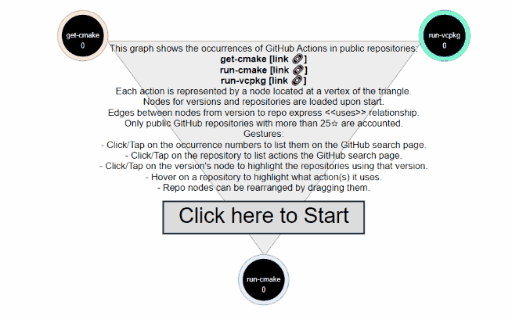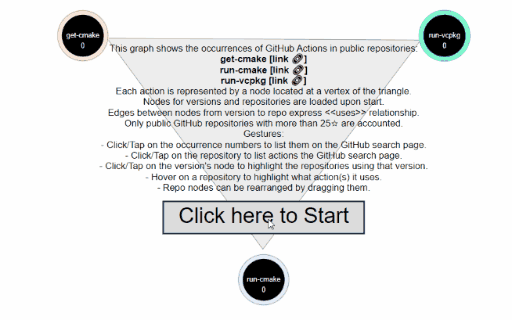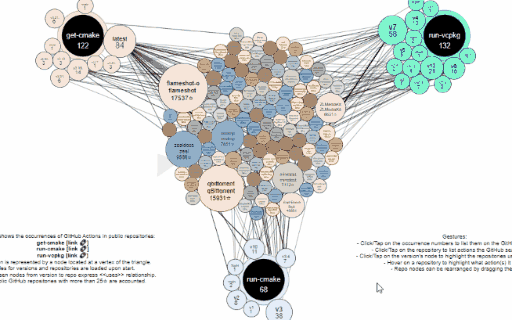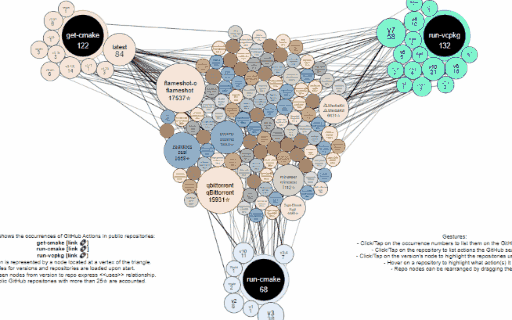
This repository contains the sources of the get-action-usage GitHub Action that regularly builds and updates the interactive graph which visualizes the consumers of the following three other actions:
The action collects all usages in public GitHub repositories of the mentioned actions, the results are stored into the repository itself in the action-usage-db.json file, which is then consumed by the graph/graph.html page to visualize an interactive network graph. Eventually the files are published online.
This get-action-usage is based on NodeJS and it is running on a recurring workflow.
The interactive graph is based on D3.js.
In early 2020 I released the GitHub Actions for using CMake and vcpkg on GitHub:
Later in 2022 I was thinking if those actions are useful at all: "are being used? If so who?".
Naturally I thought that it was obvious I could satisfy my curiosity by writing another software that would tell me the answer by visualizing it somehow.
This is the way I thought I'd like to collect all the occurrences of those actions in GitHub workflows, and then somehow visualize them in a graph.
Since my initial choice has been to not implement anything unpleasant in the actions like telemetry (aka remote monitoring), one alternative way to get all their usage is to scan all the public GitHub repository and look in their workflow files (stored under /.github/workflows/ directory). Executing this manually would be not possible, it must be automatized.
Initially I wrote a Node.js application in JavaScript that, using the @octokit module, is leveraging underneath the GitHub HTTP APIs to fetch the data. The program would first get the list of repositories and then look for the usage of the actions in their workflow.
This naive idea presented several challenges.
Obtaining the answer to my curiosity was hard and presented several challenges to face, think about and overcome, which I roughly group in three main set of challenges that were solved in three subsequent implementations.
The initial program looked like this:
import { Octokit } from '@octokit/rest';
search() {
const repos = octokit.rest.search.repos("language=cpp desc sort=stars");
foreach(var repo in repos) {
//... look in `.github/workflow` for occurrences of 'run-cmake' or 'run-vcpkg' ...
await this.octokit.rest.repos.getContent(...)
}
}This code surfaced some problems:
- The
search domain(i.e. list of repositories) is far bigger than the maximum limit of1,000results per search provided by the Search APIs. - The list of repositories is also very long, attention to the secondary HTTP request limit forces to honor the Retry-After header when doing lot of queries for long time.
Here my attempted solutions:
- To overcome the point one, the
search domainhas been partitioned in several periods of time, hoping that the resulting list is never more than1,000hits. This is a simple solution that could be improved by re-trying with a smaller period of time when the limit is hit. - For point two, I just added a simple sleep of three seconds for each HTTP request.
This is pseudo code of the next attempted solution:
import { Octokit } from '@octokit/rest';
search() {
foreach(var timePeriod in timePeriods) {
const repos = octokit.rest.search.repos(`language=cpp desc sort=stars created=${timePeriod.begin}..${timePeriod.end}`);
foreach(var repo in repos) {
//... look in `.github/workflow` for occurrences of 'run-cmake' or 'run-vcpkg' ...
await delay(3000);
await this.octokit.rest.repos.getContent(...)
}
}
}This allowed to get something like thousands of repositories scanned over an hour, and the repositories to look into are way more than that.
Now I thought that either I keep running this program locally on my computer for a very long time, or I could let it running as a GitHub Action itself and schedule a recurring run, and so I did.
To regularly scan and collect the data incrementtally a workflow has been created with a single job in it.
Running on GitHub hosted runners is good but with caveats:
- Using
GITHUB_TOKENhas a limit of 1000 requests per hour, instead a personal access token must be used to maintain the mentioned limit of5000requests/hour. So the latter must be preferred. - The workflow job can run for at most 6 hours, then it is going to be ungracefully cancelled without any chance to save any completd work. That is NOT enough time to get the full results. In fact the result must be incrementaly computed, and I had to instrument the application to accumulate the results among multiple runs. This has been accomplished accumulating results to a simple database implemented with the node-json-db module. In the same way a marker is written in the file that identify which is the next date to start the search from.
This is roughly how the second implementation looked like:
import { Octokit } from '@octokit/rest';
import { JsonDB } from 'node-json-db';
search() {
foreach(var timePeriod in timePeriods) {
const repos = octokit.rest.search.repos(`language=cpp desc sort=stars created=${timePeriod.begin}..${timePeriod.end}`);
foreach(var repo in repos) {
//... look in `.github/workflow` for occurrences of 'run-cmake' or 'run-vcpkg' ...
await delay(3000);
await this.octokit.rest.repos.getContent(...);
}
}
this.db.save(true);
} Now as noted by the astute reader, for incrementality to work correctly we need to store the JSON file somewhere to be later retrieved. I decided to push it in the repository itself, and doing this is easy when using the @action/checkout action, which allows the workflow to easily push data to the just cloned repository by using the PAT.
Also, the workflow needs to be scheduled for re-running as soon as possible. The solution is to:
- run it regularly with a fixed schedule (e.g., every hour).
- and schedule the next re-run based on when the API rate limit are reset, that is ASAP.
On each run, either the database JSON is filled with new data, and the workflow is patched to schedule a next run when the API HTTP request quota is given back. Both changes are pushed onto the repository by the workflow itself, as follows:
workflow:
on:
pull_request:
schedule:
- cron: '0 * * * *' # Regular run each hour.
- cron: '1 2 3 4 5' # Scheduled re-run as soon as the rate limit are reset and full quota is got back.
[...]
- name: Commit DB content and update CRON job
run: |
...
git remote set-url origin https://x-access-token:${{ secrets.PAT }}@github.com/${{ github.repository }}
...
git pushAgain, challenges of the solution:
-
Since the workflow is self modifying, the
PATneeds to be setup such it has the 'workflow' permission that grants to "Update GitHub Action workflows". The ordinaryGITHUB_TOKENdoes not have that permission. -
It is likely to happen that two workflows run concurrently. In this case, it's best to ensure only one is actually querying by checking whether there is an already running workflow at the very start and exit immediately without further action in affirmative case.
-
Whenever the second scheduled workflow fails before having the chance to schedule the next run, the first hourly schedule is going to (hopefully) fix it.
The fixed delay for each HTTP request is not really necessary, and it does not play nice with concurrent requests, which would improve a lot the results' throughput.
The solution is to leverage the following NPM libraries that respect the secondary limits and permit maximum speed:
In file packages.json:
"dependencies": {
"@octokit/plugin-rest-endpoint-methods": "^5.13.0",
"@octokit/plugin-retry": "~3.0.9",
"@octokit/plugin-throttling": "^3.6.2",
}
The package @octokit and the others allow to drop the silly fixed delay time and to run concurrently several requests searching for occurrences of the actions, by improving performance 100x.
import { Octokit } from '@octokit/rest';
import { JsonDB } from 'node-json-db';
import { throttling } from '@octokit/plugin-throttling';
import { retry } from '@octokit/plugin-retry';
import { restEndpointMethods } from '@octokit/plugin-rest-endpoint-methods';
search() {
foreach(var timePeriod in timePeriods) {
const repos = octokit.rest.search.repos(`language=cpp desc sort=stars created=${timePeriod.begin}..${timePeriod.end}`);
foreach(var repo in repos) {
// ... look concurrently in `.github/workflow` for occurrences of 'run-cmake' or 'run-vcpkg' ...
const promise = this.octokit.rest.repos.getContent(...)
// ...
await Promise.all(promises);
}
}
}Feedback is welcome, create Issues entries, pretty sure this is not the end of the story!
Copyright 2022-2023-2024 by Luca Cappa [email protected] All content of this repository is licensed under the CC BY-SA License. See the LICENSE file in the root for license information.