(You might also be interested in our follow-up work: https://github.com/mmalekzadeh/vicious-classifiers)
Official Paper: https://dl.acm.org/doi/10.1145/3460120.3484533
ArXiv Version: https://arxiv.org/abs/2105.12049
Title: Honest-but-Curious Nets: Sensitive Attributes of Private Inputs Can Be Secretly Coded into the Classifiers' Outputs (ACM SIGSAC Conference on Computer and Communications Security (CCS '21), November 15–19, 2021.)
Slides: https://github.com/mmalekzadeh/honest-but-curious-nets/blob/main/HBC_Nets_Slides.pdf
Presentation Video: https://www.youtube.com/watch?v=G35467ddItk
Abstract:
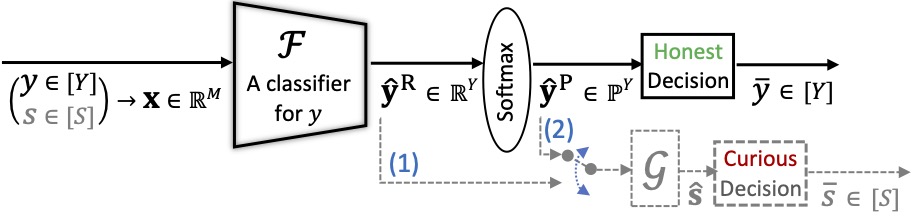
It is known that deep neural networks, trained for the classification of a non-sensitive target attribute, can reveal somesensitive attributes of their input data; through features of different granularity extracted by the classifier. We take a step forward and show that deep classifiers can be trained to secretly encode a sensitive attribute of users' input data into the classifier's outputs for the target attribute, at inference time. This results in an attack that works even if users have a full white-box view of the classifier, and can keep all internal representations hidden except for the classifier's outputs for the target attribute. We introduce an information-theoretical formulation of such attacks and present efficient empirical implementations for training honest-but-curious (HBC) classifiers based on this formulation: classifiers that can be accurate in predicting their target attribute, but can also exploit their outputs to secretly encode a sensitive attribute. Our evaluations on several tasks in real-world datasets show that a semi-trusted server can build a classifier that is not only perfectly honest but also accurately curious. Our work highlights a vulnerability that can be exploited by malicious machine learning service providers to attack their user's privacy in several seemingly safe scenarios; such as encrypted inferences, computations at the edge, or private knowledge distillation. We conclude by showing the difficulties in distinguishing between standard and HBC classifiers, discussing challenges in defending againstthis vulnerability of deep classifiers, and enumerating related open directions for future studies.
- Download the
Aligned&Cropped Facesfrom this link: https://susanqq.github.io/UTKFace/ (It is currently hosted here: https://drive.google.com/drive/folders/0BxYys69jI14kU0I1YUQyY1ZDRUE). - Unzip the file
UTKFace.tar.gzin the directoryhbcnets/data/, so you will have a folder named "UTKFace" (i.e.hbcnets/data/UTKFace) that includes JPEG images. - For the first time, you need to edit
hbcnets/constants.pyand setDATA_PREPROCESSING = 1. With this,main.pyprocesses images and creates a.npzfile for you. After that, you have to setDATA_PREPROCESSING = 0for all the next runs, unless you changeIMAGE_SIZEinhbcnets/constants.py.
- Download the
Align&Cropped Imagesfrom this link: http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html (It is currently hosted here: https://drive.google.com/drive/folders/0B7EVK8r0v71pWEZsZE9oNnFzTm8). - Create a folder named
celebain the directoryhbcnets/data/. - Unzip the file
img_align_celeba.zipin the folderceleba, so you will havehbcnets/data/celeba/img_align_celebathat includes JPEG images. - Download the folloowing files from the above link and put them in the folder
celeba(besides folderimg_align_celeba).- list_eval_partition.txt
- list_attr_celeba.txt
- identity_CelebA.txt
- For the first time, you need to edit
hbcnets/constants.pyand setDATA_PREPROCESSING = 1. With this,main.pyprocesses images and creates a.npzfile for you. After that, you have to setDATA_PREPROCESSING = 0for all the next runs, unless you changeIMAGE_SIZEinhbcnets/constants.py.
This code is tested on Pytorch V 1.9.1 (use
!pip install torch==1.9.1)
All you need is to run
> python main.py
But before that, it will be much helpful if you:
- Make sure you have read the paper once :-)
- Open
hbcnets/constants.pyand set up the desired setting. There are multiple parameters that you can play with (see below). - Use the arguments in
setting.pyfor running your desired experiments.
** If you like to use Google Colab, please look at this notebook: Colab_Version_of_Main.ipynb
https://github.com/mmalekzadeh/honest-but-curious-nets/blob/main/Colab_Version_of_Main.ipynb
In hbcnets/constants.py you can find the following parameterts:
-
DATASET: You can chooseutk_faceorceleba. -
HONEST: This is thetargetattribut (i.e.,y) in the paper. Use this to set your desired attribute. -
K_Y: After settingHONEST, you need to set the size of possible values. This isYin the paper. -
CURIOUS: This is thesensitiveattribut (i.e.,s) in the paper. Use this to set your desired attribute. -
K_S: After settingCURIOUS, you need to set the size of possible values. This isSin the paper. -
BETA_X,BETA_Y,BETA_S: These are trade-off hyper-parameteres with the same name in the paper. -
SOFTMAX: This allow us to decided whtehre we want to release thesoftoutputs (True) or therawoutputs (False). -
RANDOM_SEED: You can use this alongside these lines inmain.pyto keep your results reproducible. -
DATA_PREPROCESSING: When using a dataset for the first time, you need to set this to 1, after that it can be 0 to save time. -
IMAGE_SIZE: The default is 64 (i.e., 64x64), but you can change this to get other resolutions. Notice that if you change this, you need to setDATA_PREPROCESSING=1for the first time.
Please use:
@inproceedings{malekzadeh2021honest,
author = {Malekzadeh, Mohammad and Borovykh, Anastasia and G\"{u}nd\"{u}z, Deniz},
title = {Honest-but-Curious Nets: Sensitive Attributes of Private Inputs Can Be Secretly Coded into the Classifiers' Outputs},
year = {2021},
publisher = {Association for Computing Machinery},
doi = {10.1145/3460120.3484533},
booktitle = {Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security},
pages = {825–844},
numpages = {20},
series = {CCS '21}
}