| title | weight | catalog | date | subtitle | header-img | tags | catagories | ||
|---|---|---|---|---|---|---|---|---|---|
Pod调度 |
6 |
true |
2017-08-13 03:50:57 -0700 |
|
|
在kubernetes集群中,Pod(container)是应用的载体,一般通过RC、Deployment、DaemonSet、Job等对象来完成Pod的调度与自愈功能。
RC的功能即保持集群中始终运行着指定个数的Pod。
在调度策略上主要有:
- 系统内置调度算法[最优Node]
- NodeSelector[定向调度]
- NodeAffinity[亲和性调度]
k8s中kube-scheduler负责实现Pod的调度,内部系统通过一系列算法最终计算出最佳的目标节点。如果需要将Pod调度到指定Node上,则可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配来达到目的。
1、kubectl label nodes {node-name} {label-key}={label-value}
2、nodeSelector: {label-key}:{label-value}
如果给多个Node打了相同的标签,则scheduler会根据调度算法从这组Node中选择一个可用的Node来调度。
如果Pod的nodeSelector的标签在Node中没有对应的标签,则该Pod无法被调度成功。
Node标签的使用场景:
对集群中不同类型的Node打上不同的标签,可控制应用运行Node的范围。例如role=frontend;role=backend;role=database。
NodeAffinity意为Node亲和性调度策略,NodeSelector为精确匹配,NodeAffinity为条件范围匹配,通过In(属于)、NotIn(不属于)、Exists(存在一个条件)、DoesNotExist(不存在)、Gt(大于)、Lt(小于)等操作符来选择Node,使调度更加灵活。
- RequiredDuringSchedulingRequiredDuringExecution:类似于NodeSelector,但在Node不满足条件时,系统将从该Node上移除之前调度上的Pod。
- RequiredDuringSchedulingIgnoredDuringExecution:与上一个类似,区别是在Node不满足条件时,系统不一定从该Node上移除之前调度上的Pod。
- PreferredDuringSchedulingIgnoredDuringExecution:指定在满足调度条件的Node中,哪些Node应更优先地进行调度。同时在Node不满足条件时,系统不一定从该Node上移除之前调度上的Pod。
如果同时设置了NodeSelector和NodeAffinity,则系统将需要同时满足两者的设置才能进行调度。
DaemonSet是kubernetes1.2版本新增的一种资源对象,用于管理在集群中每个Node上仅运行一份Pod的副本实例。

该用法适用的应用场景:
- 在每个Node上运行一个GlusterFS存储或者Ceph存储的daemon进程。
- 在每个Node上运行一个日志采集程序:fluentd或logstach。
- 在每个Node上运行一个健康程序,采集该Node的运行性能数据,例如:Prometheus Node Exportor、collectd、New Relic agent或Ganglia gmond等。
DaemonSet的Pod调度策略与RC类似,除了使用系统内置算法在每台Node上进行调度,也可以通过NodeSelector或NodeAffinity来指定满足条件的Node范围进行调度。
kubernetes从1.2版本开始支持批处理类型的应用,可以通过kubernetes Job资源对象来定义并启动一个批处理任务。批处理任务通常并行(或串行)启动多个计算进程去处理一批工作项(work item),处理完后,整个批处理任务结束。
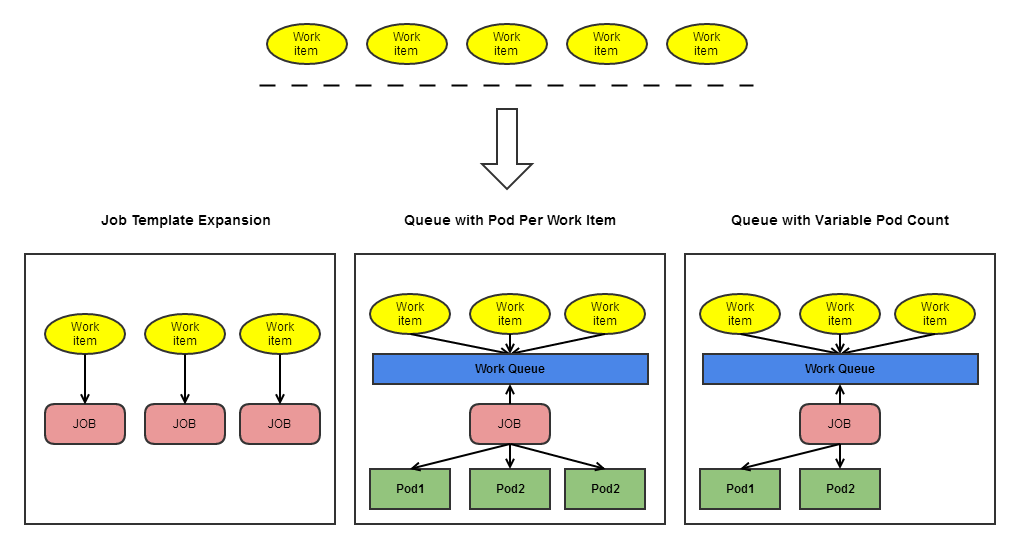
批处理按任务实现方式不同分为以下几种模式:
-
Job Template Expansion模式 一个Job对象对应一个待处理的Work item,有几个Work item就产生几个独立的Job,通过适用于Work item数量少,每个Work item要处理的数据量比较大的场景。例如有10个文件(Work item),每个文件(Work item)为100G。
-
Queue with Pod Per Work Item 采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,其中Job会启动N个Pod,每个Pod对应一个Work item。
-
Queue with Variable Pod Count 采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,其中Job会启动N个Pod,每个Pod对应一个Work item。但Pod的数量是可变的。
1)Non-parallel Jobs
通常一个Job只启动一个Pod,除非Pod异常才会重启该Pod,一旦此Pod正常结束,Job将结束。
2)Parallel Jobs with a fixed completion count
并行Job会启动多个Pod,此时需要设定Job的.spec.completions参数为一个正数,当正常结束的Pod数量达到该值则Job结束。
3)Parallel Jobs with a work queue
任务队列方式的并行Job需要一个独立的Queue,Work item都在一个Queue中存放,不能设置Job的.spec.completions参数。
此时Job的特性:
- 每个Pod能独立判断和决定是否还有任务项需要处理
- 如果某个Pod正常结束,则Job不会再启动新的Pod
- 如果一个Pod成功结束,则此时应该不存在其他Pod还在干活的情况,它们应该都处于即将结束、退出的状态
- 如果所有的Pod都结束了,且至少一个Pod成功结束,则整个Job算是成功结束
参考文章
- 《Kubernetes权威指南》