Releases: ProjectPhysX/FluidX3D
FluidX3D v2.9 (multithreading)
Thank you for using FluidX3D! The v2.9 update makes simulation startup a lot quicker, especially for large multi-GPU simulations:
- added cross-platform
parallel_forimplementation inutilities.hppusingstd::threads - significantly (>4x) faster simulation startup with multithreaded geometry initialization and sanity checks
- faster
calculate_force_on_object()andcalculate_torque_on_object()functions with multithreading - refactoring
- added total runtime and LBM runtime to
lbm.write_status()
Bug fixes:
- fixed bug in voxelization ray direction for re-voxelizing rotating objects
- fixed bug in
Mesh::get_bounding_box_size() - fixed bug in
print_message()function inutilities.hpp
Let the cores go brrrr!

Have fun with the software!
-- Moritz
FluidX3D v2.8 (documentation + polish)
Thank you for using FluidX3D! The v2.8 update doesn't add too many new features, but finally more documentation, loads of refactoring and significant usability improvements:
- finally added more documentation
- cleaned up all sample setups in
setup.cppfor much more beginner-friendly learning - added required extensions in
defines.hppas comments to all setups insetup.cpp - improved loading of composite .stl geometries, by adding an option to omit automatic repositioning of the mesh
- added more functionality to
Meshstruct inutilities.hpp - added
uint3 resolution(float3 box_aspect_ratio, uint memory)function to compute simulation box resolution based on box aspect ratio and VRAM occupation in MB - added
bool lbm.graphics.next_frame(...)function to export images for a specified video length in themain_setupcompute loop - added
VIS_...macros to ease setting visualization modes in headless graphics mode inlbm.graphics.visualization_modes - simulation box dimensions are now automatically made equally divisible by domains for multi-GPU simulations
- made Info/Warning/Error message labels colored
- added Cessna 172 propeller airplane and Bell 222 helicopter setups to showcase how loading of composite .stl geometries and revoxelization of moving parts works
- added Ahmed body setup as an example on how body forces and drag coefficient are computed; expect absolute forces to be too large by up to a factor 2, because even large resolution is not enough to fully capture the turbulent boundary layer in this case; a wall function is needed, I'll scan literature on it
- added optional semi-transparent rendering mode (
#define GRAPHICS_TRANSPARENCY 0.7findefines.hpp)
Bug fixes:
- fixed flickering of streamline visualization in interactive graphics
- improved smooth positioning of streamlines in slice mode
- fixed bug where mass and massex in SURFACE extension were also allocated in CPU RAM (not required)
- fixed bug in Q-criterion isosurface rendering of halo data in multi-GPU mode
- reduced gap width between domains in Q-criterion isosurface rendering in multi-GPU mode
- fixed crash/bug in local memory optimization in mesh voxelization kernel
- removed shared memory optimization from mesh voxelization kernel, as it crashes on Nvidia GPUs with new GPU drivers and is incompatible with old OpenCL 1.0 GPUs
- fixed Info/Warning/Error message formatting for loading files
Some showcases of what v2.8 is capable of:
(click on images to show videos on YouTube)
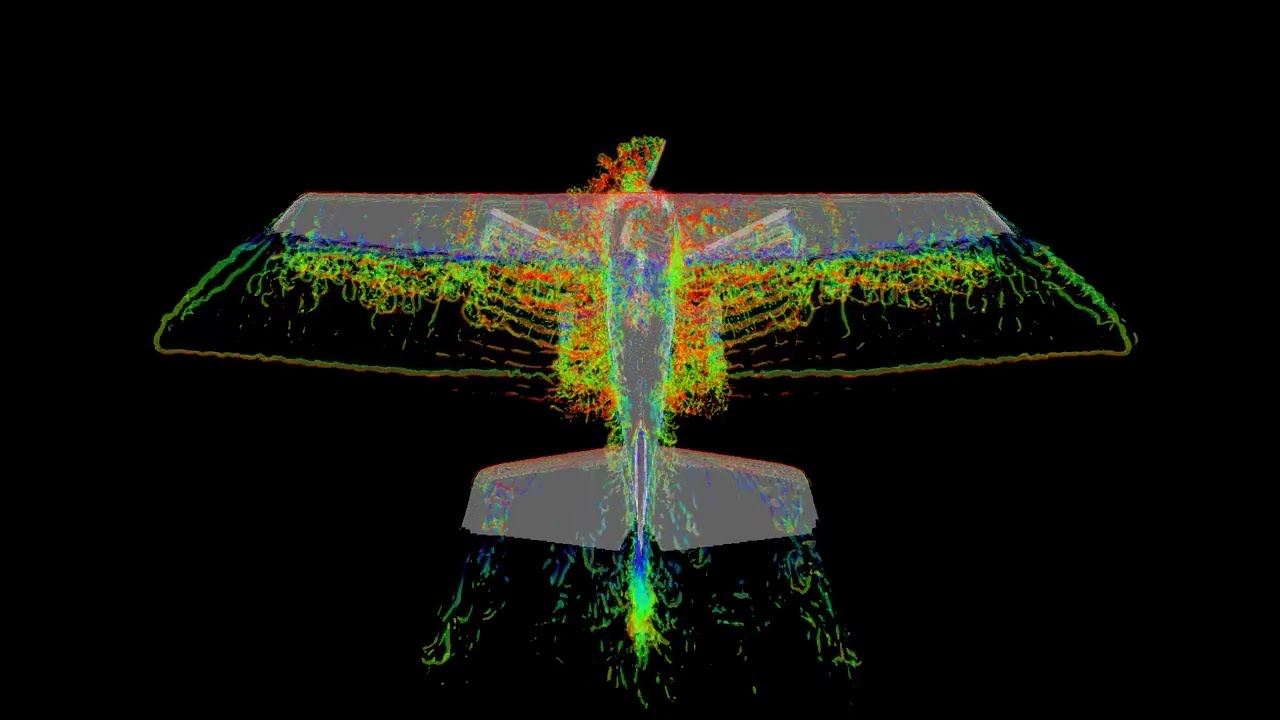

Have fun with the software!
-- Moritz
FluidX3D v2.7 (visualization upgrade)
New features:
- added slice visualization (key 2 / key 3 modes, then switch through slice modes with key T, move slice with keys Q/E)
- made flag wireframe / solid surface visualization kernels toggleable with key 1
- added surface pressure visualization (key 1 when
FORCE_FIELDis enabled andlbm.calculate_force_on_boundaries();is called) - added binary
.vtkexport function for meshes withlbm.write_mesh_to_vtk(Mesh* mesh); - added
time_step_multiplicatorforintegrate_particles()function in PARTICLES extension
Bug fixes:
- made correction of wrong memory reporting on Intel Arc more robust
- fixed bug in
write_file()template functions - reverted back to separate
cl::Contextfor each OpenCL device, as the shared Context otherwise would allocate extra VRAM on all other unused Nvidia GPUs - removed Debug and x86 configurations from Visual Studio solution file (one less complication for compiling)
- fixed bug that particles could get too close to walls and get stuck, or leave the fluid phase (added boundary force)
Preview on YouTube:

FluidX3D v2.6 (Intel Arc patch)
FluidX3D is now fully operational on Intel Arc GPUs (I patched their OpenCL driver issues):
- now VRAM allocations >4GB are possible
- this is necessary to use the full VRAM for simulations at the largest possible resolution
- perfromance impact is 1.5%, not significant
- correct VRAM capacity is reported on Intel Arc A770, A750, A580, A380 (driver wrongly reports only 80% on Windows and 95% on Linux)
FluidX3D v2.5 (raytracing overhaul)
Raytracing overhaul:
- implemented light absorption in fluid for raytracing graphics (no performance impact, demo on YouTube)
- improved raytracing framerate when camera is inside fluid
- fixed skybox pole flickering artifacts
- refactored raytracing code
Other bug fixes:
- fixed bug where moving objects during re-voxelization would leave an erroneous trail of solid grid cells behind (increased mesh bounding box by 2 cells tolerance)
FluidX3D v2.4 (UI improvements)
UI improvements:
- added a help menu with key H that shows keyboard/mouse controls, visualization settings and simulation stats
- zoom control with keyboard is now keys +/- instead of ./,
- print camera settings in console is now key G instead of H
- a simple mouseclick now frees/locks the cursor additionally to key U
- if the grid resolution is set larger than memory capacity allows, an error will now be printed, suggesting the largest possible grid resolution, so users don't have to guess how large the grid can be
- all source files are now encoded in UTF-8
Minor optimizations:
- the allocation size for the transfer buffers is now the not the maximum of Ax/Ay/Az, but only the maximum of the areas that are actually communicated; saves a few MB VRAM in some occasions
- the transfer buffer for fi is now used as faster array of structures instead of structure of arrays; performance difference is negligible
- refactoring in smart_device_selection() function
- upgraded OpenCL-Wrapper: devices from the same vendor are now in the same OpenCL Context, allowing migration of Memory objects; event-driven synchronisation can now be used
Bug fixes:
- fixed bug in temperature equilibrium function for temperature extension; lattice speed of sound in D3Q7 is 1/2 and not 1/sqrt(3)
- made erroneous double literal in skybox color functions, which is a bug for Intel iGPUs, a float literal
- fixed bug in make.sh where multiple console parameters for multi-GPU device IDs would not get forwarded from the ./make.sh call to the bin/FluidX3D executable
- fixed bug in mouse rotation in Windows when cursor is free but kept getting centered during rotation
- fixed bug in interactive graphics where text labels on the right side of the screen would not get drawn on both left/right eye screens in VR mode
- fixed bug in LBM::voxelize_stl() size parameter standard initialization
FluidX3D v2.3 (particles)
Particle update:
- added particles with immersed-boundary method (either passive or 2-way-coupled, only supported with single-GPU)
- minor optimization to GPU voxelization algorithm (workgroup threads outside mesh bounding-box return after ray-mesh intersections have been found)
- displayed GPU memory allocation size is now fully accurate
- fixed bug in
write_line()function insrc/utilities.hpp - removed
.exefile extension for Linux/macOS - refactoring and cosmetics
FluidX3D v2.2 (velocity voxelization)
Velocity voxelization update:
- simulation of moving/rotating geometry is now possible, here is a demo
- added option to voxelize moving/rotating geometry on GPU, with automatic velocity initialization for each grid point based on center of rotation, linear velocity and rotational velocity
- cells that are converted from solid->fluid during re-voxelization now have their DDFs properly initialized
- added option to not auto-scale mesh during
read_stl(...), with negativesizeparameter
- added kernel for solid boundary rendering with marching-cubes
FluidX3D v2.1 (fast voxelization)
Fast GPU voxelization update:
- new algorithm for
.stlmesh GPU voxelization: ~500x faster now, from minutes to milliseconds - added unvoxelize kernel, to quickly remove all boundaries in the mesh bounding box.
- removed old hull voxelization algorithm
Old: naive GPU voxelization
- For each voxel in the 3D grid, cast a ray from the voxel center in an arbitrary direction, and check with all mesh triangles for intersection.
- Count the number of intersections.
- Odd number of intersections means the voxel is inside.
- Runtime: N³×Triangles
New: fast GPU voxelization
- Only for the 2D bottom layer of grid points, shoot vertical rays upward and check with all mesh triangles for intersection.
- The vertical rays pass through all voxels in the columns above, so these don't have to be checked for ray-mesh intersection at all.
- Store all intersection distances in a short array in registers.
- Sort this array with insertion sort.
- Iterate through the vertical column of voxels.
- The first voxel is inside/outside depending on odd/even total intersection count.
- Each time one of the stored distances in the sorted array is passed, switch inside/outside state.
- Optimizations
- Only check inside the bounding box of the mesh.
- Don't always start from the bottom (z-direction), but from the direction where the mesh bounding box has the smallest cross-section area, so the smallest number of ray-mesh intersections have to be tested.
- To avoid errors on the odd/even total number of intersections, shoot a second ray in the opposite direction and only count the intersection number. Both have to be odd for the bottom voxel to start in inside state.
- Runtime: N²×Triangles, if N=500, this is 500x faster than naive voxelization
Known issues:
- voxelization might not always produce binary identical results in multi-GPU (floating-point round-off on ray-triangle instersection distances may differ for different ray origin) --> fixed in v2.16!
FluidX3D v2.0 (multi-GPU upgrade)
Big multi-GPU Update:
- Multi-GPU simulations are now possible on a single node (PC/laptop/server), allowing to pool VRAM from multiple GPUs.
- Easy setup with minimal changes to the user: instead of
LBM lbm(Nx, Ny, Nz, nu, ...);, useLBM lbm(Nx, Ny, Nz, Dx, Dy, Dz, nu, ...);, withDx/Dy/Dzindicating how many domains (GPUs) in each spatial direction to use. By default, all identical GPUs will be automatically assigned their domains, however the GPUs can also be manually set with a list of their indices:./make.sh 2 6 3 4or/bin/FluidX3D 2 6 3 4. - All extensions are supported and validated to produce binary identical results compared to single-GPU simulations.
- Multi-GPU also works with non-identical GPUs, regardless of vendor. Yes, you can run FluidX3D on unholy combinations of Nvidia/AMD/Intel GPUs/CPUs at the same time. I only recommend similar memory capacity and bandwidth, as the weakest GPU will bottleneck performance.
- No SLI/Crossfire/NVLink/InfinityFabric is required. All communication runs over PCIe and is compatible with all hardware.
- No MPI installation is required.
- Total grid resolution must be equally divisible into domains, such that all domains are the same size.
- The resolution of each domain is restricted to 4.29 billion grid points (2³², 225GB VRAM), but domain number and thus total grid resolution is unrestricted.
- Under the hood: Complete re-write of C++ backend, to account for the domain decomposition architecture. The code is already fully optimized and shortened for maximum maintainability/upgradeability.
- Easy setup with minimal changes to the user: instead of
- Grid resolution can now be arbitrary and is not anymore restricted to the condition
(Nx*Ny*Nz)%WORKGROUP_SIZE==0.
Known issues:
- Raytracing graphics are disabled for multi-GPU. The simulated light rays would have to travel through the entire simulation box, crossing domain boundaries. This is not easily possible, because each GPU only keeps its own domain in VRAM.