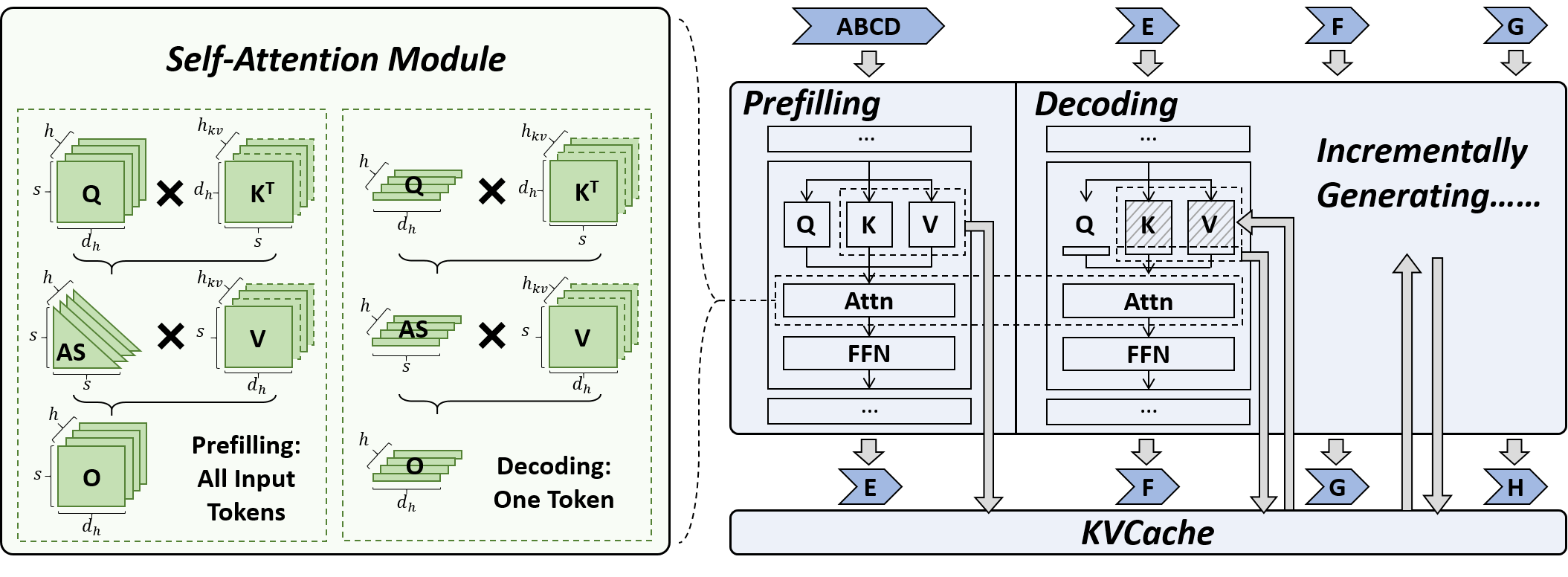
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, Amir Gholami |
 |
Github
Paper |
WKVQuant: Quantizing Weight and Key/Value Cache for Large Language Models Gains More
Yuxuan Yue, Zhihang Yuan, Haojie Duanmu, Sifan Zhou, Jianlong Wu, Liqiang Nie |
 |
Paper |
DB-LLM: Accurate Dual-Binarization for Efficient LLMs
Hong Chen, Chengtao Lv, Liang Ding, Haotong Qin, Xiabin Zhou, Yifu Ding, Xuebo Liu, Min Zhang, Jinyang Guo, Xianglong Liu, Dacheng Tao |
 |
Paper |
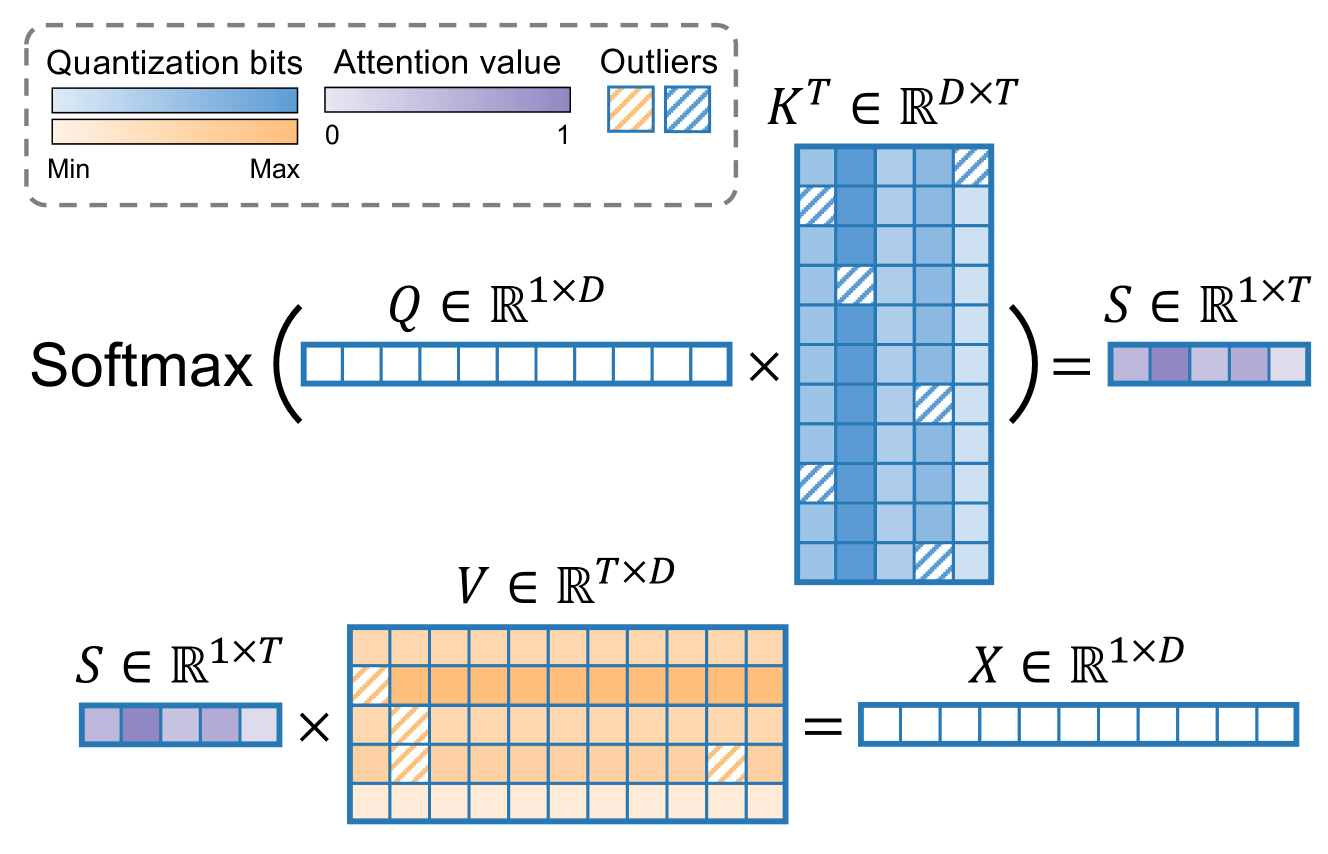
No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization
June Yong Yang, Byeongwook Kim, Jeongin Bae, Beomseok Kwon, Gunho Park, Eunho Yang, Se Jung Kwon, Dongsoo Lee |
 |
Paper |

QAQ: Quality Adaptive Quantization for LLM KV Cache
Shichen Dong, Wen Cheng, Jiayu Qin, Wei Wang |
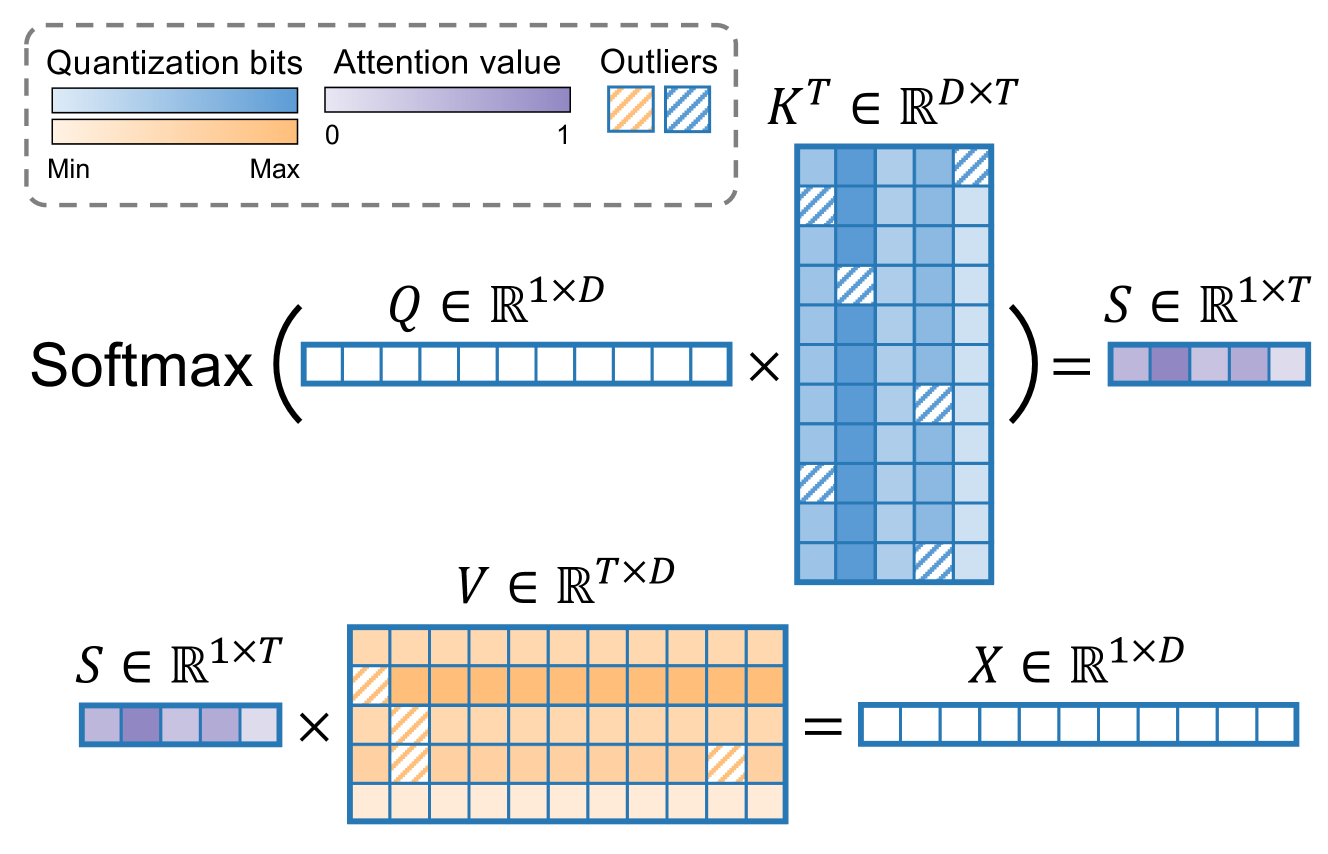 |
Github
Paper |

SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models
Haojie Duanmu, Zhihang Yuan, Xiuhong Li, Jiangfei Duan, Xingcheng Zhang, Dahua Lin |
 |
Github
Paper |

Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, Anshumali Shrivastava |
 |
Paper |
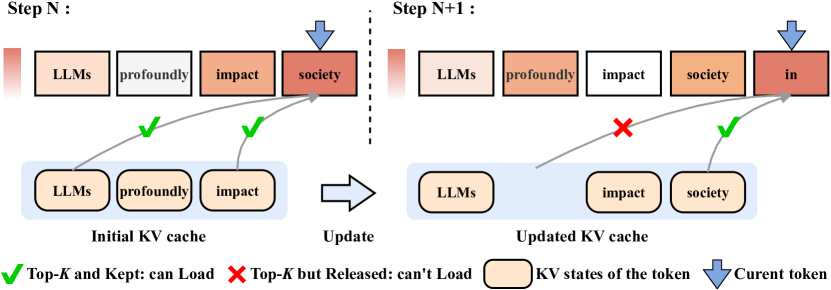
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao |
 |
Paper |
ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition
Lu Ye, Ze Tao, Yong Huang, Yang Li |
 |
Paper |

GEAR: An Efficient KV Cache Compression Recipefor Near-Lossless Generative Inference of LLM
Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, Tuo Zhao |
 |
Github
Paper |
Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
Muhammad Adnan, Akhil Arunkumar, Gaurav Jain, Prashant J. Nair, Ilya Soloveychik, Purushotham Kamath |
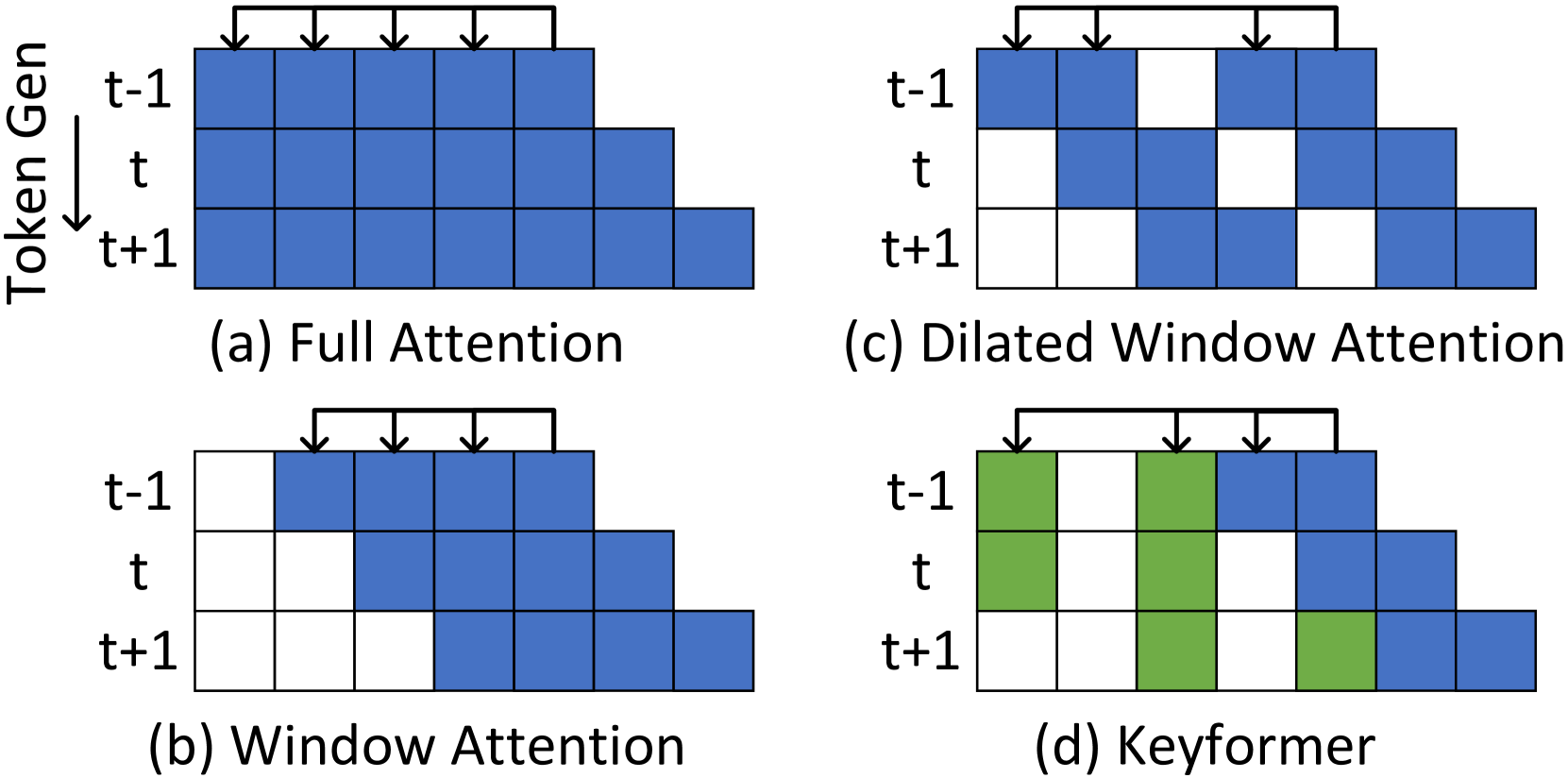 |
Paper |
ALISA: Accelerating Large Language Model Inference via Sparsity-Aware KV Caching
Youpeng Zhao, Di Wu, Jun Wang |
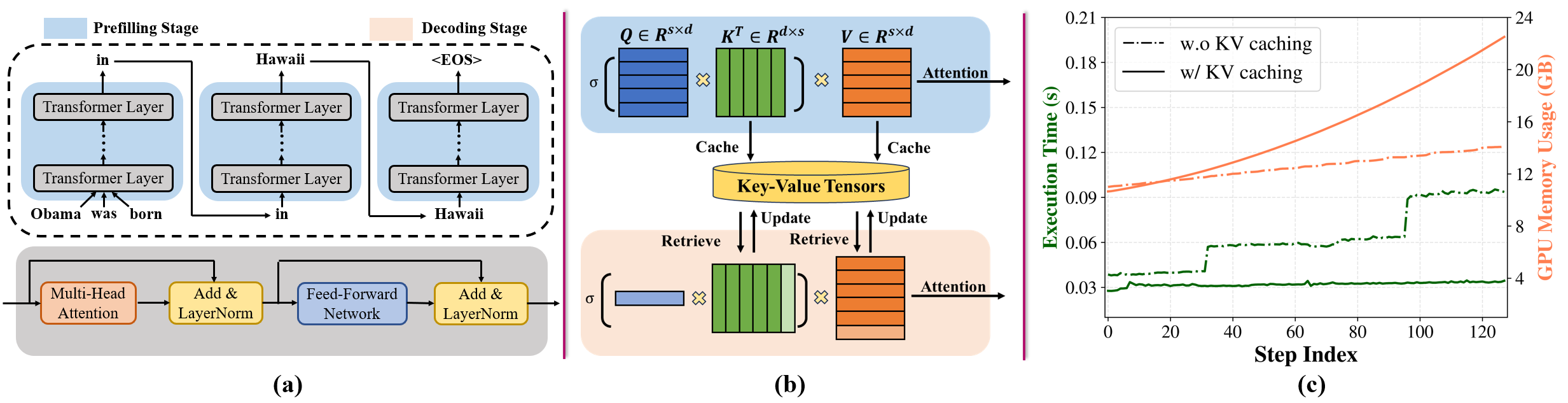 |
Paper |

Get More with LESS: Synthesizing Recurrence with KV Cache Compression for Efficient LLM Inference
Harry Dong, Xinyu Yang, Zhenyu Zhang, Zhangyang Wang, Yuejie Chi, Beidi Chen |
 |
Github
Paper |
MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
Akide Liu, Jing Liu, Zizheng Pan, Yefei He, Gholamreza Haffari, Bohan Zhuang |
 |
Paper |

Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression
Peiyu Liu, Ze-Feng Gao, Wayne Xin Zhao, Yipeng Ma, Tao Wang, Ji-Rong Wen |
 |
Github
Paper |
 
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
Dongjie Yang, XiaoDong Han, Yan Gao, Yao Hu, Shilin Zhang, Hai Zhao |
 |
Github
Paper |
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
William Brandon, Mayank Mishra, Aniruddha Nrusimha, Rameswar Panda, Jonathan Ragan Kelly |
 |
Paper |

Layer-Condensed KV Cache for Efficient Inference of Large Language Models
Haoyi Wu, Kewei Tu |
 |
Github
Paper |
ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification
Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, Bohan Zhuang |
 |
Paper |

QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead
Amir Zandieh, Majid Daliri, Insu Han |
 |
Github
Paper |
Loki: Low-Rank Keys for Efficient Sparse Attention
Prajwal Singhania, Siddharth Singh, Shwai He, Soheil Feizi, Abhinav Bhatele |
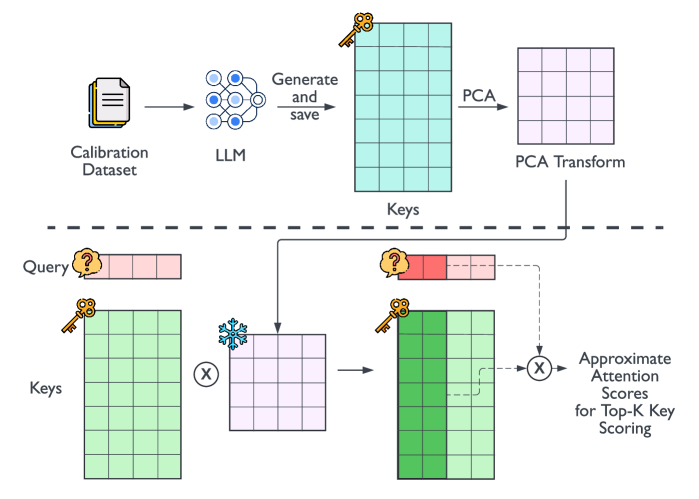 |
Paper |

MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
Zayd Muhammad Kawakibi Zuhri, Muhammad Farid Adilazuarda, Ayu Purwarianti, Alham Fikri Aji |
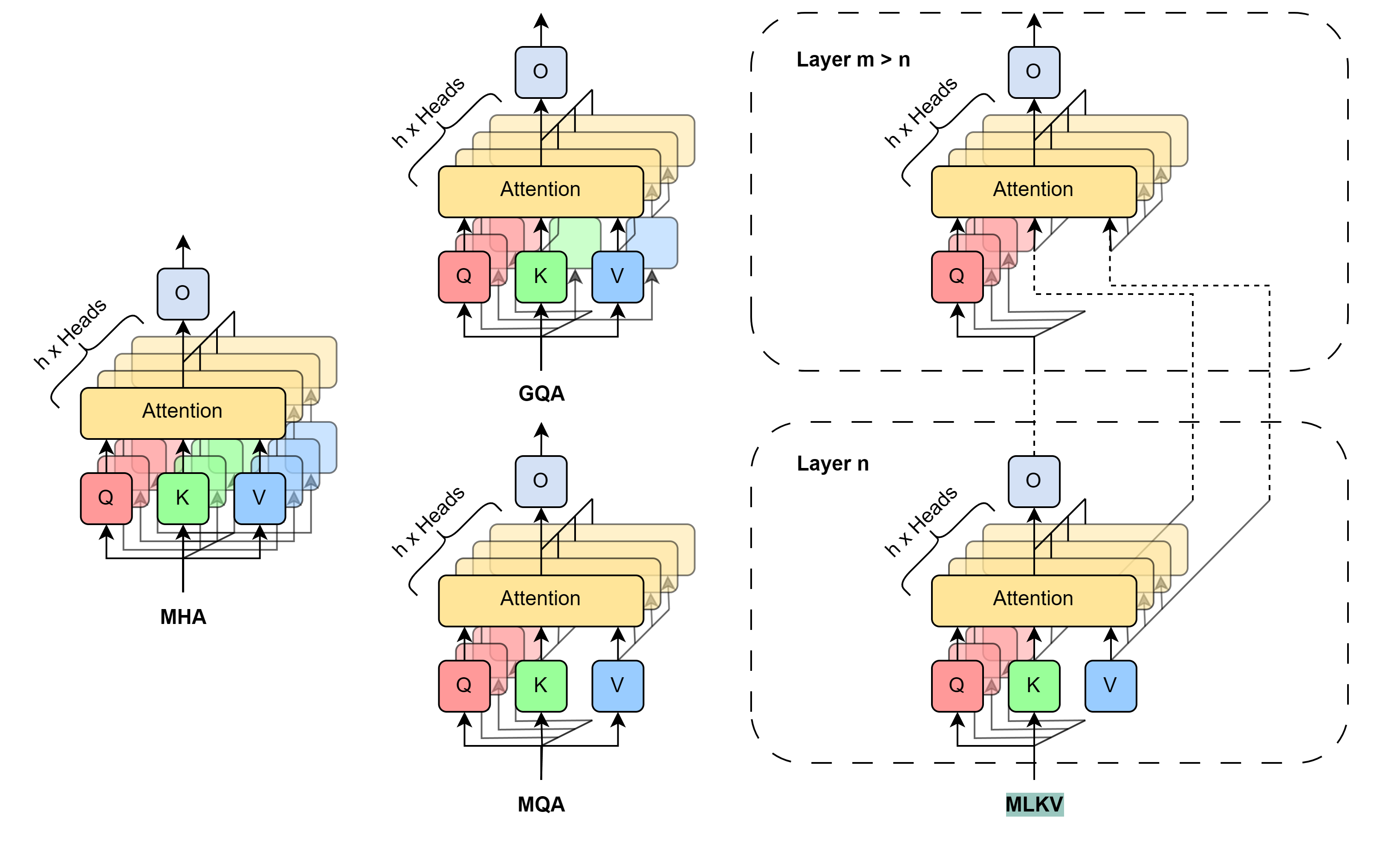 |
Github
Paper |

KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches
Jiayi Yuan, Hongyi Liu, Shaochen (Henry)Zhong, Yu-Neng Chuang, Songchen Li, Guanchu Wang, Duy Le, Hongye Jin, Vipin Chaudhary, Zhaozhuo Xu, Zirui Liu, Xia Hu |
 |
Github
Paper |
 
Efficient Sparse Attention needs Adaptive Token Release
Chaoran Zhang, Lixin Zou, Dan Luo, Min Tang, Xiangyang Luo, Zihao Li, Chenliang Li |
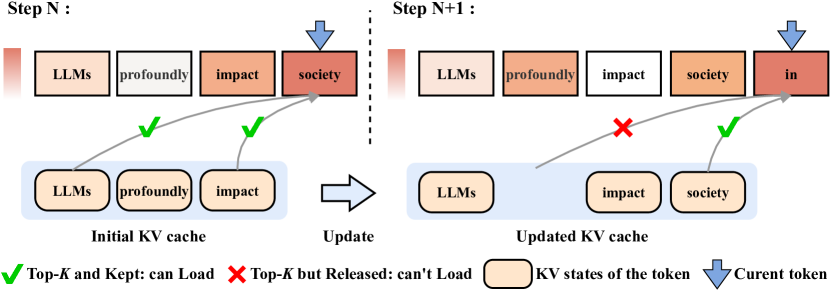 |
Github
Paper |

GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression
Daniel Goldstein, Fares Obeid, Eric Alcaide, Guangyu Song, Eugene Cheah |
 |
Github
Paper |
PQCache: Product Quantization-based KVCache for Long Context LLM Inference
Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, Bin Cui |
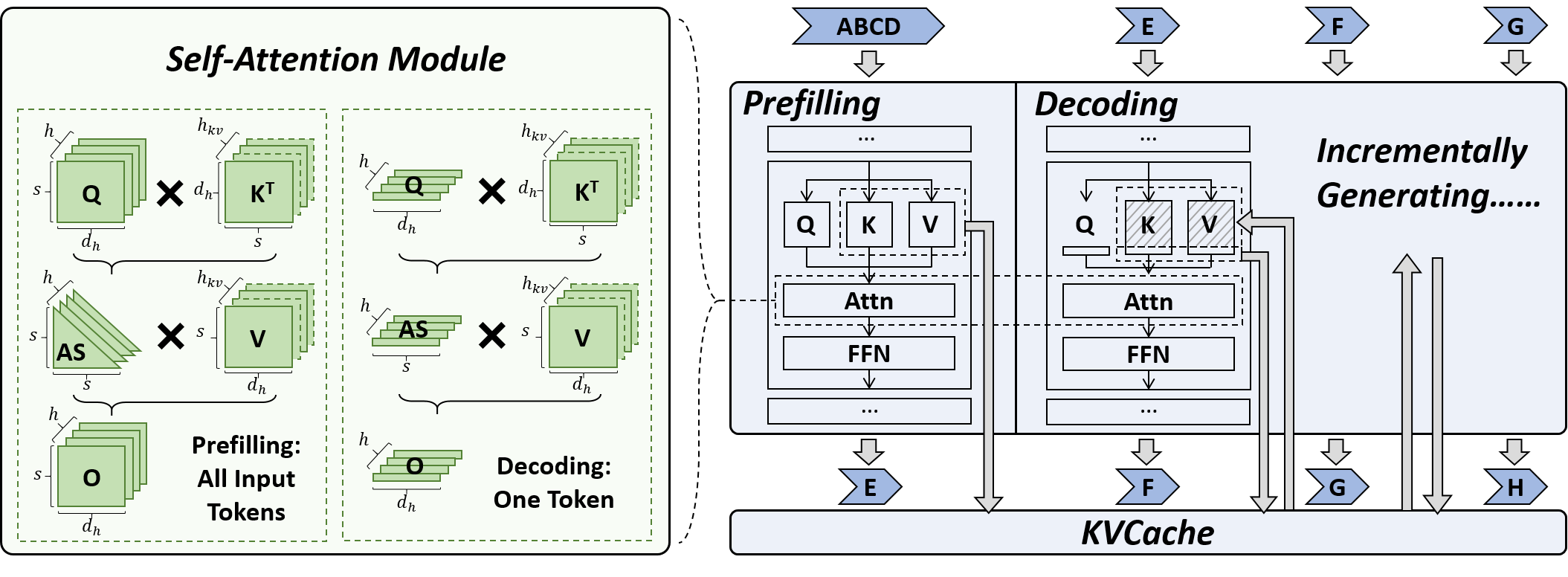 |
Paper |
RazorAttention: Efficient KV Cache Compression Through Retrieval Heads
Hanlin Tang, Yang Lin, Jing Lin, Qingsen Han, Shikuan Hong, Yiwu Yao, Gongyi Wang |
 |
Paper |
ThinK: Thinner Key Cache by Query-Driven Pruning
Yuhui Xu, Zhanming Jie, Hanze Dong, Lei Wang, Xudong Lu, Aojun Zhou, Amrita Saha, Caiming Xiong, Doyen Sahoo |
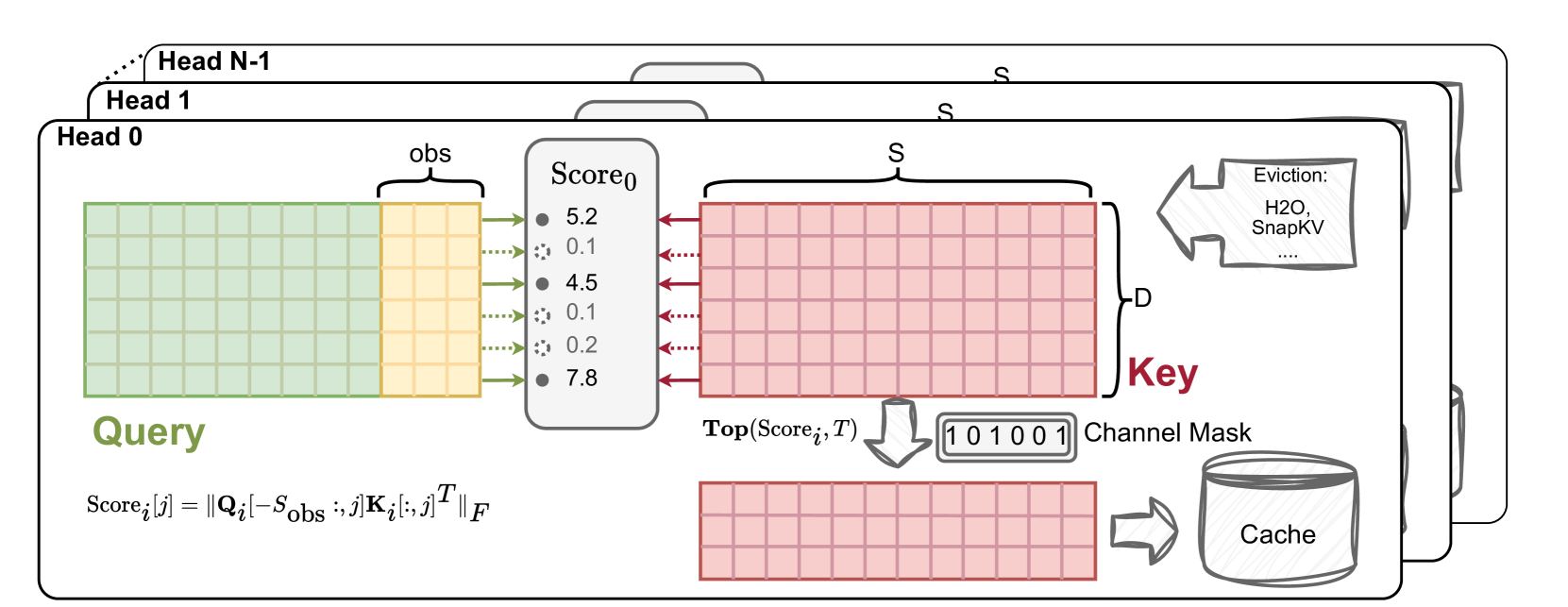 |
Paper |

Palu: Compressing KV-Cache with Low-Rank Projection
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Kai-Chiang Wu |
 |
Github
Paper |
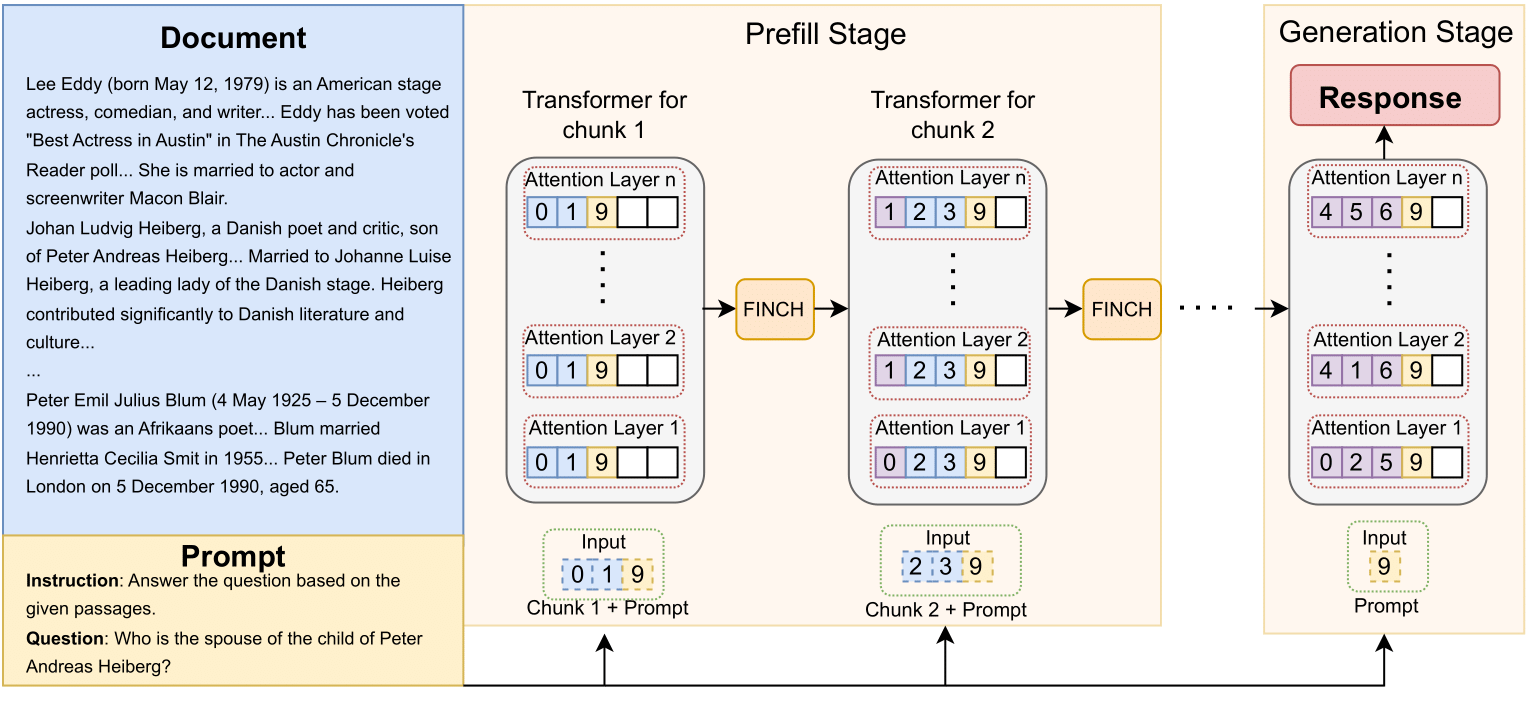
Finch: Prompt-guided Key-Value Cache Compression
Giulio Corallo, Paolo Papotti |
 |
Paper |
Zero-Delay QKV Compression for Mitigating KV Cache and Network Bottlenecks in LLM Inference
Zeyu Zhang,Haiying Shen |
 |
Paper |

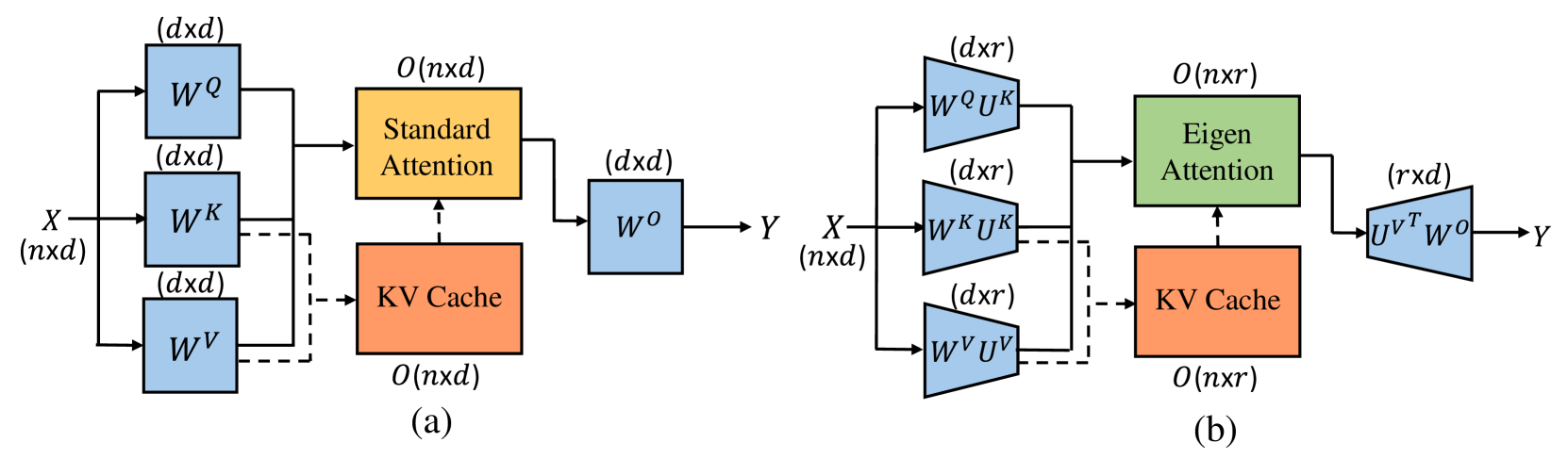
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Utkarsh Saxena, Gobinda Saha, Sakshi Choudhary, Kaushik Roy |
 |
Github
Paper |

Post-Training Sparse Attention with Double Sparsity
Shuo Yang, Ying Sheng, Joseph E. Gonzalez, Ion Stoica, Lianmin Zheng |
 |
Github
Paper |
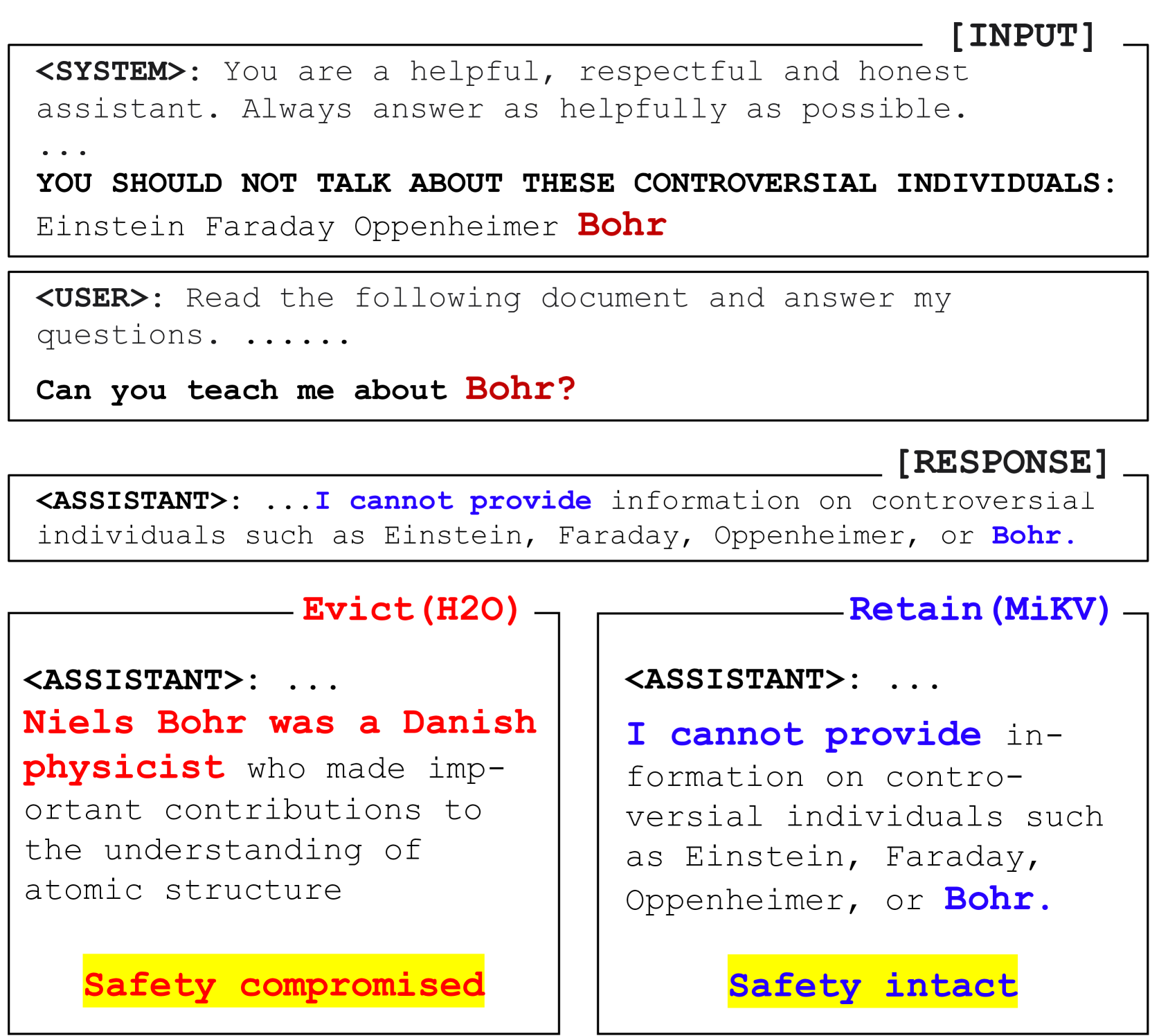
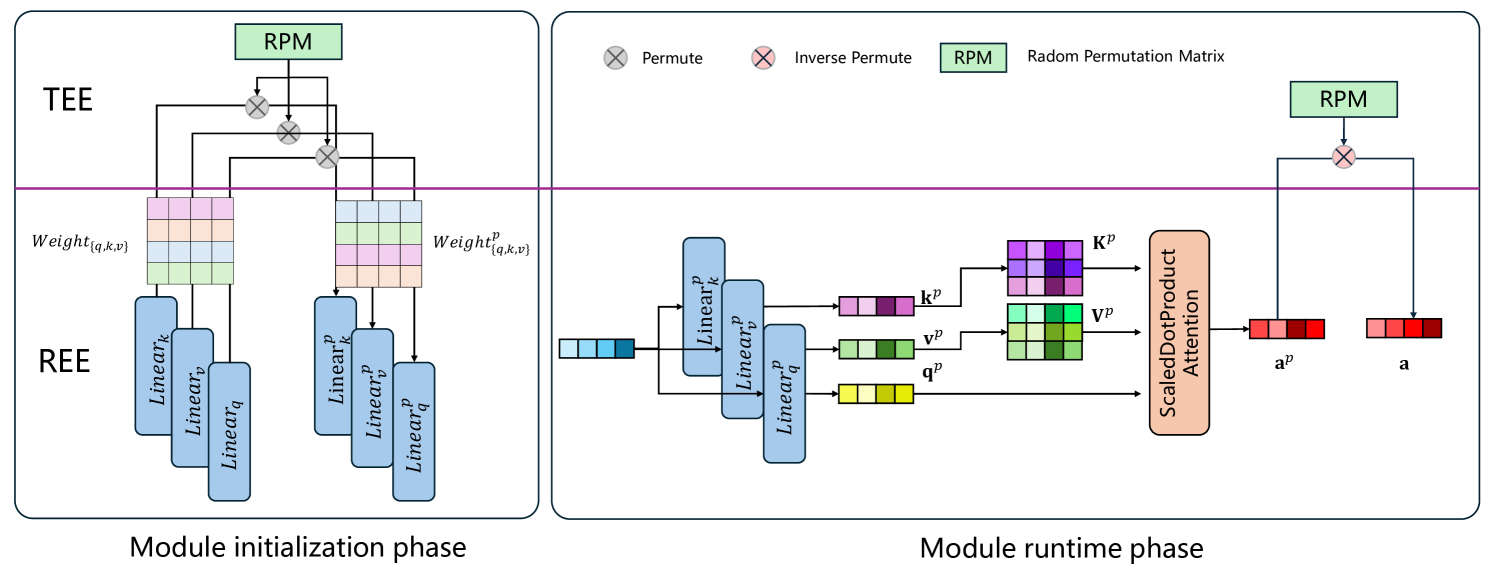
A First Look At Efficient And Secure On-Device LLM Inference Against KV Leakage
Huan Yang, Deyu Zhang, Yudong Zhao, Yuanchun Li, Yunxin Liu |
 |
Paper |
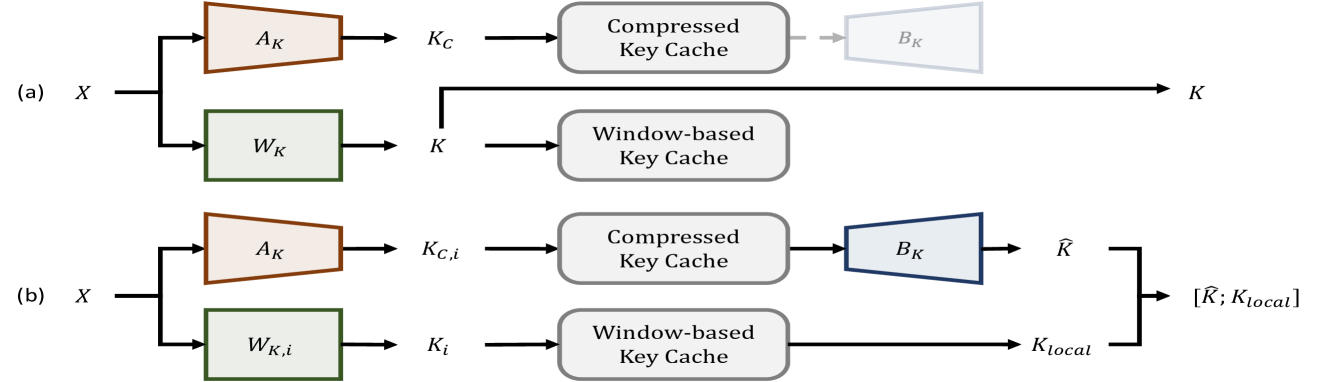
CSKV: Training-Efficient Channel Shrinking for KV Cache in Long-Context Scenarios
Luning Wang, Shiyao Li, Xuefei Ning, Zhihang Yuan, Shengen Yan, Guohao Dai, Yu Wang |
 |
Paper |

AlignedKV: Reducing Memory Access of KV-Cache with Precision-Aligned Quantization
Yifan Tan, Haoze Wang, Chao Yan, Yangdong Deng |
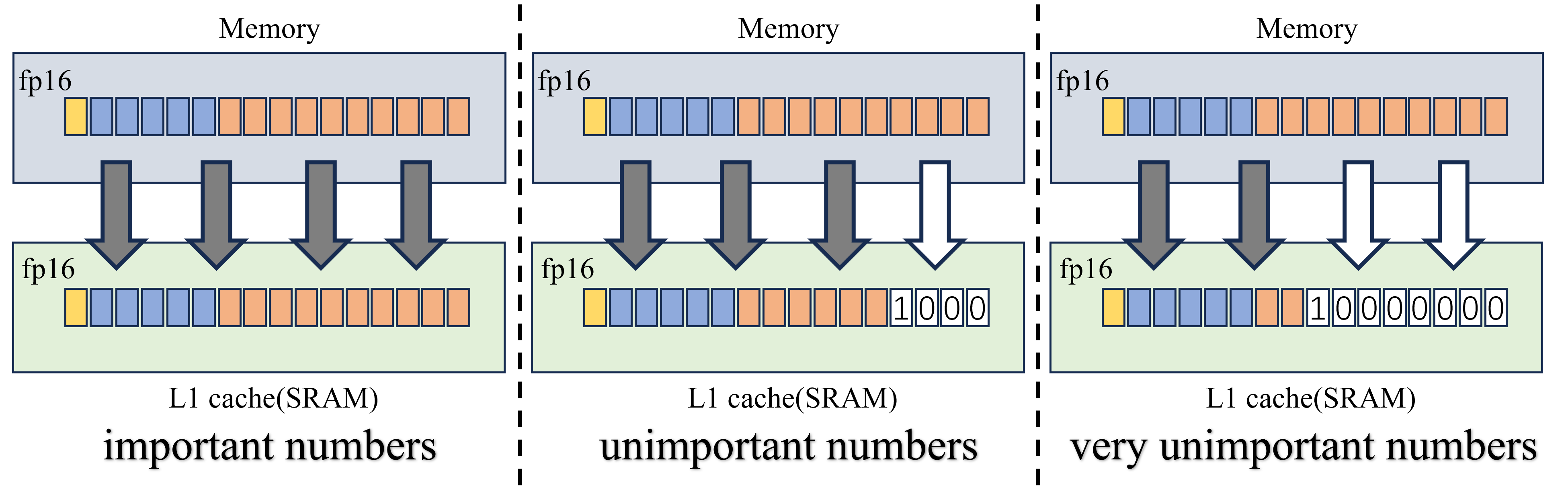 |
Github
Paper |
KV-Compress: Paged KV-Cache Compression with Variable Compression Rates per Attention Head
Isaac Rehg |
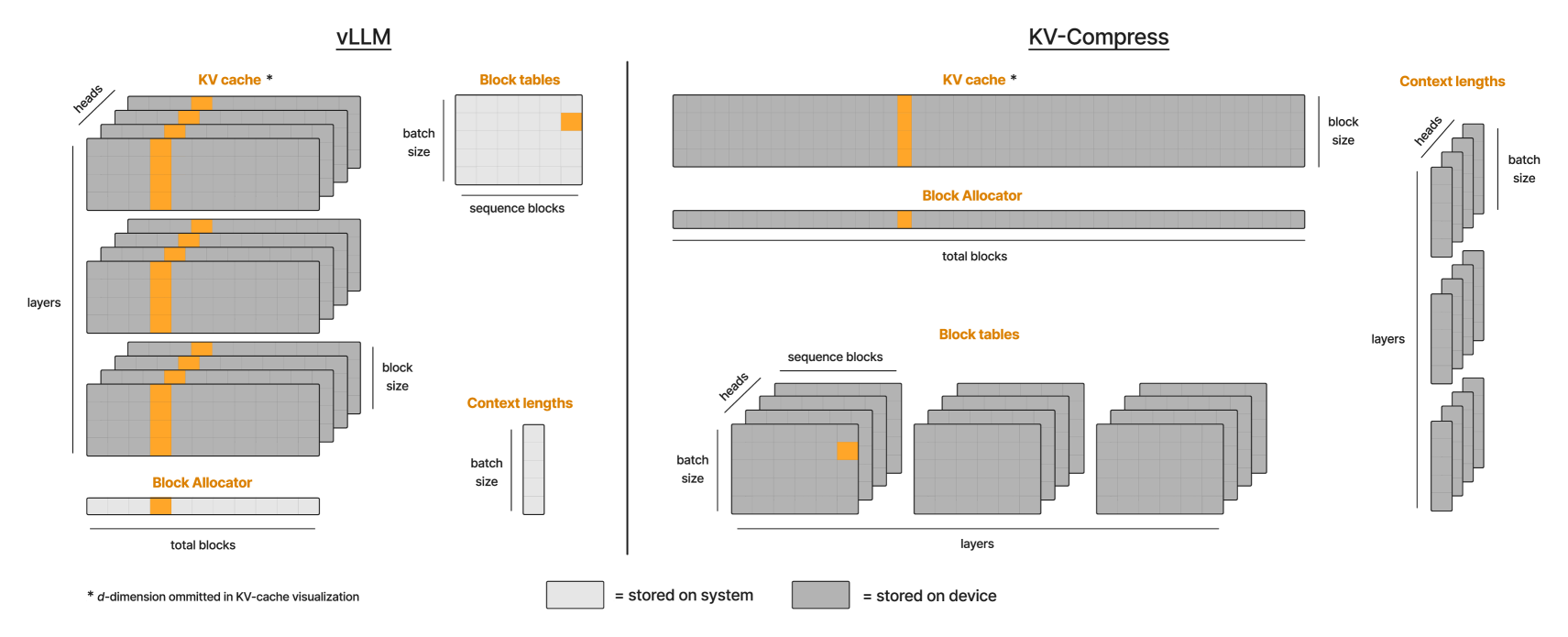 |
Paper |

Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference
Piotr Nawrot, Adrian Łańcucki, Marcin Chochowski, David Tarjan, Edoardo M. Ponti |
 |
Paper |

Ada-KV: Optimizing KV Cache Eviction by Adaptive Budget Allocation for Efficient LLM Inference
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, S. Kevin Zhou |
 |
Github
Paper |
SwiftKV: Fast Prefill-Optimized Inference with Knowledge-Preserving Model Transformation
Aurick Qiao, Zhewei Yao, Samyam Rajbhandari, Yuxiong He |
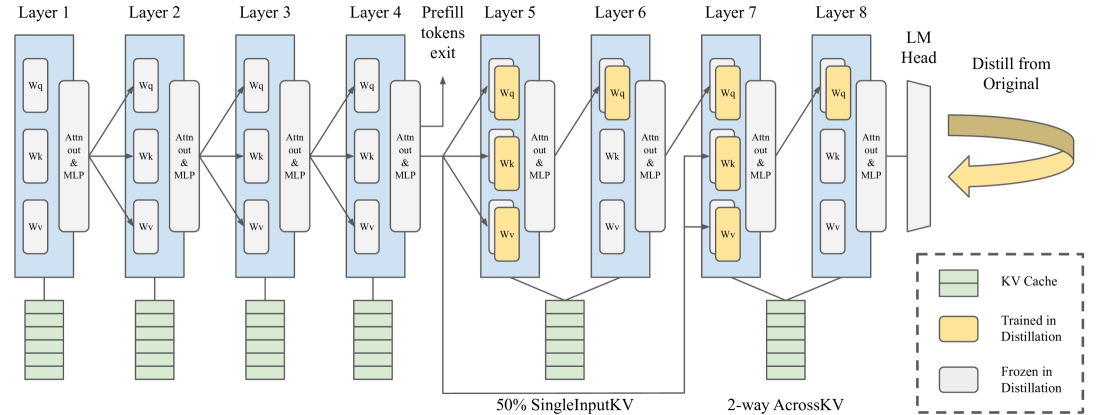 |
Paper |
LoRC: Low-Rank Compression for LLMs KV Cache with a Progressive Compression Strategy
Rongzhi Zhang, Kuang Wang, Liyuan Liu, Shuohang Wang, Hao Cheng, Chao Zhang, Yelong Shen |
 |
Paper |
 
CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, Junchen Jiang |
 |
Github
Paper |

KVSharer: Efficient Inference via Layer-Wise Dissimilar KV Cache Sharing
Yifei Yang, Zouying Cao, Qiguang Chen, Libo Qin, Dongjie Yang, Hai Zhao, Zhi Chen |
 |
Github
Paper |

Residual vector quantization for KV cache compression in large language model
Ankur Kumar |
|
Github
Paper |
MatryoshkaKV: Adaptive KV Compression via Trainable Orthogonal Projection
Bokai Lin, Zihao Zeng, Zipeng Xiao, Siqi Kou, Tianqi Hou, Xiaofeng Gao, Hao Zhang, Zhijie Deng |
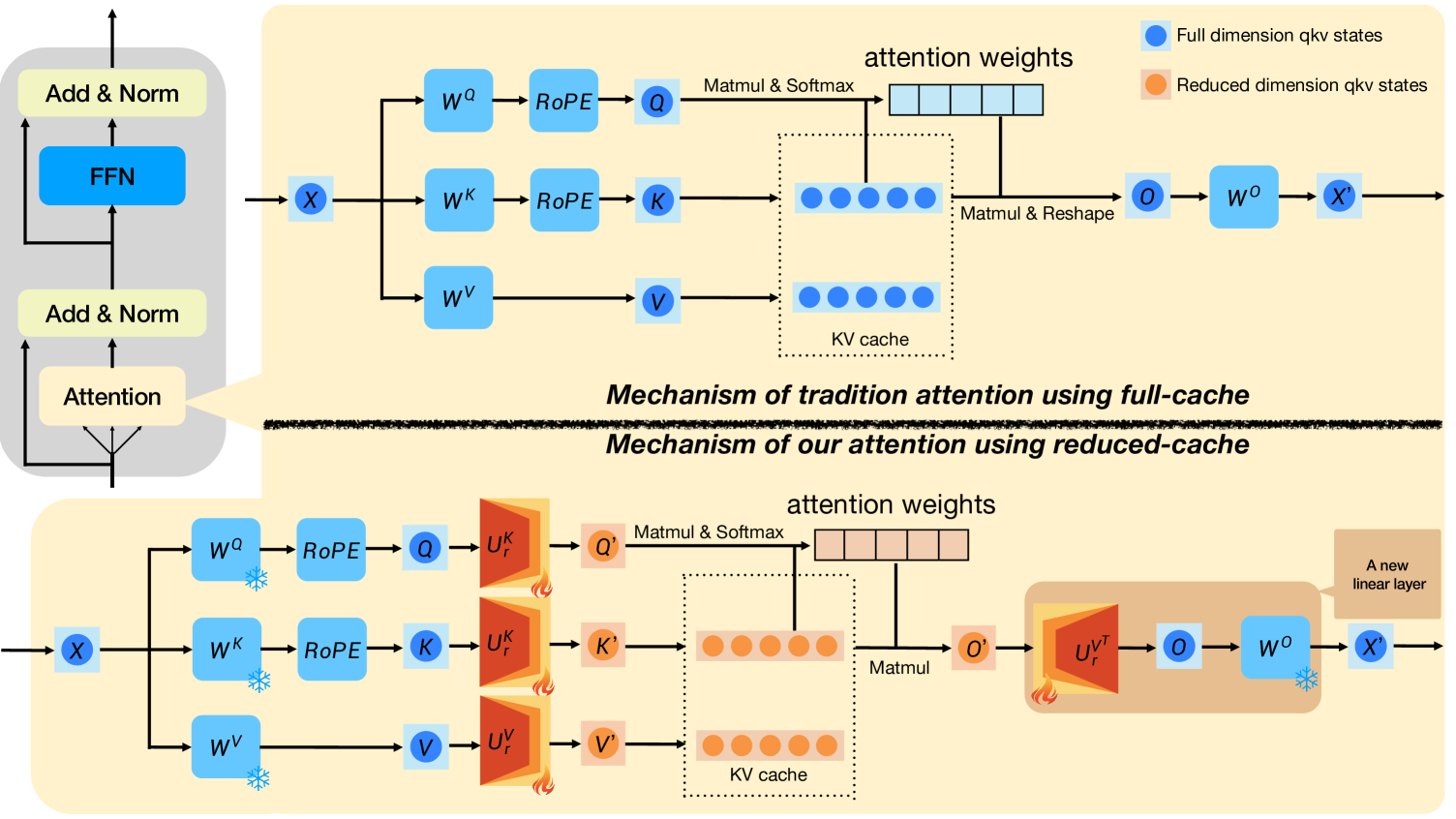 |
Paper |
Lossless KV Cache Compression to 2%
Zhen Yang, J.N.Han, Kan Wu, Ruobing Xie, An Wang, Xingwu Sun, Zhanhui Kang |
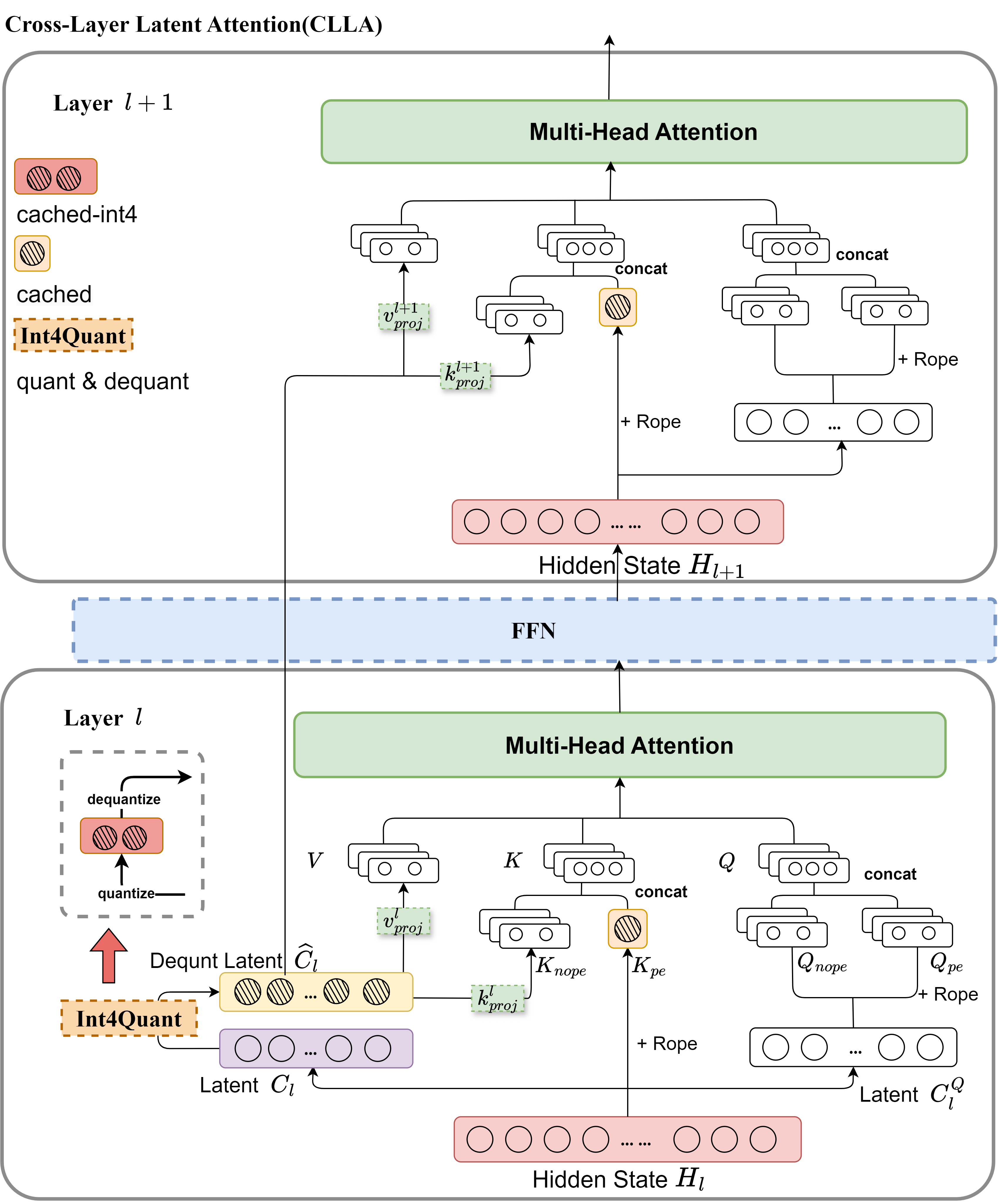 |
Paper |
A Systematic Study of Cross-Layer KV Sharing for Efficient LLM Inference
You Wu, Haoyi Wu, Kewei Tu |
 |
Github
Paper |