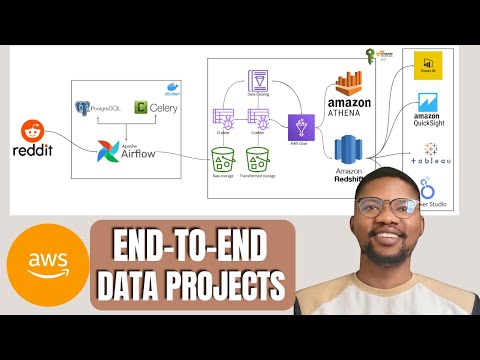
This project provides a comprehensive data pipeline solution to extract, transform, and load (ETL) Reddit data into a Redshift data warehouse. The pipeline leverages a combination of tools and services including Apache Airflow, Celery, PostgreSQL, Amazon S3, AWS Glue, Amazon Athena, and Amazon Redshift.
The pipeline is designed to:
- Extract data from Reddit using its API.
- Store the raw data into an S3 bucket from Airflow.
- Transform the data using AWS Glue and Amazon Athena.
- Load the transformed data into Amazon Redshift for analytics and querying.

- Reddit API: Source of the data.
- Apache Airflow & Celery: Orchestrates the ETL process and manages task distribution.
- PostgreSQL: Temporary storage and metadata management.
- Amazon S3: Raw data storage.
- AWS Glue: Data cataloging and ETL jobs.
- Amazon Athena: SQL-based data transformation.
- Amazon Redshift: Data warehousing and analytics.
- AWS Account with appropriate permissions for S3, Glue, Athena, and Redshift.
- Reddit API credentials.
- Docker Installation
- Python 3.9 or higher
- Clone the repository.
git clone https://github.com/airscholar/RedditDataEngineering.git
- Create a virtual environment.
python3 -m venv venv
- Activate the virtual environment.
source venv/bin/activate - Install the dependencies.
pip install -r requirements.txt
- Rename the configuration file and the credentials to the file.
mv config/config.conf.example config/config.conf
- Starting the containers
docker-compose up -d
- Launch the Airflow web UI.
open http://localhost:8080