From 5025813c6d94e04b7c7c33575519ba83336d9034 Mon Sep 17 00:00:00 2001
From: jin <571979568@qq.com>
Date: Mon, 15 Jul 2024 07:52:02 +0800
Subject: [PATCH] docs:Update Regression.md of Model Example
---
.../Model Example/Regression/Regression.md | 490 +++++++++---------
1 file changed, 249 insertions(+), 241 deletions(-)
diff --git a/docs/source/For User/Model Example/Regression/Regression.md b/docs/source/For User/Model Example/Regression/Regression.md
index 731b7df7..e36745cc 100644
--- a/docs/source/For User/Model Example/Regression/Regression.md
+++ b/docs/source/For User/Model Example/Regression/Regression.md
@@ -24,19 +24,11 @@ By running this line of command, the following output should show up on your scr
2 - Data For Classification
3 - Data For Clustering
4 - Data For Dimensional Reduction
-(User) ➜ @Number:
+(User) ➜ @Number: 1
```
Enter the serial number of the sub-menu you want to choose and press `Enter`. In this doc, we will focus on the usage of Regression function, to do that, enter `1` and press `Enter`.
-```python
--*-*- Built-in Data Option-*-*-
-1 - Data For Regression
-2 - Data For Classification
-3 - Data For Clustering
-4 - Data For Dimensional Reduction
-(User) ➜ @Number: 1
-```
### 2.2 Generate a map projection
@@ -103,7 +95,7 @@ After pressing `Enter`to move forward, you will see a question pops up enquiring
World Map Projection for A Specific Element Option:
1 - Yes
2 - No
-(Plot) ➜ @Number:
+(Plot) ➜ @Number: 1
```
By choosing “Yes”, you can then choose one element to be projected in the world map; By choosing “No”, you can skip to the next mode. For demonstrating, we choose “Yes” in this case:
@@ -161,16 +153,17 @@ Index - Column Name
46 - TH(PPM)
47 - U(PPM)
--------------------
-(Plot) ➜ @Number:
+(Plot) ➜ @Number: 10
```
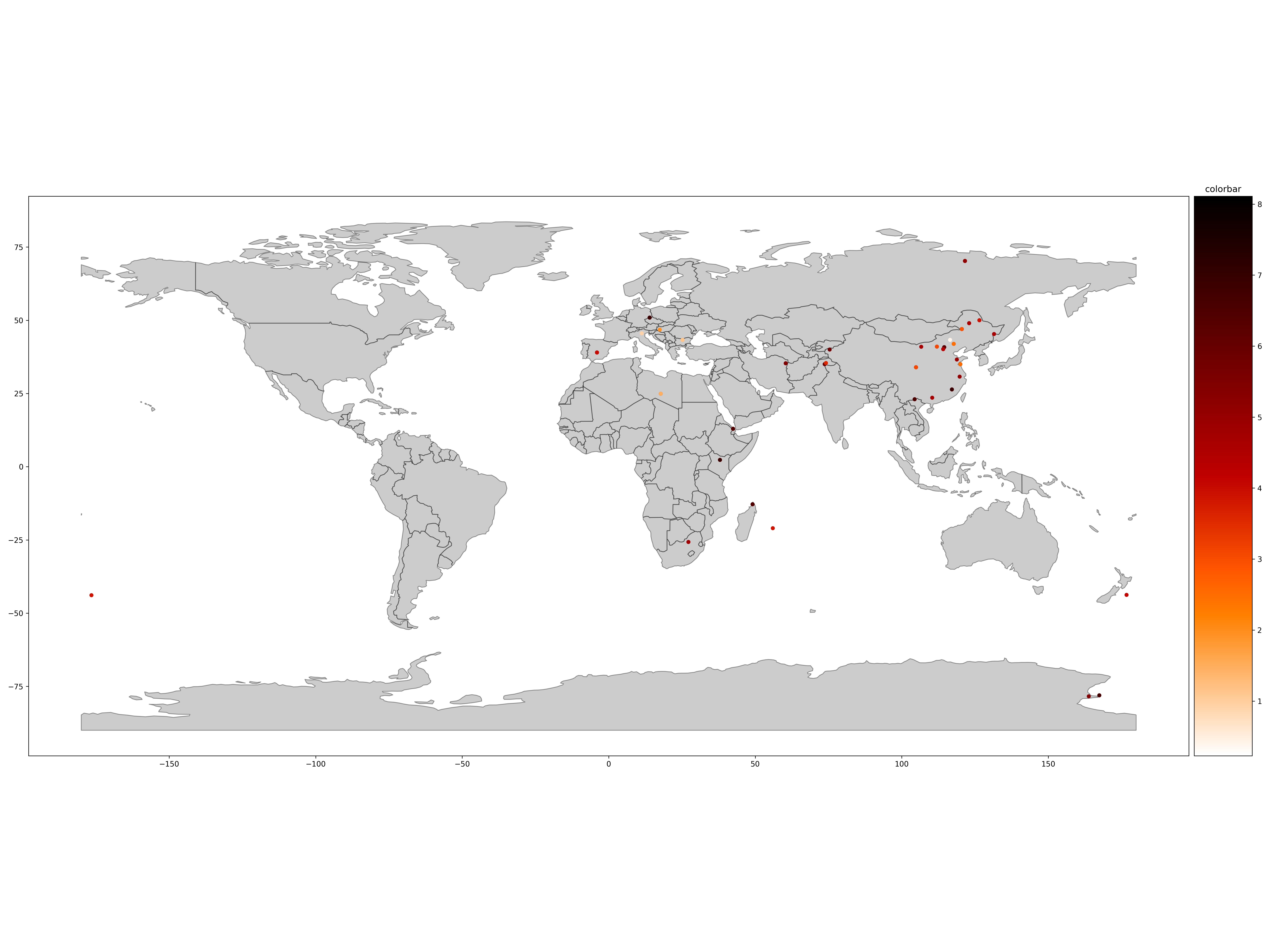
Here, we choose “10 - AL2O3(WT%)” as an example, after this, the path to save the image will be presented:
```python
-Save figure 'Map Projection - AL2O3(WT%)' in /home/yucheng/output/images/ma
+Save figure 'Map Projection - AL2O3(WT%)' in C:\Users\YSQ\geopi_output\Regression\test\artifacts\image\map.
+Successfully store 'Map Projection - AL2O3(WT%)'in 'Map Projection - AL2O3(WT%).xlsx' inC:\Users\YSQ\geopi_output\Regression\test\artifacts\image\map.
```
-
+
Map Projection - AL2O3(WT%)
When you see the following instruction:
@@ -179,10 +172,10 @@ When you see the following instruction:
Do you want to continue to project a new element in the World Map?
1 - Yes
2 - No
-(Plot) ➜ @Number:
+(Plot) ➜ @Number: 2
```
-You can choose “Yes” to map another element or choose “No” to exit map mode.
+You can choose “Yes” to map another element or choose “No” to exit map mode. Here, we choose 2 to skip this step.
### 2.3 Enter the range of data and check the output
@@ -193,7 +186,7 @@ Select the data range you want to process.
Input format:
Format 1: "[**, **]; **; [**, **]", such as "[1, 3]; 7; [10, 13]" --> you want to deal with the columns 1, 2, 3, 7, 10, 11, 12, 13
Format 2: "xx", such as "7" --> you want to deal with the columns 7
-@input:
+@input: [10,13]
```
Here, we use “[10, 13]” as an example. The values of the elements we choose would be shown on the screen.
@@ -253,30 +246,25 @@ min 0.230000 0.000000 1.371100 13.170000
50% 4.720000 0.925000 2.690000 21.223500
75% 6.233341 1.243656 3.330000 22.185450
max 8.110000 3.869550 8.145000 25.362000
-Successfully calculate the pair-wise correlation coefficient among the selected columns.
-Save figure 'Correlation Plot' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\image\statistic.
-Successfully store 'Correlation Plot' in 'Correlation Plot.xlsx' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\image\statistic.
-Successfully draw the distribution plot of the selected columns.
-Save figure 'Distribution Histogram' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\image\statistic.
-Successfully store 'Distribution Histogram' in 'Distribution Histogram.xlsx' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\image\statistic.
-Successfully draw the distribution plot after log transformation of the selected columns.
-Save figure 'Distribution Histogram After Log Transformation' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\image\statistic.
-Successfully store 'Distribution Histogram After Log Transformation' in 'Distribution Histogram After Log Transformation.xlsx' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test
-1\artifacts\image\statistic.
-Successfully store 'Data Original' in 'Data Original.xlsx' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\data.
-Successfully store 'Data Selected' in 'Data Selected.xlsx' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\data.
-(Press Enter key to move forward.)
+Successfully calculate the pair-wise correlation coefficient among the selected columns. Save figure 'Correlation Plot' in C:\Users\YSQ\geopi_output\Regression\test\artifacts\image\statistic.
+Successfully store 'Correlation Plot' in 'Correlation Plot.xlsx' in C:\Users\YSQ\geopi_output\Regression\test\artifacts\image\statistic.
+...
+Successfully store 'Data Original' in 'DataOriginal.xlsx' in C:\Users\YSQ\geopi_output\Regression\test\artifacts\data.
+Successfully store 'Data Selected' in 'DataSelected.xlsx' in C:\Users\YSQ\geopi_output\Regression\test\artifacts\data.
```
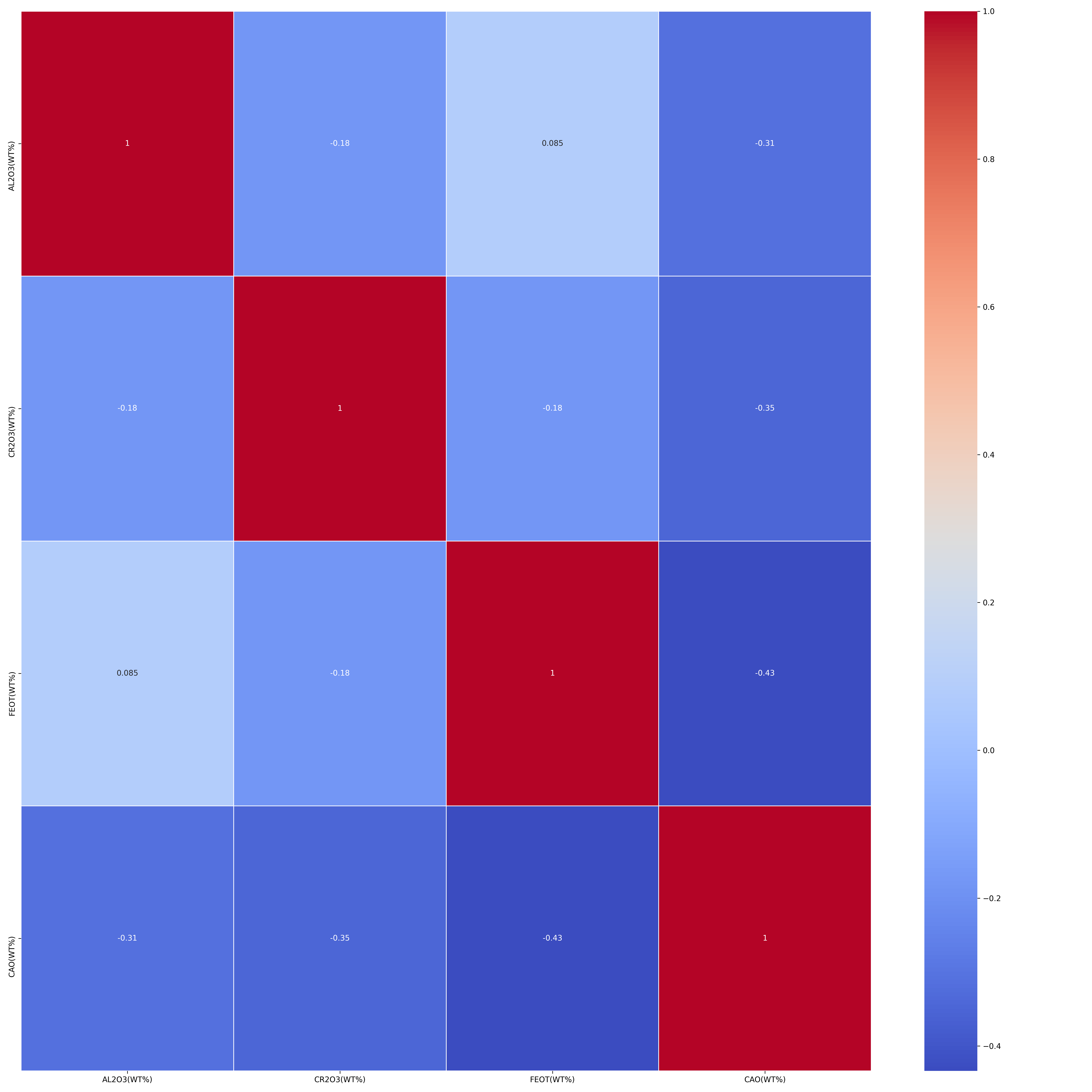
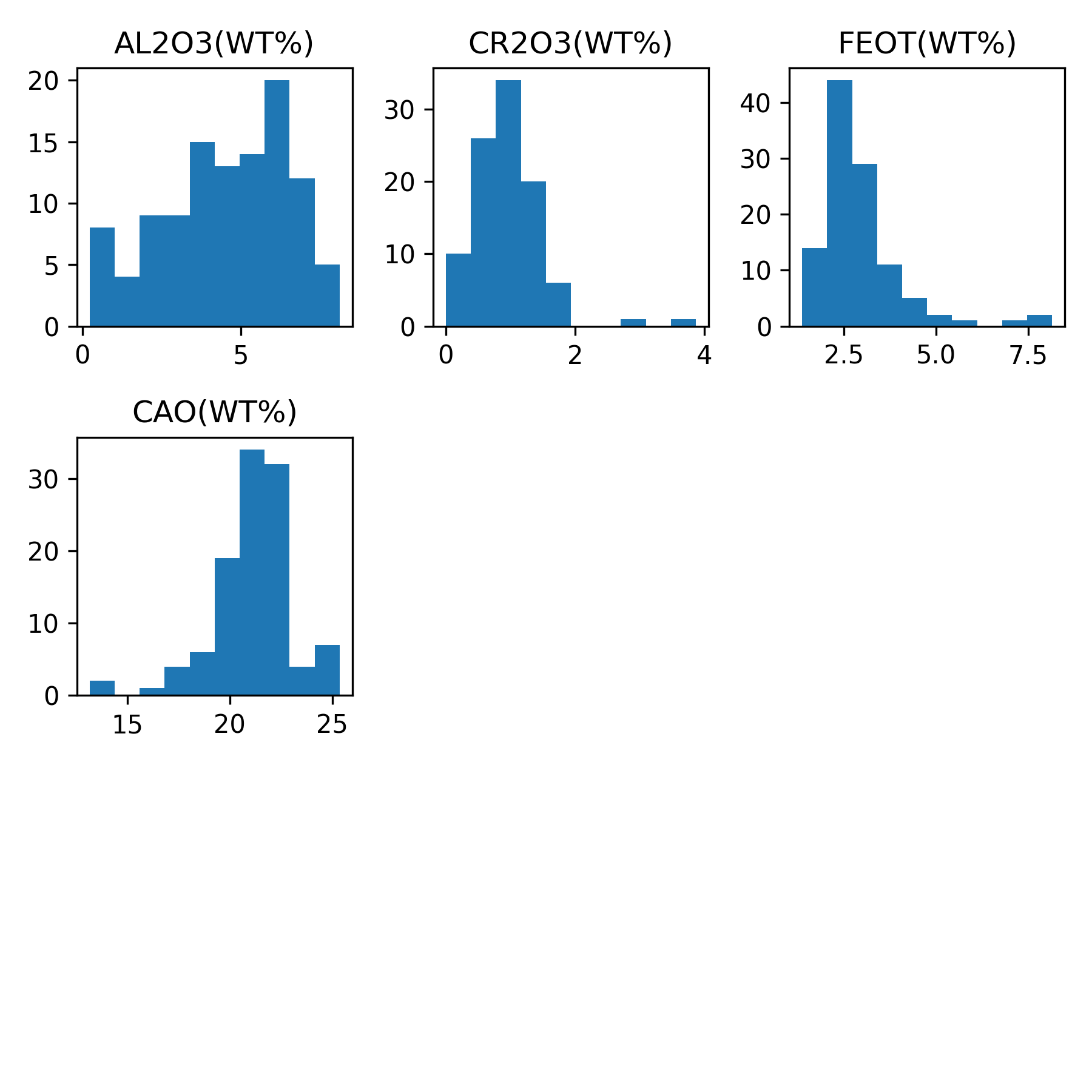
The function calculates the pairwise correlation coefficients among these elements and create a distribution plot for each element. Here are the plots generated by our example:
-
+
+
Correlation Plot
-
+
+
Distribution Histogram
-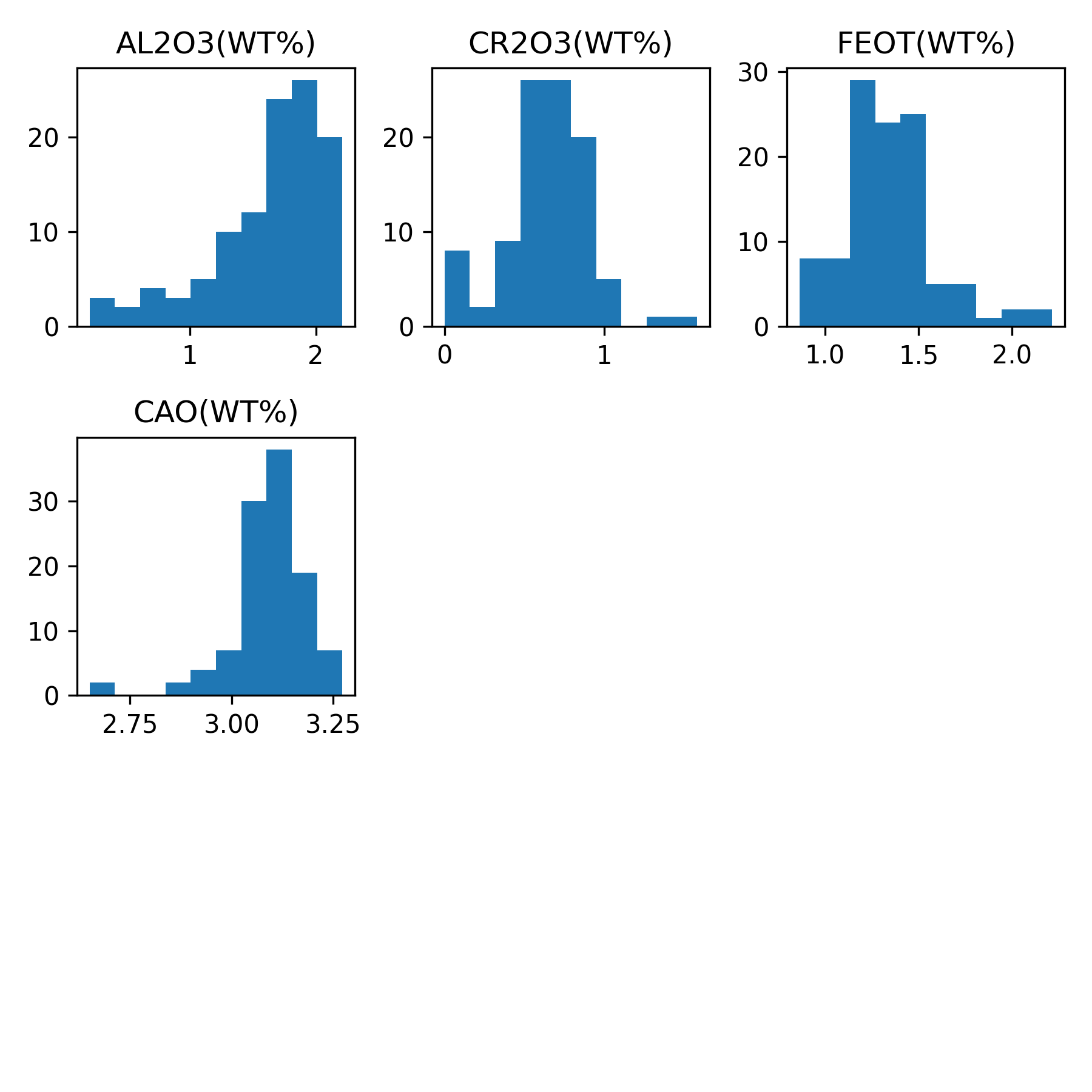
+
+
Distribution Histogram After Log Transformation
@@ -306,71 +294,27 @@ Note: you'd better use imputation techniques to deal with the missing values.
(Press Enter key to move forward.)
```
-Here, we choose ”1 - Mean Values” as our strategy:
-
```python
--*-*- Strategy for Missing Values -*-*-
-1 - Mean Value
-2 - Median Value
-3 - Most Frequent Value
-4 - Constant(Specified Value)
-Which strategy do you want to apply?
+-*-*- Missing Values Process -*-*-
+Do you want to deal with the missing values?
+1 - Yes
+2 - No
(Data) ➜ @Number: 1
-Successfully fill the missing values with the mean value of each feature column respectively.
-(Press Enter key to move forward.)
```
-
-Here, the pragram is performing a hypothesis testing on the imputation method used to fill missing values in a dataset. The null hypothesis is that the distribution of the data set before and after imputing remains the same. The Kruskal Test is used to test this hypothesis, with a significance level of 0.05. Monte Carlo simulation is used with 100 iterations, each with a sample size of half the dataset (54 in this case). The p-values are calculated for each column and the columns that reject the null hypothesis are identified.
+Here, let's choose 1 to deal with the missing values.
```python
--*-*- Hypothesis Testing on Imputation Method -*-*-
-Null Hypothesis: The distributions of the data set before and after imputing remain the same.
-Thoughts: Check which column rejects null hypothesis.
-Statistics Test Method: kruskal Test
-Significance Level: 0.05
-The number of iterations of Monte Carlo simulation: 100
-The size of the sample for each iteration (half of the whole data set): 54
-Average p-value:
-AL2O3(WT%) 1.0
-CR2O3(WT%) 0.9327453056346102
-FEOT(WT%) 1.0
-CAO(WT%) 1.0
-Note: 'p-value < 0.05' means imputation method doesn't apply to that column.
-The columns which rejects null hypothesis: None
-Successfully draw the respective probability plot (origin vs. impute) of the selected columns
-Save figure 'Probability Plot' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\image\statistic.
-Successfully store 'Probability Plot' in 'Probability Plot.xlsx' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\image\statistic.
-
-RangeIndex: 109 entries, 0 to 108
-Data columns (total 4 columns):
- # Column Non-Null Count Dtype
---- ------ -------------- -----
- 0 AL2O3(WT%) 109 non-null float64
- 1 CR2O3(WT%) 109 non-null float64
- 2 FEOT(WT%) 109 non-null float64
- 3 CAO(WT%) 109 non-null float64
-dtypes: float64(4)
-memory usage: 3.5 KB
-None
-Some basic statistic information of the designated data set:
- AL2O3(WT%) CR2O3(WT%) FEOT(WT%) CAO(WT%)
-count 109.000000 109.000000 109.000000 109.000000
-mean 4.554212 0.956426 2.962310 21.115756
-std 1.969756 0.524695 1.133967 1.964380
-min 0.230000 0.000000 1.371100 13.170000
-25% 3.110977 0.680000 2.350000 20.310000
-50% 4.720000 0.956426 2.690000 21.223500
-75% 6.233341 1.170000 3.330000 22.185450
-max 8.110000 3.869550 8.145000 25.362000
-Successfully store 'Data Selected Imputed' in 'Data Selected Imputed.xlsx' in C:\Users\86188\geopi_output\GeoPi - Rock Classification\Xgboost Algorithm - Test 1\artifacts\data.
-(Press Enter key to move forward.)
+-*-*- Strategy for Missing Values -*-*-
+1 - Drop Rows with Missing Values
+2 - Impute Missing Values
+Notice: Drop the rows with missing values may lead to a significant loss of data if too many
+features are chosen.
+Which strategy do you want to apply?
+(Data) ➜ @Number:1
```
+We'll just skip the lines with missing info to keep things simple.
-A probability plot of the selected columns is also drawn and saved in a specified location.
-
-
-Probability Plot
### 2.5 Feature Engineering
@@ -389,7 +333,7 @@ Index - Column Name
Feature Engineering Option:
1 - Yes
2 - No
-(Data) ➜ @Number:
+(Data) ➜ @Number: 1
```
After enter “1”, we now is ready to name the constructed feature and build the formula. In this example, we use “newFeature” as the name and we build the formula with “b*c+d”:
@@ -402,6 +346,8 @@ c - FEOT(WT%)
d - CAO(WT%)
Name the constructed feature (column name), like 'NEW-COMPOUND':
@input: new Feature
+```
+```python
Build up new feature with the combination of basic arithmatic operators, including '+', '-', '*', '/', '()'.
Input example 1: a * b - c
--> Step 1: Multiply a column with b column;
@@ -422,51 +368,66 @@ You can use mean(x) to calculate the average value.
@input: b*c+d
```
-The output is as below:
+This step, we enter b*c+d. And the output is as below:
```python
-Successfully construct a new feature "new Feature".
-0 23.005680
-1 22.084600
-2 23.126441
-3 24.392497
-4 23.394575
- ...
-104 23.801200
-105 22.017500
-106 27.033200
-107 23.825000
-108 22.656000
-Name: new Feature, Length: 109, dtype: float64
+Successfully construct a new feature new Feature.
+0 23.00568
+1 22.08460
+2 25.43000
+3 23.39590
+4 22.90900
+ ...
+93 23.80120
+94 22.01750
+95 27.03320
+96 23.82500
+97 22.65600
+Name: new Feature, Length: 98, dtype: float64
(Press Enter key to move forward.)
------------------
-RangeIndex: 109 entries, 0 to 108
+RangeIndex: 98 entries, 0 to 97
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
- 0 AL2O3(WT%) 109 non-null float64
- 1 CR2O3(WT%) 109 non-null float64
- 2 FEOT(WT%) 109 non-null float64
- 3 CAO(WT%) 109 non-null float64
- 4 new Feature 109 non-null float64
+ 0 AL2O3(WT%) 98 non-null float64
+ 1 CR2O3(WT%) 98 non-null float64
+ 2 FEOT(WT%) 98 non-null float64
+ 3 CAO(WT%) 98 non-null float64
+ 4 new Feature 98 non-null float64
dtypes: float64(5)
-memory usage: 4.4 KB
+memory usage: 4.0 KB
None
Some basic statistic information of the designated data set:
- AL2O3(WT%) CR2O3(WT%) FEOT(WT%) CAO(WT%) new Feature
-count 109.000000 109.000000 109.000000 109.000000 109.000000
-mean 4.554212 0.956426 2.962310 21.115756 23.853732
-std 1.969756 0.524695 1.133967 1.964380 1.596076
-min 0.230000 0.000000 1.371100 13.170000 18.474000
-25% 3.110977 0.680000 2.350000 20.310000 22.909000
-50% 4.720000 0.956426 2.690000 21.223500 23.904360
-75% 6.233341 1.170000 3.330000 22.185450 24.763500
-max 8.110000 3.869550 8.145000 25.362000 29.231800
+ AL2O3(WT%) CR2O3(WT%) FEOT(WT%) CAO(WT%) new Feature
+count 98.000000 98.000000 98.000000 98.000000 98.000000
+mean 4.444082 0.956426 2.929757 21.187116 23.883266
+std 1.996912 0.553647 1.072481 1.891933 1.644173
+min 0.230000 0.000000 1.371100 13.170000 18.474000
+25% 3.051456 0.662500 2.347046 20.310000 22.872800
+50% 4.621250 0.925000 2.650000 21.310000 23.907180
+75% 6.222500 1.243656 3.346500 22.284019 24.795747
+max 8.110000 3.869550 8.145000 25.362000 29.231800
(Press Enter key to move forward.)
```
-After building the new feature, we can choose the mode to process data, in this doc, we choose “1 - Regression”:
+If you feel it's enough, just select 'no' to proceed to the next step. Here, we choose 2.
+```python
+Do you want to continue to build a new feature?
+1 - Yes
+2 - No
+(Data) ➜ @Number:2
+```
+
+```
+Successfully store 'Data Selected Dropped-Imputed Feature-Engineering' in 'Data Selected
+Dropped-Imputed Feature-Engineering.xlsx' in
+C:\Users\YSQ\geopi_output\Regression\test\artifacts\data.
+Exit Feature Engineering Mode.
+(Press Enter key to move forward.)
+```
+
+After building the feature, we can choose the mode to process data, in this doc, we choose “1 - Regression”:
```python
-*-*- Mode Selection -*-*-
@@ -482,7 +443,7 @@ After building the new feature, we can choose the mode to process data, in this
After entering the Regression menu, we are going to input X Set and Y Set separately, note that the new feature we just created is also in the list:
```python
--*-*- Data Split - X Set and Y Set-*-*-
+-*-*- Data Segmentation - X Set and Y Set -*-*-
Divide the processing data set into X (feature value) and Y (target value) respectively.
Selected sub data set to create X data set:
--------------------
@@ -498,42 +459,101 @@ Select the data range you want to process.
Input format:
Format 1: "[**, **]; **; [**, **]", such as "[1, 3]; 7; [10, 13]" --> you want to deal with the columns 1, 2, 3, 7, 10, 11, 12, 13
Format 2: "xx", such as "7" --> you want to deal with the columns 7
-@input:
+@input: 1
```
After entering the X Set, the prompt of successful operation and basic statistical information would be shown:
```python
-uccessfully create X data set.
+Successfully create X data set.
The Selected Data Set:
- AL2O3(WT%)
-0 3.936000
-1 3.040000
-2 7.016561
-3 3.110977
-4 6.971044
-.. ...
-104 2.740000
-105 5.700000
-106 0.230000
-107 2.580000
-108 6.490000
-
-[109 rows x 1 columns]
+ AL2O3(WT%)
+0 3.936
+1 3.040
+2 4.220
+3 6.980
+4 6.250
+.. ...
+93 2.740
+94 5.700
+95 0.230
+96 2.580
+97 6.490
+
+[98 rows x 1 columns]
Basic Statistical Information:
Some basic statistic information of the designated data set:
AL2O3(WT%)
-count 109.000000
-mean 4.554212
-std 1.969756
+count 98.000000
+mean 4.444082
+std 1.996912
min 0.230000
-25% 3.110977
-50% 4.720000
-75% 6.233341
+25% 3.051456
+50% 4.621250
+75% 6.222500
max 8.110000
-Successfully store 'X Without Scaling' in 'X Without Scaling.xlsx' in /home/yucheng/output/data.
+Successfully store 'X Without Scaling' in 'X Without Scaling.xlsx' in
+C:\Users\YSQ\geopi_output\Regression\test\artifacts\data.
(Press Enter key to move forward.)
```
+Then, input Y Set like "2 - CR203(WT%)".
+```python
+-*-*- Data Segmentation - X Set and Y Set-*-*-
+Selected sub data set to create Y data set:
+--------------------
+Index - Column Name
+1 - AL2O3(WT%)
+2 - CR2O3(WT%)
+3 - FEOT(WT%)
+4 - CAO(WT%)
+5 - new Feature
+--------------------
+The selected Y data set:
+Notice: Normally, please choose only one column to be tag column Y, not multiple columns.
+Notice: For classification model training, please choose the label column which has
+distinctive integers.
+Select the data range you want to process.
+Input format:
+Format 1: "[**, **]; **; [**, **]", such as "[1, 3]; 7; [10, 13]" --> you want to deal with the columns 1, 2, 3, 7, 10, 11, 12, 13
+Format 2: "xx", such as "7" --> you want to deal with the columns 7
+@input:2
+```
+
+The prompt of successful operation and basic statistical information would be shown:
+
+```python
+Successfully create Y data set.
+The Selected Data Set:
+ CR2O3(WT%)
+0 1.440
+1 0.578
+2 1.000
+3 0.830
+4 0.740
+.. ...
+93 0.060
+94 0.690
+95 2.910
+96 0.750
+97 0.800
+
+[98 rows x 1 columns]
+Basic Statistical Information:
+Some basic statistic information of the designated data set:
+ CR2O3(WT%)
+count 98.000000
+mean 0.956426
+std 0.553647
+min 0.000000
+25% 0.662500
+50% 0.925000
+75% 1.243656
+max 3.869550
+Successfully store 'Y' in 'Y.xlsx' in
+C:\Users\YSQ\geopi_output\Regression\test\artifacts\data.
+(Press Enter key to move forward.)
+```
+
After this, you may choose to process feature scaling on X Set or not:
@@ -541,10 +561,18 @@ After this, you may choose to process feature scaling on X Set or not:
-*-*- Feature Scaling on X Set -*-*-
1 - Yes
2 - No
-(Data) ➜ @Number:
+(Data) ➜ @Number: 2
+```
+
+In this doc, we choose 2, and for the next step of feature selection, we also choose option 2.
+
+```python
+-*-*- Feature Selection on X set -*-*-
+1 - Yes
+2 - No
+(Data) ➜ @Number:2
```
-In the similar manner, we then set Y Set and check the related information generated onto the screen.
The next step is to split the data into a training set and a test set. The test set will be used to evaluate the performance of the machine learning model that will be trained on the training set. In this example, we set 20% of the data to be set aside as the test set. This means that 80% of the data will be used as the training set. The data split is important to prevent overfitting of the model on the training data and to ensure that the model's performance can be generalized to new, unseen data:
@@ -554,10 +582,17 @@ Note: Normally, set 20% of the dataset aside as test set, such as 0.2
(Data) ➜ @Test Ratio: 0.2
```
-After checking the output, you should be able to see a menu to choose a machine learning model for your data, in this example, we are going to use “2 - Polynomial Regression”:
+
+
+
+//
+
+
+
+After checking the output, you should be able to see a menu to choose a machine learning model for your data, in this example, we are going to use “7 - Extra-Trees”.
```python
--*-*- Model Selection -*-*-:
+-*-*- Model Selection -*-*-
1 - Linear Regression
2 - Polynomial Regression
3 - K-Nearest Neighbors
@@ -566,106 +601,79 @@ After checking the output, you should be able to see a menu to choose a machine
6 - Random Forest
7 - Extra-Trees
8 - Gradient Boosting
-9 - Xgboost
+9 - XGBoost
10 - Multi-layer Perceptron
11 - Lasso Regression
-12 - All models above to be trained
+12 - Elastic Net
+13 - SGD Regression
+14 - BayesianRidge Regression
+15 - All models above to be trained
Which model do you want to apply?(Enter the Corresponding Number)
-(Model) ➜ @Number: 2
+(Model) ➜ @Number:7
```
-After choosing the model, the command line may prompt you to provide more specific options in terms of the model you choose, after offering the options, the program is good to go! And you may check the output like this after processing:
+We have already set up an automated learning program. You can simply choose option '1' to easily access it.
+```python
+Do you want to employ automated machine learning with respect
+to this algorithm?(Enter the Corresponding Number):
+1 - Yes
+2 - No
+(Model) ➜ @Number:1
+```
```python
-*-**-* Polynomial Regression is running ... *-**-*
-Expected Functionality:
-+ Model Score
-+ Cross Validation
-+ Model Prediction
-+ Model Persistence
-+ Predicted vs. Actual Diagram
-+ Residuals Diagram
-+ Permutation Importance Diagram
-+ Polynomial Regression Formula
------* Model Score *-----
-Root Mean Square Error: 1.2981800081993564
-Mean Absolute Error: 0.8666537321359384
-R2 Score: -0.5692041761356125
-Explained Variance Score: -0.5635060495257759
------* Cross Validation *-----
-K-Folds: 10
-* Fit Time *
-Scores: [0.00217414 0.00214863 0.00225115 0.00212574 0.00201654 0.00203323
- 0.00196433 0.00200295 0.00195527 0.00195432]
-Mean: 0.0020626306533813475
-Standard deviation: 9.940905756158756e-05
--------------
-* Score Time *
-Scores: [0.00440168 0.00398946 0.00407624 0.0041182 0.00420284 0.00452423
- 0.00406241 0.00427079 0.00406742 0.00404215]
-Mean: 0.004175543785095215
-Standard deviation: 0.0001651057611709732
--------------
-* Root Mean Square Error *
-Scores: [1.15785222 1.29457522 2.71100276 3.38856833 0.94791697 1.0329962
- 1.54759602 1.8725529 1.82623562 0.84039699]
-Mean: 1.6619693228088945
-Standard deviation: 0.7833005136355865
--------------
-* Mean Absolute Error *
-Scores: [0.86020769 0.85255076 1.71707909 2.17595274 0.73042456 0.8864327
- 1.2754413 1.32740744 1.48587525 0.67660019]
-Mean: 1.1987971734378662
-Standard deviation: 0.4639441214337496
--------------
-* R2 Score *
-Scores: [ 0.3821429 -0.12200627 -0.58303497 -0.98544835 0.3240076 0.02309755
- -0.93382518 -9.20857756 -1.11023532 -0.50902637]
-Mean: -1.2722905973773913
-Standard deviation: 2.6935459556340082
--------------
-* Explained Variance Score *
-Scores: [ 0.42490745 -0.01768215 -0.54672932 -0.90106814 0.32644583 0.18391296
- -0.92481771 -7.4016756 -0.39601889 0.24420376]
-Mean: -0.9008521815781642
-Standard deviation: 2.2175052662305945
--------------
------* Predicted Value Evaluation *-----
-Save figure 'Predicted Value Evaluation - Polynomial Regression' in /home/yucheng/output/images/model_output.
------* True Value vs. Predicted Value *-----
-Save figure 'True Value vs. Predicted Value - Polynomial Regression' in /home/yucheng/output/images/model_output.
------* Polynomial Regression Formula *-----
-y = 1.168AL2O3(WT%)+4.677CR2O3(WT%)-0.085AL2O3(WT%)^2-2.572AL2O3(WT%) CR2O3(WT%)-2.229CR2O3(WT%)^2+0.002AL2O3(WT%)^3+0.14AL2O3(WT%)^2 CR2O3(WT%)+0.762AL2O3(WT%) CR2O3(WT%)^2+0.232CR2O3(WT%)^3+1.4708950432993957
------* Model Prediction *-----
- FEOT(WT%) CAO(WT%)
-0 6.234901 21.516655
-1 3.081208 20.471231
-2 3.082333 19.539309
-3 2.838430 20.666521
-4 2.434649 21.558533
-5 2.478282 21.784115
-6 2.689378 20.075947
-7 2.744644 21.954583
-8 3.336340 22.054664
-9 3.033059 20.288637
-10 3.268753 21.438835
-11 3.129242 22.290128
-12 2.451531 21.640214
-13 2.984390 19.752188
-14 2.513781 21.035197
-15 2.699384 20.676107
-16 2.641574 21.844654
-17 3.449548 20.632201
-18 3.134386 22.138135
-19 2.986511 21.673300
-20 2.899159 19.943711
-21 2.606604 22.146161
-Successfully store 'Y Test Predict' in 'Y Test Predict.xlsx' in /home/yucheng/output/data.
------* Model Persistence *-----
-Successfully store the trained model 'Polynomial Regression' in 'Polynomial_Regression_2023-02-24.pkl' in /home/yucheng/output/trained_models.
-Successfully store the trained model 'Polynomial Regression' in 'Polynomial_Regression_2023-02-24.joblib' in /home/yucheng/output/trained_models.
+-*-*- Feature Engineering on Application Data -*-*-
+The same feature engineering operation will be applied to the
+inference data.
+Successfully construct a new feature new Feature.
+0 NaN
+1 NaN
+2 NaN
+3 25.430000
+4 22.909000
+5 23.211800
+...
+49 25.158800
+50 23.342814
+51 21.512000
+52 25.668000
+53 23.801200
+54 23.825000
+Name: new Feature, dtype: float64
+Successfully store 'Application Data Original' in 'Application Data Original.xlsx' in C:\Users\YSQ\geopi_output\GeoPi - Rock Classification\Regression\artifacts\data.
+Successfully store 'Application Data Feature-Engineering' in 'Application Data Feature-Engineering.xlsx' in C:\Users\YSQ\geopi_output\GeoPi - Rock Classification\Regression\artifacts\data.
+Successfully store 'Application Data Feature-Engineering Selected' in 'Application Data Feature-Engineering Selected.xlsx' in C:\Users\YSQ\geopi_output\GeoPi - Rock Classification\Regression\artifacts\data.
+(Press Enter key to move forward.)
```
+
+After moving to the next step, the Extra-Trees algorithm training will run automatically.
+This includes functionalities such as Model Scoring, Cross Validation, Predicted vs. Actual Diagram, Residuals Diagram, Permutation Importance Diagram, Feature Importance Diagram, Single Tree Diagram, Model Prediction, and Model Persistence.
+You can find the output stored in the specified path.
+
+```python
+-*-*- Transform Pipeline Construction -*-*-
+Build the transform pipeline according to the previous operations.
+Successfully store 'Transform Pipeline Configuration' in 'Transform Pipeline Configuration.txt' in C:\Users\YSQ\geopi_output\GeoPi - Rock Classification\Regression\artifacts.
+(Press Enter key to move forward.)
+
+-*-*- Model Inference -*-*-
+Use the trained model to make predictions on the application data.
+Successfully store 'Application Data Predicted' in 'Application Data Predicted.xlsx' in C:\Users\YSQ\geopi_output\GeoPi - Rock Classification\Regression\artifacts\data.
+Successfully store 'Application Data Feature-Engineering Selected Dropped-Imputed' in 'Application Data Feature-Engineering Selected Dropped-Imputed.xlsx' in C:\Users\YSQ\geopi_output\GeoPi - Rock Classification\Regression\artifacts\data.
+(Press Enter key to move forward.)
```
+
+
+
+Feature Importance - Extra-Trees
+
+Permutation Importance - Extra-Trees
+
+Predicted vs Actual Diagram - Extra-Trees
+
+Residuals Diagram - Extra-Trees
+
+Tree Diagram - Extra-Trees