各种马尔可夫子模型的关系:
| 不考虑动作 | 考虑动作 | |
|---|---|---|
| 状态完全可见 | 马尔科夫链(MC) | 马尔可夫决策过程(MDP) |
| 状态不完全可见 | 隐马尔可夫模型(HMM) | 不完全可观察马尔可夫决策过程(POMDP) |
一个马尔可夫决策过程由一个四元组构成$M = (S, A, P_{sa}, 𝑅)$ [注1]
- S: 表示状态集(states),有$s∈S$,$s_i$表示第i步的状态。
- A:表示一组动作(actions),有$a∈A$,$a_i$表示第i步的动作。
-
$𝑃_{sa}$ : 表示状态转移概率。$𝑃_{s𝑎}$ 表示的是在当前$s ∈ S$状态下,经过$a ∈ A$作用后,会转移到的其他状态的概率分布情况。比如,在状态s下执行动作$a$,转移到m的概率可以表示为$p(s'|s,a)$。 -
$R: S×A⟼ℝ$ ,R是回报函数(reward function)。有些回报函数状态$S$的函数,可以简化为$R: S⟼ℝ$。如果一组$(s,a)$转移到了下个状态$s'$,那么回报函数可记为$r(s'|s, a)$。如果$(s,a)$对应的下个状态s'是唯一的,那么回报函数也可以记为$r(s,a)$。
MDP 的动态过程如下:某个智能体(agent)的初始状态为$s_0$,然后从 A 中挑选一个动作$a_0$执行,执行后,agent 按$P_sa$概率随机转移到了下一个$s1$状态,$s1∈P_{s_0a_0}$。然后再执行一个动作$a_1$,就转移到了$s_2$,接下来再执行$a_2$…,我们可以用下面的图表示状态转移的过程。
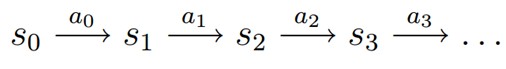
如果回报r是根据状态s和动作a得到的,则MDP还可以表示成下图:
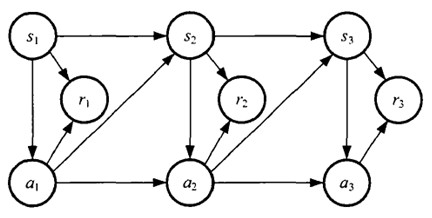
增强学习学到的是一个从环境状态到动作的映射(即行为策略),记为策略$π: S→A$。而增强学习往往又具有延迟回报的特点: 如果在第n步输掉了棋,那么只有状态$s_n$和动作$a_n$获得了立即回报$r(s_n,a_n)=-1$,前面的所有状态立即回报均为0。所以对于之前的任意状态s和动作a,立即回报函数r(s,a)无法说明策略的好坏。因而需要定义值函数(value function,又叫效用函数)来表明当前状态下策略π的长期影响。
重点看第三个式子
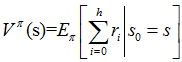

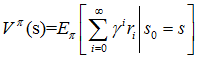
其中:
a)是采用策略π的情况下未来有限h步的期望立即回报总和;
b)是采用策略π的情况下期望的平均回报;
c)是值函数最常见的形式,式中γ∈[0,1]称为折合因子,表明了未来的回报相对于当前回报的重要程度。特别的,γ=0时,相当于只考虑立即不考虑长期回报,γ=1时,将长期回报和立即回报看得同等重要。
$$ \begin{array}{l}{V^{\pi}(\mathrm{s})=E_{\pi}\left[\mathrm{r}{0}+\gamma \mathrm{r}{1}+\gamma^{2} \mathrm{r}{2}+\gamma^{3} \mathrm{r}{3}+\ldots | s_{0}=s\right]} \ {=E_{\pi}\left[r_{0}+\gamma E\left[\gamma \mathrm{r}{1}+\gamma^{2} \mathrm{r}{2}+\gamma^{3} \mathrm{r}{3}+\ldots\right] | s{0}=s\right]} \ {=E_{\pi}\left[\mathrm{r}\left(\mathrm{s}^{\prime} | \mathrm{s}, \mathrm{a}\right)+\gamma V^{\pi}(\mathrm{s}) | s_{0}=s\right]}\end{array} $$ 给定策略π和初始状态s,则动作$a=π(s)$,下个时刻将以概率$p(s'|s,a)$转向下个状态$s'$,那么上式的期望可以拆开,可以重写为:
$$ V^{\pi}(\mathrm{s})=\sum_{s \in S} p\left(\mathrm{s}^{\prime} | \mathrm{s}, \mathrm{\pi(s)}\right)\left[\mathrm{r}\left(\mathrm{s}^{\prime} | \mathrm{s}, \mathrm{\pi(s)}\right)+\gamma \mathrm{V}^{\pi}\left(\mathrm{s}^{\prime}\right)\right] $$ **注意:**在$V^π(s)$中,π和初始状态s是我们给定的,而初始动作a是由策略π和状态s决定的,即a=π(s)。
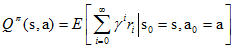
给定当前状态s和当前动作a,在未来遵循策略π,那么系统将以概率p(s'|s,a)转向下个状态s',上式可以重写为:
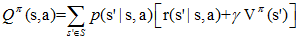
在$Q^π(s,a)$中,不仅策略π和初始状态s是我们给定的,当前的动作a也是我们给定的,这是$Q^π(s,a)$和$V^π(a)$的主要区别。
在得到值函数后,即可列出MDP的最优策略:
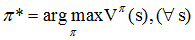
即我们的目标是寻找的是在任意初始条件s下,能够最大化值函数的策略π*。
基本的解法有三种:
- 动态规划法(dynamic programming methods)
- 蒙特卡罗方法(Monte Carlo methods)
- 时间差分法(temporal difference)
本文先介绍动态规划法求解MDP
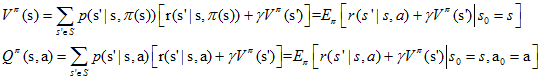
在动态规划中,上面两个式子称为贝尔曼方程,它表明了当前状态的值函数与下个状态的值函数的关系 。
优化目标$π^*$可以表示为:
$$
\pi^{}(\mathrm{s})=\arg \max _{\pi} V^{\pi}(\mathrm{s})
$$
分别记最优策略$π$对应的状态值函数和动作值函数为 $V^(s)$
状态值函数和行为值函数分别满足如下贝尔曼最优性方程(Bellman optimality equation),定义了最优解满足的条件:
$$ \begin{align*} V^{}(\mathrm{s})&=\max _{a} E\left[r\left(s^{\prime} | s, a\right)+\gamma V^{}\left(\mathrm{s}^{\prime}\right) | s_{0}=s\right] \ &=\max _{a \in A(s)} \sum p\left(\mathrm{s}^{\prime} | \mathrm{s}, \pi(\mathrm{s})\right)\left[\mathrm{r}\left(\mathrm{s}^{\prime} | \mathrm{s}, \pi(\mathrm{s})\right)+\gamma V^{\pi}\left(\mathrm{s}^{\prime}\right)\right]\end{align*} $$
$$ \begin{align*} \mathrm{Q}^{}(\mathrm{s})&=E\left[r\left(s^{\prime} | s, a\right)+\gamma \max _{a^{\prime}} Q^{}\left(s^{\prime}, \mathrm{a}^{\prime}\right) | s_{0}=s, \mathrm{a}_{0}=\mathrm{a}\right]\ &=\sum p\left(\mathrm{s}^{\prime} | \mathrm{s}, \pi(\mathrm{s})\right)\left[\mathrm{r}\left(\mathrm{s}^{\prime} | \mathrm{s}, \pi(\mathrm{s})\right)+\gamma \max _{a=A(\mathrm{s})} Q^{}\left(\mathrm{s}^{\prime}, \mathrm{a}^{\prime}\right)\right] \end{align} $$
故可知,$V^(s)$ $和$$Q^(s, a)$存在如下关系:
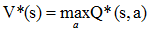
对于任意的策略π,我们如何计算其状态值函数$V^π(s)$?
确定性策略: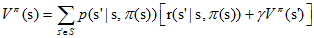
扩展到一般:如果在某策略π下,π(s)对应的动作a有多种可能,每种可能记为π(a|s),则状态值函数为
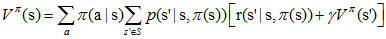
一般采用迭代的方法更新状态值函数,首先将所有$V_π(s)$的初值赋为0(其他状态也可以赋为任意值,不过吸收态必须赋0值),然后采用如下式子更新所有状态s的值函数(第k+1次迭代):
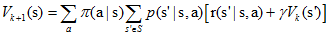
对于$V^π(s)$,有两种更新方法:
- 将第k次迭代的各状态值函数
$[V_k(s1),V_k(s2),V_k(s3), \dots]$ 保存在一个数组中,第k+1次的Vπ(s)采用第k次的$V^π(s')$来计算,并将结果保存在第二个数组中。 - 即仅用一个数组保存各状态值函数,每当得到一个新值,就将旧的值覆盖,形如$[V_{k+1}(s1),V_{k+1}(s2),V_k(s3), \dots]$,第k+1次迭代的$V^π(s)$可能用到第k+1次迭代得到的$V^π(s')$。
通常情况下,我们采用第二种方法更新数据,因为它及时利用了新值,能更快的收敛。整个策略估计算法如下图所示:

假设我们有一个策略$π$,并且确定了它的所有状态的值函数$V^π(s)$。对于某状态s,有动作$a_0=π(s)$。 那么如果我们在状态s下不采用动作$a_0$,而采用其他动作$a≠π(s)$是否会更好呢?要判断好坏就需要我们计算行为值函数$Q^π(s,a)$,公式我们前面已经说过:
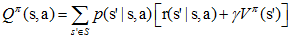
评判标准是:$Q^π(s,a)$是否大于$V^π(s)$。如果$Q^π(s,a)$>
策略改进定理(policy improvement theorem):$π$和$π'$是两个确定的策略,如果对所有状态$s∈S$有$Q^π(s,π'(s))≥V^π(s)$,那么策略π'必然比策略π更好,或者至少一样好。其中的不等式等价于$V^{π'}(s)≥V^π(s)$。
有了在某状态s上改进策略的方法和策略改进定理,我们可以遍历所有状态和所有可能的动作a,并采用贪心策略来获得新策略$π'$。即对所有的$s∈S$, 采用下式更新策略:
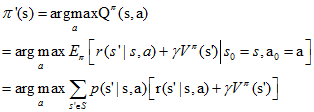
这种采用关于值函数的贪心策略获得新策略,改进旧策略的过程,称为策略改进(Policy Improvement)
贪心策略收敛:
假设策略改进过程已经收敛,即对所有的s,Vπ'(s)等于Vπ(s)。那么根据上面的策略更新的式子,可以知道对于所有的s∈S下式成立:
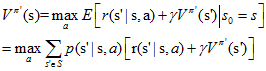
这个式子正好就是我们在1中所说的Bellman optimality equation,所以π和π'都必然是最优策略!神奇吧!
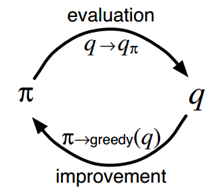
策略迭代算法就是上面两节内容的组合。假设我们有一个策略π,那么我们可以用 policy evaluation 获得它的值函数 Vπ(s),然后根据 policy improvement 得到更好的策略π',接着再计算 Vπ'(s), 再获得更好的策略π'',整个过程顺序进行如下图所示:
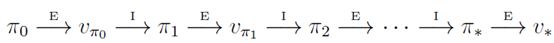
完整的算法如下图所示:

从上面我们可以看到,策略迭代算法包含了一个策略估计的过程,而策略估计则需要扫描 (sweep) 所有的状态若干次,其中巨大的计算量直接影响了策略迭代算法的效率。我们必须要获得精确的 Vπ值吗?事实上不必,有几种方法可以在保证算法收敛的情况下,缩短策略估计的过程。
值迭代(Value Iteration)就是其中非常重要的一种。它的每次迭代只扫描 (sweep) 了每个状态一次。值迭代的每次迭代对所有的 s∈S 按照下列公式更新:
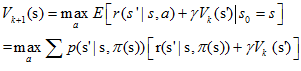
即在值迭代的第 k+1 次迭代时,直接将能获得的最大的 Vπ(s) 值赋给 Vk+1。值迭代算法直接用可能转到的下一步 s'的 V(s') 来更新当前的 V(s),算法甚至都不需要存储策略π。而实际上这种更新方式同时却改变了策略πk 和 V(s) 的估值 Vk(s)。 直到算法结束后,我们再通过 V 值来获得最优的π。
此外,值迭代还可以理解成是采用迭代的方式逼近 1 中所示的贝尔曼最优方程。
值迭代完整的算法如图所示:

由上面的算法可知,值迭代的最后一步,我们才根据 V*(s),获得最优策略π*。
一般来说值迭代和策略迭代都需要经过无数轮迭代才能精确的收敛到 V * 和π*, 而实践中,我们往往设定一个阈值来作为中止条件,即当 Vπ(s) 值改变很小时,我们就近似的认为获得了最优策略。在折扣回报的有限 MDP(discounted finite MDPs) 中,进过有限次迭代,两种算法都能收敛到最优策略π*。
至此我们了解了马尔可夫决策过程的动态规划解法,动态规划的优点在于它有很好的数学上的解释,但是动态要求一个完全已知的环境模型,这在现实中是很难做到的。另外,当状态数量较大的时候,动态规划法的效率也将是一个问题。下一篇介绍蒙特卡罗方法,它的优点在于不需要完整的环境模型。
参考资料:
[1] R.Sutton et al. Reinforcement learning: An introduction , 1998
[2] 徐昕,增强学习及其在移动机器人导航与控制中的应用研究[D],2002
蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法。该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基础的方法。
一个简单的例子可以解释蒙特卡罗方法,假设我们需要计算一个不规则图形的面积,那么图形的不规则程度和分析性计算(比如积分)的复杂程度是成正比的。而采用蒙特卡罗方法是怎么计算的呢?首先你把图形放到一个已知面积的方框内,然后假想你有一些豆子,把豆子均匀地朝这个方框内撒,散好后数这个图形之中有多少颗豆子,再根据图形内外豆子的比例来计算面积。当你的豆子越小,撒的越多的时候,结果就越精确。
现在我们开始讲解增强学习中的蒙特卡罗方法,与上篇的 DP 不同的是,这里不需要对环境的完整知识。蒙特卡罗方法仅仅需要经验就可以求解最优策略,这些经验可以在线获得或者根据某种模拟机制获得。
要注意的是,我们仅将蒙特卡罗方法定义在 episode task 上,所谓的 episode task 就是指不管采取哪种策略π,都会在有限时间内到达终止状态并获得回报的任务。比如玩棋类游戏,在有限步数以后总能达到输赢或者平局的结果并获得相应回报。
那么什么是经验呢?经验其实就是训练样本。比如在初始状态 s,遵循策略π,最终获得了总回报 R,这就是一个样本。如果我们有许多这样的样本,就可以估计在状态 s 下,遵循策略π的期望回报,也就是状态值函数 Vπ(s) 了。蒙特卡罗方法就是依靠样本的平均回报来解决增强学习问题的。
尽管蒙特卡罗方法和动态规划方法存在诸多不同,但是蒙特卡罗方法借鉴了很多动态规划中的思想。在动态规划中我们首先进行策略估计,计算特定策略π对应的 Vπ和 Qπ,然后进行策略改进,最终形成策略迭代。这些想法同样在蒙特卡罗方法中应用。
首先考虑用蒙特卡罗方法来学习状态值函数 Vπ(s)。如上所述,估计 Vπ(s) 的一个明显的方法是对于所有到达过该状态的回报取平均值。这里又分为 first-visit MC methods 和 every-visit MC methods。这里,我们只考虑 first MC methods,即在一个 episode 内,我们只记录 s 的第一次访问,并对它取平均回报。
现在我们假设有如下一些样本,取折扣因子γ=1,即直接计算累积回报,则有
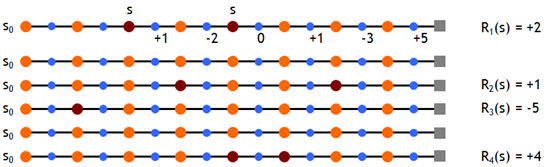
根据 first MC methods,对出现过状态 s 的 episode 的累积回报取均值,有 Vπ(s)≈ (2 + 1 – 5 + 4)/4 = 0.5
容易知道,当我们经过无穷多的 episode 后,Vπ(s) 的估计值将收敛于其真实值。
在状态转移概率 p(s'|a,s) 已知的情况下,策略估计后有了新的值函数,我们就可以进行策略改进了,只需要看哪个动作能获得最大的期望累积回报就可以。然而在没有准确的状态转移概率的情况下这是不可行的。为此,我们需要估计动作值函数 Qπ(s,a)。Qπ(s,a) 的估计方法前面类似,即在状态 s 下采用动作 a,后续遵循策略π获得的期望累积回报即为 Qπ(s,a),依然用平均回报来估计它。有了 Q 值,就可以进行策略改进了

下面我们来探讨一下 Maintaining Exploration 的问题。前面我们讲到,我们通过一些样本来估计 Q 和 V,并且在未来执行估值最大的动作。这里就存在一个问题,假设在某个确定状态 s0 下,能执行 a0, a1, a2 这三个动作,如果智能体已经估计了两个 Q 函数值,如 Q(s0,a0), Q(s0,a1),且 Q(s0,a0)>Q(s0,a1),那么它在未来将只会执行一个确定的动作 a0。这样我们就无法更新 Q(s0,a1) 的估值和获得 Q(s0,a2) 的估值了。这样的后果是,我们无法保证 Q(s0,a0) 就是 s0 下最大的 Q 函数。
Maintaining Exploration 的思想很简单,就是用 soft policies 来替换确定性策略,使所有的动作都有可能被执行。比如其中的一种方法是ε-greedy policy,即在所有的状态下,用 1-ε的概率来执行当前的最优动作 a0,ε的概率来执行其他动作 a1, a2。这样我们就可以获得所有动作的估计值,然后通过慢慢减少ε值,最终使算法收敛,并得到最优策略。简单起见,在下面 MC 控制中,我们使用 exploring start,即仅在第一步令所有的 a 都有一个非零的概率被选中。
我们看下 MC 版本的策略迭代过程:
根据前面的说法,值函数 Qπ(s,a) 的估计值需要在无穷多 episode 后才能收敛到其真实值。这样的话策略迭代必然是低效的。在上一篇 DP 中,我们介绍了值迭代算法,即每次都不用完整的策略估计,而仅仅使用值函数的近似值进行迭代,这里也用到了类似的思想。每次策略的近似值,然后用这个近似值来更新得到一个近似的策略,并最终收敛到最优策略。这个思想称为广义策略迭代。
具体到 MC control,就是在每个 episode 后都重新估计下动作值函数(尽管不是真实值),然后根据近似的动作值函数,进行策略更新。这是一个 episode by episode 的过程。
一个采用 exploring starts 的 Monte Carlo control 算法,如下图所示,称为 Monte Carlo ES。而对于所有状态都采用 soft policy 的版本,这里不再讨论。

Monte Carlo 方法的一个显而易见的好处就是我们不需要环境模型了,可以从经验中直接学到策略。它的另一个好处是,它对所有状态 s 的估计都是独立的,而不依赖与其他状态的值函数。在很多时候,我们不需要对所有状态值进行估计,这种情况下蒙特卡罗方法就十分适用。
不过,现在增强学习中,直接使用 MC 方法的情况比较少,而较多的采用 TD 算法族。但是如同 DP 一样,MC 方法也是增强学习的基础之一,因此依然有学习的必要。
参考资料:
[1] R.Sutton et al. Reinforcement learning: An introduction, 1998
[2] Wikipedia,蒙特卡罗方法
接下来我们回顾一下动态规划算法(DP)和蒙特卡罗方法(MC)的特点,对于动态规划算法有如下特性:
-
需要环境模型,即状态转移概率
$P_{sa}$ -
状态值函数的估计是自举的(bootstrapping),即当前状态值函数的更新依赖于已知的其他状态值函数。
相对的,蒙特卡罗方法的特点则有:
- 可以从经验中学习不需要环境模型
- 状态值函数的估计是相互独立的
- 只能用于episode tasks
而我们希望的算法是这样的:
- 不需要环境模型
- 它不局限于episode task,可以用于连续的任务
本文介绍的时间差分学习(Temporal-Difference learning, TD learning)正是具备了上述特性的算法,它结合了DP和MC,并兼具两种算法的优点。
在介绍TD learning之前,我们先引入如下简单的蒙特卡罗算法,我们称为
constant-α MC,它的状态值函数更新公式如下:
$$
V\left(s_{t}\right) \leftarrow V\left(s_{t}\right)+\alpha\left[R_{t}-V\left(s_{t}\right)\right]
$$
其中
这个式子的直观的理解就是, 用实际累积回报
现在我们将公式修改如下,把
那么MC和TD(0)的更新公式的有何不同呢?我们举个例子,假设有以下8个episode, 其中A-0表示经过状态A后获得了回报0:
| index | samples |
|---|---|
| episode 1 | A-0, B-0 |
| episode 2 | B-1 |
| episode 3 | B-1 |
| episode 4 | B-1 |
| episode 5 | B-1 |
| episode 6 | B-1 |
| episode 7 | B-1 |
| episode 8 | B-0 |
首先我们使用constant-α MC方法估计状态A的值函数,其结果是
现在我们使用TD(0)的更新公式,简单起见取
-
首先,状态B的值函数是容易求得的,B作为终止状态,获得回报1的概率是75%,因此
$V(B)=0.75$ 。 -
接着从数据中我们可以得到状态A转移到状态B的概率是100%并且获得的回报为0。根据公式(9)可以得到
可见在只有
将式(2)作为状态值函数的估计公式后,前面文章中介绍的策略估计算法就变成了如下形式,这个算法称为TD prediction:

-
-
不理解环境(Model-free RL)
Q Learning、Sarsa、Policy Gradients
-
理解环境(Model-Based RL)
相较于Model-free,Model-Based可以构建虚拟环境,并且可以想象
-
-
- 基于概率(Policy-Based RL):输出的是概率,不一定选择最高概率的,适用于连续动作:Policy Gradients
- 基于价值(Value-Based RL):输出的是价值,一定选择价值最高的动作:QLearning、Sarsa
- Actor-Critic:Actor基于概率做出动作,Critic再基于价值给出动作的价值
-
-
回合更新(Monte-Carlo update):游戏结束更新
基础版Policy Gradients
-
单步更新(Temporal-Difference update):游戏进行的每一步都可以更新
Q Learning、Sarsa、升级版Policy Gradients
-
-
-
在线学习(On-Policy)
Sarsa、Sarsa(
$\lambda$ ) -
离线学习(Off-Policy)
Q Learning、DQN
-
根据$Q$表对下一时刻的动作进行选择,下图是$Q$表的更新方式

此时,$S_2$并未进行下一次的动作,而是预估了一下后果,由此来更新$S_1$的$Q$表。

其中,$\alpha$是学习速率,$\epsilon$是选择$Q$表最大值的概率。若$\epsilon=90%$,则$90%$概率选择$Q$表最大值即最优动作,$10%$的概率随机动作。
由于$Q(s',a')$是下一次的动作,会通过乘以奖励衰减值
- Q估计:$s_1$状态最优动作$a$的Q值
- Q现实:在选择了动作$a$后,进入
$s'$ 状态。Q表中$s'$ 状态对应的Q值的最大值加上执行动作$a$之后得到的奖励值$r$,即 - 为Q现实。
- 决策部分与Q Learning一样
- 区别在于Q表的更新方式:
- Q Learning并没有实际进行下一次的动作,会选择有危险的动作,因此是离线学习;
- Sarsa是实践派,进行了实际的下一步动作,会避免选择有危险的动作,因此是在线学习;

-
不仅更新离奖励最近的一步,还更新来时沿途的每一步
Sarsa 是一种单步更新法, 在环境中每走一步, 更新一次自己的行为准则, 我们可以在这样的 Sarsa 后面打一个括号, 说他是 Sarsa(0), 因为他等走完这一步以后直接更新行为准则. 如果延续这种想法, 走完这步, 再走一步, 然后再更新, 我们可以叫他 Sarsa(1). 同理, 如果等待回合完毕我们一次性再更新呢, 比如这回合我们走了 n 步, 那我们就叫 Sarsa(n). 为了统一这样的流程, 我们就有了一个
$\lambda$ 值来代替我们想要选择的步数, 这也就是 Sarsa($\lambda$ ) 的由来. -
更新沿途存在的问题:会记录不必要的重复步骤,因此需要Sarsa(
$\lambda$ ) -
$\lambda$ 的含义:$\lambda$ 是一个衰变值,在$0-1$之间,离奖励越远的步对到达奖励的影响越小,衰减越大;反之,离奖励越近的步对奖励的影响越大,衰减较小。
-
算法:


- 抛弃Q表这种Q值记录方式,使用神经网络生成Q值,在状态较多的情况下格外有效率

-
- Q估计:通过NN预测出的$Q(s_2, a_1), Q(s_2,a_2)$的最大值
- Q现实:Q 估计中最大值的动作来换取环境中的奖励 reward+$\gamma*$下一步$s'$中通过NN预测出的$Q(s‘, a_1), Q(s',a_2)$的最大值
-
DQN两大利器:
- Experience replay: 作为一种离线学习,每次 DQN 更新的时候,我们都可以随机抽取一些之前的经历进行学习。随机抽取这种做法打乱了经历之间的相关性,也使得神经网络更新更有效率。
- Fixed Q-target: 在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计的神经网络具备最新的参数, 而预测 Q 现实的神经网络使用的参数则是很久以前的.
-
算法:

- 记忆库 (用于重复学习)
- 神经网络计算 Q 值
- 暂时冻结
q_target参数 (切断相关性)
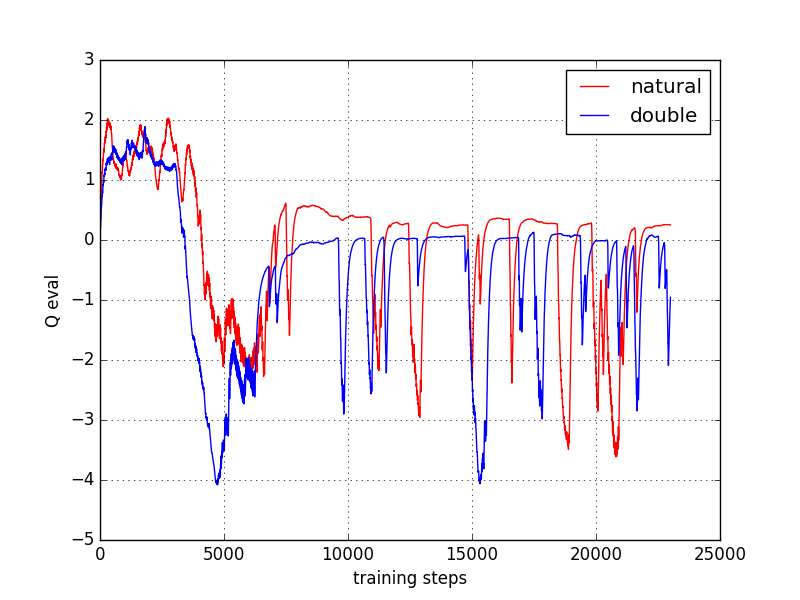
因为我们的神经网络预测 Qmax 本来就有误差, 每次也向着最大误差的 Q现实 改进神经网络, 就是因为这个 Qmax 导致了 overestimate. 所以 Double DQN 的想法就是引入另一个神经网络来打消一些最大误差的影响. 而 DQN 中本来就有两个神经网络, 我们何不利用一下这个地理优势呢. 所以, 我们用 Q估计 的神经网络估计 Q现实 中 Qmax(s', a') 的最大动作值. 然后用这个被Q估计 估计出来的动作来选择 Q现实 中的 Q(s'). 总结一下:
有两个神经网络: Q_eval (Q估计中的), Q_next (Q现实中的).
原本的 Q_next = max(Q_next(s', a_all)).
Double DQN 中的 Q_next = Q_next(s', argmax(Q_eval(s', a_all))). 也可以表达成下面那样.
对比原始和Double的cost曲线:
Policy gradient输出不是 action 的 value, 而是具体的那一个 action, 这样 policy gradient 就跳过了 value 这个阶段.
优势:输出的这个 action 可以是一个连续值, 之前我们说到的 value-based 方法输出的都是不连续的值, 然后再选择值最大的 action. 而 policy gradient 可以在一个连续分布上选取 action.
一种基于整条回合数据的更新
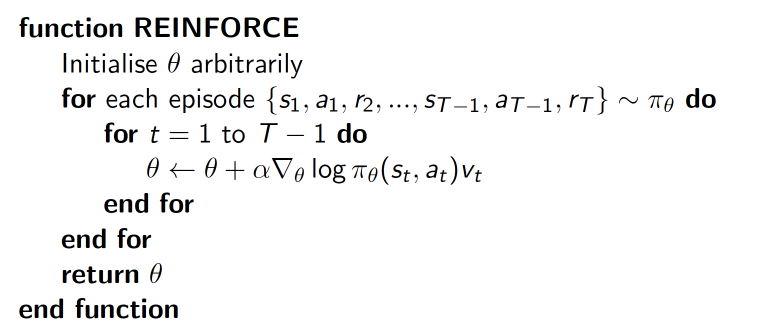
其中,$\nabla log \pi_{\theta}(s_t,a_t)v_t$表示在状态 -log(P)) 反而越大. 如果在 Policy(s,a) 很小的情况下, 拿到了一个 大的 R, 也就是大的 V, 那$\nabla log \pi_{\theta}(s_t,a_t)v_t$ 就更大, 表示更吃惊, (我选了一个不常选的动作, 却发现原来它能得到了一个好的 reward, 那我就得对我这次的参数进行一个大幅修改). 这就是吃惊度的物理意义。
结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法. Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率,输入的单次奖赏变成了critic输出的总奖赏增量td-error。critic建立s-Q的网络,然后根据[s, r, s_]来训练,并返回td-error。
**优势:**可以进行单步更新, 比传统的 Policy Gradient 要快.
**劣势:**取决于 Critic 的价值判断, 但是 Critic 难收敛, 再加上 Actor 的更新, 就更难收敛. 为了解决收敛问题, Google Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient. 后者融合了 DQN 的优势, 解决了收敛难的问题.
DDPG 结合了之前获得成功的 DQN 结构, 提高了 Actor Critic 的稳定性和收敛性。为了体现DQN的思想,每种神经网络都需要再细分为两个,
- Actor有估计网络和现实网络,估计网络用来输出实时的动作, 供actor在现实中实行。而现实网络则是用来更新价值网络系统的。
- Critic这边也有现实网络和估计网络,他们都在输出这个状态的价值,而输入端却有不同,状态现实网络这边会拿着从动作现实网络来的动作加上状态的观测值加以分析,而状态估计网络则是拿着当时Actor施加的动作当作输入。

Paper: IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures

IMPALA架构使用Learner代替传统Actor,而这里的Actors相当于A3C中的agents,用于并行探索。然而A3C-based agents向中央server传输策略参数的梯度信息,IMPALA的Actors则是向中央learner通信经验轨迹(trajectories of experience)。由于IMPALA的learner可以获得全部的经验轨迹,因此可以实现非常高的数据吞吐量。但由于生成经验轨迹的策略会滞后于learner的策略,因此IMPALA成为了off-policy算法。IMPALA使用V-trace off-policy actor-critic算法来修正这种不一致。

(a)和(b)揭示了A2C存在GPU利用率低的问题,而IMPALA将探索和学习分开,由多个Actors在多个env中探索,再由中央learner学习,实现了GPU的高效利用
传统RL问题的目标是寻找一个策略
Off-policy 的RL算法是用由策略
Consider a trajectory $\left(x_{t}, a_{t}, r_{t}\right){t=s}^{t=s+n}$ generated by the actor following some policy $\mu$ . We define the n-steps V-trace target for $V(x_s)$, our value approximation at state $x_s$, as:
$$
v{s} \stackrel{\mathrm{def}}{=} V\left(x_{s}\right)+\sum_{t=s}^{s+n-1} \gamma^{t-s}\left(\prod_{i=s}^{t-1} c_{i}\right) \delta_{t} V
$$
其中,$\delta_{t} V \stackrel{\mathrm{def}}{=} \rho_{t}\left(r_{t}+\gamma V\left(x_{t+1}\right)-V\left(x_{t}\right)\right)$是
Remark 1. V-trace targets can be computed recursively: $$ v_{s}=V\left(x_{s}\right)+\delta_{s} V+\gamma c_{s}\left(v_{s+1}-V\left(x_{s+1}\right)\right) $$
V值参数
策略参数
本篇文章提出了基于DPG(deterministic policy gradient)和DQN的DDPG算法。成功地将DQN应用到连续动作域,并且这是一种基于DPG的Actor-Critic、无模型算法。DDPG是一种端到端的算法,可以直接从原始输入数据映射到输出数据。A long-standing challenge of robotic control is to learn an action policy directly from raw sensory input such as video.
DQN缺点:
DQN是可以解决的问题一般要具有高维观测空间,并且其动作空间是低维且离散的。
DQN优势:
- 网络是从replay buffer中离线的学习到的,这样就减小了数据间的相关性;
- 该网络使用target-Q网络进行训练,以便在时间差异备份期间提供一致的目标。
DDPG优势:
可以在保持超参数和网络结构不变的情况下,从低维观测空间中鲁棒地学习到策略。

-
Action-value function:
$$ Q^π(s_t, a_t) = E_{r_{i≥t},s_{i>t}∼E,a_{i>t}∼π} [R_t|s_t, a_t] $$
表示在状态
$s_t$ 选择了动作$a_t$ 的期望返回值,并且在此之后策略服从$\pi$ 。 -
贝尔曼方程中体现了状态之间的递归关系
$$ Q^π(s_t, a_t) = E_{r_t,s_{t+1}∼E} [r(s_t, a_t) + γ E_{a_t+1∼π} [Q^π(s_{t+1}, a_{t+1})]] $$
-
如果策略是确定的,可用
$\mu : S ← A$ 来表示策略,并且这样就省去了求$n+1$ 次期望的过程 $$ Q^µ(s_t, a_t) = E_{r_t,s_{t+1}∼E} [r(s_t, a_t) + γQ^µ(s_{t+1}, µ(s_{t+1}))] $$ 这样期望就只和环境有关,意味着可以通过迁移学习的方式从另一个随机策略$\beta$ 中离线学习到$Q^{\mu}$ . Q-Leaning是一种经典离线学习算法,使用的是贪婪策略$\mu(s)=\arg \max_aQ(s,a)$ -
DPG:The DPG algorithm maintains a parameterized actor function µ(s|θµ) which specifies the current policy by deterministically mapping states to a specific action. The critic Q(s, a) is learned using the Bellman equation as in Q-learning. The actor is updated by following the applying the chain rule to the expected return from the start distribution J with respect to the actor parameters: $$ \begin{align*} ∇_{θ^µ}J &≈ E_{s_t∼ρ^β} [∇_{θ^µ}Q(s, a|θ^Q)|{s=s_t,a=µ(s_t|θ^µ)}]\ &= E{s_t∼ρ^β}[ ∇_aQ(s, a|θ^Q)|{s=st,a=µ(s_t)}∇{θ^µ} µ(s|θ^µ)|_{s=st}] \end{align*} $$
对于Q-Learning这样的算法来说,非线性函数逼近是不能保证收敛性的,因此借鉴DQN用神经网络来在线逼近函数的成功案例,开发了DDPG。
One challenge when using neural networks for reinforcement learning is that most optimization algorithms assume that the samples are independently and identically distributed(IID). Additionally, to make efficient use of hardware optimizations, it is essential to learn in mini- batches, rather than online.
-
Problem 1 发散:
Since the network
$Q(s, a|θ^Q)$ being updated is also used in calculating the target value (equation 5), the Q update is prone to divergence. We create a copy of the actor and critic networks,$Q‘(s, a|θ^{Q’})$ and$µ'(s|θ^{µ'})$ respectively, that are used for calculating the target values. This means that the target values are constrained to change slowly, greatly improving the stability of learning. 即使延迟更新导致了学习速度慢,但是它所带来的稳定性更加重要。 -
Problem 2 输入量范围不一致:
Using batch normalization (Ioffe & Szegedy, 2015). This technique normalizes each dimension across the samples in a minibatch to have unit mean and variance. In addition, it maintains a run- ning average of the mean and variance to use for normalization during testing.
-
Problem 3 探索:
DDPG这样的离线学习算法的好处在于,可以将探索独立于学习算法之外。我们定义一个包含噪声的动作策略: $$ \mu'(s_t)=\mu(s_t|\theta_t^{\mu})+\mathcal{N} $$ 利用Ornstein-Uhlenbeck过程来生成惯性物理系统的探索
Trust region policy optimization (TRPO) (Schulman et al., 2015b), directly constructs stochastic neural network policies without decomposing problems into optimal control and supervised phases. 经过精准的调参,该方法可以近乎单调的更新,并且不需要计算动作值函数,可能因此导致数据效率下降。
**Guided policy search (GPS) ** algorithms (e.g., (Levine et al., 2015)) decomposes the problem (Actor-Critic存在的问题) into three phases that are rela- tively easy to solve:
- First, it uses full-state observations to create locally-linear approximations of the dynamics around one or more nominal trajectories,
- Then uses optimal control to find the locally-linear optimal policy along these trajectories;
- Finally, it uses supervised learning to train a complex, non-linear policy (e.g. a deep neural network) to reproduce the state-to-action mapping of the optimized trajectories.
PILCO (Deisenroth & Rasmussen, 2011) uses Gaussian processes to learn a non-parametric, probabilistic model of the dynamics. 但是在高维问题上不切实际。不过深度函数逼近看起来是将强化学习应用到大型的、高维问题上的最好办法。
还可以使用压缩权重或无监督学习的方法来从像素中学习策略(Koutn´ık et al., 2014) (两篇)
需要大量的训练步数才能找到解决方案。