
The idea behind this project is to develop an image classifier using HuggingFace framework for its ease to implement transformer or other novel models that are SOTA for lots of different tasks related with images.
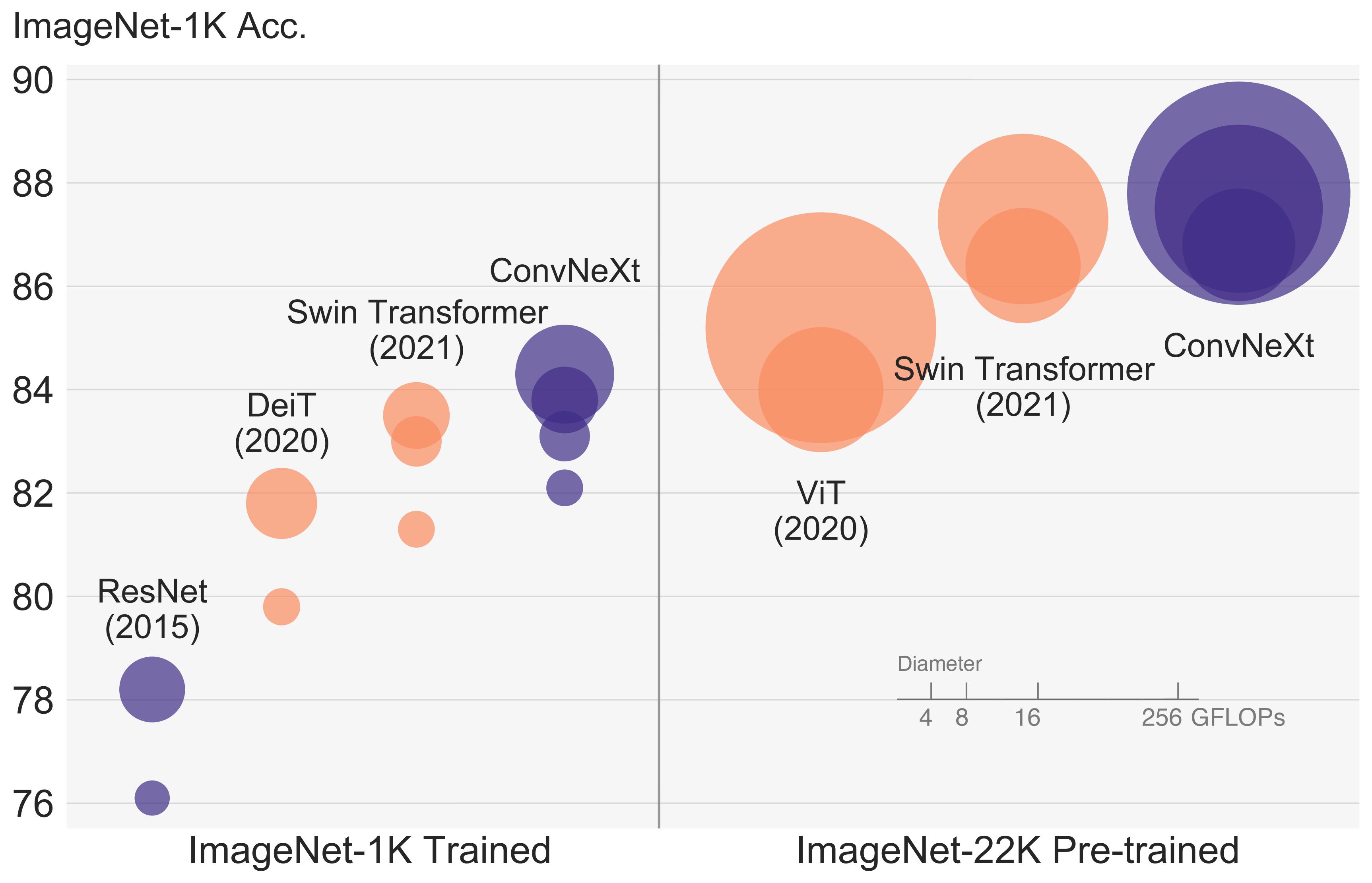
For the model, I have selected ConvNext model. The ConvNeXT model was proposed in A ConvNet for the 2020s and it is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
In the last years, Transformers have great success with NLP and are now applied to images. One special type of transformers called Vision Transformers (ViTs) have been developed for outperform convolutional networks in computer vision tasks. While CNN uses pixel arrays, ViT divides the image into visual tokens.

ConvNeXt came out in January of 2022 and it is a pure-conv network that was inspired by some of the new advances with ViTs, and appropriated a few concepts that helped it make a leap in CNN-based accuracy.
The authors started by taking the well know ResNet architecture and iteratively improving it following new best practices and discoveries made in the last decade. The authors focused on Swin-Transformer and follows closely its design choices. They divided their roadmap into two parts: macro design and micro design. Macro design is all the changes we do from a high-level perspective, e.g. the number of stages, while micro design is more about smaller things, e.g. which activation to use. Some of the main improvements they do are:
- AdamW as optimizer
- Adjusted the number of blocks in each stage, with a large kernel size and a stride such that the sliding window does not overlap
- Designing an inverted bottleneck with an expansion ratio of 4 (as it happens in Swin Transformers)
- Increasing the kernel size to equal the power of vision transformer models with a global receptive field. The vision transformer tends to view the whole image at once through self-attention that spans the entire image.
- Replacing RELU activation function by the Gaussian Error Linear Unit (GELU)
- Use fewer normalization layers because transformers use them less often.
- Replace Batch Normalization (BL) with Layer Normalization (LN).
