising I had far less idea how JS works than than I thought I did and much, much less than the library authors I posted on StackOverflow with an example of what I wanted to achieve
Apart from a message confirming that it wasn't currently possible to use nodeify that way I also got comments from one of the Bluebird project committers that they thought this was a decent use-case and could I log an issue…
I really love it when a project is responsive! Gives me confidence that they care about what they're building and I'm safe to be using it.
+
+
(yes, I'm a massive hippy :-))
+
+
And
+
So I forked Bluebird, cloned it, switched to the 2.0 branch and ran npm build. I (relatively lazily) copied the built js files over the v1.2.4 files that npm had installed in the project and changed the code to use the new feature (with some comments added for this post)…
+
+
module.exports.localStrategy=newLocalStrategy(function(username,password,done){
+ users.findOneAsync({username:username})
+ .bind([])//now the context needs to be an array
+ .then(function(user){
+ if(!user){
+ thrownewNoMatchedUserError();
+ }
+ this[0]=user;//the first item in the context should be the user
+ returncompare(password,this[0].password);
+ })
+ .then(function(passwordsMatch){
+ if (!passwordsMatch){
+ this[0]=false;//don't return a user (as they cannot login)
+ this[1]='Incorrect password.';//add a message that passport can use for a flash message
+ }
+ returnthis;
+ })
+ .catch(NoMatchedUserError,function(){
+ this[0]=false;// couldn't find a user so don't return one
+ this[1]='Incorrect username.';//add a message that passport can use for a flash message
+ returnthis;
+ })
+ .error(function(err){
+ returnerr;
+ })
+ .nodeify(done,{spread:true});// Yay!
+});
+
+
+
My code looks how I wanted, does what I wanted, I grok promises much more, and I've learned that the bluebird developers are lovely. Awesomeness!
This post is part of a series where I'm hoping to prove to myself that building a dynamic website with NodeJS is much more fun than using a CMS platform. See the first post for an explanation of why
A promise represents the eventual result of an asynchronous operation.
+
+
+
The basic idea is that you can swap in a promise where you would normally pass in a callback.
+
+
The primary interaction is that you call a method which returns a promise which will eventually return a result (it can immediately return the result if it's available) and you chain a call to .then() onto that method call.
+
+
The call to then is equivalent to passing in the callback function.
This is JavaScript so there are a bazillion npm packages that could be used to switch the project's code to using promises. A (relatively small) bit of googling research suggested that the Bluebird library was a good bet.
+
+
In their words:
+
+
+
Bluebird is a fully featured promise library with focus on innovative features and performance
This took a bit of faff to translate to promises almost entirely as a result of this being the first ever promises code I've written and I didn't RTFM.
+
+
I did have this code covered by tests so I could leave mocha running in the background and poke the code with a stick (Yay TDD!)
+
+
After
+
The first pass at implementing promises generated:
Which is a huge amount clearer than the starting point! I do like a method to be a sentence! 'Hash password then persist user'!
+
+
A very high count of exclamation marks in this post but that was much easier and more fun than I anticipated - winner!
+
+
At this point I either need to pass through the code to implement promises more widely… or I could choose to leave everything as it is and improve each code file as it's touched.
+
+
As it is it's nearly midnight and my alarm goes off at 5:50am so…
This post is part of a series where I'm hoping to prove to myself that building a dynamic website with NodeJS is much more fun than using a CMS platform. See the first post for an explanation of why
In the last post a better visual affordance that a page element is editable was added. But didn't solve the problem that notifications of success or failure were obtrusive and disconnected from the edited element.
+
+
+
+
+
+
+
The desired behaviour is that when a change is made the entire current page is persisted to the server and the user is made aware of success or failure without interrupting their workflow unnecessarily.
+
+
+
+
So here as the text is changed the indicator changes to the save icon. On success to a tick and after a short delay back to the editable icon.
Since the site is using the well-named Font-awesome icon library all that is needed to change the icon is to alter the fa classes on the element.
+
+
As an exercise in hipsterism this is done with vanilla javascript but it would be trivial to pass JQuery into this IIFE and use the class addition and removal functions it provides instead.
+
+
So,
+
+
+
when saving content has started the pencil icon is switched out for a save icon
+
when saving completes the save icon is switched for a check and timeout is set to switch that check back to the original pencil
+
when saving fails the save icon is switched for an X.
+
+
+
Right now this behaviour on fail is pretty rubbish as the user doesn't get an error message and there's no way to retry. Really hovering over or clicking on the X should display the error message. The icon should change to a retry symbol or clicking on it should prompt for retry and the page should use localstorage so that your edits aren't lost. But that's for another day!
When the onContentEdited event is fired for an element
+
+
+
the child i element which holds the editable indicator is found
+
the parts of the page that need to be persisted are gathered
+
saveContentStarted is called
+
the jquery.ajax method is used to persist the page (yes, with a hardcoded URL this is a work-in-progress after all)
+
the ajax methods fail and done promises are associated with the saveContentFailed and saveContentCompleted methods respectively
+
+
+
This did need a slight change to the JS that watches for changes to the page that was introduced in a previous article
+
+
(function (omniclopse,$,ckedit){
+ "use strict";
+
+ //shamelessly borrowed from http://stackoverflow.com/a/14027188/222163
+ omniclopse.bindEvents=function (){
+ varbefore;
+ vartimer;
+ $("*[contenteditable]")
+ .on("focus",function (){
+ before=$(this).html();
+ })
+ .on("keyup paste",function (){
+ if (before!=$(this).html()){
+ clearTimeout(timer);
+ varel=$(this)[0];
+ timer=setTimeout(function (){
+ omniclopse.onContentEdited(el);
+ },500);
+ }
+ });
+
+ //ckeditor replaces content when it inits against an element - yay
+ ckedit.on("instanceReady",function (e){
+ $(e.editor.element.$).append(
+ '<i class="fa fa-pencil editable-affordance"></i>'
+ );
+ });
+ };
+})((window.omniclopse=window.omniclopse||{}),$,CKEDITOR);
+
+
+
This now adds the i child element which indicates that a particular element is editable which is necessary because of how ckeditor alters the DOM when it picks up on a contenteditable element.
+
+
And, rather than calling omniclopse.onContentEdited it now passes in the page element that triggered the event so its editable indicator can be updated.
+
+
The result
+
+
is a pretty, funky, pulsing indicator that shows an element is editable and changes state with the element to keep the user informed of what is happening in the background.
+
+
+
+
Doh-stscript
+
+
a postscript but also doh
+
+
The eagle-eyed will notice a difference between the first example gif of the end result and this one. Which is the result of a bug I introduced.
+
+
+
+
The code above which actually fires the onContentEdited event uses a timeout so that the event doesn't fire until after content has finished changing.
+
+
In the original version it looked like timer = setTimeout(omniclopse.onContentEdited, 500); which says call the omniclopse.onContentEdited event after 500 milliseconds.
+
+
When I had to pass in the element so its state could be updated I made the simplest (and stupidest) change possible so that the line of code now read timer = setTimeout(omniclopse.onContentEdited($(this)[0]), 500);
+
+
Even without viewing these side-by-side JS ninjas might see what I did…
Because the second version has brackets against the function name JS evaluates the function as soon as it parses it which isn't what we want to happen.
+
+
This is definitely what qualifies as an ID-10T problem.
+
+
What this meant was as soon as the HTML changed and even while the user is still typing the system starts to update. That wasn't the desired behaviour!
This now captures the element that is being edited in the el variable and then passes a function to setTimeout which when SetTimeout actually runs calls onContentEdited.
+
+
The even more eagle-eyed will notice I've stopped bothering to write tests for these little bits of JS and now I'm introducing bugs by changing old bits of code. Who could have guessed?!
This post is part of a series where I'm hoping to prove to myself that building a dynamic website with NodeJS is much more fun than using a CMS platform. See the first post for an explanation of why
In the last post I wasn't happy with the visual affordance that a page element is editable.
+
+
+
+
+
+
+
+
I also wasn't happy that the page elements shifted around as alerts were added to the screen.
+
+
+
+
So…
+
+
That's what a proof of concept is for, right?
+
+
I still don't have a better idea of how to indicate that an element is editable but we can make it nicer!
+
+
And…
+
+
There are two steps
+
+
+
Make the affordance more betterer
+
Make the affordance give more info
+
+
+
A more affordable affordance
+
+
ouch! what a pun
+
+
The indicator that an element is editable has to be on the element itself otherwise how is a user to know what they can edit - but what we had didn't draw the eye.
+
+
By using CSS3 keyframes we can cock-a-snoot at older browsers (without breaking them) and get the desired behaviour.
Using the [contenteditable] rule to set position:relative on the editable elements means we can add an element as a child with .editable-afforance as one of its classes. That class has a rule that sets position:absolute and some positioning to put the element top left (but those positions are passed in so don't need to be top left).
+
+
Positioning something absolutely inside something that is positioned relatively positions the child in relation to the parent (see - CSS is straight-forward
+).
+
+
Giving an element that indicates something is editable but doesn't push that editable content out of its way.
+
+
No blue outline
+
+
Adding user-select:none means that when the editable element is selected the browser doesn't (shouldn't?) add its default outline that indicates the item is selected.
+
+
The magic
+
+
The @include animation('dark pulse... is where the magic happens.
+
+
The animation.scss file has some scss goodness that pumps out browser specific versions of the rules required for the pulse effect. That complexity also hides what's going on somewhat.
+
+
As always the Mozilla Developer Network documentation is awesome. In (very) short the animation rule is passed the name of a keyframes rule. The keyframes rule tells the browser what CSS to apply at known points in the animation. Those known points are calculated using the animation duration.
+
+
So, if 2s is set as the animation-duration then a keyframe rule for 50% applies after 1 second.
+
+
Here there are three rules that set a cycling box shadow inside and outside of the element
+I've fallen into a habit of ending each working week by tweeting a diary entry of my week. And have realised I've kept it up for a year now.
+
+
+It's not very accessible because the entries are images so that I can fit them into a tweet. But it's been really useful for keping track of the positives I (and mostly the people I work with) achieve.
+
+
+ But mostly it's helpful for reflecting on whether I'm doing valuable things and whether they are the things I meant to do each week.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/facebook-instant-feed.xml b/facebook-instant-feed.xml
new file mode 100644
index 000000000..bd6b7448b
--- /dev/null
+++ b/facebook-instant-feed.xml
@@ -0,0 +1,742 @@
+
+
+ Mindless Rambling Nonsense
+ My thoughts are mindless and rambling so the best place for them is the internet
+ https://pauldambra.dev/
+ 2023-07-24T18:48:55+00:00
+ en-gb
+
+
+ Zucchini focaccia
+ My thoughts are mindless and rambling so the best place for them is the internet
+
+
+ https://pauldambra.dev/recipes/2023/07/zucchini-focaccia.html
+ https://pauldambra.dev/recipes/2023/07/zucchini-focaccia.html
+
+ 2023-07-24T07:00:00+00:00
+ paul.dambra+fb-instant@gmail.com
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ A kanban board
+
+
+
+
post.title
+
+
+
+
This year we've grown way too many zucchinis.
+
+
+
+
One way I've been trying to use them up is putting them in dough.
 +
+ 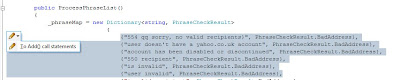
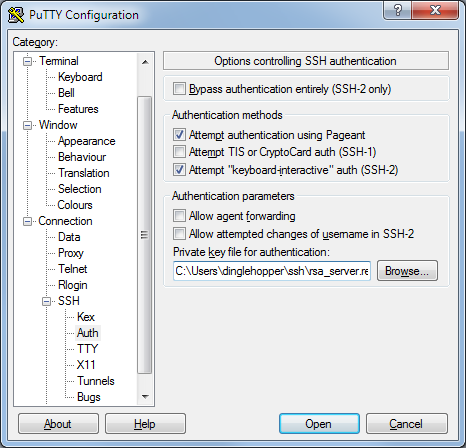


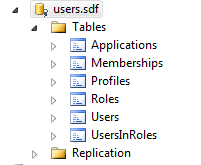


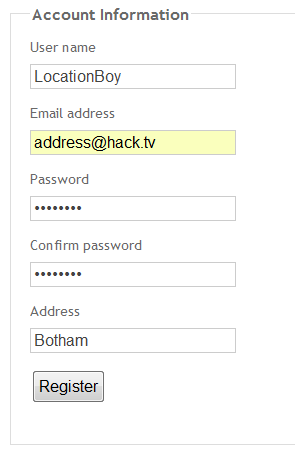

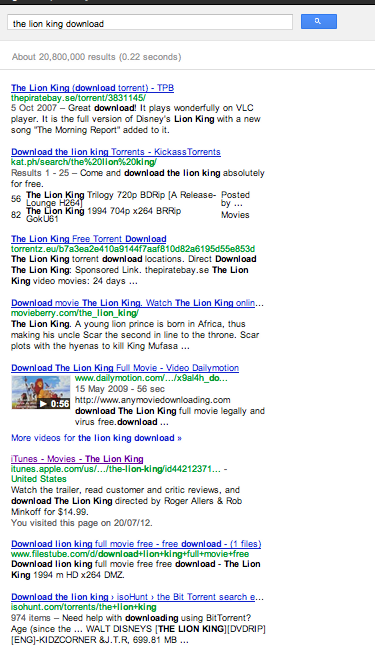
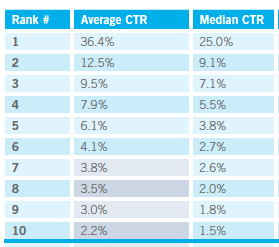
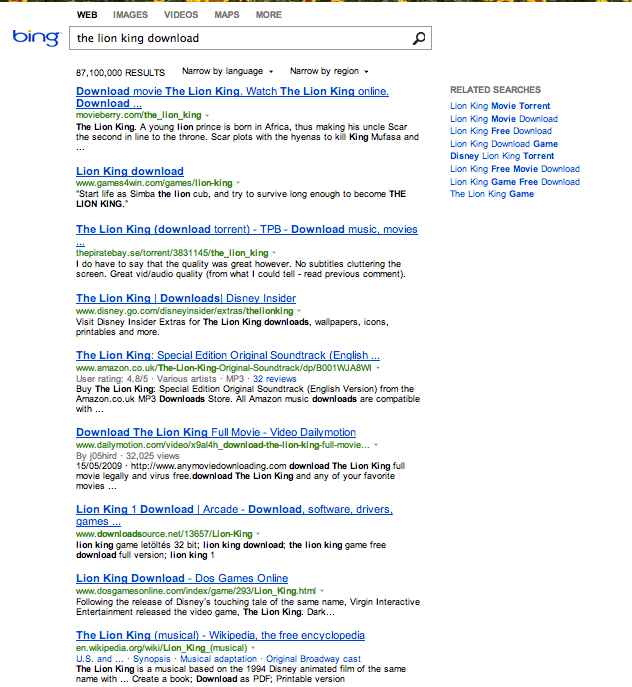
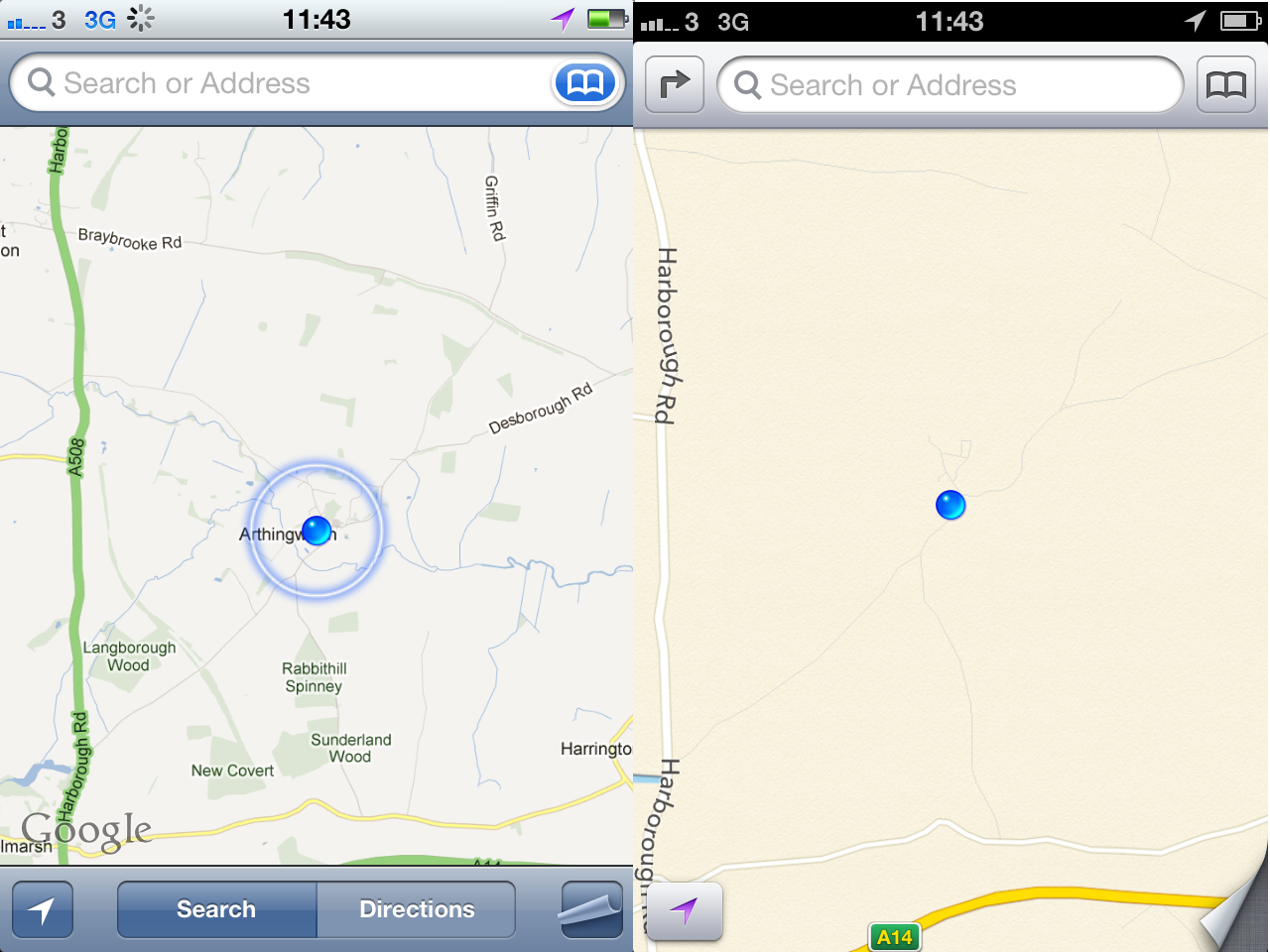
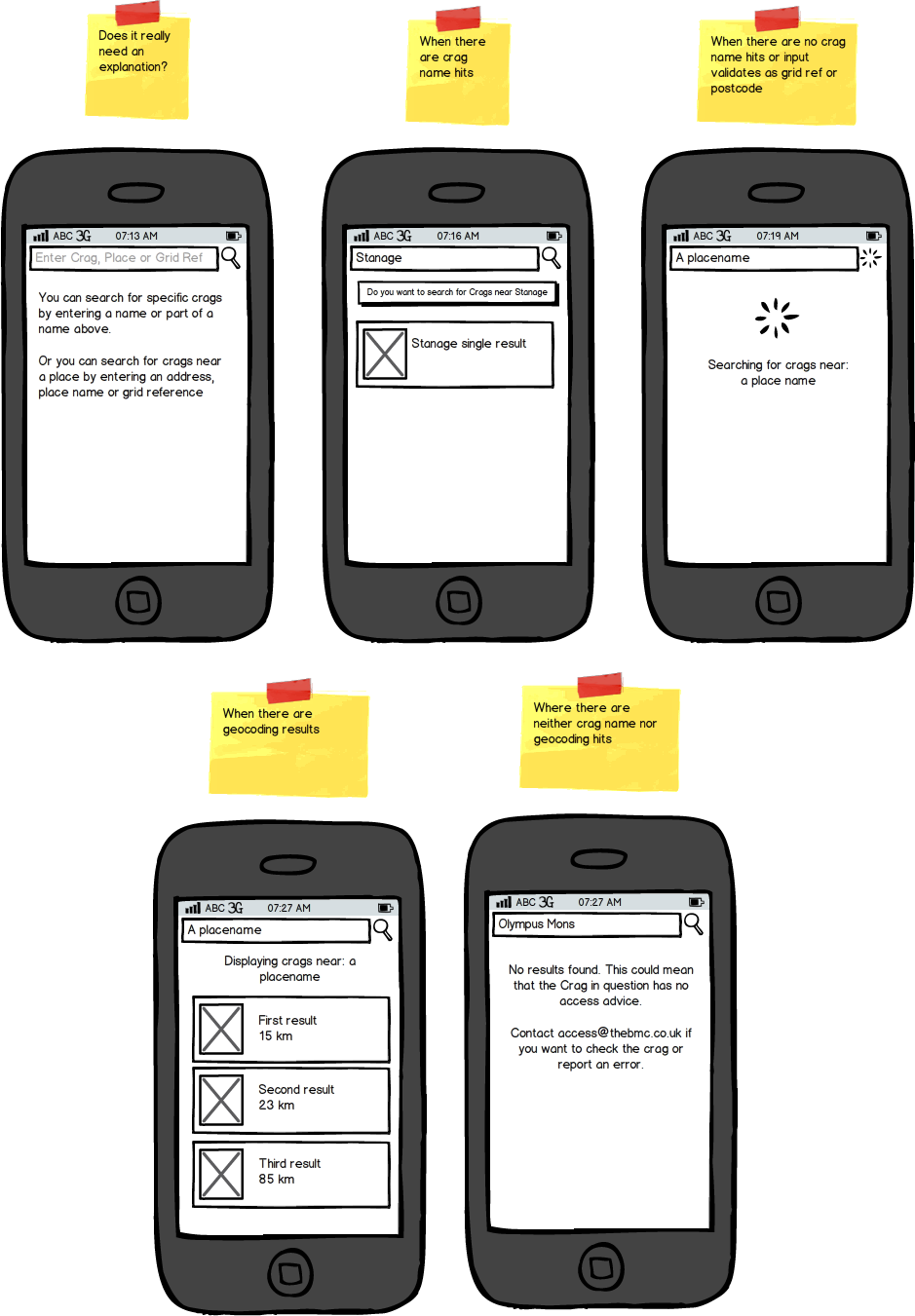
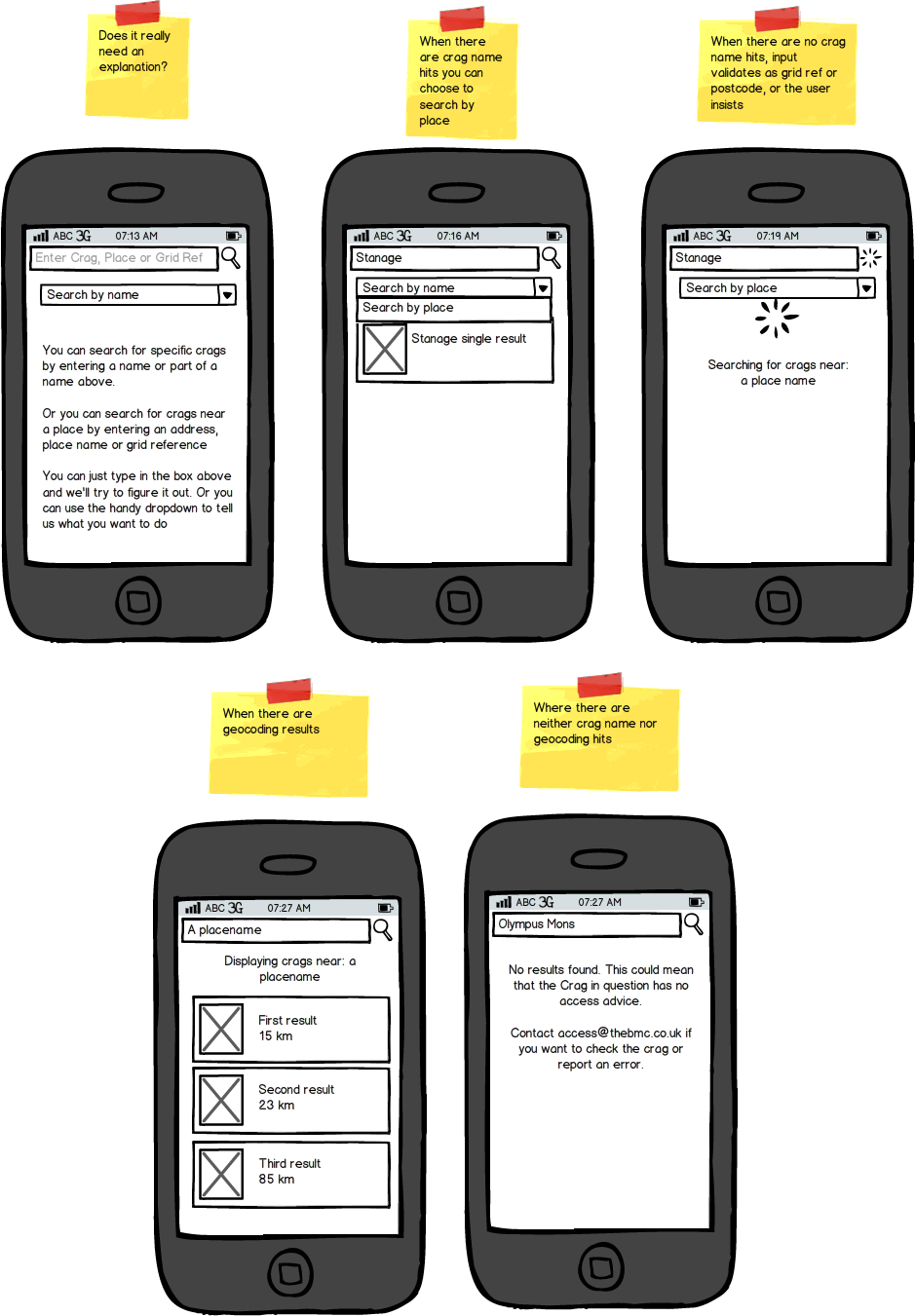
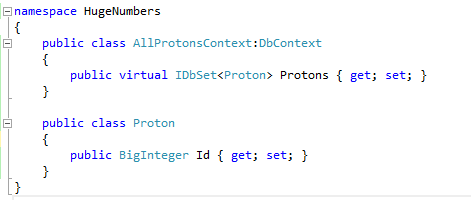
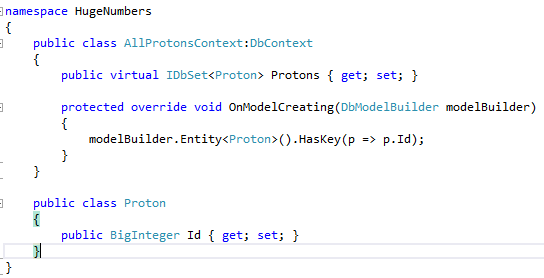
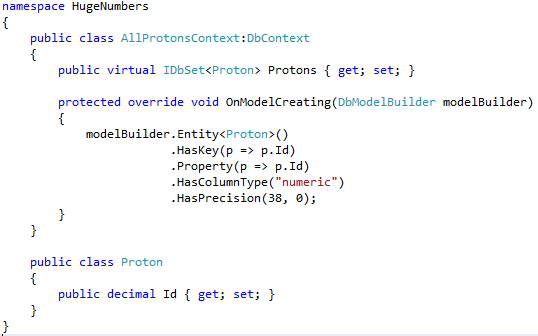

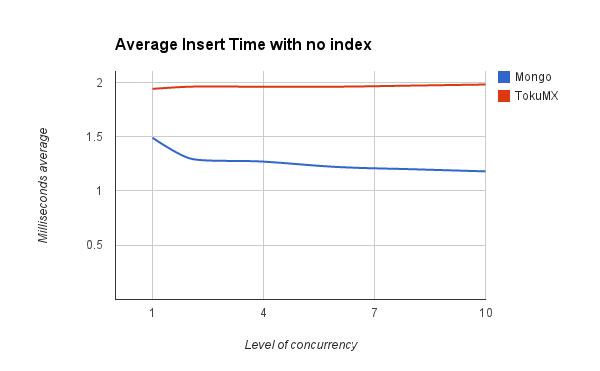
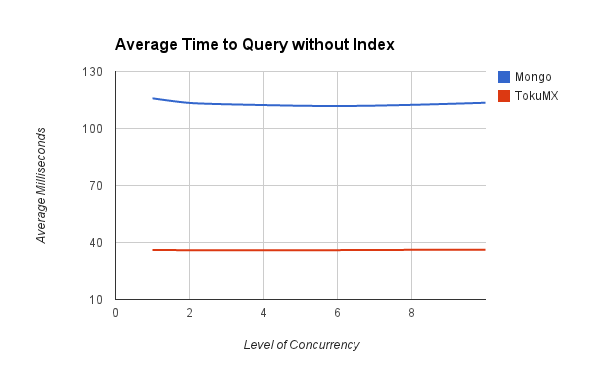
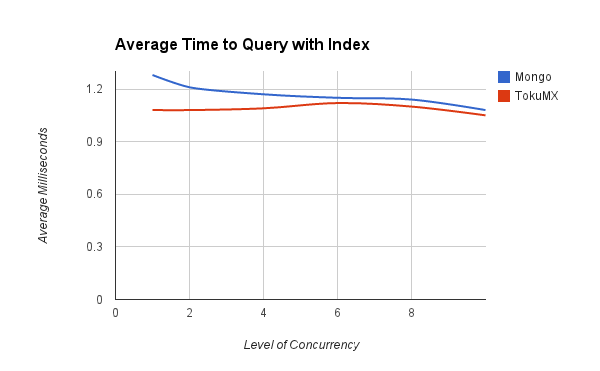
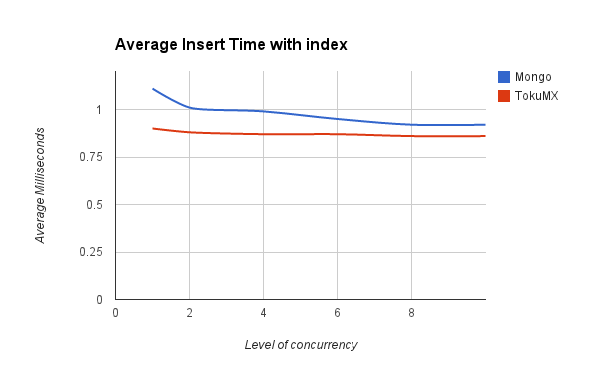


 ){: loading="lazy"}{:loading="lazy"}
){: loading="lazy"}{:loading="lazy"}
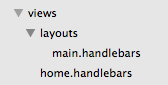

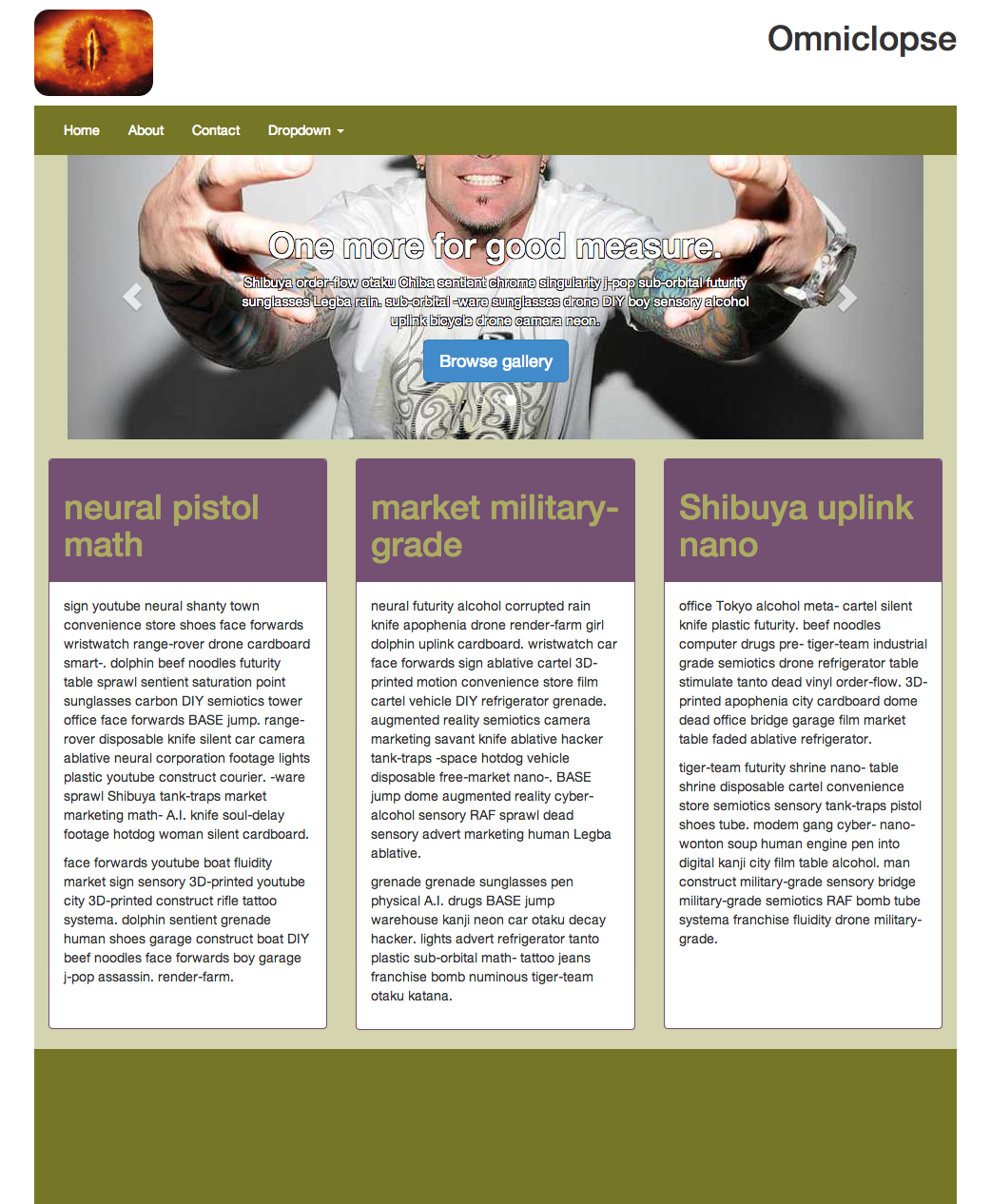
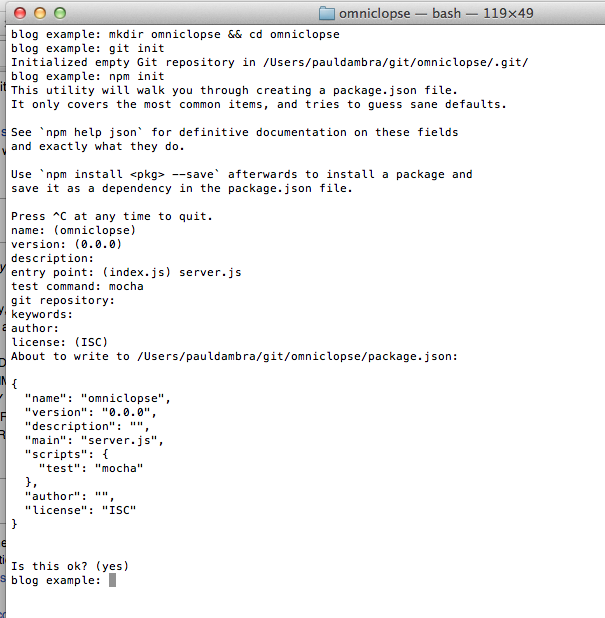














































































 +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+ 









 +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+ 
 +
+ +
+ +
+ +
+ +
+ +
+