Cross-Modal-Based Fusion Recommendation Algorithm(CMBF)是一个能够捕获多个模态之间的交叉信息的模型,它能够缓解数据稀疏的问题,对冷启动物品比较友好。
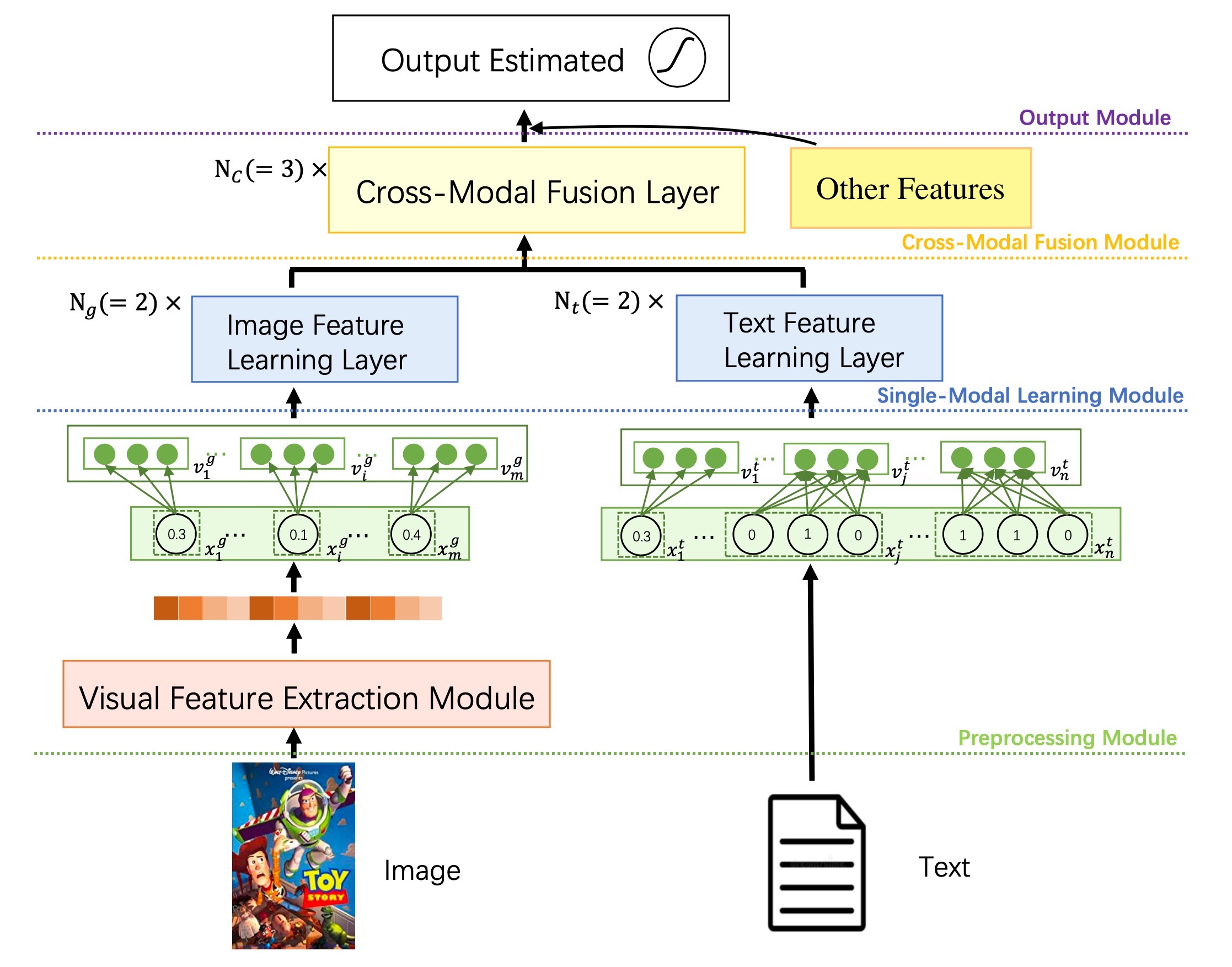
CMBF主要有4个模块(如上图):
- 预处理模块:提取图片和文本特征
- 单模态学习模块:基于Transformer学习图像、文本的语义特征
- 跨模态融合模块:学习两个模态之间的交叉特性
- 输出模块:获取高阶特征并预测结果
模型支持四种类型的特征组(feature group),如下所述。
不一定需要有全部四种类型的输入特征,只需要保证至少有一种类型的输入特征即可训练模型。根据输入特征类型的不同,部分网络结构可能会被短路(skip)掉。
视觉特征提取模块通常是一个CNN-based或Transformer-based的模型,用来提取图像或视频特征,以便后续接入transformer模块。
视觉特征的输入(对应配置名为image的feature group)可以是以下三种情况之一:
- 多个图像特征向量,每个特征向量对应原始图像的一个分片(patch)或一个兴趣区域 (region of interest) ,或者对应视频的某一帧;
- 一个大的复合特征向量,即上述多个图像特征向量铺平(flat)之后的结果,这时需要配置
image_feature_patch_num参数; - 一个常规的由某个图像模型提取的图像特征。
文本型特征包括两部分:
- 常规类型的特征,包括数值特征、单值类别特征、多值类别特征;(对应配置名为
general的feature group) - 不定长文本序列特征,例如 物品的
title、description等;(对应配置名为text的feature group) 每个特征需要转换为相同维度的embedding,以便接入后续的transformer模块。
注意:每一个feature group(image,general,text)内部的各个特征的embedding_dim必须配置为相同的值。
其他特征:不参与单模态学习模块和跨模态融合模块的输入特征,直接与跨模态融合模块的结果拼接后,接入后续的MLP,通常是一些统计类特征。
(对应配置名为other的feature group)
单模块学习模块采用标准的transformer结构,如下:
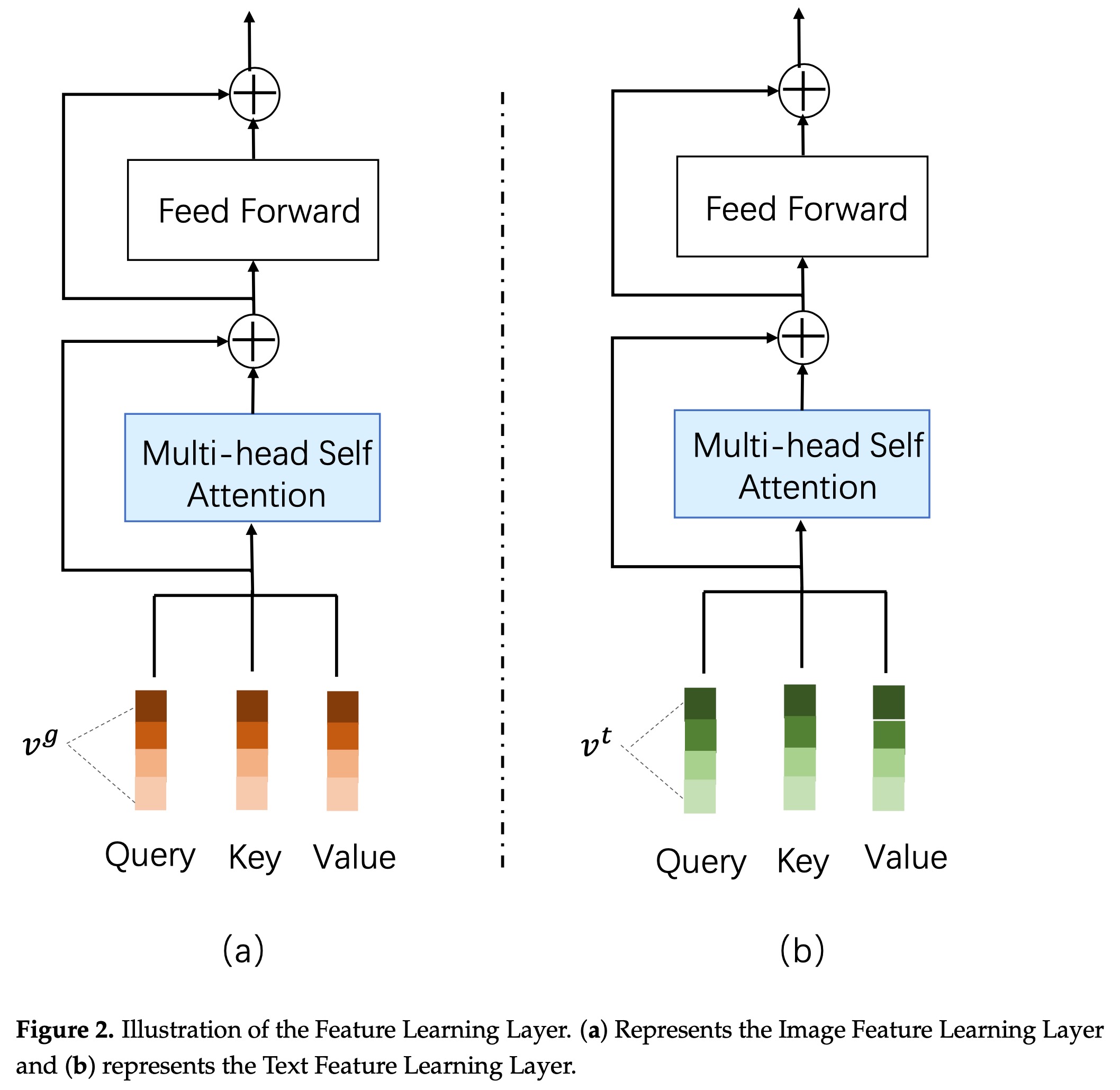
image_self_attention_layer_num = 0来跳过图像特征的单模块学习阶段。
跨模态融合模块使用了一个交叉attention的结构,如下:
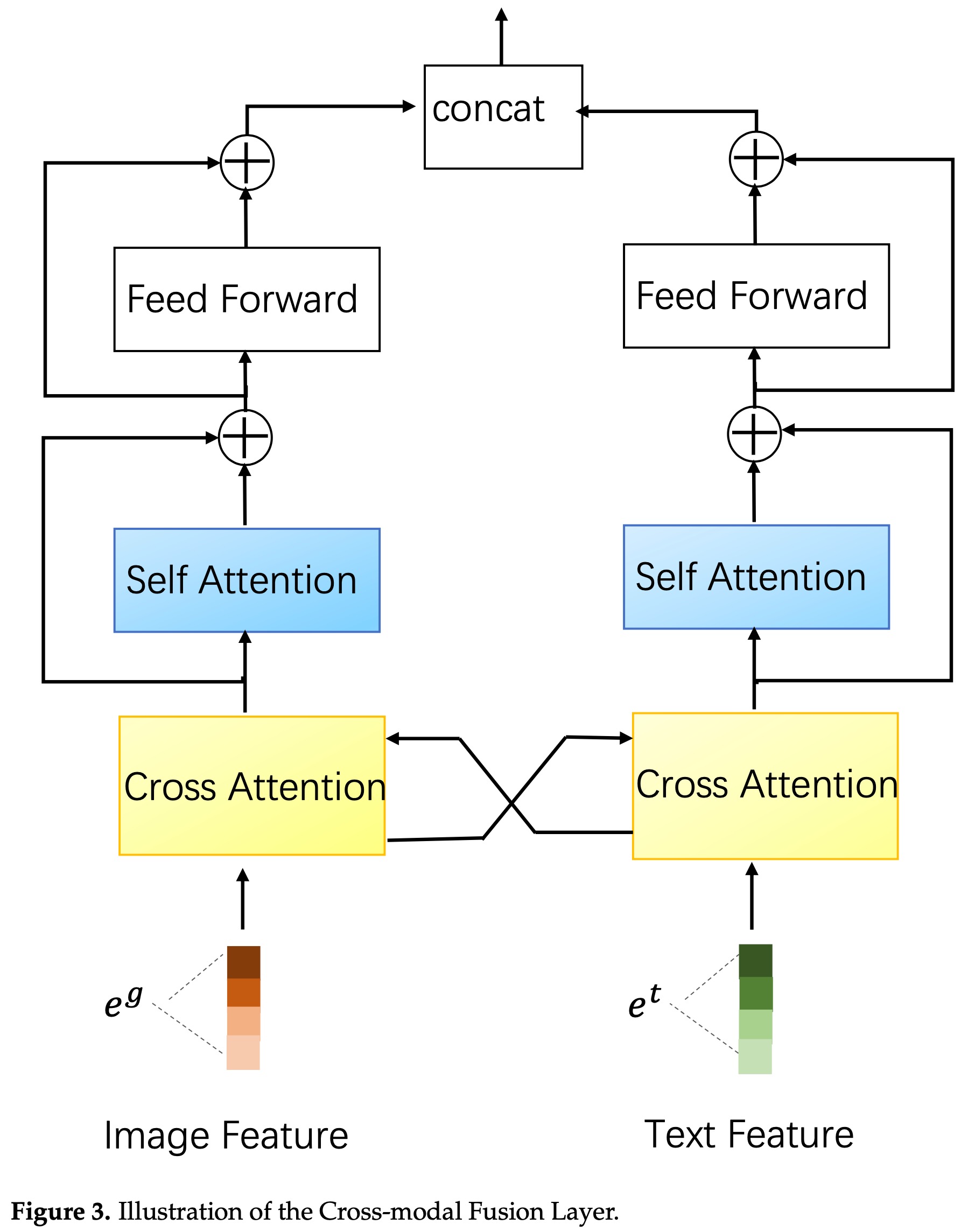
CMBF模型在多目标学习任务重的应用请参考 DBMTL+CMBF。
model_config: {
model_class: 'CMBF'
feature_groups: {
group_name: 'image'
feature_names: 'embedding'
wide_deep: DEEP
}
feature_groups: {
group_name: 'general'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'gender'
feature_names: 'age'
feature_names: 'occupation'
feature_names: 'zip_id'
feature_names: 'movie_year_bin'
feature_names: 'score_year_diff'
wide_deep: DEEP
}
feature_groups: {
group_name: 'text'
feature_names: 'title'
feature_names: 'genres'
wide_deep: DEEP
}
cmbf {
config {
multi_head_num: 2
text_multi_head_num: 4
image_multi_head_num: 3
image_head_size: 16
text_head_size: 8
image_feature_dim: 64
image_self_attention_layer_num: 2
text_self_attention_layer_num: 2
cross_modal_layer_num: 3
image_cross_head_size: 8
text_cross_head_size: 16
max_position_embeddings: 16
use_token_type: true
}
final_dnn: {
hidden_units: 256
hidden_units: 64
}
}
embedding_regularization: 1e-6
}-
model_class: 'CMBF', 不需要修改
-
feature_groups:
- 配置一个名为
image的feature_group,包含一个图像特征,或者一组embedding_size相同的图像特征(对应视频的多个帧,或者图像的多个region)。 - 配置一个名为
general的feature_group,包含需要做跨模态attention的常规特征,这些特征的embedding_dim必须相同。 - 配置一个名为
text的feature_group,包含需要做跨模态attention的不定长文本序列特征,这些特征的embedding_dim必须相同。 - 注意:CMBF 模型要求所有文本侧(包括
text和general两个特征组)输入特征的 embedding_dim 保持一致。 - [可选] 配置一个名为
other的feature_group,包含不需要做跨模态attention的其他特征,如各类统计特征。
- 配置一个名为
-
cmbf/config: CMBF 模型相关的参数
- image_feature_dim: 在单模态学习模块之前做图像特征维度调整,调整到该参数指定的维度
- multi_head_num: 跨模态融合模块中的 head 数量,默认为1
- image_multi_head_num: 图像单模态学习模块中的 head 数量,默认为1
- text_multi_head_num: 文本单模态学习模块中的 head 数量,默认为1
- image_head_size: 单模态学习模块中的图像tower,multi-headed self-attention的每个head的size
- text_head_size: 单模态学习模块中的文本tower,multi-headed self-attention的每个head的size
- image_feature_patch_num: [可选,默认值为1] 当只有一个image feature时生效,表示该图像特征是一个复合embedding,维度为
image_feature_patch_num * embedding_size。 - image_self_attention_layer_num: 单模态学习模块中的图像tower,multi-headed self-attention的层数;当只有一个图像特征时,可设置为0
- text_self_attention_layer_num: 单模态学习模块中的文本tower,multi-headed self-attention的层数
- cross_modal_layer_num: 跨模态融合模块的层数,建议设在1到5之间,默认为1
- image_cross_head_size: 跨模模态学习模块中的图像tower,multi-headed attention的每个head的size
- text_cross_head_size: 跨模模态学习模块中的文本tower,multi-headed attention的每个head的size
- attention_probs_dropout_prob: self/cross attention模块attention权重的dropout概率
- hidden_dropout_prob: multi-headed attention模块中FC layer的dropout概率
- use_token_type: bool,default is false;是否使用token type embedding区分不同的text sequence feature
- use_position_embeddings: bool, default is true;是否为文本序列添加位置编码
- max_position_embeddings: 文本序列的最大位置,当
use_position_embeddings为true时,必须配置;并且必须大于或等于所有特征配置max_seq_len的最大值 - text_seq_emb_dropout_prob: 文本序列embedding的dropout概率
- other_feature_dnn: [可选] 其他特征的MLP网络配置
-
cmbf/final_dnn: 输出模块的MLP网络配置
-
embedding_regularization: 对embedding部分加regularization,防止overfit