| title | shortTitle |
|---|---|
MySQL 之简单查询:开始踏上 SELECT 之旅 |
MySQL 之简单查询 |
前面我们介绍了如何创建数据库、如何创建数据表,那今天我们来结合技术派实战项目的数据来讲讲 MySQL 查询,也就是 SELECT 语句。
我们先从最简单的 SELECT 查询开始,主打一个循序渐进,以便让大家彻底掌握 SELECT。
在日常的开发工作中,查询语句也是最常用的,因为表在一开始设计的时候已经确定了,后期很少去修改表结构,也就意味着插入数据的方式也是确定的,但数据的展示方式却千奇百怪,用户端和 admin 管理端可能需要各种各样的数据,那 MySQL 就要提供最接近需求的数据,这样可以节省 Java 程序对数据的转换处理,也就相应提升了程序的性能。
如何提供最接近需求的数据呢?这就要靠 SELECT 语句了。
技术派实战项目的代码是开源的,大家可以在GitHub进行下载,下载完成后直接在本地运行主程序,就会自动生成对应的数据表。
当然了,如果你只想要技术派的真实数据,那我也提供了一种渠道,你可以加入二哥的编程星球,找二哥私发最新的数据库文件。之所以这么做,是因为涉及到用户的隐私数据,没法向所有人公开。
目前技术派实战项目初始启动后的数据表如下所示,article 表是本篇内容主要查询的表对象。
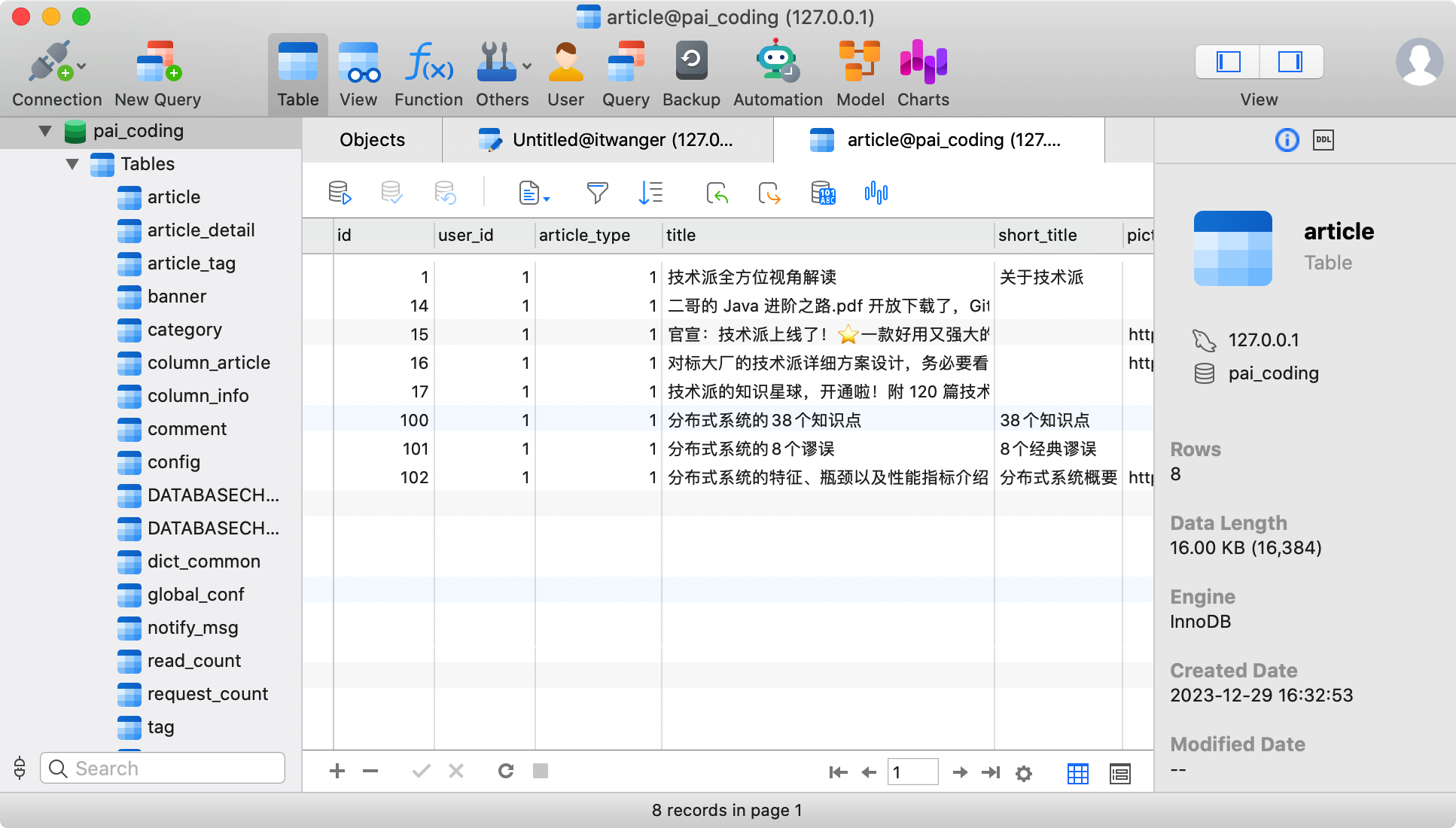
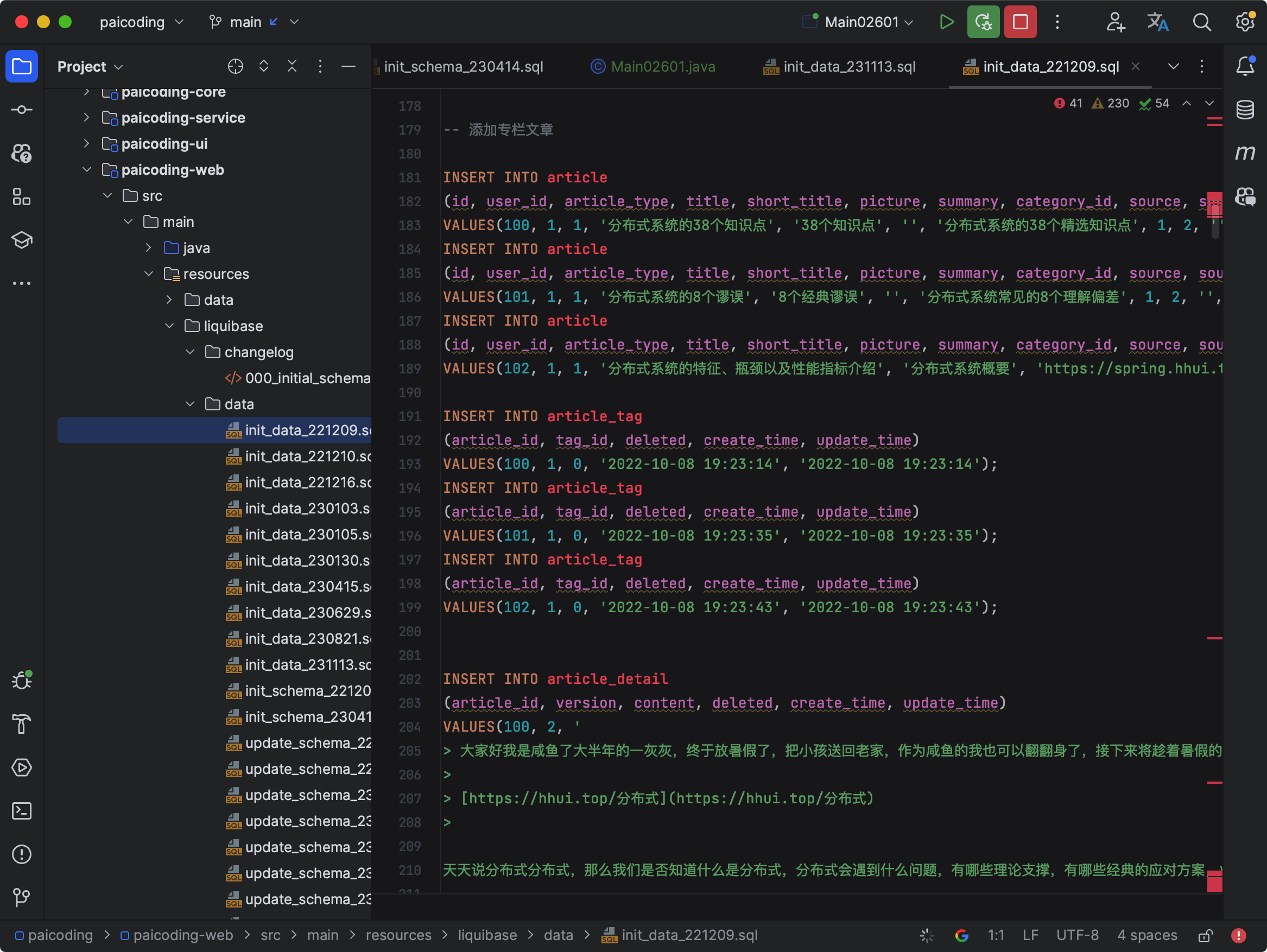
如果你用 Intellij IDEA 打开技术派的源码,可以在 init_data_221209.sql 文件中看到这些数据的插入语句。
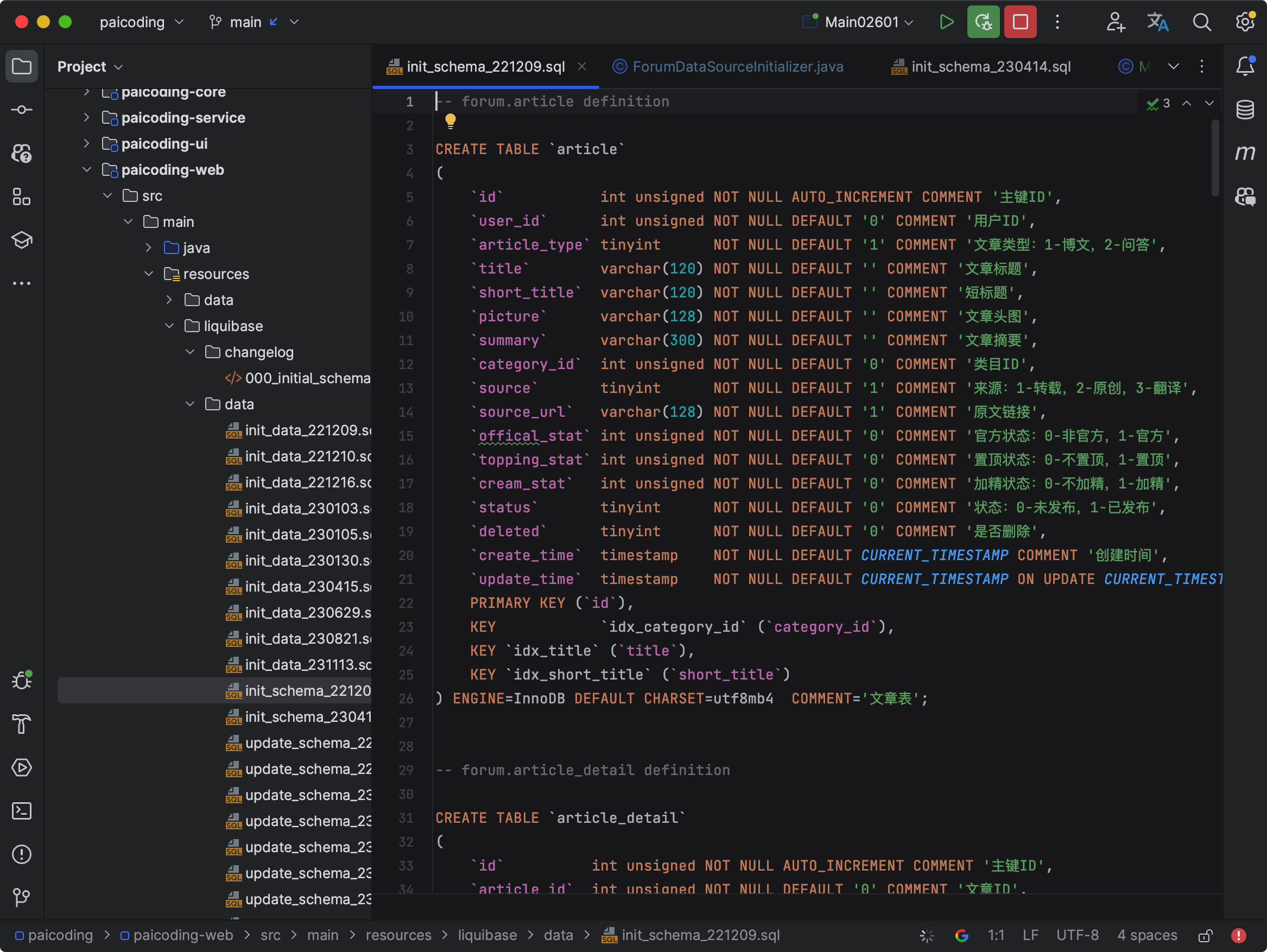
表结构的定义在 init_schema_221209.sql 文件中。
好,初始数据准备完成后,我们就可以开始查询语句的学习了。
查看某个表的某个字段,格式如下所示:
SELECT 字段名 FROM 表名;比如说,我们想要查看 article 表的 title 字段,那查询语句就是:
SELECT title FROM article;执行这条语句后,我们可以看到下面这些数据。

如果你想要给查询出来的字段起一个别名,可以使用 AS 关键字,格式如下所示:
SELECT 字段名 AS 别名 FROM 表名;比如说,我们想要给 title 字段起一个别名叫做 文章标题,那查询语句就是:
SELECT title AS '文章标题' FROM article;这通常会在多表进行联合查询或者 Java 程序端和 MySQL 表字段不一致时使用。
比如说,Java 程序端的字段名是 articleTitle,那我们就可以使用别名来解决这个问题。
SELECT title AS articleTitle FROM article;当结果集中需要多个字段时,可以使用逗号 , 分隔字段进行查询,格式如下所示:
SELECT 字段1, 字段2, 字段3 FROM 表名;比如说,我们想要查看 article 表的 title、user_id、create_time 字段,那查询语句就是:
SELECT title, user_id, create_time FROM article;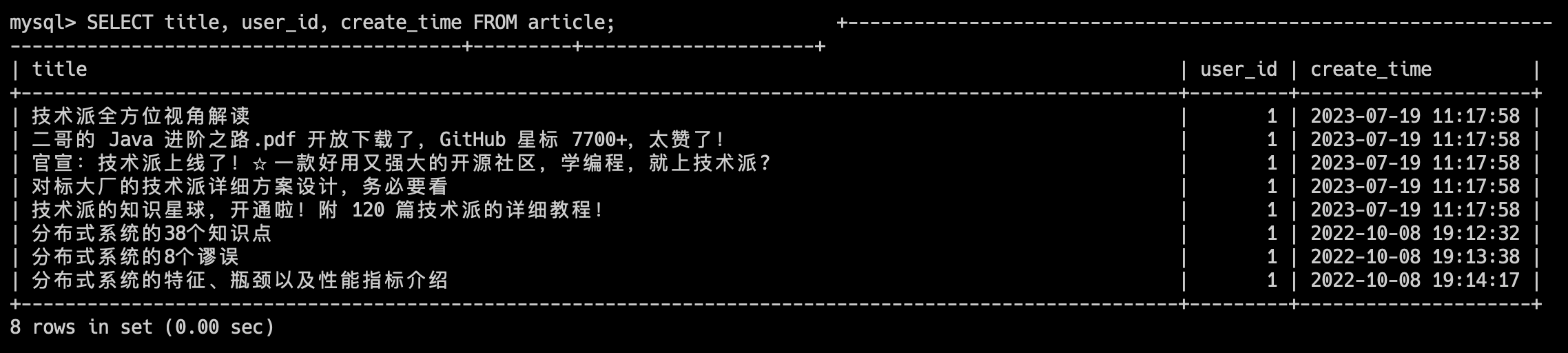
当结果集中需要查询所有字段时,可以使用 * 通配符进行查询,格式如下所示:
SELECT * FROM 表名;比如说,我们想要查看 article 表的所有字段,那查询语句就是:
SELECT * FROM article;由于某些字段的内容较多,我们可以使用 \G 来查看结果集。
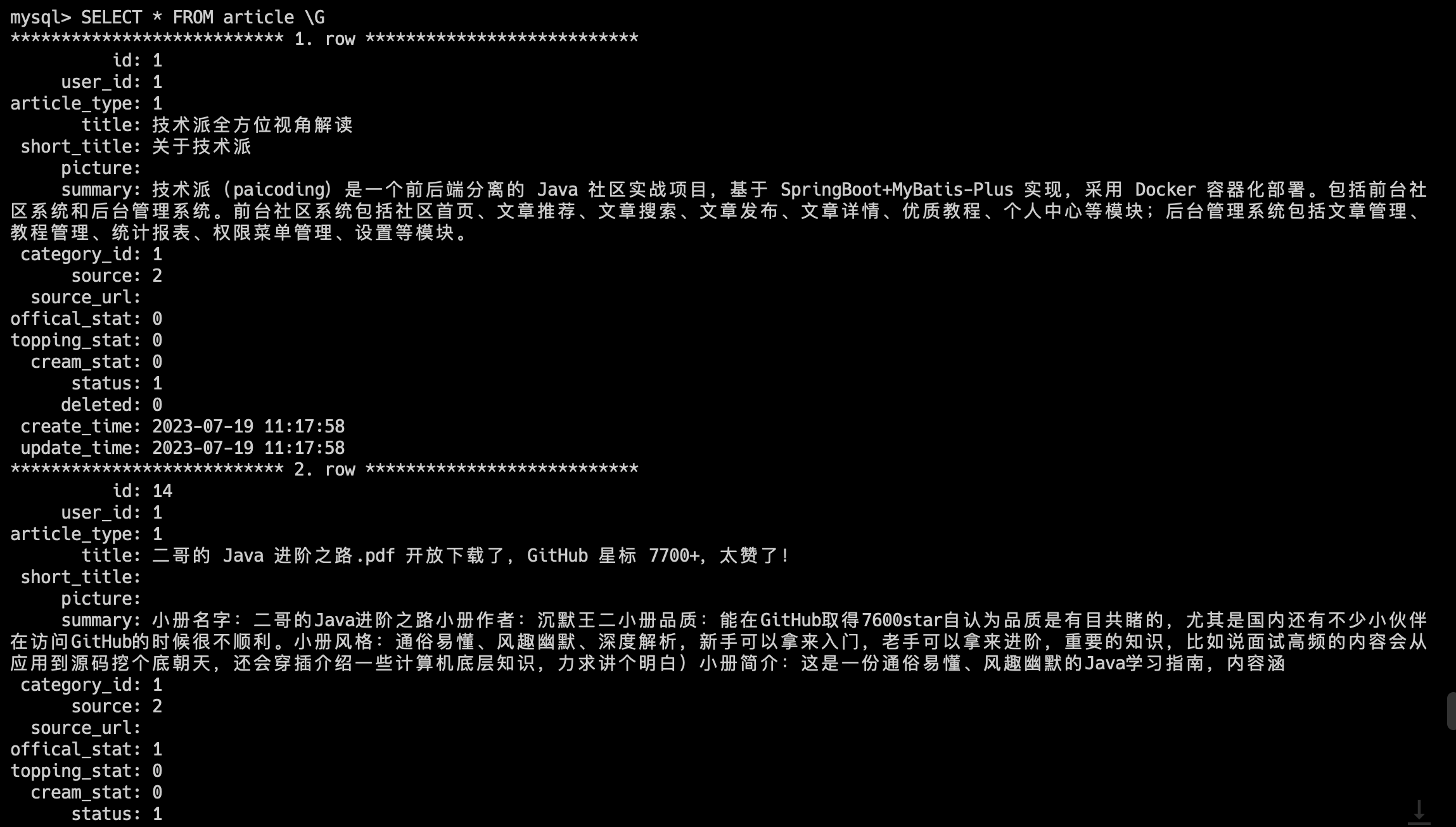
说到 * 通配符,就必须得提一嘴 SELECT COUNT(*) 和 SELECT COUNT(字段名),以及 SELECT COUNT(1),是面试中经常考察的一个知识点,我们后面会专门抽出来一篇帖子来讲,这里先放个传送门。
COUNT(*)、COUNT(字段名)、COUNT(1) 之间的区别
当然了,并不建议使用 * 通配符,因为这样会导致查询出来的字段过多,而且不利于程序的性能优化,尽量按需查询字段,就是当前需要什么字段就查询什么字段,不够用的话,再添加字段。
从根源上减轻数据传输的负载,是我们在编写代码时应该遵守的好习惯。
当结果集中需要去重时,可以使用 DISTINCT 关键字进行查询,格式如下所示:
SELECT DISTINCT 字段名 FROM 表名;比如说,我们想要查看 tag 表的所有标签,那查询语句就是:
SELECT DISTINCT tag_name FROM tag;
当结果集中需要排序时,可以使用 ORDER BY 关键字进行查询,格式如下所示:
SELECT 字段名 FROM 表名 ORDER BY 字段名 [ASC|DESC];ASC 是升序,DESC 是降序,默认是升序。
比如说,我们想要查看 article 表的 title 字段,并按照 create_time 字段进行降序排序,那查询语句就是:
SELECT title,create_time FROM article ORDER BY create_time DESC;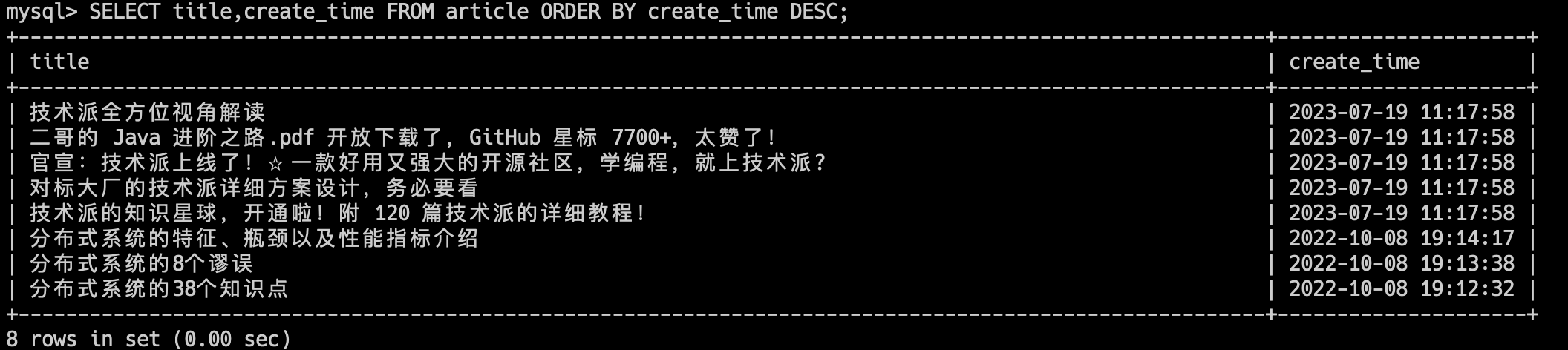
如果需要按照多个字段排序,可以使用逗号 , 分隔字段进行排序。
SELECT 字段1, 字段2 FROM 表名 ORDER BY 字段1 [ASC|DESC], 字段2 [ASC|DESC];比如说,我们想要查看 article 表的 title 字段,并按照 create_time 字段进行降序排序,如果 create_time 字段相同的话,再按照 update_time 字段进行升序排序,那查询语句就是:
SELECT title,create_time,update_time FROM article ORDER BY create_time DESC, update_time ASC;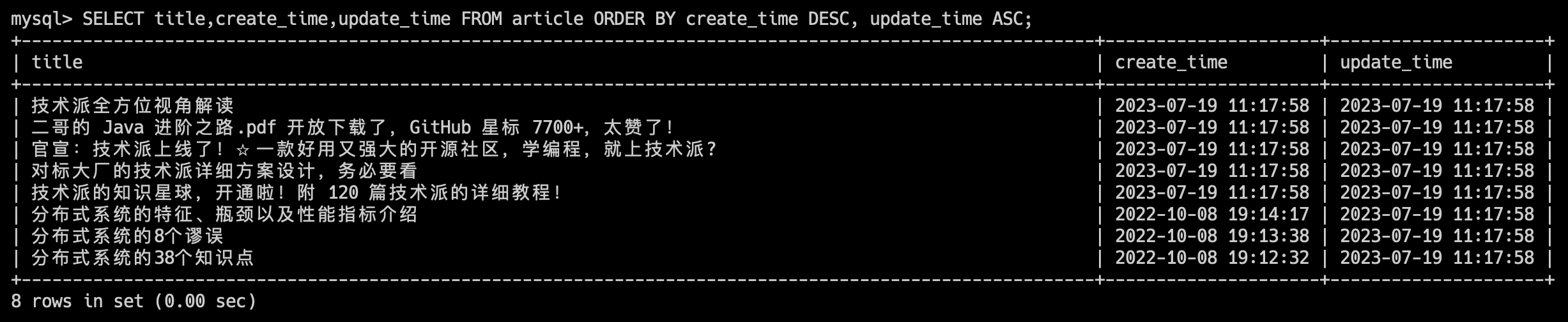
当结果集中需要限制返回的行数时,可以使用 LIMIT 关键字进行查询,格式如下所示:
SELECT 字段名 FROM 表名 LIMIT 开始行,行数;开始行也叫偏移量(OFFSET),默认是 0,可以缺省。
比如说,我们想要查看 article 表的 title 字段,并限制返回 5 条数据,那查询语句就是:
SELECT title FROM article LIMIT 5;LIMIT 对于分页查询非常有用,比如说,我们想要查看 article 表的 title 字段,并限制返回 5 条数据,从第 6 条数据开始,那查询语句就是:
SELECT title FROM article LIMIT 5,5;开始行为 5 是因为数据集在计数的时候是以 0 开始的。

不过,使用 LIMIT 和大偏移量(OFFSET)进行分页时,MySQL 需要读取从开始到偏移量指定的行数的所有数据,然后丢弃前面所有的行,只返回指定范围内的数据。这意味着,随着 OFFSET 值的增加,性能会逐渐下降。对于大数据量的表,这会导致查询变得非常慢。
这里我们也留一个传送门:
MySQL 分页查询:为什么 LIMIT OFFSET 性能会逐渐下降?
今天我们学习了 MySQL 的简单查询,主要包括了查询单个字段、查询多个字段、查询所有字段、查询结果去重、查询结果排序、查询结果限制条数。
虽然很基础,但留了两个需要深度探讨的知识点,一个是 COUNT(*)、COUNT(字段名)、COUNT(1) 之间的区别,另一个是 LIMIT OFFSET 性能逐渐下降的原因。
这些简单查询在日常开发中其实已经不需要我们手动去实现了,因为有很多持久层框架会帮我们做这些事情。
比如说,技术派当中就使用了 MyBatis-Plus 框架,它提供了很多便捷的查询方法,比如说 selectById、selectList、selectPage 等等,这些方法都是基于 SELECT 语句的封装。
大家如果对 MyBatis-Plus 的源码感兴趣的话,可以研究一下它的 selectById 方法,看看它是如何封装 SELECT 语句的。
虽然有持久层框架的帮助,但我们还是需要掌握 SQL 语句的基本用法,因为有些复杂的查询,持久层框架可能无法满足我们的需求,这时候就需要我们手动编写 SQL 语句了。
好了,今天的内容就到这里,希望新手都能够按照教程实操一遍,加深对 SELECT 语句的理解。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
