在发布Stable Diffusion 3之后,StabilityAI最近终于放出了SD3的技术报告,相比SD之前的版本,SD3有比较大的改进。
- 首先,SD3是一个基于Rectified Flow的生成模型;
- 其次,SD3引入了T5-XXL来作为text encoder来提升模型的文本理解能力;
- 最后,SD3采用了一个多模态的DiT架构,并且将模型参数量扩展为8B。
从目前给出的例子和评测上,SD3在文字渲染和对文本提示词的遵循上,已经达到甚至超过目前STOA的文生图模型如DALL·E 3、Midjourney v6和Ideogram v1。这篇文章将根据SD3的论文分析SD3的具体实现细节。

SD3相比之前的SD一个最大的变化是采用Rectified Flow来作为生成模型,Rectified Flow在Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow被首先提出,但其实也有同期的工作比如Flow Matching for Generative Modeling提出了类似的想法。
这里和SD3的论文一样,首先将基于Flow Matching来介绍RF,然后再介绍SD3在RF上的具体改进。
Flow Matching(FM)是建立在continuous normalizing flows的基础上,这里将生成模型定义为一个常微分方程(ODE):
这里的
接下来,我们来看一个新的优化目标,那就是Conditional Flow Matching (CFM)目标:
这里的条件向量场
换句话说,使用CFM目标来训练
进一步根据前向过程我们有:
我们将上式代入CFM目标中,就可以得到:
这里我们对
代入CFM优化目标可得到:
此时相当于神经网络变成了预测噪音,这和扩散模型DDPM预测噪音是一样的,但是优化目标的多了一个和
不同的生成模型所采用的优化目标不同,等价于采用不同的权重
在FM中,作者给出了一个基于最优传输( Optimal Transport)具体的前向过程:
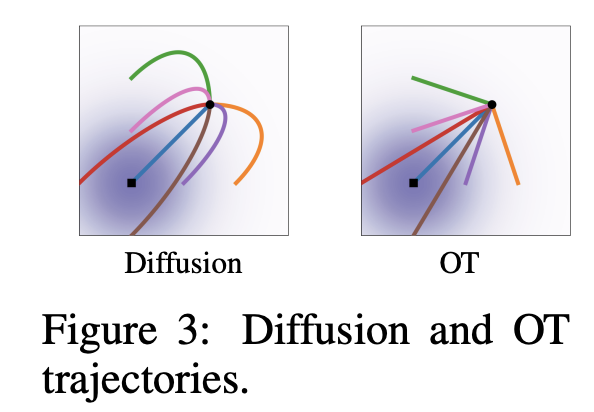
对于RF,有
可以看到,最终RF的损失函数是非常简单的。如果将RF转成
SD3论文中除了实验RF模型外,还对其它模型做了对比实验,这里也需要简单介绍一下。
首先是之前版本的SD所采用的(LDM-)Linear,LDM是基于DDPM,但和DDPM采用了不同的noise schedule。DDPM是基于离散时间
除了线性noise schedule,I-DDPM还提出了cosine noise schedule,其前向过程可以定义为(采用连续时间):
除了此外,SD3还实验了EDM,但这里我们不再展开了。
这里所说的采样是指的训练过程对时间步
下面我们介绍一下SD3论文中所实验的几种采样方法。
- Logit-Normal Sampling
- Mode Sampling with Heavy Tails
- CosMap
第一个采样方法是Logit-Normal Sampling,这是采用Logit-Normal分布,所谓的Logit-Normal分布是指变量的logit满足正态分布,对于Logit-Normal分布,其概率密度为:
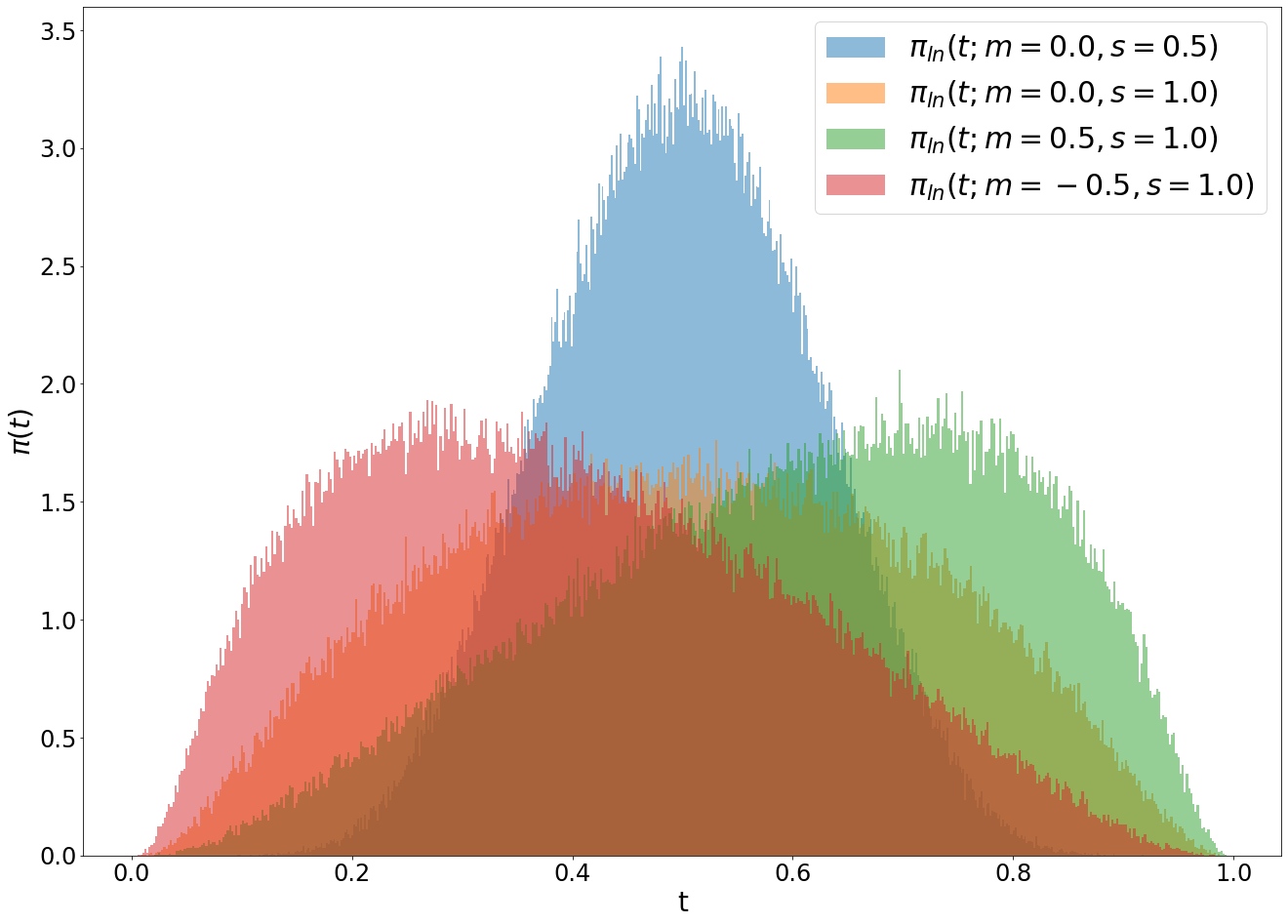
在采样过程中,我们可以先基于正态分布
第二个采样方法是Mode Sampling with Heavy Tails。Logit-Normal分布的一个问题是两边
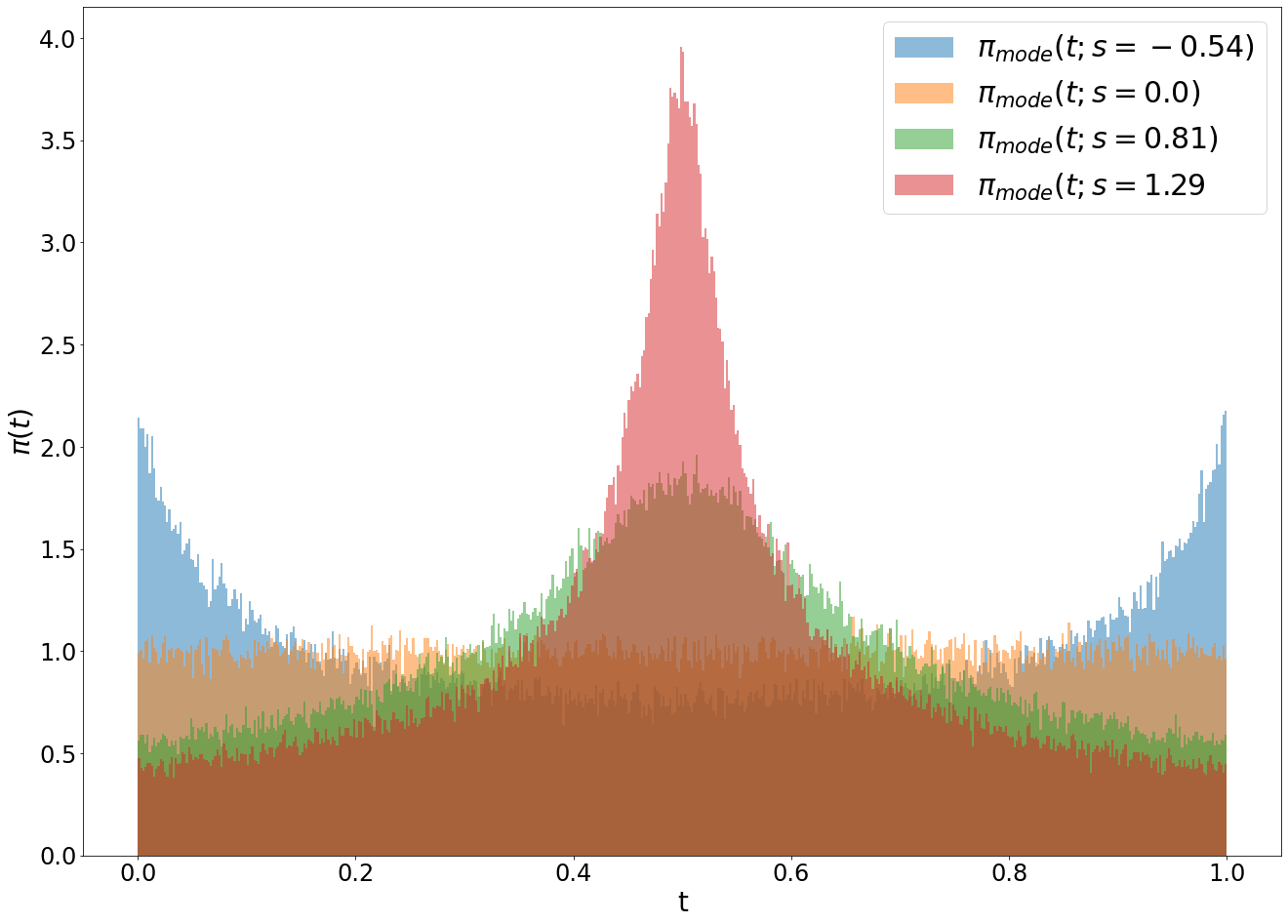
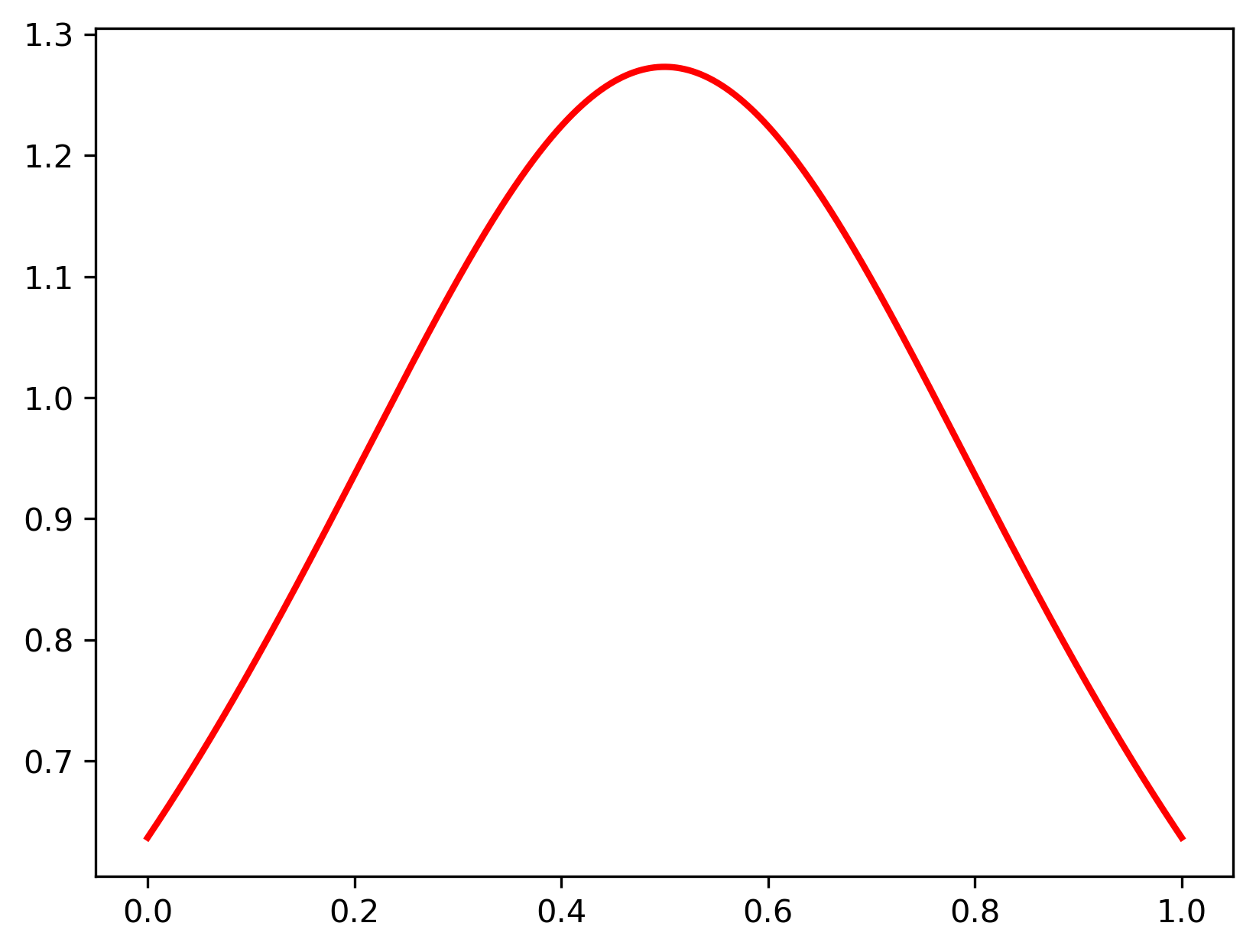
最后一个采样方法是CosMap。这里其实是想实现下RF下的cosine schedule ,我们可以求解一个映射
这里我们可以画出这个分布,如下所示,它也是中间概率密度高:
为了验证RF是否在文生图上是有效的,SD3论文中做了一系列的对比实验,实验的模型共包括61个,分别是:
- 采用
$\epsilon $ 和$v $ 优化目标,同时noise schedule采用linear和cosine,这共4个配置:eps/linear,v/linear,eps/cos,v/cos,其中eps/linear就是LDM所采用的配置。 - 采用RF和
$\pi_{\text{mode}}(t;s) $ ,这里记为rf/mode(s),其中其中$s $ 在−1~1.75之间均匀选取7个值,另外还包含一个$s=0 $ 的配置,这其实就是原来的RF。所以这组总共8个配置。 - 采用RF和
$\pi_{\text{ln}}(t;m,s) $ ,这里记为rf/lognorm(m, s),其中在$m\sim[-1,1] $ 和$s\sim[0.2,2.2] $ 以网格方式选择30组$(m,s) $ 。 - 采用RF和
$\pi_{\text{CosMap}}(t) $ ,这里记为rf/cosmap。 - 采用EDM,记为
$edm(P_{m}, P_{s}) $ ,这两个参数决定EDM的SNR,其中在$P_{m}\sim [-1.2,1.2] $ 和$P_{s}\sim [0.6,1.8] $ 均匀选择15组。 - 采用EDM,但是schedule分别设置为
edm和rf与v/cos的log-SNR加权匹配,这两个配置分别记为$rf(edm/rf) $ 和$v/cos(edm/cos) $ 。
每个模型的实验配置如下:
- 训练数据集:ImageNet和CC12M两个数据集,其中ImageNet数据通过"a photo of a "构造成文本-图像对数据集。
- 评测指标:CLIP score和FID(这里的FID采用CLIP来计算特征,而不是基于Inception V3),同时还基于validation loss选择模型。
- 评测数据集:COCO-2014验证集。
- 采样器设置:推理阶段均采用欧拉方法,共包括不同steps和CFG scale的6个配置,50 steps(CFG scale为1.0, 2.5, 5.0)以及CFG scale为5.0的5, 10, 25 steps。
- 权重:非EMA和EMA权重。
每个实验用EMA权重在不同的训练steps基于validation loss最小来确定最优的模型。这里2个训练数据集+6个采样器设置+2套参数共产生24个组合,所以每个模型也会得到24个评测结果。由于评测指标是2个,所以采用多目标优化中非支配排序算法(基于Pareto最优)来进行排序。每一种配置(24种)单独进行排序,然后取平均值。下表展示了不同模型的rank结果(这里只展示每组配置的top 2):
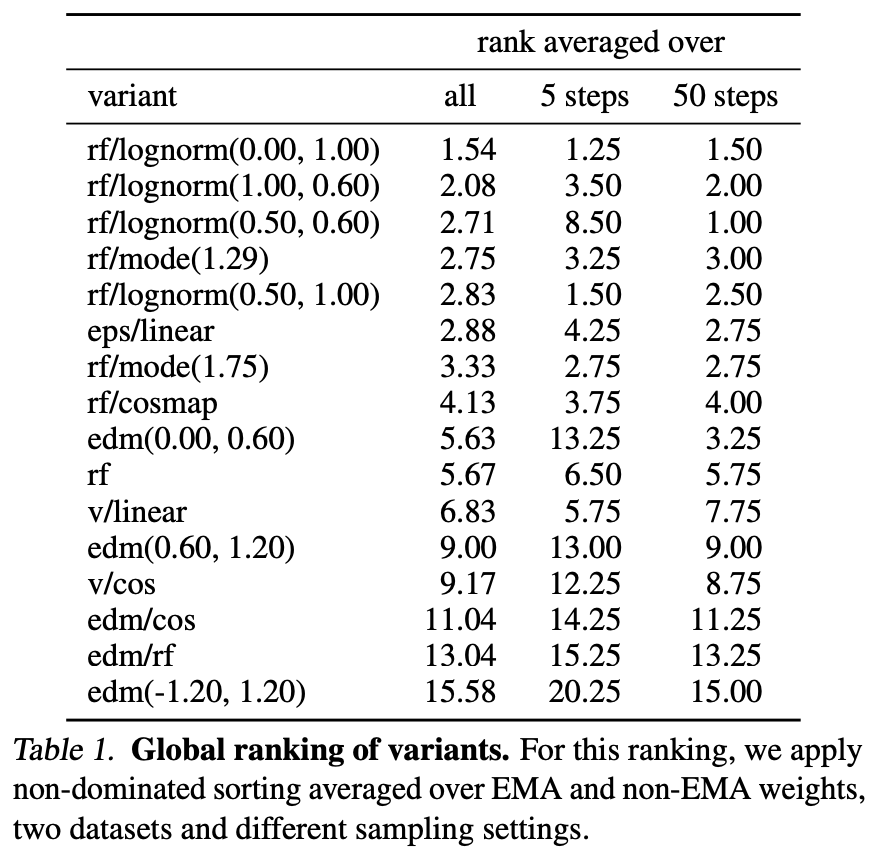
可以看到rf/lognorm(0.00, 1.00)是综合rank最高的,而且在5 steps和50 steps下也可以取得较好的rank。这里所采用的lognorm(0.00, 1.00)的时间采样方法也恰好是偏向中间时间步的,这说明对中间时间步加权是重要且有效的。这里也可以看到未改进的RF效果上反而是不如LDM所采用的eps/linear,而且经典的eps/linear的rank也仅次于几个改进的RF。
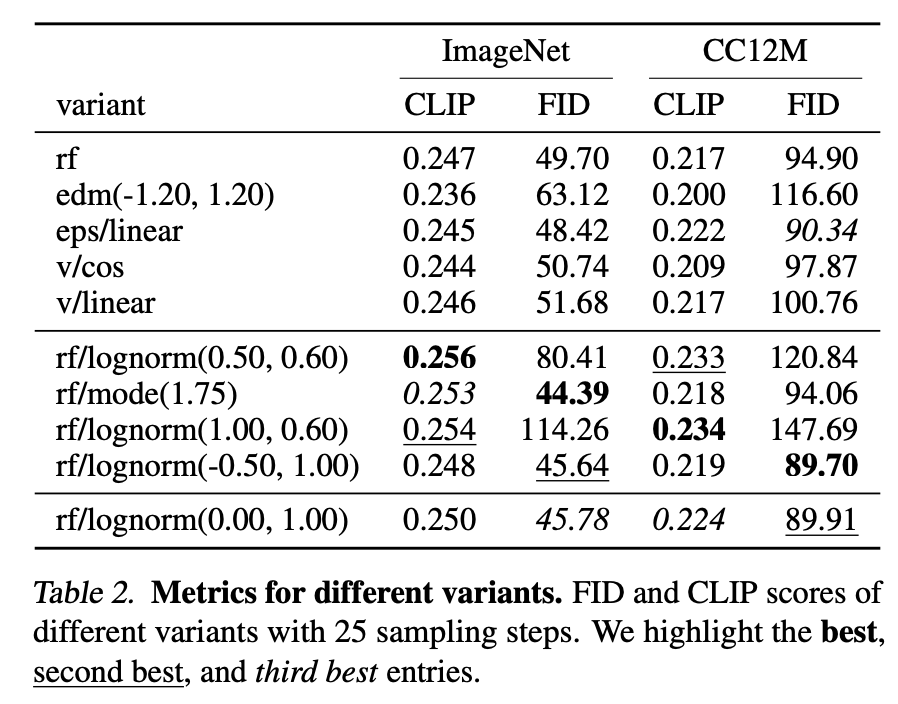
下表展示了不同的模型在25 steps下具体的CLIP score和FID,rf/lognorm(0.00, 1.00)两个数据集均表现不错,而经典的eps/linear其实也不差。
我们可以进一步去观察不同steps下各个模型的表现,如下图所示:
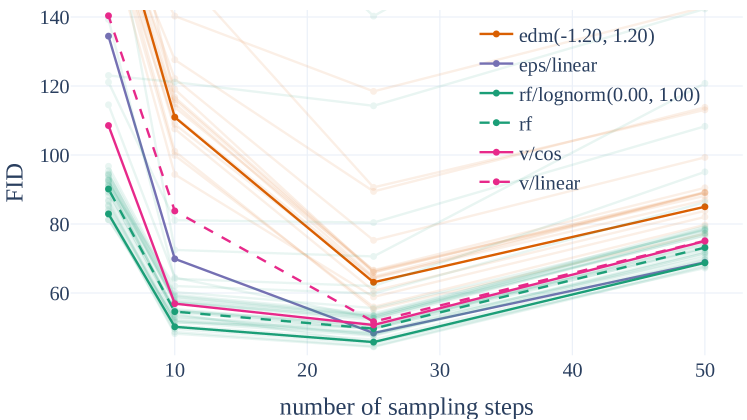
可以看到RF模型在steps比较小时展现比较明显的优势,说明RF模型可以减少推理阶段的采样步数。当steps增加时,RF不如eps/linear,但是改进后的rf/lognorm(0.00, 1.00)依然能够超过eps/linear。
总结:RF模型推理高效,但是通过改进时间采样方法对中间时间步加权能进一步提升效果,这里基于lognorm(0.00, 1.00)的采样方法从实验看是最优的。
SD3除了采用改进的RF,另外一个重要的改进就是采用了一个多模态DiT。多模态DiT的一个核心对图像的latent tokens和文本tokens拼接在一起,并采用两套独立的权重处理,但是在attention时统一处理。整个架构图如下所示:
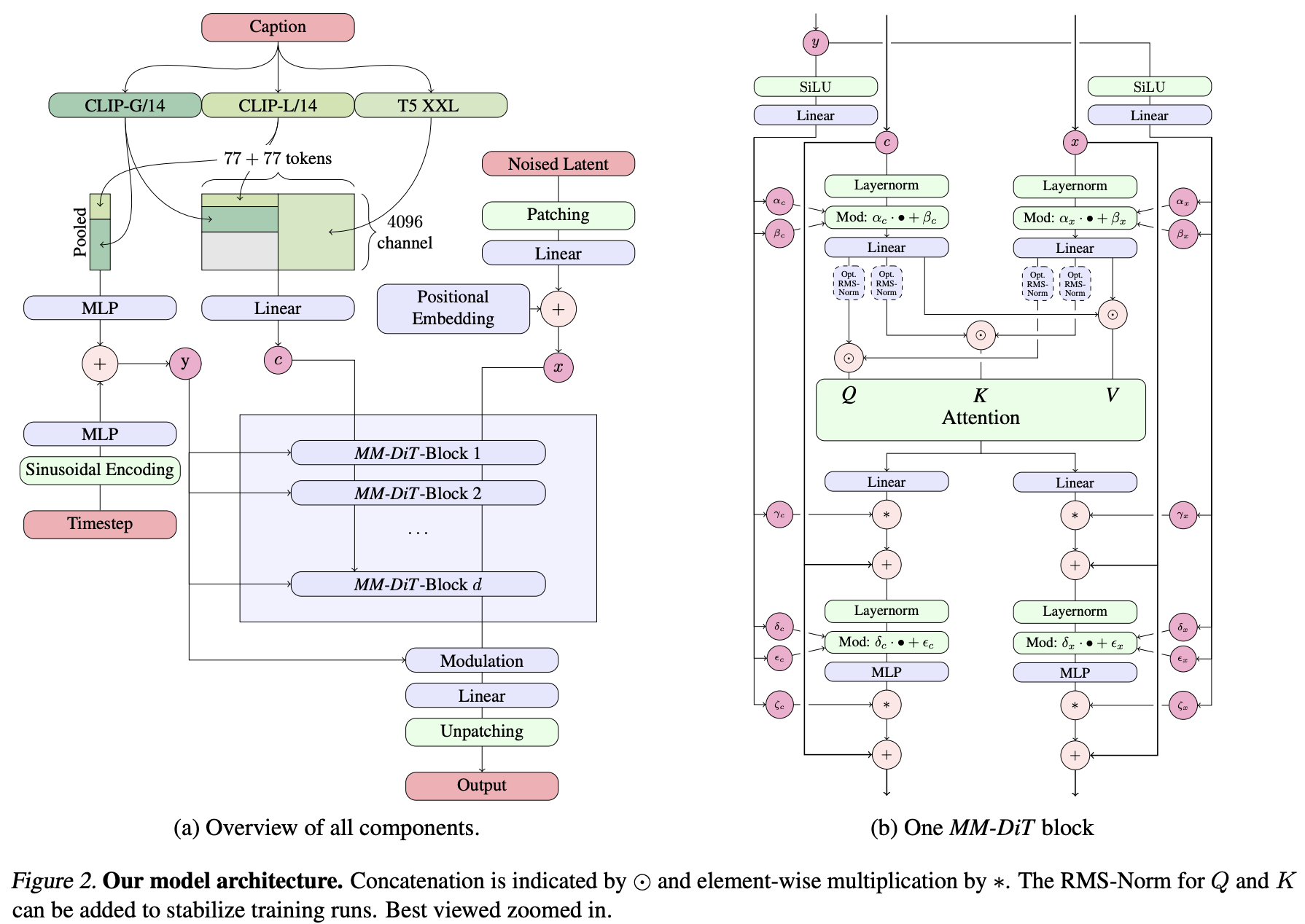
这里的MM-DiT和DiT一样,依然是使用一个autoencoder(VAE)来将图像编码为latent,然后将latent转成patches,送入transformer处理。之前版本的SD所使用的autoencoder是将一个

当
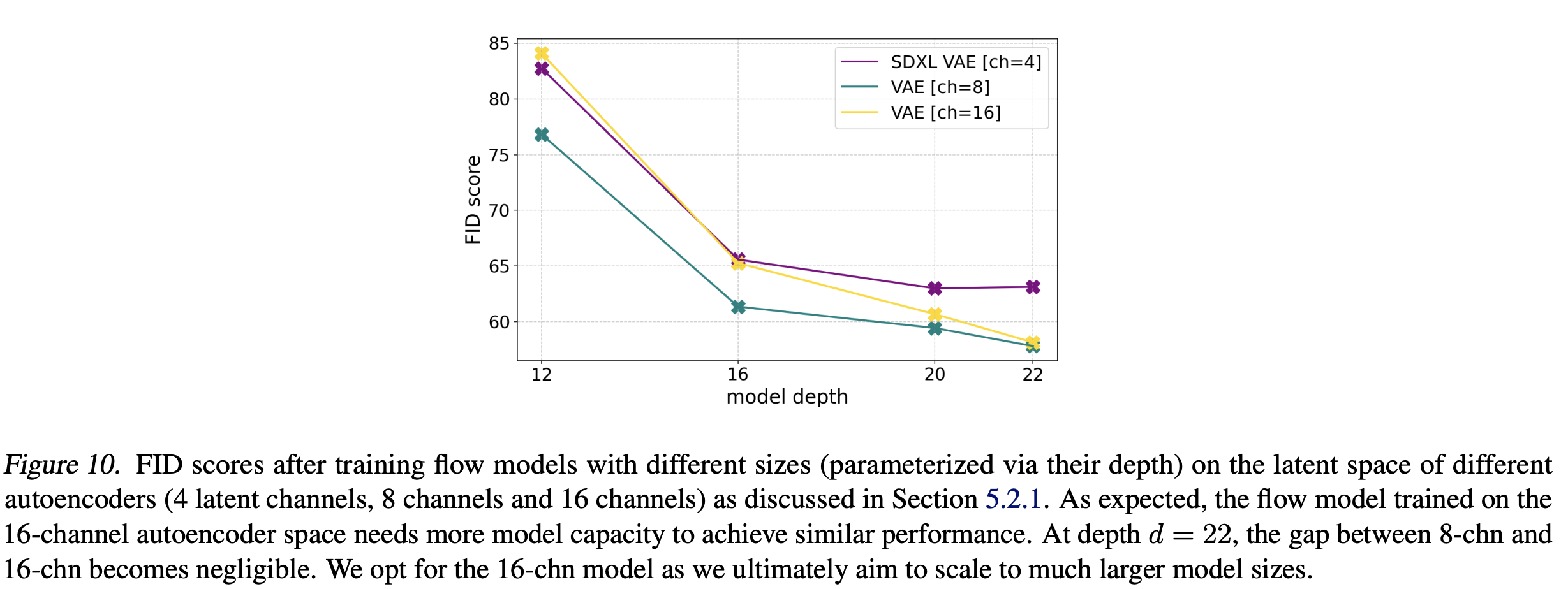
当模型参数小时,16通道的autoencoder并没有比4通道的autoencoder更好,但当模型参数增加时,16通道的autoencoder的优势慢慢展示出来,当模型深度到22时,16通道的autoencoder明显优于4通道的autoencoder。不过这里8通道的autoencoder在FID上也不差于16通道的autoencoder,但FID只是图像质量的一个间接评价指标,并不能提现图像细节的差异,从重建效果上看,16通道的autoencoder应该优势更明显,而且当模型变大后,上限更高。
比较类似的是,之前Meta的文生图模型Emu也采用16通道的autoencoder来提升图像细节。

而DALLE-3则是通过训练一个基于扩散模型的latent decoder来解决4通道autoencoder的问题,但是不如直接采用16通道的autoencoder,直接从源头解决问题。
SD3的text encoder包含3个预训练好的模型:
- CLIP ViT-L:参数量约124M
- OpenCLIP ViT-bigG:参数量约695M
- T5-XXL encoder:参数量约4.7B
对比其他版本的Stable Diffusion 模型的text encoder
- SD 1.x模型的text encoder使用CLIP ViT-L,
- SD 2.x模型的text encoder采用OpenCLIP ViT-H,
- 而SDXL的text encoder使用CLIP ViT-L + OpenCLIP ViT-bigG。
- SD3更上一个台阶,加上了一个更大的T5-XXL encoder。
谷歌的Imagen最早使用T5-XXL encoder作为文生图模型的text encoder,并证明预训练好的纯文本模型可以实现更好的文本理解能力,后面的工作,如NVIDIA的eDiff-I和Meta的Emu采用T5-XXL encoder + CLIP作为text encoder,OpenAI的DALL-E 3也采用T5-XXL encoder。SD3加入T5-XXL encoder也是模型在文本理解能力特别是文字渲染上提升的一个关键。
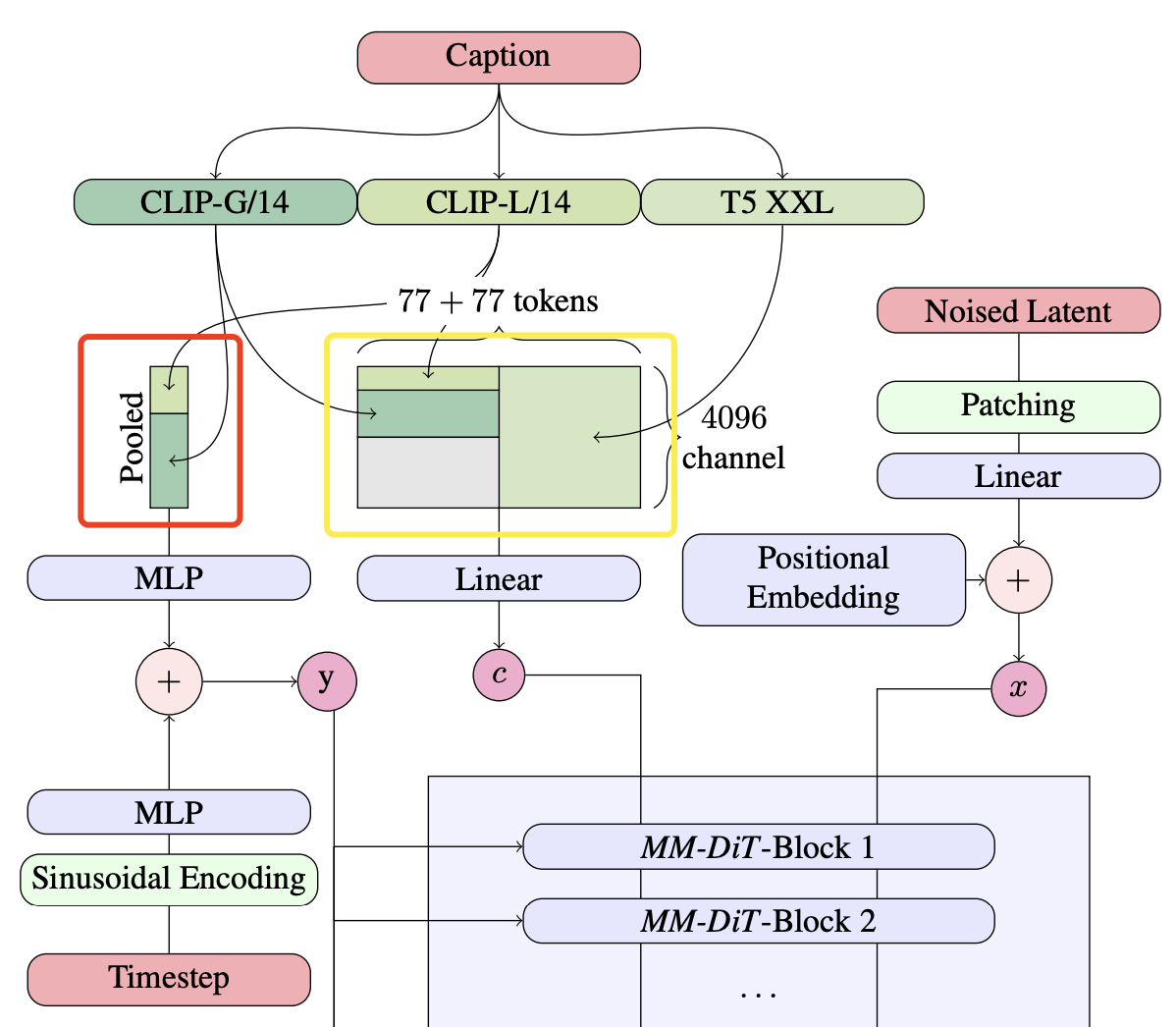
具体地,SD3总共提取两个层面的特征。
首先提取两个CLIP text encoder的pooled embedding,它们是文本的全局语义特征,维度大小分别是768和1280,两个embedding拼接在一起得到2048的embedding,然后经过一个MLP网络之后和timestep embedding相加。
然后是文本细粒度特征。这里也先分别提取两个CLIP模型的倒数第二层的特征,拼接在一起可以得到77x2048维度的CLIP text embeddings;同样地也从T5-XXL encoder提取最后一层的特征T5 text embeddings,维度大小是77x4096(这里也限制token长度为77)。然后对CLIP text embeddings使用zero-padding得到和T5 text embeddings同维度的特征。最后,将padding后的CLIP text embeddings和T5 text embeddings在token维度上拼接在一起,得到154x4096大小的混合text embeddings。text embeddings将通过一个linear层映射到与图像latent的patch embeddings同维度大小,并和patch embeddings拼接在一起送入MM-DiT中。
采用CLIP+T5-XXL encoder相比单独的T5-XXL encoder可能带来性能增益,但是一个不利的影响是CLIP text encoder只能默认编码77 tokens长度的文本,这也限制了T5-XXL encoder的token长度(T5-XXL encoder能够编码512 tokens)。DALL-E 3可以输入比较长的文本,而这里的SD3默认只能处理77 tokens长度的文本。
MM-DiT和DiT一样也是处理图像latent空间,这里先对图像的latent转成patches,这里的patch size=2x2,和DiT的默认配置是一样的。patch embedding再加上positional embedding送入transformer中。
这里的重点是如何处理前面说的文本特征。对于CLIP pooled embedding可以直接和timestep embedding加在一起,并像DiT中所设计的adaLN-Zero一样将特征插入transformer block。
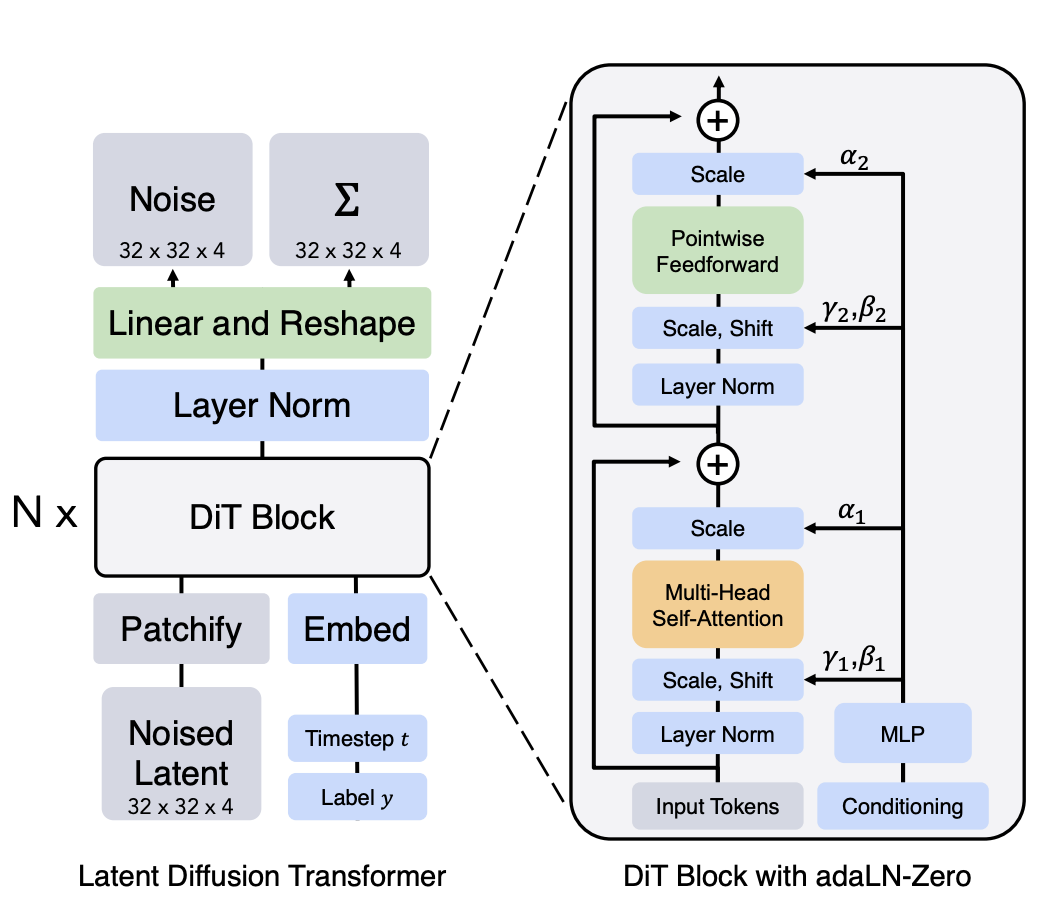
具体的实现代码如下所示:
def modulate(x, shift, scale):
return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
class DiTBlock(nn.Module):
"""
A DiT block with adaptive layer norm zero (adaLN-Zero) conditioning.
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return x对于序列的text embeddings,常规的处理方式是增加cross attention层来处理,其中text embeddings作为attention的keys和values,比如SD的UNet以及PIXART-α(基于DiT)。但是SD3是直接将text embeddings和patch embeddings拼在一起处理,这样不需要额外引入cross-attention。由于text和image属于两个不同的模态,这里采用两套独立的参数来处理,即所有transformer层的学习参数是不共享的,但是共用一个self-attention来实现特征的交互。这等价于采用两个transformer模型来处理文本和图像,但在attention层连接,所以这是一个多模态模型,称之为MM-DiT。
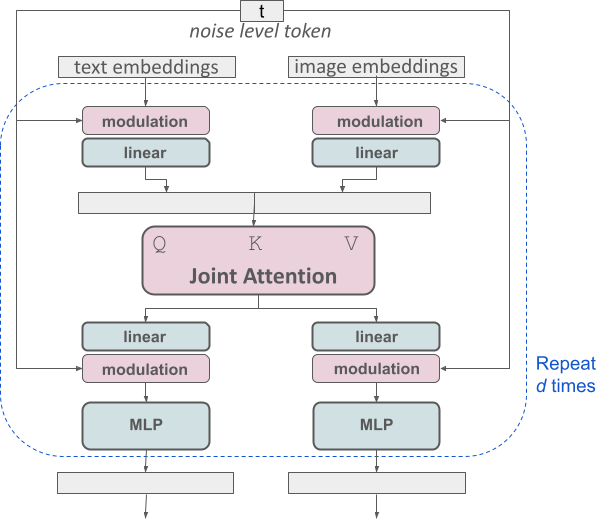
MM-DiT和之前文生图模型的一个区别是文本特征不再只是作为一个条件,而是和图像特征同等对待处理。论文中也基于CC12M数据集将MM-DiT和其它架构做了对比实验,这里对比的模型有DiT(这里的DiT是指的不引入cross-attention,直接将text tokens和patches拼接,但只有一套参数),CrossDiT(额外引入cross-attention),UViT(UNet和transformer混合架构),还有3套参数的MM-DiT(CLIP text tokens,T5-XXL text tokens和patches各一套参数)。不同架构的模型表现如下所示:
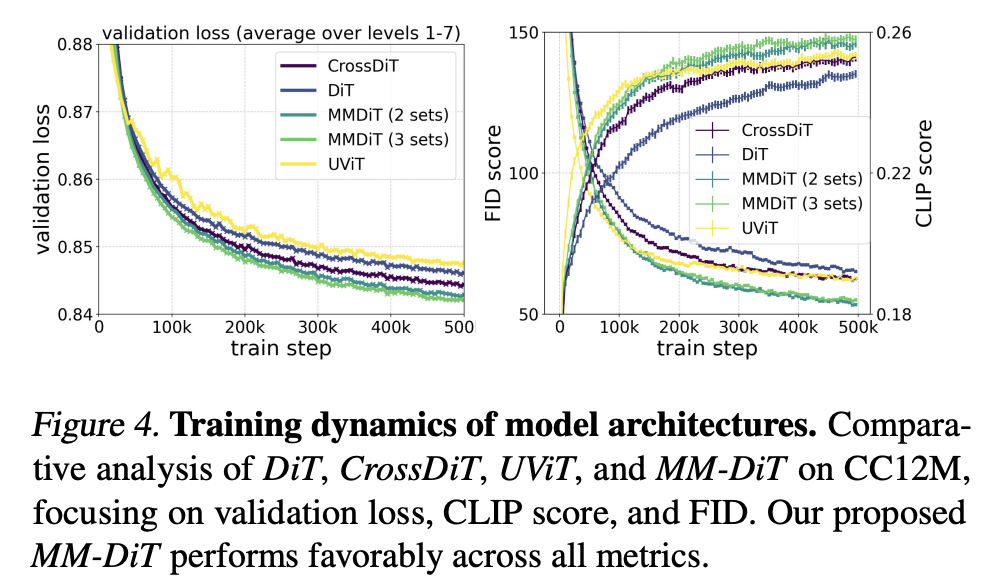
可以看到MM-DiT是优于其它架构的,其中3套参数的MM-DiT略好于2套参数的MM-DiT,最终还是选择参数量更少的2套参数的MM-DiT。不过,这里和其它架构的对比是否保证了同参数大小,否则实验就显得有点不公平了。
MM-DiT的模型参数主要是模型的深度
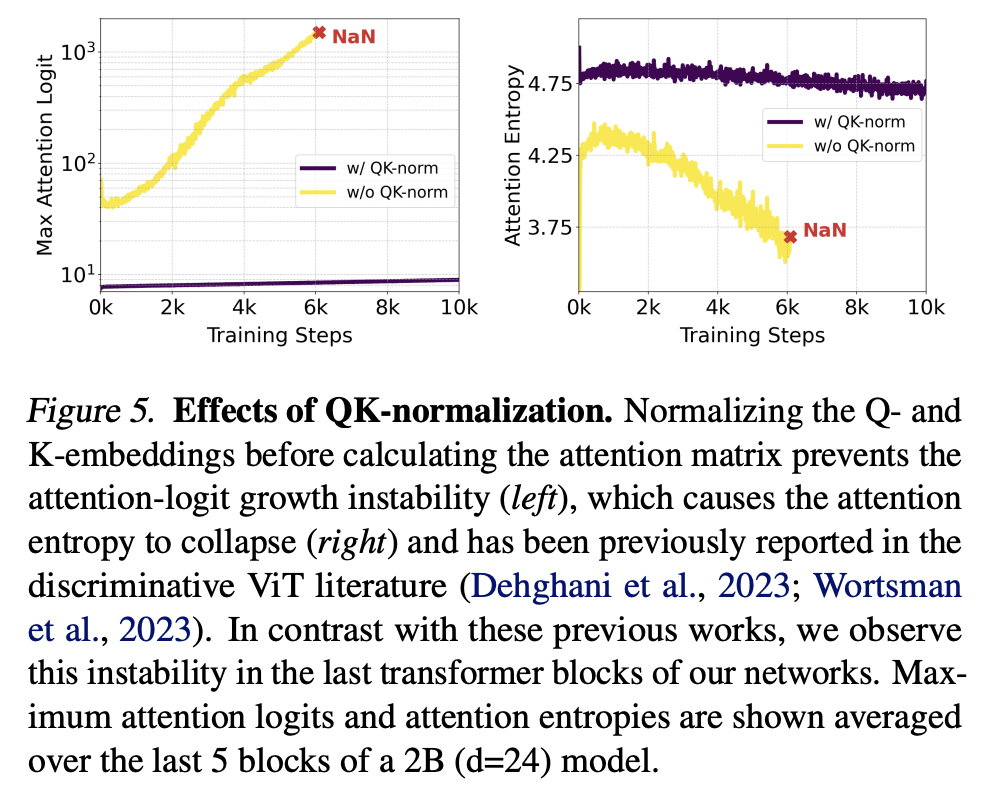
为了提升混合精度训练的稳定性,MM-DiT的self-attention层还采用了QK-Normalization。当模型变大,而且在高分辨率图像上训练时,attention层的attention-logit(Q和K的矩阵乘)会变得不稳定,导致训练出现NAN。这里的解决方案是采用RMSNorm(简化版LayerNorm)对attention的Q和K进行归一化。
MM-DiT的位置编码和ViT一样采用2d的frequency embeddings(两个1d frequency embeddings进行concat)。SD3先在256x256尺寸下预训练,但最终会在以1024x1024为中心的多尺度上微调,这就需要MM-DiT的位置编码需要支持变尺度。SD3采用的解决方案是插值+扩展。
这里假定我们的目标分辨率的像素量为
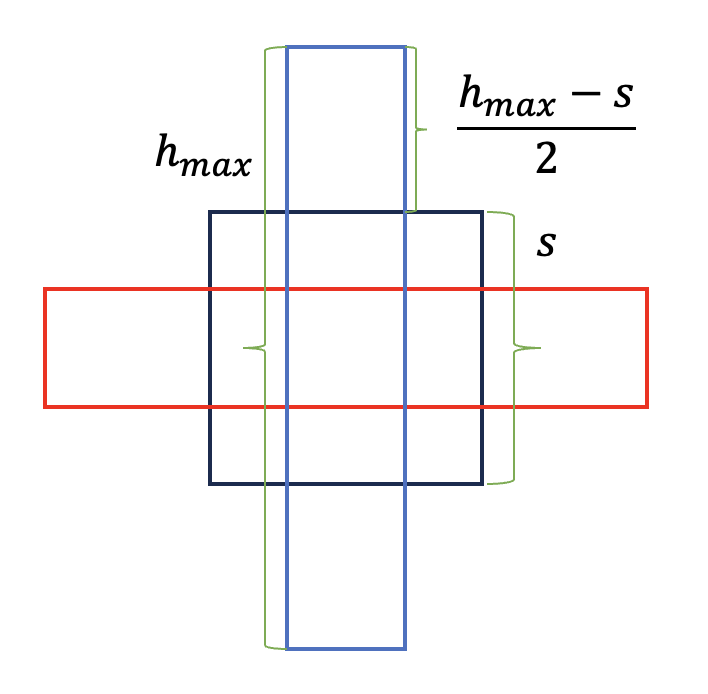
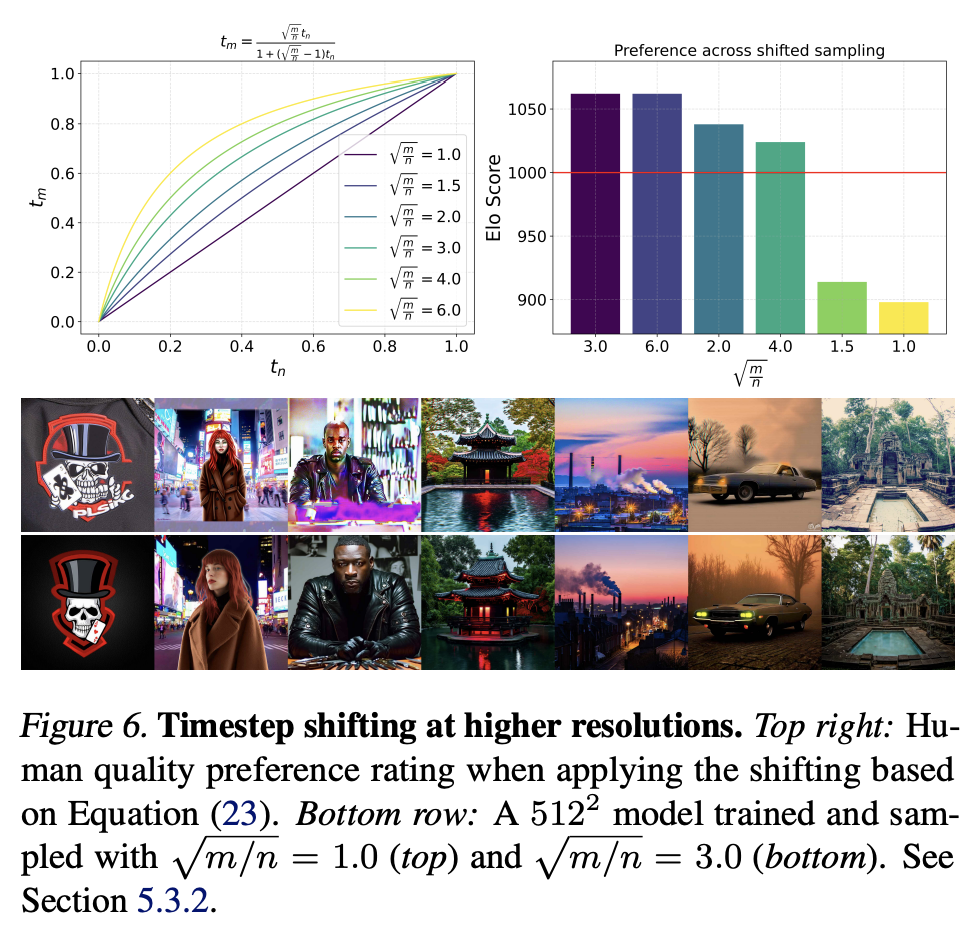
对高分辨率的图像,如果采用和低分辨率图像的一样的noise schedule,会出现对图像的破坏不够的情况,如下图所示(图源自On the Importance of Noise Scheduling for Diffusion Models):

一个解决办法是对noise schedule进行偏移,对于RF模型来说,就是timestep schedule的shift。下面我们来理论分析如何进行shift。假定要处理的图像包含
transformer一个比较大的优势是有好的scaling能力:当增大模型带来性能的稳定提升。论文中也选择了不同规模大小的MM-DiT进行实验,不同大小的网络深度分别是15,18,21,30,38,其中最大的模型参数量为8B。结论是MM-DiT同样表现了比较好的scaling能力,当模型变大后,性能稳步提升,如下图所示:
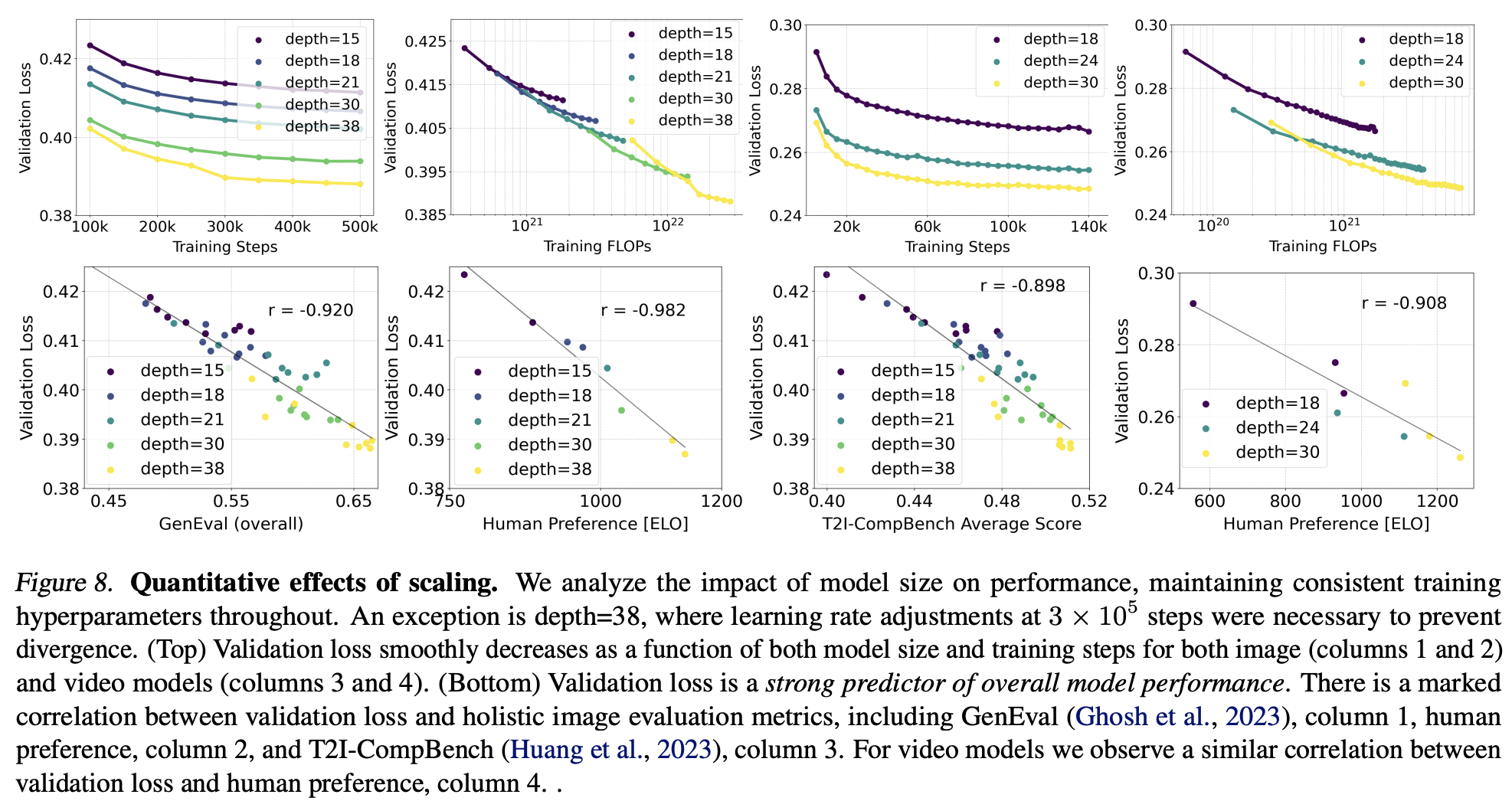
这里的另外一个结论是validation loss可以作为一个很好的模型性能的衡量指标,它和文生图模型的一些评测指标如CompBench和GenEval,以及人类偏好是正相关的。而且从目前的实验结果来看,还没有看到出现性能的饱和,这意味着继续增大模型,依然有可能继续提升。
下图展示了三个不同大小的模型生成图像的差异,可以看到大模型确实是质量最好的。

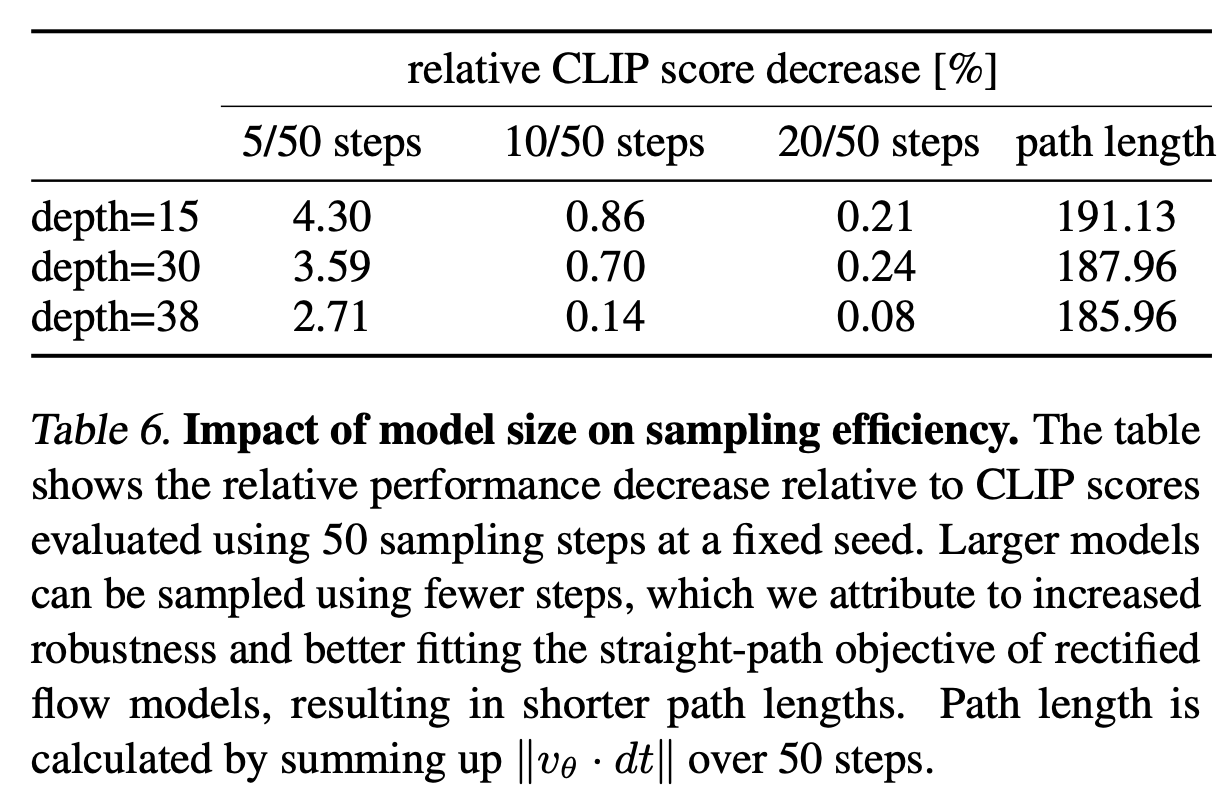
而且更大的模型不仅性能更好,而且生成时可以用较少的采样步数,比如当步数为5步时,大模型的性能下降要比小模型要低。
这部分简单介绍一下SD3的一些实现细节,包括训练数据的处理以及训练参数等。
预训练数据集的大小和来源是没有的,但是预训练数据会进行一些筛选,包括:
- 色情内容:使用NSFW检测模型来过滤。
- 图像美学:使用评分系统移除预测分数较低的图像。
- 重复内容:基于聚类的去重方法来移除训练数据中重复的图像,防止模型直接复制训练数据集中图像。(这部分策略附录部分很详细)
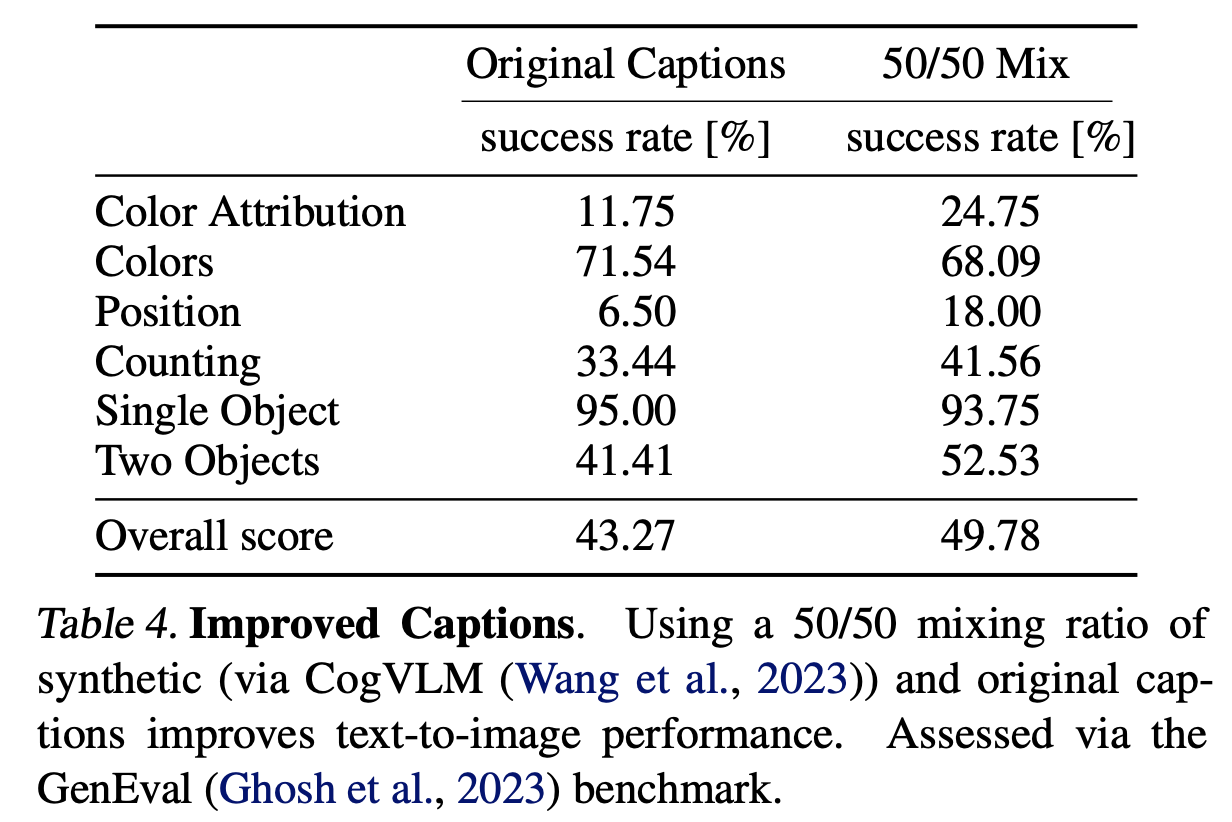
和DALL-E 3一样,这里也对训练数据集中的图像生成高质量caption,这里使用的模型是多模态大模型CogVLM。训练过程中,使用50%的原始caption和50%的合成caption,使用合成caption能够提升模型性能,如下表所示。
为了减少训练过程中所需显存,这里预先计算好图像经过autoencoder编码得到的latent,以及文本对应的text embedding,特别是T5,可以节省接近20B的显存。同时预先计算好特征,也会节省一部分时间。
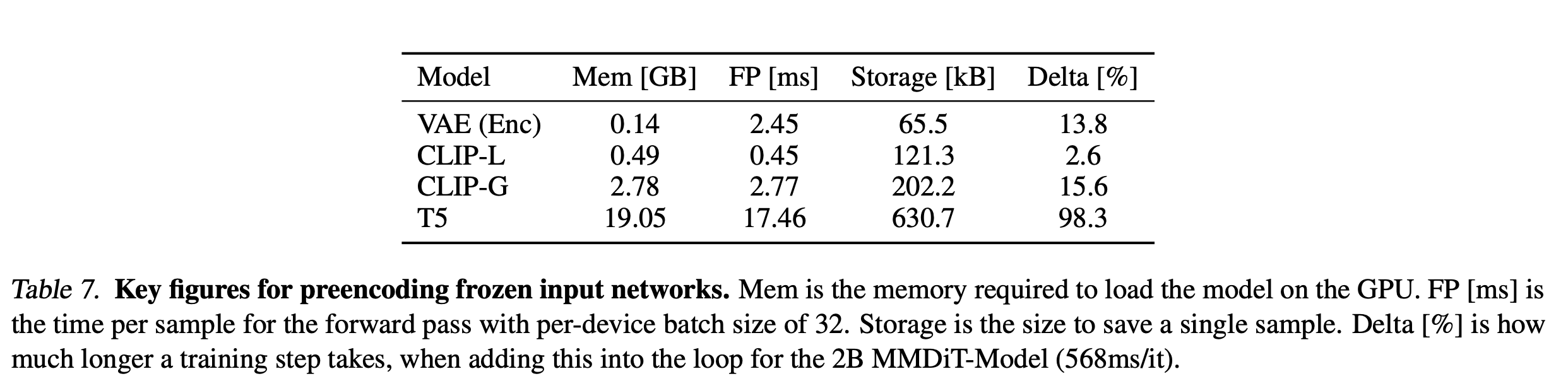
但是预计算特征也不是没有代价的,首先是图像就不能做数据增强,好在文生图模型训练一般不太需要数据增强,其次需要一定的存储空间,而且加载特征也需要时间。预计算特征其实就是空间换时间。
训练过程需要对文本进行一定的drop来实现Classifier-Free Guidance,这里是三个text encoder各以46.4%的比例单独drop,这也意味着text完全drop的比例为
三个text encoder独立drop的一个好处是推理时可以灵活使用text encoder。比如,我们可以去掉比较吃显存的T5模型,只保留两个CLIP text encoder,实验发现这并不会影响视觉美感(没有T5的胜率为50%),并且只会导致文本遵循度略有下降(胜率为46%),这种情况包括文本提示词包含高度详细的场景描述或大量文字。然而,如果想生成文字,还是加上T5,没有T5的胜率只有38%。下面是一些具体的例子:

SD3最后基于DPO来进一步提升性能,DPO相比RLHF的一个优势不需要单独训练一个reward模型,而且直接基于成对的比较数据训练。
DPO目前已经成功应用在文生图上:Diffusion Model Alignment Using Direct Preference Optimization。SD3这里没有finetune整个网络,而是基于rank=128的LoRA,经过DPO后,图像生成质量有一定的提升,如下所示:

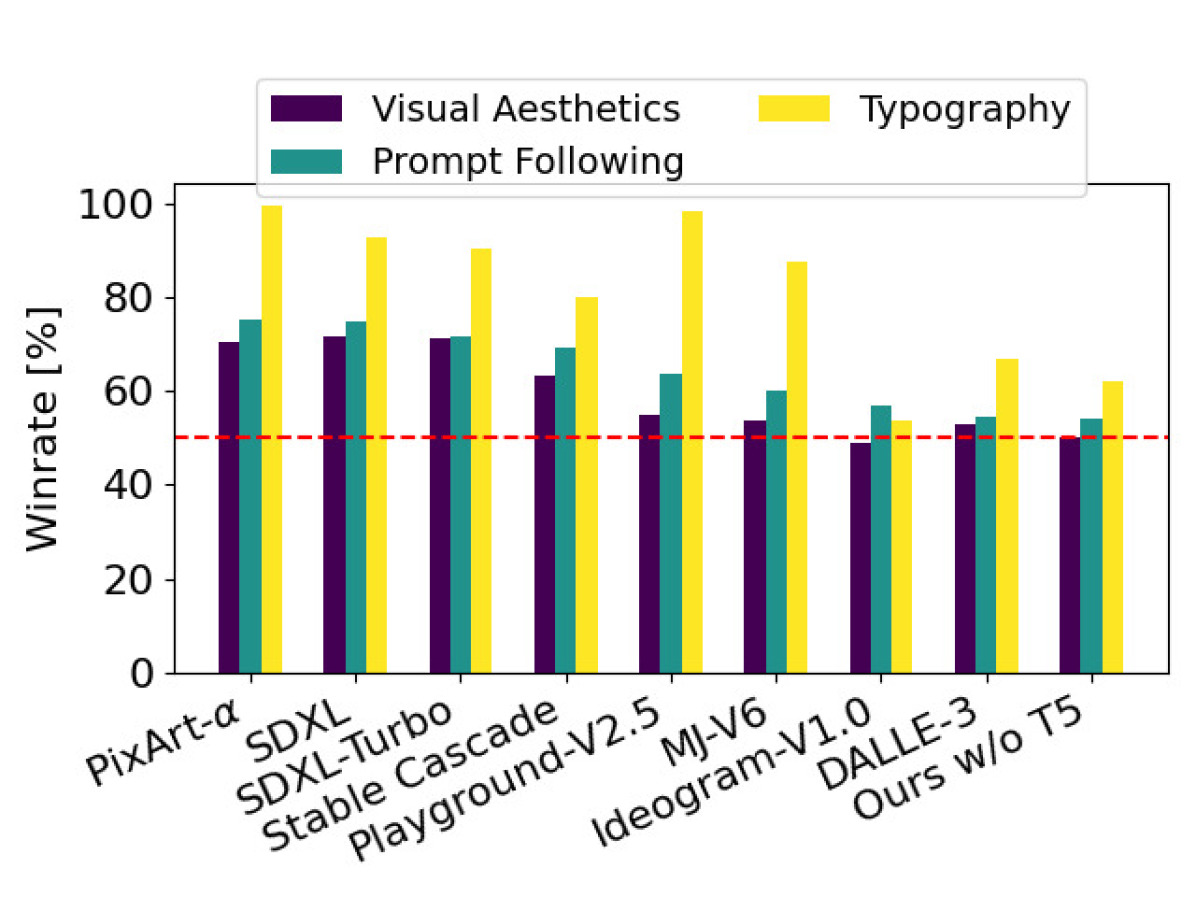
性能评测包括定量评测和人工评测。
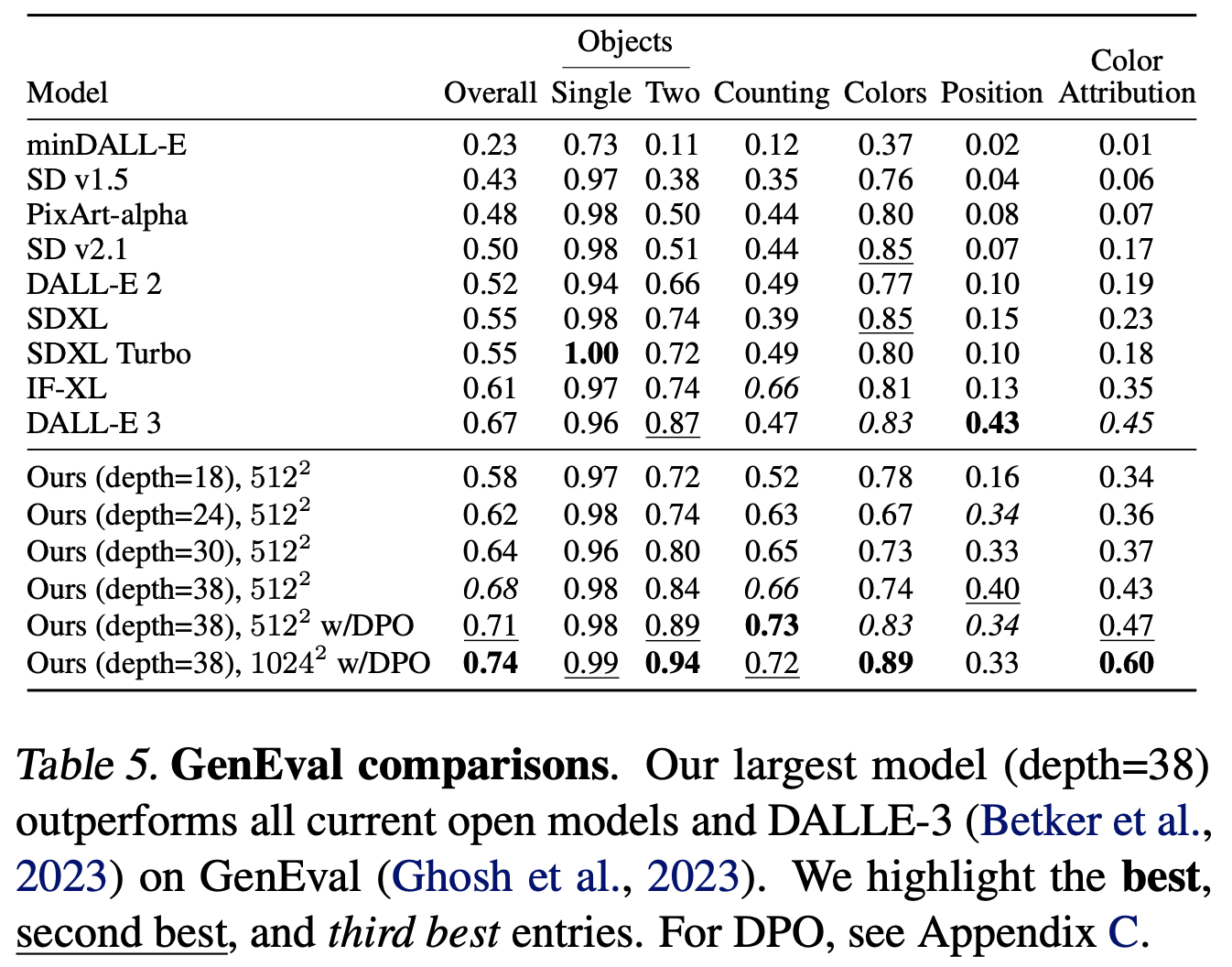
定量评测基于GenEval,SD3和其它模型的对比如下所示,可以看到最大的模型在经过DPO后超过DALL-E 3。

人工评测包括三个方面:
- Prompt following: Which image looks more representative to the text shown above and faithfully follows it?
- Visual aesthetics: Given the prompt, which image is of higher-quality and aesthetically more pleasing?
- Typography: Which image more accurately shows/displays the text specified in the above description? More accurate spelling is preferred! Ignore other aspects.
评测结果如下所示,这里对比的模型有SOTA的模型:MJ-V6,Ideogram-V1.0,DALL-E 3,在文字生成方面,SD3基本大幅赢过其它模型(和Ideogram-V1.0相差上下),在图像质量和文本提示词遵循方面也和SOTA模型不相上下。
SD3可以说是集大成者,基本上把业界最好的或者最成熟的方案都用上了,比如RF和DiT,以及DPO等等。
SD3的正式发布,也基本宣告文生图进入transformer时代了,现在的模型才是8B,未来更大的模型也定会出现。