PEP: 13
Title: OpenShift 3.x System Design
Status: draft
Author: Clayton Coleman [email protected], Daniel McPherson [email protected], Abhishek Gupta [email protected], Ben Parees [email protected]
Arch Priority: high
Complexity: 100
Affected Components: all
Affected Teams: all
User Impact: high
Epic:
OpenShift 3.x will incorporate a number of significant model changes to better align the PaaS with the evolving development and operational ecosystems - leveraging the Docker container runtime and image model, the Google container management model, and the Mesos scheduling and execution framework.
- Provide a high level abstraction for networked applications on top of containers that allows easy scaling, service discovery, and deployment
- Enable Docker image authors to easily deliver reusable application components, including highly available databases, monitoring and log aggregation tools, service discovery platforms, and prepackaged web applications
- Allow developers to deeply customize their runtime environments while preserving operational support at scale for those applications
- Expose concepts and APIs which enable higher level microservice platforms to reuse core container infrastructure
- Orchestrate and schedule Docker containers onto hosts at a level very close to the Docker API
- Allow operators to easily integrate external build and Docker image creation processes into OpenShift
The application model is being simplified to reflect real-world use cases around service-oriented architectures and to break down artificial barriers imposed in OpenShift 2.x.
- Cartridge
- a set of code and scripts that can be launched inside a Linux container and offers a specific function (web frontend, database, monitoring, cron)
- Cartridge Version
- a single version of a cartridge's metadata and code - there is only one active cartridge version for each cartridge in a deployment
- Gear
- a slice of system resources that runs the processes of one or more cartridges
- Gear group
- a set of gears with the same cartridges that can be scaled from 1..N
- Application
- a set of gear groups that has a single source repository (and deployment flow), a set of frontend aliases that map to a single load-balanced HTTP or SSL gear group, and shared environment variables
- Alias
- a public web endpoint identified by a project name and an optional set of SSL certificates that enables custom SSL security
- Domain
- a grouping of applications with shared access control and resource limits
- a domain is used for grouping multiple related applications with a common set of member roles or constraints
- Cartridge
- a deployable component within OpenShift
- Plugin Cartridge
- a cartridge that can only exist by being collocated with another cartridge inside a gear
- Plugin Cartridge
- a deployable component within OpenShift
These resources are nested:
- 1 account
- 0..N projects
- 0..N applications
- 1..N cartridge versions (but all versions must have different names)
- 1..M gear groups
- 1..P gears
- 1..L aliases
- 0..N applications
- 0..N projects
The 3.x model attempts to expose underlying Docker and Google models as accurately as possible, with a focus on easy composition of applications by a developer (install Ruby, push code, add MySQL). Unlike 2.x, more flexibility of configuration is exposed after creation in all aspects of the model. Terminology is still being weighed, but the concept of an application as a separate object is being removed in favor of more flexible composition of "services" - allowing two web containers to reuse a DB, or expose a DB directly to the edge of the network.
The core OpenShift use case is allowing operators to efficiently host applications and provide developers easy to run software environments. The key unit of exchange between a developer and operator is an image - the operator may provide a maintainable template for a runtime system to a developer, and the developer can customize or tweak that system to add their application code, and then provide the operator with an image that can then be deployed. The image represents a parameterizable set of code and configuration that can be reused across many environments (dev, production) and reliably redeployed even over time.
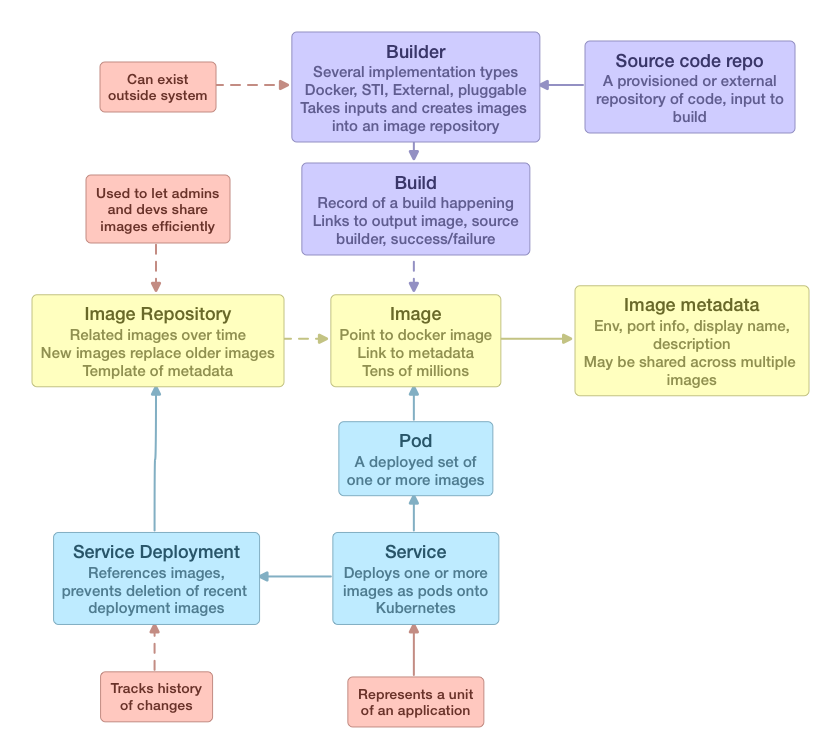
An executable image that represents a runnable component (web app, mysql, etc), a set of exposed ports, and an set of directories that represent persistent storage across container restarts
- an image may have extended metadata beyond that specified in the Dockerfile/registry
- how many instances of the image are required for normal function (1, 1..N)
- the environment variables it exposes that must be generated or specified (beyond the defaults in the Dockerfile itself)
- additional port metadata describing what type of network services are exposed
- named commands that may be run inside of an image for performing specific actions
- each image (contents and metadata) are immutable and changing them requires creating a new image (the reference to older image data or older metadata may be preserved)
- image metadata may change over successive versions of an image - multiple images may share the same metadata
- any image can be executed (which runs its default command/entrypoint), but different images may have different roles and thus not be suitable for execution as a network service
- An example is an image that contains scripts for backing up a database - the image might be used by a service like cron to periodically execute tasks against a remote DB, but the image itself is not useful for hosting the DB
- images are protected by reference - if you have access to a resource that refers to an image, you can view that image
For more details about images and exposing software as components within in OpenShift, see the Docker cartridge PEP.
A set of images with a given name corresponding to a Docker repository in a registry (a set of images where a single tag represents the latest image that people pull by default). A repository has 1..N tags - the implicit "latest" tag refers to the image that would be retrieved / used if the user did not specify a tag
- an image repository has a set of default metadata which is applied to every image created under that stream, which allows an operator to define an image repository and then push images to the stream and have that metadata set
- Use case: allows operators to provide security updates to end users - allows end users to rely on a continuously maintained piece of software
- Use case: allow developers and operators to share a set of images across multiple applications and environments
- An image repository would expose a webhook that allows a consumer to register a new image, as well as integrating into a Docker registry so that a docker push to a certain repository (probably uniquely identified by name and a short id) would add that image * Image streams are owned by a project or are public, and an administrator of that project can grant view access to that stream to other projects. Anyone who can view an image repository can use it. If access is revoked, any builds or services that reference that stream can still use it.
- Retention of images is controlled by reference - deployed services, service deployment history, and recent builds all take strong references on individual images in a stream and control when images pass out of scope.
- Image repositories may be global in scope to a deployment as well as per project
A build creates a docker image as output and places that image into a single image repository.
- there are two defined types of build:
- Docker build takes as input as input a source repository or an archive containing a resource
- Source build takes as input a builder image and a source repository
- A source build is typically based on either an image, OR an image repository
- a build is owned by a project
- a build result is recorded whenever a build happens
- a build provides a webhook resource for remote servers to notify a build that an underlying image or repo or archive has changed (allows consumers to trigger builds)
- build results history may be removed when it reaches certain limits
- a build has configuration to control whether an automatic build occurs when an input changes
- a build exposes an endpoint that allows a consumer to POST an archive that results in a build
- Example: post a WAR file to a source-to-images build that results in that WAR being deployed
- Example: post a zip of the source contents of a Git repo to the build endpoint to result in a Docker image build using those contents as the Docker build context
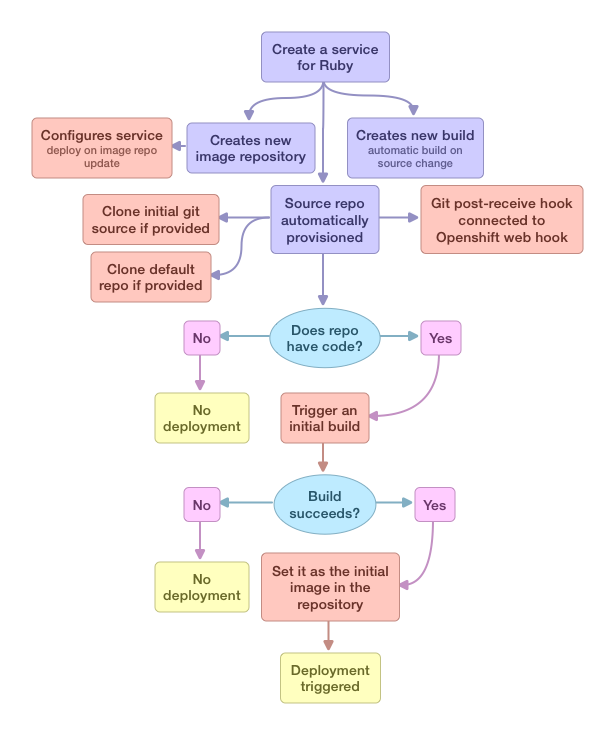
OpenShift 2.x embeds a git repository in the first gear of every application - in OpenShift 3.x, source code repositories are referenced or owned by a service, but are not physically located inside the gears of that service.
- The APIs for repositories should be flexible to other types of source code repositories, but OpenShift will focus on Git integration
- When creating a service a user may
- specify that a source code repository be allocated for that service
- the repository will be secured with the keys and tokens of the owning project
- a build will be defined using the "source to images flow" if the image(s) used by the service support STI
- a git postreceive hook will be configured that triggers the build hook, if a build exists
- reference an external source code repository and optionally provide authentication credentials for the repository (private key, username or password)
- a build will be defined using the "source to images flow" if the image(s) used by the service support STI
- the user will be able to download a commit hook that they can put into their git repository
- specify no repository
- When a source code repository is connected to a build, there is a set of config on that reference that what source code specific options apply (similar to 2.x):
- Trigger build only a specific branch (optional, defaults to false) * Whether to automatically build (is the link present or not) * Any service with a referenced source code repository has a source code webhook exposed via the API which can be used to trigger the default flow
- specify that a source code repository be allocated for that service
- A user should be able to easily push a Docker image to OpenShift and have applications be redeployed
- An integrator should be able to easily notify OpenShift when the inputs to a build have changed (source code or base image) as well as notify OpenShift of the existence of a new image generated by an external build
- Workflows on top of images should be able to refer to an image repository instead of having to directly specify an image
- A system administrator can manage the total images in use across the system by setting retention policies on accounts
In a 3.x system, an image repository is a reusable component across multiple services - builds generate images and place them into image repositories, third parties can push new images into image repositories via docker push, and developers can push source code to git repositories (internal or external) that trigger docker builds and source to image builds that then result in new images. Services deploy based on images, not on builds or source code, which means any image creation can be used as the input to a deployment.
- Images may be referenced externally (via their full name <registry>/<user>/<repository>) or pulled into the integrated OpenShift registry
- An image repository should support a direct
docker pushwith access control from a Docker client to the integrated OpenShift registrydocker push my.openshift.server.com/<some_generated_user_name>/mysql-58343 - An image repository should have a webhook endpoint which allows a new image to be created when a 3rd party builds an external image (like the DockerHub)
- In the future it would be nice to be able to automatically pull that image into the integrated registry
- A build can be triggered by a DockerHub build webhook (for a base image) or a GitHub commit webhook (for an external source repo)
In OpenShift 2.x, the primary unit of access control was the domain, which has a membership list and each member is granted a specific role. Someone with access to a domain sees all of the resources belonging to the domain. The domain owner may allow a subset of their capabilities to be expressed within the domain in order to subdivide their resources across multiple subsets of users - for instance, by limiting the gear sizes or cartridges available to an end user.
In 3.x this pattern will continue, but we will rename the domain to a project to more closely associate the concept with its common use.
The project is the set of resources that a team of people with a joint objective can access - the role each person or machine has on the project applies to each resource in the project.
- Should be used to subdivide visibility and control
- Should represent the fundamental units of the organization creating the software
- team A creates a web service that is used by team B, both teams have their own projects
An account owns a set of projects and, by extension, the resources within those projects. Accounts represent an entity like a person or business organization or company that is charged / granted access to a set of cluster resources.
- In most deployments, each account corresponds to a single user.
- An account has an ownership relationship to zero or more projects
- The resources an account may use (its capabilities and limits) can be selectively divided among the projects it owns
In a system with multiple login providers and ways of authenticating, an identity is the combination of a source of users and the unique user identifier within that source. As an example, a person may log in directly to a system and have an identity of "dc=example.com,cn=bob" in the company LDAP, but that person may also be [email protected] in Facebook. Both identities point to the same account, but the identity (source of authentication) is kept for audit purposes.
- An account always has 1..N identities
- Most systems will have a default identity
- All actions in the system should be associated with an identity and an account
It should be possible to grant access on APIs and resources of a project to an automated system without requiring the creation of a new user account. Each project should allow 0..N machine identities to be created which can have individual authorization tokens granting access to the project.
- A machine identity may be created by the owner or administrator of a domain
- A machine identity may have 0..N authorization tokens
- A machine identity may have 0..N private SSL keys assigned to it with downloadable public keys
- A record of all machine identities and their authorization tokens and the creators of those identities and tokens should be stored for audit purposes
- Any API action taken by a machine identity should be identified as such
- When integrating with external source control solutions, the machine identity SSH private keys will be used to authenticate to the remote solutions over SSH. There may be a need to pick the appropriate keys offered.
In general the OpenShift access control model focuses on roles rather than assigning individual permissions. It makes clients easier to build and is easier for users to reason about. To that extent, we expect to continue to offer the same generally increasing roles we have in 2.x, with the potential for more flexibility in customization.
Defined roles:
- View - Can see everything except secure data, does not necessarily have SSH access
- Edit - Can create or delete services, but not modify resource limits or assign access control
- Admin - Can assign access control, and modify some resource limits
- Admin(owner) - Can modify all resource limits
A long term objective is to ensure the owner role is decoupled from a single account, so that organizations are less vulnerable to a single person leaving. A new role may be created "owner" which allows other owners to be assigned and to set resource limits.
Both large and small web applications (and supporting software like databases and message brokers) lean naturally towards tiers of single-responsibility software working together over the network. Some components are stateful and can only run a single instance (traditional SQL databases, legacy applications) while others are able to work without state or dynamically copy their state from their peers (many modern web apps, replicated NoSQL databases). Classic two or three tier applications involve a web layer, a database, and potentially a message bus. In larger projects, teams of developers expose services with strong, versioned APIs for use by other components. As the size of an architecture increase, services tend to get smaller, change less, and focus on scale - these are often called microservices.
The OpenShift 3.x application model recognizes all three scales, and focuses on enabling composition of many different types of software rather than being limited to a single web-focused world.
A running execution environment based on an image and runtime parameters
- a container encapsulates a set of processes and manages their lifecycle and allows a unit of software to be deployed repeatably to a host
- gear is the historical OpenShift term for a container and will continue to be exposed via the user interface
A set of related containers that should be run together on a host as a group. The primary motivation of a pod is to support co-located, co-managed helper programs.
- a pod enables users to group containers together on a host and share disk storage, memory, and potentially access each other's processes.
- images beyond the first in a pod can be thought of as plugins - providing additional functionality through composition
- a pod template is a definition of a pod that can be created multiple times
A pod definition that can be replicated 0..N times onto hosts. A service is responsible for defining how a set of images should be run and how they can be replicated and reused by other services, as well as defining a full software lifecycle (code, build, deploy, manage).
- All services have environment variables, aliases, an optional internal or external source code repository, a build flow (if they have a source code repository), and a set of deployments
- a service is a template for a sequence of deployments which create actual containers. The service has 0..N current deployments, but typically transitions from one deployment to another.
- a user may customize the ports exposed by an image in a service
- note: the term services currently overlaps with the Google service concept - there has been discussion about renaming that to "lbservices" because the service term is generic. TBD
Some images may depend on persistent disk data (such as a database) - these images have special rules that restrict how a pod containing them may be replicated, moved, or configured
- in a stateful service, a "move" operation is exposed for each pod that will relocate the pod onto another host while preserving the data of that pod
- this operation is yet to be defined but would likely be a pod specific action
- stateful services may incur downtime when a host is rebooted or fails, but the system will be designed to minimize that downtime
- by design, stateless services may be aggressively moved and the system will prefer to create extra pods in new locations and delete existing pods in the old locations
Each service has 0..N environment variables (key value string pairs) which may be set by the user, automatically generated at creation, or automatically provided by a link, that are available at runtime in each container in the service
- Automatically generated environment variables may represent passwords or shared secrets, and can be overriden by the user post-creation
- Link environment variables may be overridden by a user environment variable (to the empty string or a different value) but if the user unsets the user environment variable the link variable will return
- The pod template for a service may also define container level variables, which override service environment variables.
- If an image requires a variable be generated, but does not publish it (via a link), the variable is only defined on the pod template. A published variable is added to the service environment.
- Changing an environment variable may require a deployment (if only to update environment settings). It may be desirable to offer a faster change process.
A historical or in-progress rolling update to a service that replaces one service configuration with another (primarily updating the image, but also changing ports, environment, or adding new images). A deployment is a snapshot of the state of a service at a point in time, and as such records the history of the service.
- Recording deployments allows a user to see the history of the deployments of a service, rollback to a previous configuration, and to react to ongoing deployments
- A deployment may be automatically triggered by a build, by manual intervention with a known image, or via an API call such as a DockerHub webhook.
- Some deployments may fail because the ports the old image exposes differ from the ports the new image exposes
- A deployment in the model records the intent of what a deployment should be - a deployment job carries out the deployment and may be cancelled or stopped. There may be pods representing multiple deployments active in a service at any one time.
- A deployment retains a reference to an image - the retention policy of deployments controls which references are valid, and as long as an image is referenced it will not be deleted.
- A deployment does not control the the horizontal scale of a service, and during a deployment the number of pods created may exceed the current horizontal scale depending on the type of deployment requested.
- There are different deployment types:
- External - user defines the new deployment, and creates or manipulates the underlying replication controllers corresponding to the service to add or remove pods for old and new versions
- Simple rolling deploy - pods corresponding to the new template are created, added to the load balancer(s), and then the old pods are removed from the load balancer and then deleted
- TBD
A relationship between two services that defines an explicit connection, how that connection is exposed environment, a proxy or load balancer), and potentially whether start order is significant.
- Use Case: A link allows one service to export environment variables to another service
- Use Case: A link may be used by the infrastructure to create or configure proxies to service a load balanced access point for the instances of a service
- A link represents an intent to connect two components of a system - the existing "add cartridge" action is roughly translated to "create a new service and link to the existing service with a set of defaults".
- A link as described is different than a Docker link, which links individual containers. Service links define how sets of Docker links may be created.
A template defines how one or more services can be created, linked, and deployed
- Use case: A template allows users to capture existing service configurations and create new instances of those services
- A template also may have a deployment script (an embedded text blob, URL, or command in a known image), which is invoked as a job after the service definitions, links, and environment variables have been created
- A template merges the existing quickstart and cartridge concepts to allow precanned applications or units of software to be deployed.
- A template may be the target of the "create and link" action, which allows complex components to be templatized and reused. The template must identify the components that should be linked in this fashion.
- Templates may be global in scope to a deployment as well as per project
Additional enablement for services
A load balancing proxy server associated with the system capable ofhandling traffic for many services and protocols at once
- An installation of OpenShift may have multiple routers available at any time
- The system administrator may configure the system to assign DNS entries to services automatically - these entries are associated with a router via an alias
- Routers map frontends to backends that contain multiple endpoints - a frontend may support multiple protocols (HTTP, HTTPS, Websockets) on different ports that are translated to a single port on the endpoints.
- The default router software will be HAProxy 1.5 with support for SSL and SNI load balancing. Additional integration with important load balancer software is planned.
A DNS name for a service that exposes one or more frontend protocols to a router for load balancing.
- For example, each service may be assigned a generated DNS entry "<service_name>-<project_name>.rhcloud.com" that is mapped to the IP address of an HTTP load balancer, which will route traffic to one or more containers in the service
- An alias may specify a TLS certificate which allows a router to terminate SSL for the service
- An alias may be mapped to one or more routers at a time, allowing services to be migrated across routers
- An alias may be configured to map different ports exposed by the container instances in the service
- An alias has similarities to a Kubernetes service and are likely to be merged / altered
A unit of work that encapsulates changes to the system that require significant resources, changes to other resources in sequence, or long delays.
- A job is executed as a run-once container (runs to completion and succeeds or fails) and is associated with the account, project, build, or service that triggered it
- Modelling jobs as container executions means that all framework actions are extensible and that resource limits can be applied to the execution of the task, and that the scheduler can prioritize framework actions according to available resources or prioritization
- Jobs may need to declare prerequisites or be scheduled to execute in a recurring fashion by being templated.
- Jobs may be queued, cancelled, or retried by the infrastructure
These resources are nested:
- 0..N public image repositories
- 1 account
- 0..N projects
- 0..N image repositories
- 0..X owned image repositories
- 0..Y shared image repositories
- 0..M references to images (images are one-to-many repositories)
- 0..N services
- 1 active pod definition (1..M images)
- references 1..M image repositories or explicit images
- additional per image config that becomes the template for containers
- references 1..M image repositories or explicit images
- 0..N instances of a pod
- 0..N deployments
- 0..1 source code repositories
- 0..1 builds
- 0..N aliases
- 0..N environment variables
- 1 active pod definition (1..M images)
- 0..N links
- 0..N image repositories
- 0..N projects
- 1 account

The system architecture is divided into a set of component subsystems, which will define the interfaces for interaction. The included figure describes the primary subsystems:
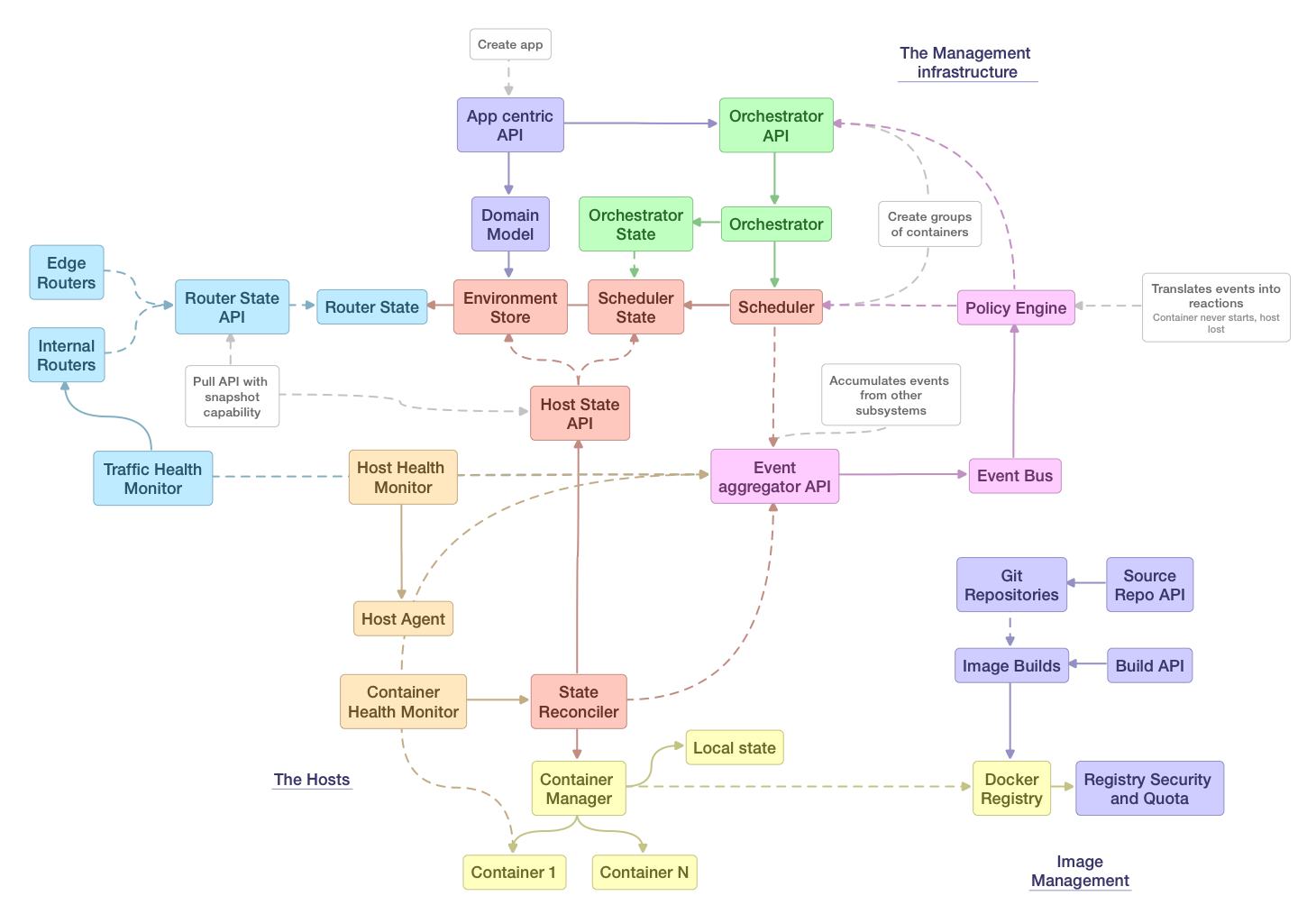
Implements a high level API that allows end users and clients to offer an application centric view of the world, vs a container centric view. Performs project validation on incoming requests and invokes/triggers the orchestrator and scheduler as necessary.
The API allocates source repositories via an API and configures them to bind to build hooks. The build hooks can trigger builds via the orchestrator onto hosts as containers, and then after completion push the new images into the registry and trigger other orchestrations like deployments.
A job API that schedules sequential execution of tasks on the cluster (which may run for seconds, minutes, or hours). Examples include triggering a build, running a long deployment across multiple services, or scheduled operations that run at intervals. A job creates a "run-once" pod and has an API for callback, blocking, or status. The orchestrator encapsulates all operations that run to completion that a client may wish to block on.
The scheduler (and cluster manager) would be Google's Kubernetes and exposes an API for setting the desired state of a cluster (via a replication controller) and managing the cluster. The scheduler is related to ensuring containers are running with a certain config, for autohealing the cluster as issues develop, and for ensuring individual hosts are in sync with the master. Over time, integration at a lower level with Mesos for fine grained resource allocation is desirable.
The event subsystem aggregates and exposes events from many sources to enable administrators, users, and third party observers to make decisions about the health of a system or container. The policy engine represents a component that may make decisions automatically based on events from the cluster. Examples of events include container exit, host unreachable, router detecting failed backend, node removed, or an alert generated by a hardware monitoring agent.
The policy engine is able to decide on the appropriate action in a customizable fashion. Some events are core to other subsystems and may flow through alternate means (as an example, Kubernetes may aggregate exit status of containers via its own API), but the general goal is to expose as much of the activity of the system to external observation and review as possible.
System integrators may choose to expose the event bus to containers.
Routers provide external DNS mapping and load balancing to services over protocols that pass distinguishing information directly to the router (HTTP, HTTPS, TLS with SNI, and potentially SSH). Routers subscribe to configuration changes and automatically update themselves with new configuration, and routers may be containerized or virtual (converting those changes to API calls to a system like an F5).
Other automatic capabilities exist to load balance individual services within the cluster - these would be exposed via configuration on link relations between services and would ensure a set of services would be available. Implementations may choose to implement these as local proxies per host, or to reuse the shared routing infrastructure.
The execution of containers is handled by systemd unit files generated by geard. Key access for SSH or additional linking information would be propagated to hosts similar to the container configuration. The host may also be configured to run one or more additional containers that provide monitoring, management, or pluggable capabilities. The container subsystem is responsible for ensuring logs are aggregated and available to be centralized in the cluster.
The status of containers and hosts is monitored by active and passive checks over TCP or through process level calls. The state reconciler has the responsibility of acting on failing heath checks on containers, while the host health monitor reports failing hosts to the event subsystem for the policy engine to act on.
Rather than forcing Git to be directly integrated into the hosting infrastructure, OpenShift 3.x will allow external integration to Git hosting. The requirements on a host are to be able to dynamically create a repository on demand, set git postreceive hooks, and assign security to those repositories that matches the ownership model in OpenShift. Features like high availability of the hosting infrastructure and the individual Git repositories are desirable. At this time, the GitBlit appears to offer the best open source component that can satisfy these limits. The integration will be pluggable at the code level, and possibly at an API level.
OpenShift should utilize any server implementing the Docker registry API as a source of images, including the canonical DockerHub, private registries run by 3rd parties, and self hosted registries that implement the registry API
- In order to connect to private registries, it is expected that authorization information may need to be associated with the registry source
- It would be desirable to develop plugins that allow smooth integration of an external access control model with individual repositories in the registry
- In many systems, imposing quota limits on repositories (size of image, number of images, total image size) may be necessary
An important focus in OpenShift 3.x will be enabling the components of OpenShift to run and be managed by the same infrastructure. All of the capabilities desired for end user applications apply to the central components described above, and we want to make the deployment of OpenShift benefit from those same capabilities. It should be possible to bootstrap Kubernetes on a host, then install and run OpenShift through Kubernetes to manage the infrastructure. The end goal is a 30s installation that can be extended as needed to offer more function.
OpenShift 3.x will utilize Docker containers in combination with systemd to ensure a predictable, secure, and efficient process execution environment.
Log output should be captured by journald (under systemd) and aggregated on a host. Integrators should be able to ship logs to a central point for aggregation across the cluster. Docker images should log to STDOUT/STDERR/syslog and bypass disk for common logging.
Data about the CPU, memory, disk, and network utilization of containers from Linux cGroups will be exposed to the scheduler and integrators through the Kubernetes core system, allowing the scheduler to make decisions about placement and react to changes in the infrastructure.
Applications in OpenShift 3.x will have additional options for reporting statistics to the system:
- Containers may expose a metrics polling hook in each image that can be invoked by the system to record and report structured data from a container instance
- The administrator may choose to expose a metrics endpoint into each (or some) container for ease of consumption. The type of this endpoint may be a network connection, Unix socket, or file, but in all cases the container can remain decoupled from the destination of the metrics.
A core premise of containerized software is that it should be isolated from the details of its environment - seeing the topology of the network containers communicate over and the location of remote services breaks that abstraction. At the network level, there are three tools for hiding that information - DNS (high latency service discovery via a global namespace), load balancing proxies, and network routing abstractions.
The geard project demonstrated connecting containers across hosts using network level abstractions via iptables - OpenShift 3.x will use that concept between linked containers to simplify standard development cases (my database is on localhost:3306 from my web container). These links offer a huge advantage for running containers - they can be changed without requiring restart of a process to pick up new environment variables. In addition, we expect to expose service discovery endpoints via libchan into each container to offer more dynamic reactions. Finally, environment variables that represent the connections will continue to be exposed into each container consistent with OpenShift 2.x.
DNS can map global names to specific endpoints but is more difficult to expose locally to applications. Assigning individual DNS entries to each container can be useful and should be exposed via integration hooks, but is not strictly necessary for system operation if IP addresses of containers are reasonably stable.
Finally, proxies (like the routing layer or host level proxies) can dynamically reconfigure to connect to remote endpoints, but introduce an extra hop and may bottleneck outbound traffic. With linking, proxies are less necessary, although for local load balancing links can point to a host-local load balancer as opposed to requiring a centralized load balancer (the instances a container on the host connects to can be enumerated at the time container definitions are transferred to the host).
Two additional layers of network security are possible in OpenShift 3.x for containers. First, outbound network traffic to the cluster not explicitly allowed can be blocked via iptables and network namespaces. Second, the linking abstraction allows traffic between containers to be send over a secure proxy (like stunnel), a VPN, or an IPSec configured interface. Allowing administrators more control over network configuration outside the container starts with abstraction inside the container.
The selection of volume storage on pods should be subject to some operator discretion - in particular, the following use cases should be possible for advanced users:
- I can ensure certain volumes have certain storage characteristics (high IOPs)
- I can split volumes for a container/set of containers across multiple storage devices (db log and db storage)
- I can reuse previously allocated network attached storage when a container is rescheduled
- I can access subsets of global network storage from inside a container
Integration of storage with Ceph, GlusterFS, and NFS mounts should be possible for administrators to enable, even if not all users have access to those capabilities.
We expect to broaden the set of possible integrations with OpenStack over the course of OpenShift 3.x, especially around automatic scaling of the infrastructure via HEAT.
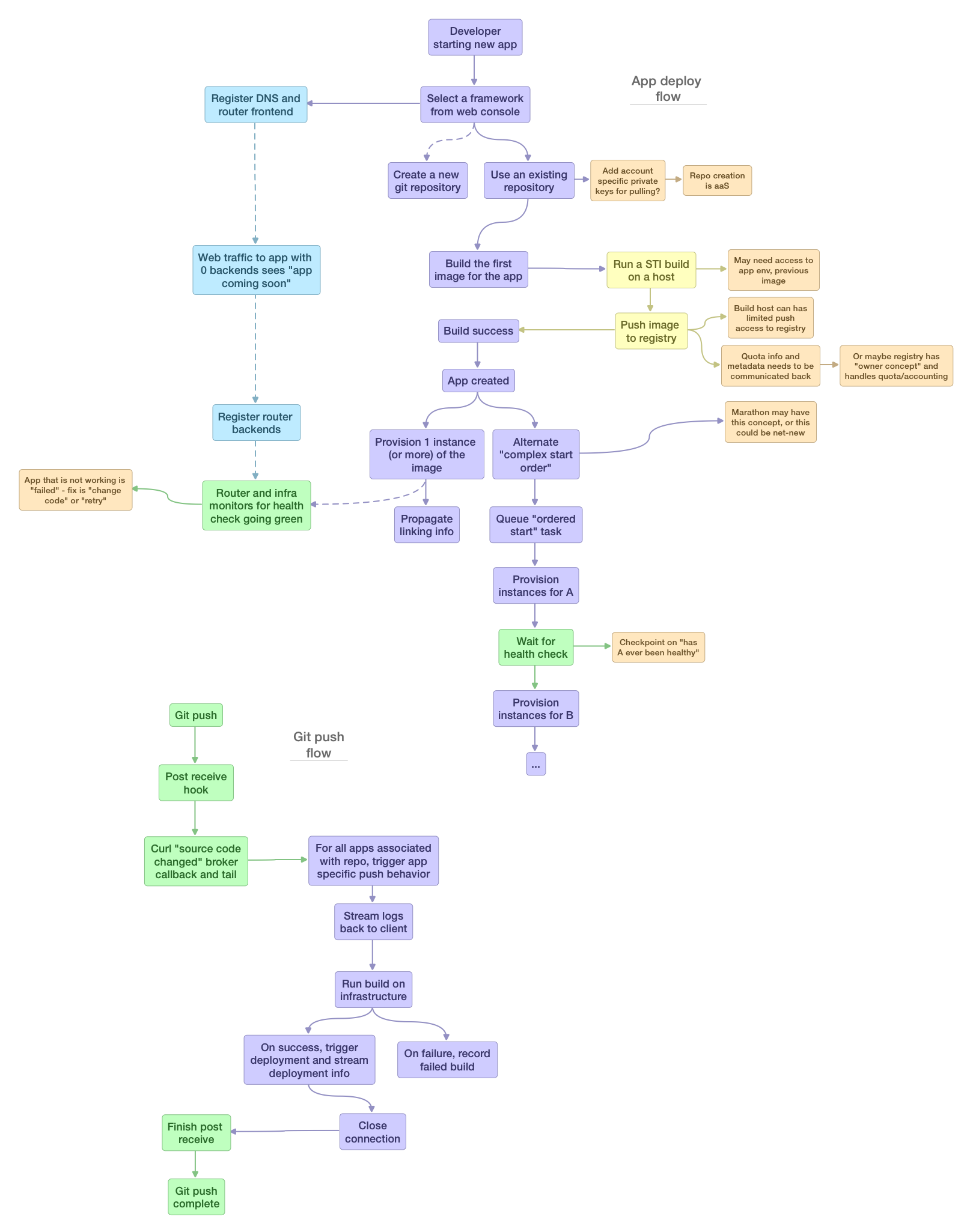
The following image shows a high level overview of the create flow in OpenShift 3.x (evolving)