| category | tag | title | ||
|---|---|---|---|---|
|
|
微服务网关:从对比到选型,由理论到实践 |
微服务近几年非常火,围绕微服务的技术生态也比较多,比如微服务网关、Docker、Kubernetes等。
我是于2019年开始接触微服务网关,当时和公司的一位同事一起开发,由于技术能力有限,我只负责网关后台,后续微服务网关的迭代,我其实没有参与,不过后来抽空看了微服务网关前台的代码,所以对这套微服务网关的实现原理算是基本掌握。
最近在写技术栈相关的文章,刚好写到微服务网关,就把之前学习的知识进行简单总结,同时也把市面上常用的微服务网关进行梳理,一方面便于后续技术选型,另一方面也算是给自己一个交代。下面是文章目录:

API网关是一个服务器,是系统的唯一入口。 从面向对象设计的角度看,它与外观模式类似。
API网关封装了系统内部架构,为每个客户端提供一个定制的API。它可能还具有其它职责,如身份验证、监控、负载均衡、缓存、协议转换、限流熔断、静态响应处理。
API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。通常,网关也是提供REST/HTTP的访问API。
微服务网关作为微服务后端服务的统一入口,它可以统筹管理后端服务,主要分为数据平面和控制平面:
- 数据平面主要功能是接入用户的HTTP请求和微服务被拆分后的聚合。使用微服务网关统一对外暴露后端服务的API和契约,路由和过滤功能正是网关的核心能力模块。另外,微服务网关可以实现拦截机制和专注跨横切面的功能,包括协议转换、安全认证、熔断限流、灰度发布、日志管理、流量监控等。
- 控制平面主要功能是对后端服务做统一的管控和配置管理。例如,可以控制网关的弹性伸缩;可以统一下发配置;可以对网关服务添加标签;可以在微服务网关上通过配置Swagger功能统一将后端服务的API契约暴露给使用方,完成文档服务,提高工作效率和降低沟通成本。
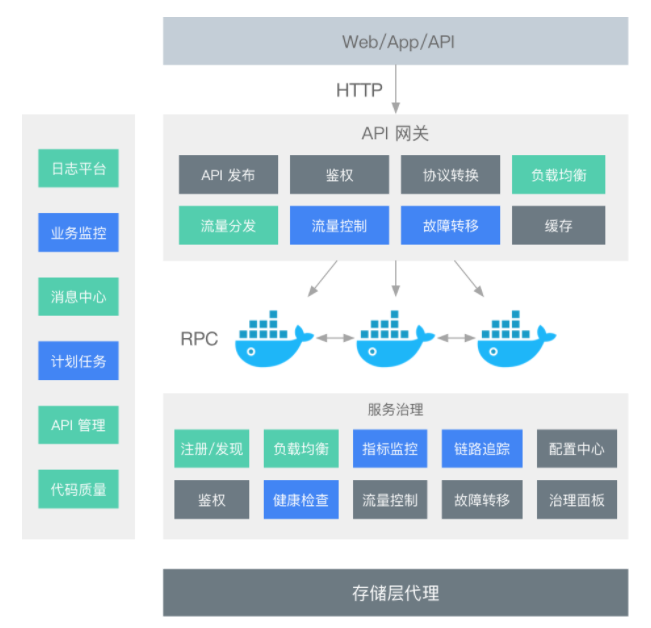
- 路由功能:路由是微服务网关的核心能力。通过路由功能微服务网关可以将请求转发到目标微服务。在微服务架构中,网关可以结合注册中心的动态服务发现,实现对后端服务的发现,调用方只需要知道网关对外暴露的服务API就可以透明地访问后端微服务。
- 负载均衡:API网关结合负载均衡技术,利用Eureka或者Consul等服务发现工具,通过轮询、指定权重、IP地址哈希等机制实现下游服务的负载均衡。
- 统一鉴权:一般而言,无论对内网还是外网的接口都需要做用户身份认证,而用户认证在一些规模较大的系统中都会采用统一的单点登录(Single Sign On)系统,如果每个微服务都要对接单点登录系统,那么显然比较浪费资源且开发效率低。API网关是统一管理安全性的绝佳场所,可以将认证的部分抽取到网关层,微服务系统无须关注认证的逻辑,只关注自身业务即可。
- 协议转换:API网关的一大作用在于构建异构系统,API网关作为单一入口,通过协议转换整合后台基于REST、AMQP、Dubbo等不同风格和实现技术的微服务,面向Web Mobile、开放平台等特定客户端提供统一服务。
- 指标监控:网关可以统计后端服务的请求次数,并且可以实时地更新当前的流量健康状态,可以对URL粒度的服务进行延迟统计,也可以使用Hystrix Dashboard查看后端服务的流量状态及是否有熔断发生。
- 限流熔断:在某些场景下需要控制客户端的访问次数和访问频率,一些高并发系统有时还会有限流的需求。在网关上可以配置一个阈值,当请求数超过阈值时就直接返回错误而不继续访问后台服务。当出现流量洪峰或者后端服务出现延迟或故障时,网关能够主动进行熔断,保护后端服务,并保持前端用户体验良好。
- 黑白名单:微服务网关可以使用系统黑名单,过滤HTTP请求特征,拦截异常客户端的请求,例如DDoS攻击等侵蚀带宽或资源迫使服务中断等行为,可以在网关层面进行拦截过滤。比较常见的拦截策略是根据IP地址增加黑名单。在存在鉴权管理的路由服务中可以通过设置白名单跳过鉴权管理而直接访问后端服务资源。
- 灰度发布:微服务网关可以根据HTTP请求中的特殊标记和后端服务列表元数据标识进行流量控制,实现在用户无感知的情况下完成灰度发布。
- 流量染色:和灰度发布的原理相似,网关可以根据HTTP请求的Host、Head、Agent等标识对请求进行染色,有了网关的流量染色功能,我们可以对服务后续的调用链路进行跟踪,对服务延迟及服务运行状况进行进一步的链路分析。
- 文档中心:网关结合Swagger,可以将后端的微服务暴露给网关,网关作为统一的入口给接口的使用方提供查看后端服务的API规范,不需要知道每一个后端微服务的Swagger地址,这样网关起到了对后端API聚合的效果。
- 日志审计:微服务网关可以作为统一的日志记录和收集器,对服务URL粒度的日志请求信息和响应信息进行拦截。
先简单看一下市面上常用的API网关:

Nginx是一个高性能的HTTP和反向代理服务器。Nginx一方面可以做反向代理,另外一方面可以做静态资源服务器,接口使用Lua动态语言可以完成灵活的定制功能。
Nginx 在启动后,会有一个 Master 进程和多个 Worker 进程,Master 进程和 Worker 进程之间是通过进程间通信进行交互的,如图所示。Worker 工作进程的阻塞点是在像 select()、epoll_wait() 等这样的 I/O 多路复用函数调用处,以等待发生数据可读 / 写事件。Nginx 采用了异步非阻塞的方式来处理请求,也就是说,Nginx 是可以同时处理成千上万个请求的。
Zuul 是 Netflix 开源的一个API网关组件,它可以和 Eureka、Ribbon、Hystrix 等组件配合使用。社区活跃,融合于 SpringCloud 完整生态,是构建微服务体系前置网关服务的最佳选型之一。
Zuul 的核心是一系列的过滤器,这些过滤器可以完成以下功能:
- 统一鉴权 + 动态路由 + 负载均衡 + 压力测试
- 审查与监控:与边缘位置追踪有意义的数据和统计结果,从而带来精确的生产视图。
- 多区域弹性:跨越 AWS Region 进行请求路由,旨在实现 ELB(Elastic Load Balancing,弹性负载均衡)使用的多样化,以及让系统的边缘更贴近系统的使用者。
Zuul 目前有两个大的版本:Zuul1 和 Zuul2
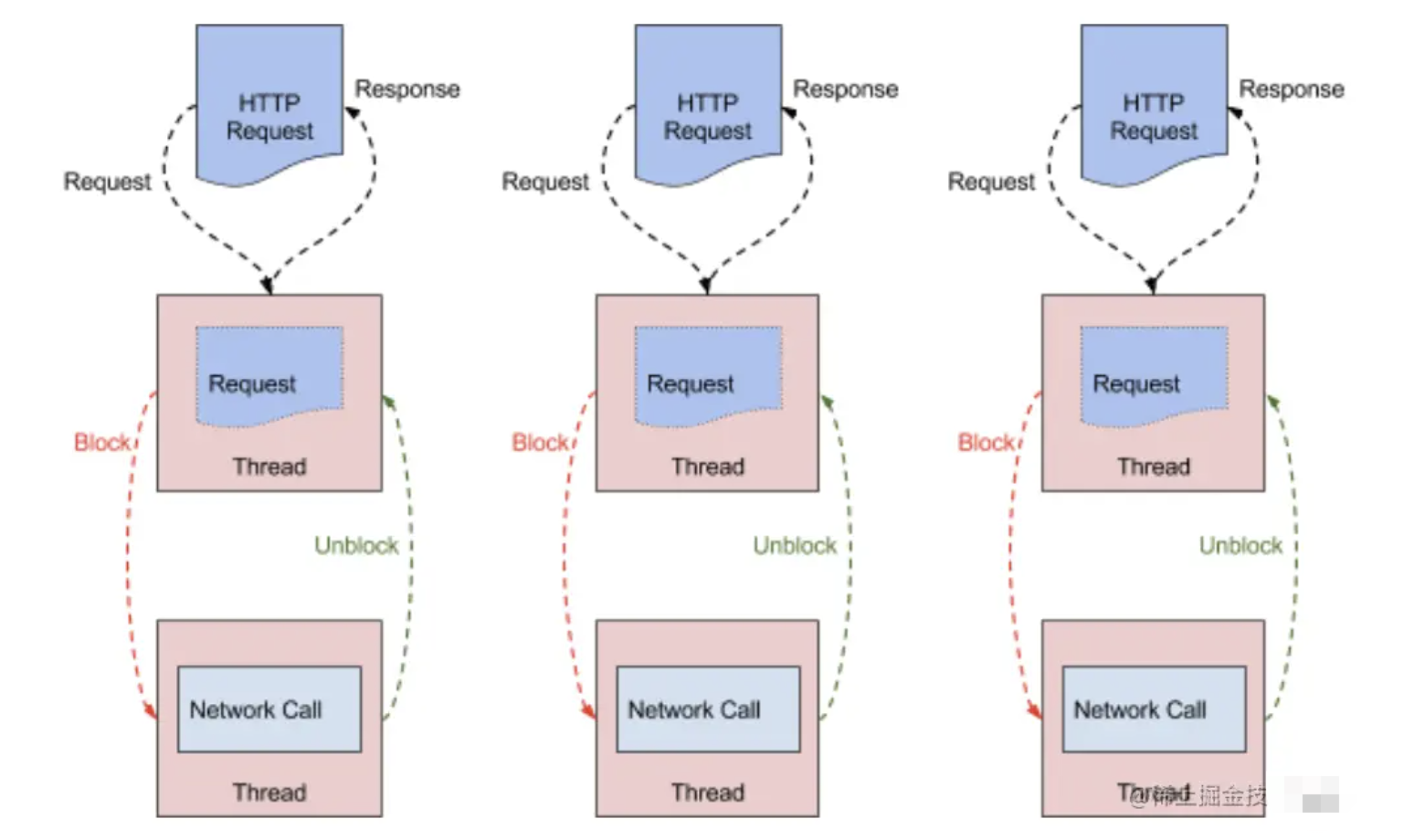
Zuul1 是基于 Servlet 框架构建,如图所示,采用的是阻塞和多线程方式,即一个线程处理一次连接请求,这种方式在内部延迟严重、设备故障较多情况下会引起存活的连接增多和线程增加的情况发生。
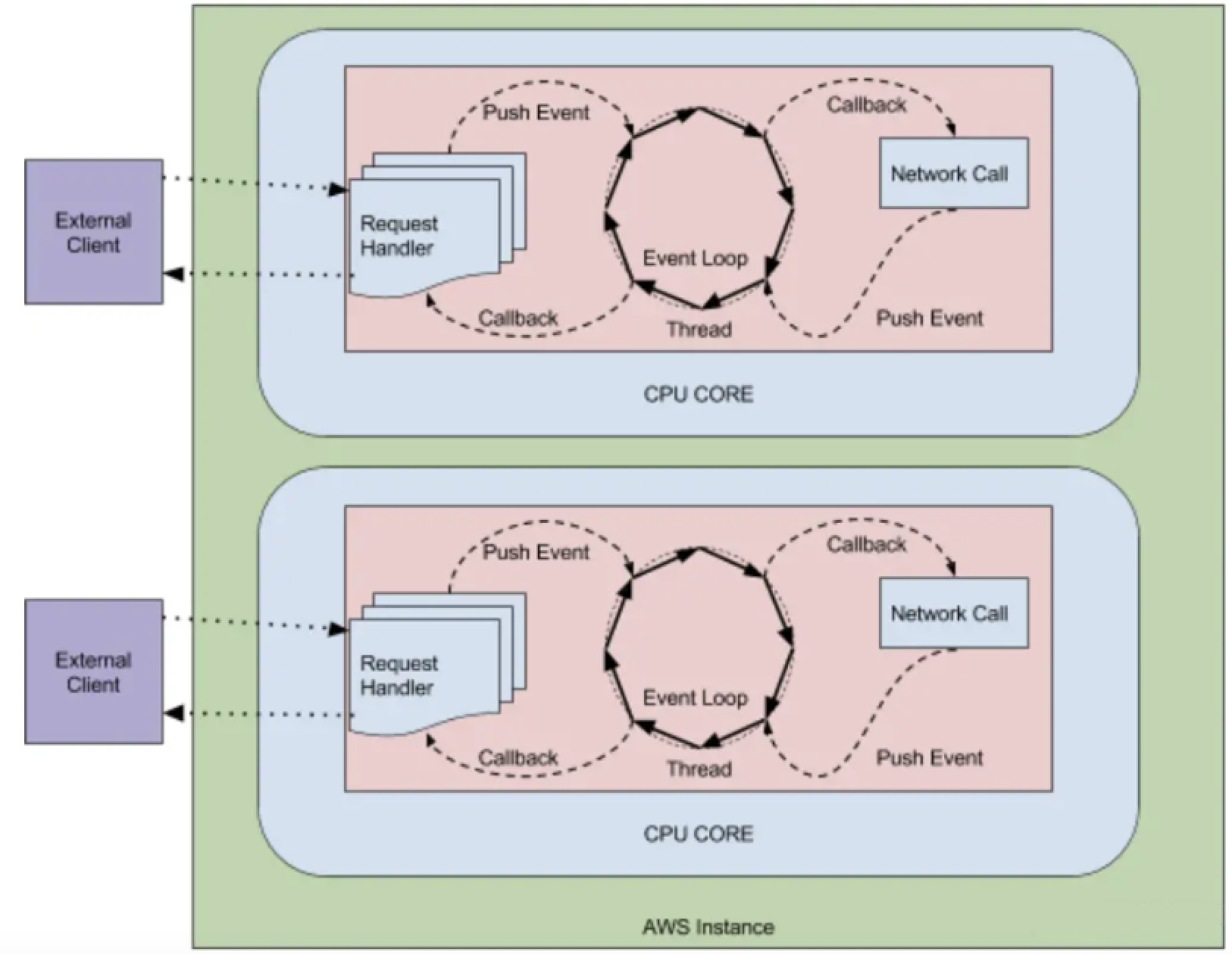
Netflix 发布的 Zuul2 有重大的更新,它运行在异步和无阻塞框架上,每个 CPU 核一个线程,处理所有的请求和响应,请求和响应的生命周期是通过事件和回调来处理的,这种方式减少了线程数量,因此开销较小。
Spring Cloud Gateway 是Spring Cloud的一个全新的API网关项目,目的是为了替换掉Zuul1,它基于Spring5.0 + SpringBoot2.0 + WebFlux(基于⾼性能的Reactor模式响应式通信框架Netty,异步⾮阻塞模型)等技术开发,性能⾼于Zuul,官⽅测试,Spring Cloud GateWay是Zuul的1.6倍,旨在为微服务架构提供⼀种简单有效的统⼀的API路由管理⽅式。
Spring Cloud Gateway可以与Spring Cloud Discovery Client(如Eureka)、Ribbon、Hystrix等组件配合使用,实现路由转发、负载均衡、熔断、鉴权、路径重写、⽇志监控等,并且Gateway还内置了限流过滤器,实现了限流的功能。

Kong是一款基于OpenResty(Nginx + Lua模块)编写的高可用、易扩展的,由Mashape公司开源的API Gateway项目。Kong是基于NGINX和Apache Cassandra或PostgreSQL构建的,能提供易于使用的RESTful API来操作和配置API管理系统,所以它可以水平扩展多个Kong服务器,通过前置的负载均衡配置把请求均匀地分发到各个Server,来应对大批量的网络请求。
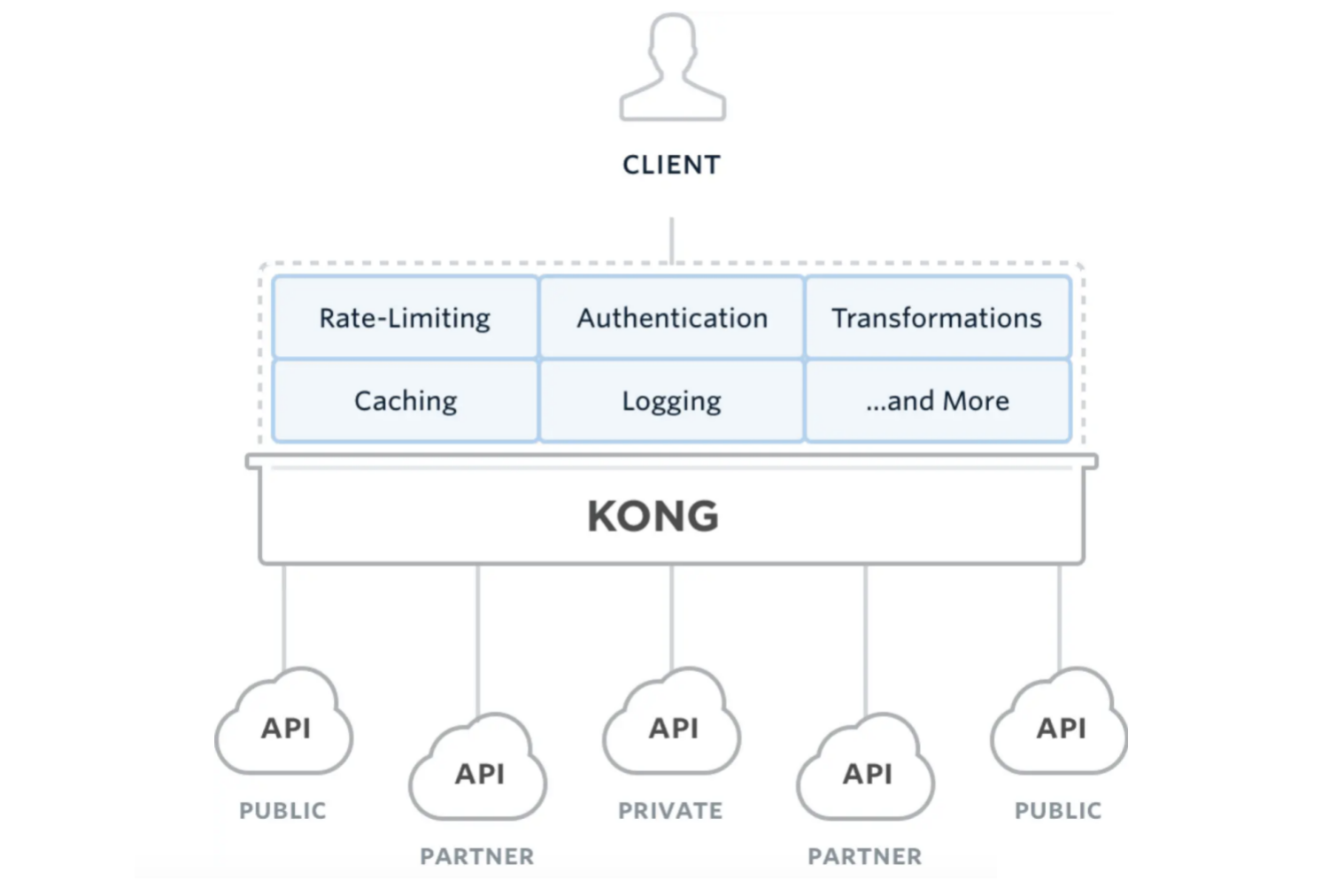
Kong主要有三个组件:
- Kong Server :基于Nginx的服务器,用来接收API请求。
- Apache Cassandra/PostgreSQL :用来存储操作数据。
- Kong dashboard:官方推荐UI管理工具,也可以使用 restfull 方式管理admin api。
Kong采用插件机制进行功能定制,插件集(可以是0或N个)在API请求响应循环的生命周期中被执行。插件使用Lua编写,目前已有几个基础功能:HTTP基本认证、密钥认证、CORS(Cross-Origin Resource Sharing,跨域资源共享)、TCP、UDP、文件日志、API请求限流、请求转发以及Nginx监控。
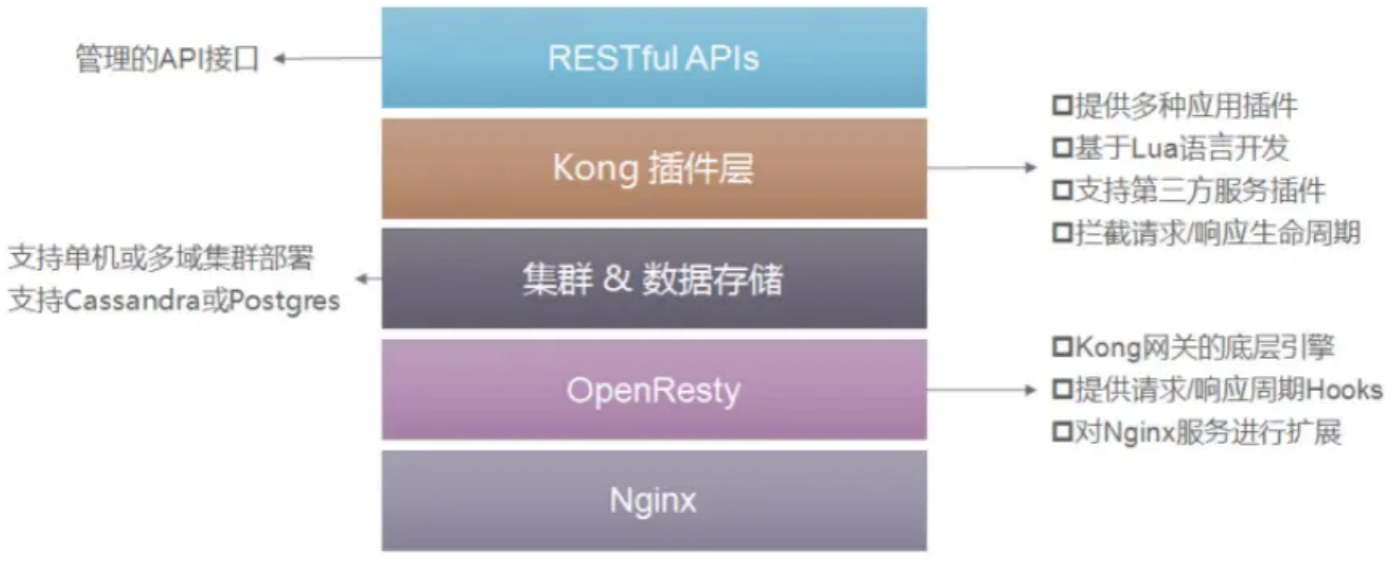
Kong网关具有以下的特性:
- 可扩展性: 通过简单地添加更多的服务器,可以轻松地进行横向扩展,这意味着您的平台可以在一个较低负载的情况下处理任何请求;
- 模块化: 可以通过添加新的插件进行扩展,这些插件可以通过RESTful Admin API轻松配置;
- 在任何基础架构上运行: Kong网关可以在任何地方都能运行。您可以在云或内部网络环境中部署Kong,包括单个或多个数据中心设置,以及public,private 或invite-only APIs。
Træfɪk 是一个为了让部署微服务更加便捷而诞生的现代HTTP反向代理、负载均衡工具。 它支持多种后台 (Docker, Swarm, Kubernetes, Marathon, Mesos, Consul, Etcd, Zookeeper, BoltDB, Rest API, file…) 来自动化、动态的应用它的配置文件设置。
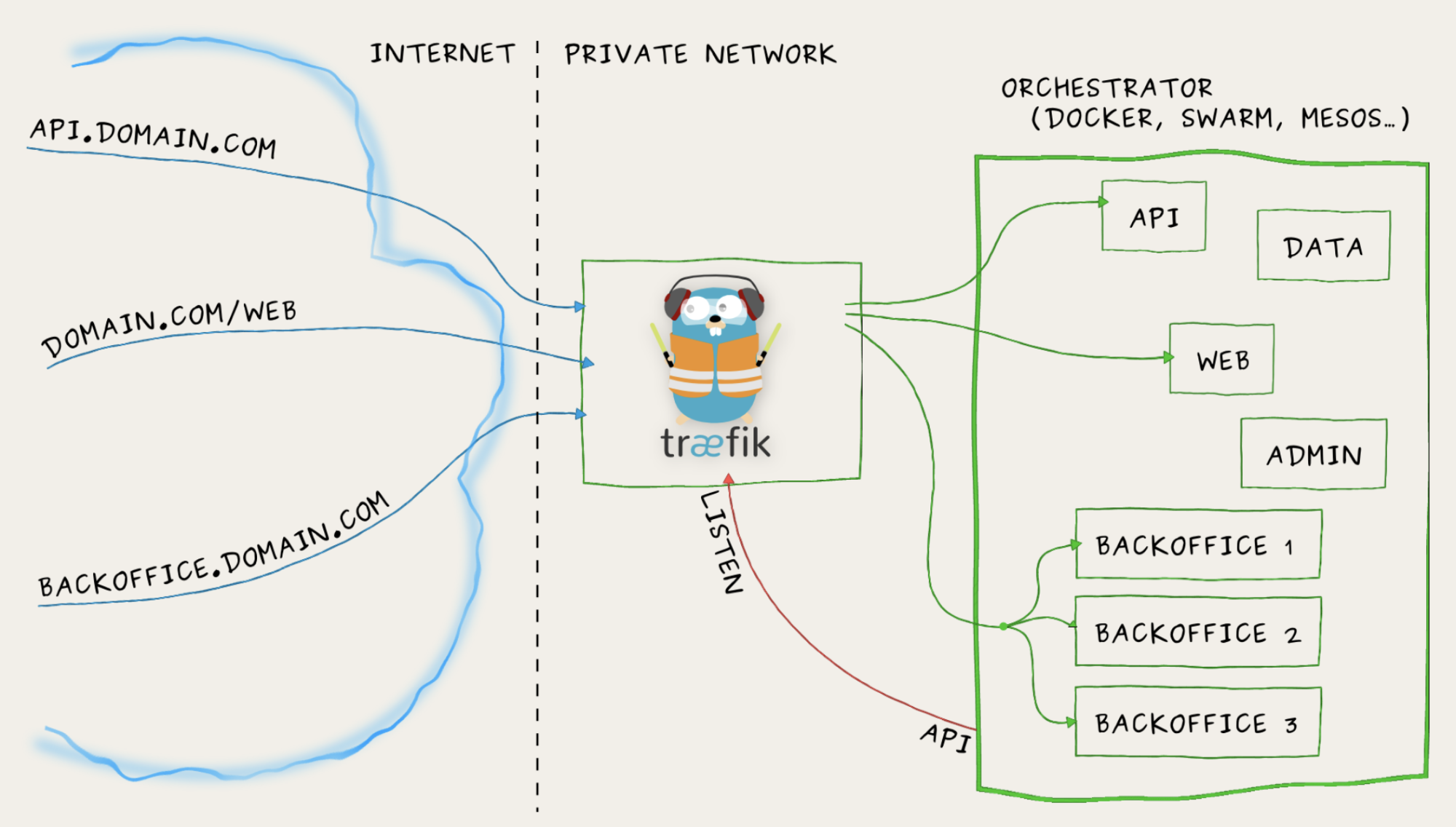
重要特性:
- 它非常快,无需安装其他依赖,通过Go语言编写的单一可执行文件;
- 多种后台支持:Docker, Swarm, Kubernetes, Marathon, Mesos, Consul, Etcd;
- 支持支持Rest API、Websocket、HTTP/2、Docker镜像;
- 监听后台变化进而自动化应用新的配置文件设置;
- 配置文件热更新,无需重启进程;
- 后端断路器、负载均衡、容错机制;
- 清爽的前端页面,可监控服务指标。
关于Traefik的更多内容,可以查看官网:https://traefik.cn/



上面是网关对比截图,偷个懒,大家主要关注Kong、Traefik和Zuul即可:
- 从开源社区活跃度来看,无疑是Kong和Traefik较好;
- 从成熟度来看,较好的是Kong、Tyk、Traefik;
- 从性能来看,Kong要比其他几个领先一些;
- 从架构优势的扩展性来看,Kong、Tyk有丰富的插件,Ambassador也有插件但不多,而Zuul是完全需要自研,但Zuul由于与Spring Cloud深度集成,使用度也很高,近年来Istio服务网格的流行,Ambassador因为能够和Istio无缝集成也是相当大的优势。
下面是其它网友的思考结论,可供参考:
- 性能:Nginx+Lua形式必然是高于Java语言实现的网关的,Java技术栈里面Zuul1.0是基于Servlet实现的,剩下都是基于webflux实现,性能是高于基于Servlet实现的。在性能方面我觉得选择网关可能不算那么重要,多加几台机器就可以搞定。
- 可维护性和扩展性:Nginx+Lua这个组合掌握的人不算多,如果团队有大神,大佬们就随意了,当没看到这段话,对于一般团队来说的话,选择自己团队擅长的语言更重要。Java技术栈下的3种网关,对于Zuul和Spring Cloud Getway需要或多或少要搞一些集成和配置页面来维护,但是对于Soul我就无脑看看文章,需要哪个搬哪个好了,尤其是可以无脑对接Dubbo美滋滋,此外Soul2.0以后版本可以摆脱ZK,在我心里再无诟病,我就喜欢无脑操作。
- 高可用:对于网关高可用基本都是统一的策略都是采用多机器部署的方式,前面挂一个负载,对于而外需要用的一些组件大家注意一下。
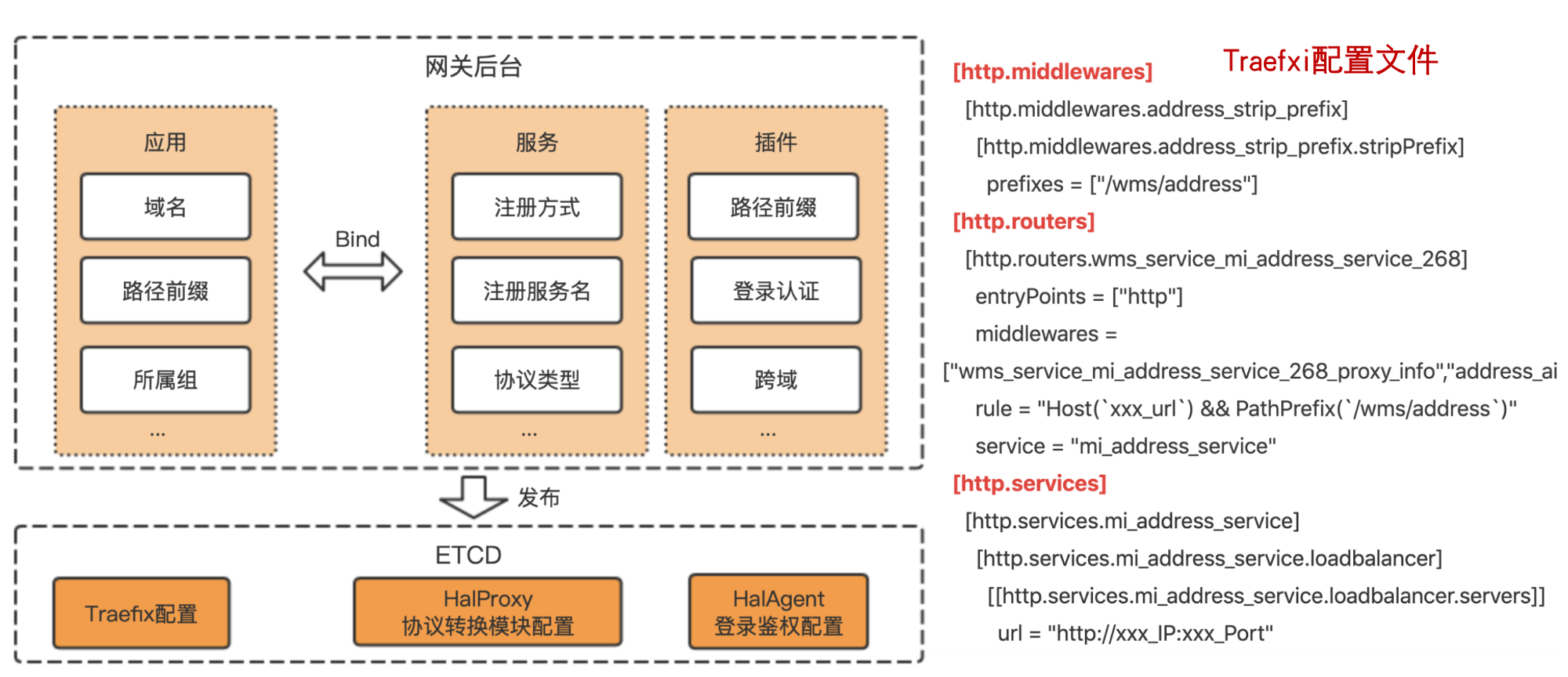
这个是我司自研的微服务网关,基于Traefik进行开发,下面从技术选型、网关框架、网关后台、协议转换进行讲解,绝对干货!
- Traefik:一款开源的反向代理与负载均衡工具,它最大的优点是能够与常见的微服务系统直接整合,可以实现自动化动态配置。traefik较为轻量,非常易于使用和设置,性能比较好,已在全球范围内用于生产环境。
- Etcd:一个Go言编写的分布式、高可用的一致性键值存储系统,用于提供可靠的分布式键值存储、配置共享和服务发现等功能。
- Go:并发能力强,性能媲美C,处理能力是PHP的4倍,效率高,语法简单,易上手,开发效率接近PHP。

整个网关框架分为3块:
- 网关后台(hal-fe和hal-admin):用于应用、服务和插件的配置,然后将配置信息发布到ETCD;
- Traefik:读取ETCD配置,根据配置信息对请求进行路由分发,如果需要鉴权,会直接通过hal-agent模块进行统一鉴权。鉴权完毕后,如果是Http请求,直接打到下游服务,如果是Grpc和Thrift协议,会通过hal-proxy模块进行协议转换。
- 协议转换模块:读取ETCD配置,对Traefik分发过来的请求,进行Grpc和Thrift协议转换,并通过服务发现机制,获取服务下游机器,并通过负载均衡,将转换后的数据打到下游服务机器。
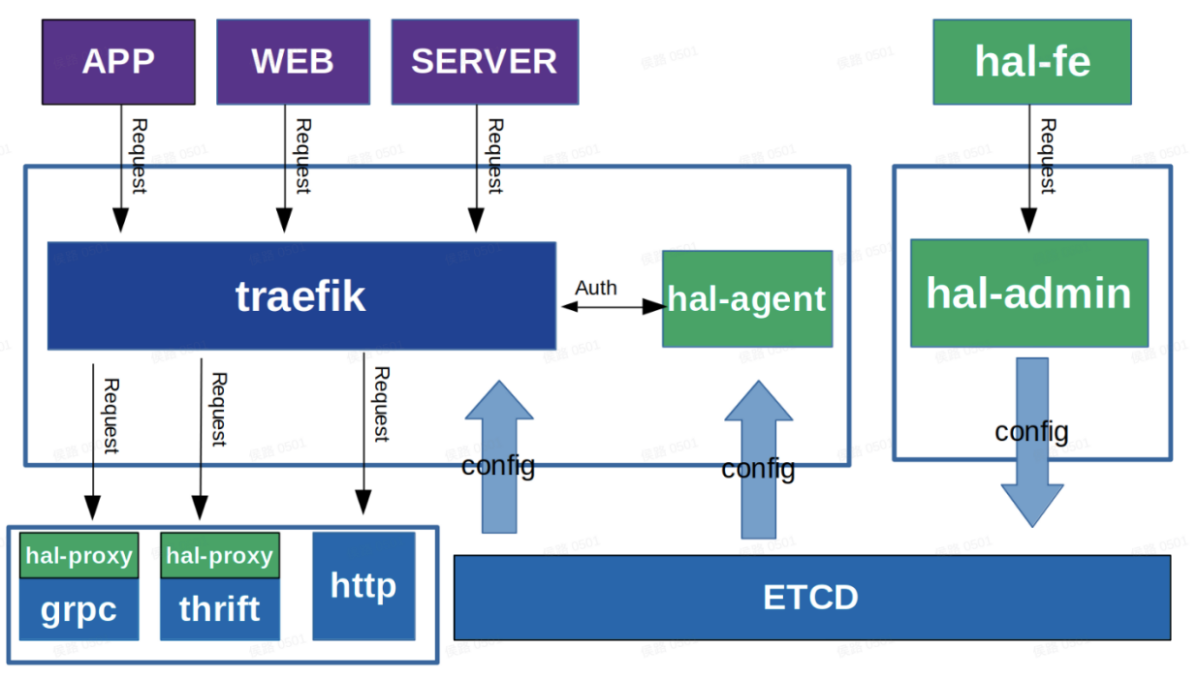
主要由3大模块组成:
- 应用:主要包括应用名、域名、路径前缀、所属组、状态等,比如印度海外商城、印度社区;
- 服务:主要包括服务名、注册方式、协议类型、所属组、状态等,比如评论服务、地址服务、搜索服务。
- 插件:主要包括插件名称、插件类型、插件属性配置等,比如路径前缀替换插件、鉴权插件。

一个应用只能绑定一个服务,但是可以绑定多个插件。 通过后台完成网关配置后,将这些配置信息生成Config文件,发布到ETCD中,Config文件需要遵循严格的数据格式,比如Traefix配置需要遵循官方的文件配置格式,才能被Traefik识别。
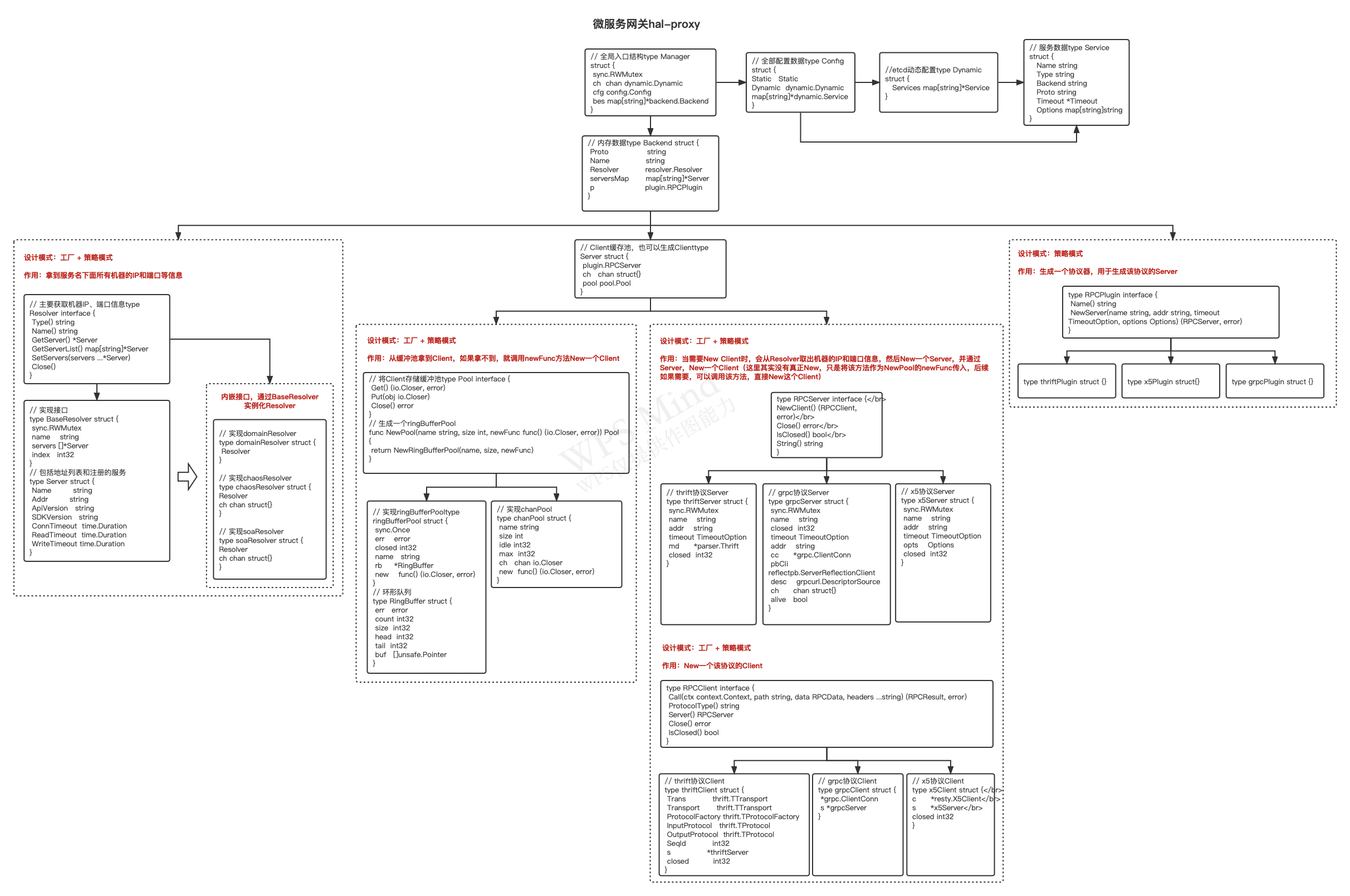
hal-proxy模块是整个微服务网关最复杂,也是技术含量最高的模块,所以给大家详细讲解一下。
在讲这个模块前,我们先看下面几个问题:
- 当请求从上游的trafik过来时,需要知道访问下游的机器IP和端口,才能将请求发送给下游,这些机器如何获取呢?
- 有了机器后,我们需要和下游机器建立连接,如果连接用一次就直接释放,肯定对服务会造成很大的压力,这就需要引入Client缓存池,那这个Client缓存池我们又该如何实现呢?
- 最后就是需要对协议进行转换,因为不同的下游服务,支持的协议类型是不一样的,这个网关又是如何动态支持的呢?

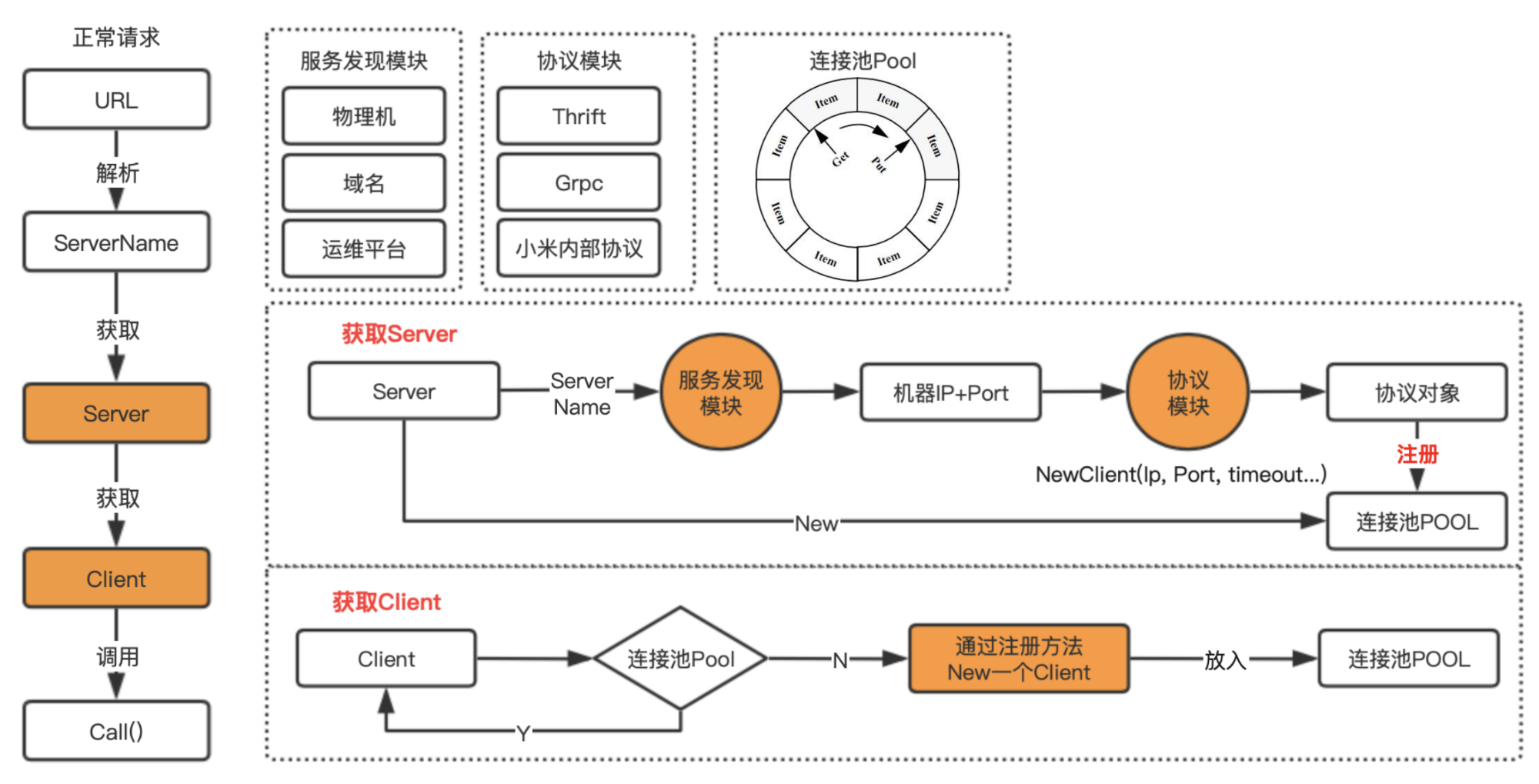
我们还是先看一下hal-proxy内部有哪些模块,首先是Resolver模块,这个模块的是什么作用呢?这里我简单介绍一下,目前公司内部通过服务获取到机器列表的方式有多种,比如MIS平台、服务树等,也就是有的是通过平台配置的,有的是直接挂在服务树下,无论哪种方式,我们都通过服务名,通过一定的方式,找到该服务下面所有的主机。
所以Resolver模块的作用,其实就是通过服务名,找到该服务下的所有机器的IP和服务端口,然后持久化到内存中,并定时更新。
协议模块就是支持不同的协议转换,每个协议类型的转换,都需要单独实现,这些协议转换,无非就是先通过机器IP和端口初始化Client,然后再将数据进行转换后,直接发送到下游的机器。
最后就是连接池,之前我们其实也用到go自带的pool来做,但是当对pool数据进行更新时,需要加锁,所以性能一直起不来,后来改成了环形队列,然后对数据的操作全部通过原子操作方式,就实现了无锁操作,大大提高的并发性能。
这个是hal-proxy的逻辑实现图,画了2天,包含所有核心对象的交互方式,这里就不去细讲,能掌握多少,靠大家自己领悟,如果有任何疑问(或者看不清图片),可以关注我公众号,加我微信沟通。