简体中文 | English
在实际生产环境中,许多应用对部署策略的性能指标(尤其是响应速度)有着较严苛的标准,以确保系统的高效运行与用户体验的流畅性。为此,PaddleX 提供高性能推理插件,旨在对模型推理及前后处理进行深度性能优化,实现端到端流程的显著提速。本文档将首先介绍高性能推理插件的安装和使用方式,然后列举目前支持使用高性能推理插件的产线与模型。
使用高性能推理插件前,请确保您已经按照PaddleX本地安装教程 完成了PaddleX的安装,且按照PaddleX产线命令行使用说明或PaddleX产线Python脚本使用说明跑通了产线的基本推理。
在下表中根据处理器架构、操作系统、设备类型、Python 版本等信息,找到对应的安装指令并在部署环境中执行:
- 当设备类型为 GPU 时,请使用与环境匹配的 CUDA 和 cuDNN 版本对应的安装指令,否则,将无法正常使用高性能推理插件。
- 对于 Linux 系统,使用 Bash 执行安装指令。
- 当设备类型为 CPU 时,安装的高性能推理插件仅支持使用 CPU 进行推理;对于其他设备类型,安装的高性能推理插件则支持使用 CPU 或其他设备进行推理。
在 飞桨AI Studio星河社区-人工智能学习与实训社区 页面的“开源模型产线部署序列号咨询与获取”部分选择“立即获取”,如下图所示:

选择需要部署的产线,并点击“获取”。之后,可以在页面下方的“开源产线部署SDK序列号管理”部分找到获取到的序列号:
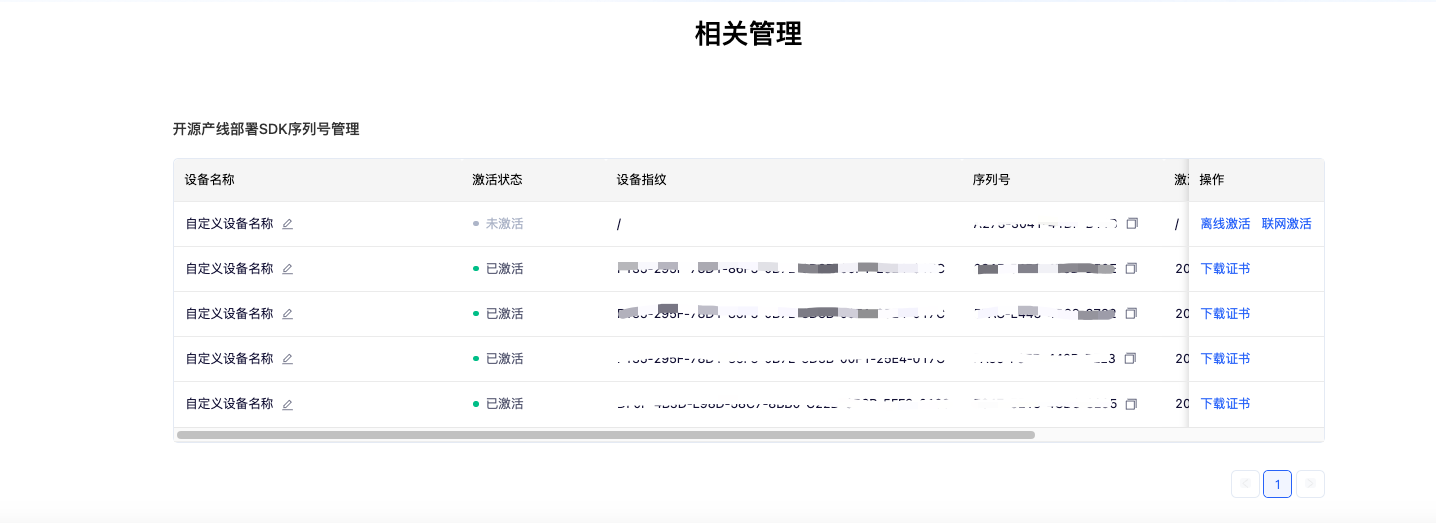
使用序列号完成激活后,即可使用高性能推理插件。PaddleX 提供离线激活和在线激活两种方式(均只支持 Linux 系统):
- 联网激活:在使用推理 API 或 CLI 时,通过参数指定序列号及联网激活,使程序自动完成激活。
- 离线激活:按照序列号管理界面中的指引(点击“操作”中的“离线激活”),获取机器的设备指纹,并将序列号与设备指纹绑定以获取证书,完成激活。使用这种激活方式,需要手动将证书存放在机器的
${HOME}/.baidu/paddlex/licenses目录中(如果目录不存在,需要创建目录),并在使用推理 API 或 CLI 时指定序列号。 请注意:每个序列号只能绑定到唯一的设备指纹,且只能绑定一次。这意味着用户如果使用不同的机器部署模型,则必须为每台机器准备单独的序列号。
在启用高性能插件前,请确保当前环境的 LD_LIBRARY_PATH 没有指定 TensorRT 的共享库目录,因为插件中已经集成了 TensorRT,避免 TensorRT 版本冲突导致插件无法正常使用。
对于 PaddleX CLI,指定 --use_hpip,并设置序列号,即可启用高性能推理插件。如果希望进行联网激活,在第一次使用序列号时,需指定 --update_license,以通用图像分类产线为例:
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
+ --use_hpip \
+ --serial_number {序列号}
# 如果希望进行联网激活
paddlex \
--pipeline image_classification \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \
--device gpu:0 \
+ --use_hpip \
+ --serial_number {序列号}
+ --update_license对于 PaddleX Python API,启用高性能推理插件的方法类似。仍以通用图像分类产线为例:
from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="image_classification",
+ use_hpip=True,
+ serial_number="{序列号}",
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg")启用高性能推理插件得到的推理结果与未启用插件时一致。对于部分模型,在首次启用高性能推理插件时,可能需要花费较长时间完成推理引擎的构建。PaddleX 将在推理引擎的第一次构建完成后将相关信息缓存在模型目录,并在后续复用缓存中的内容以提升初始化速度。
PaddleX 为每个模型提供默认的高性能推理配置,并将其存储在模型的配置文件中。由于实际部署环境的多样性,使用默认配置可能无法在特定环境中获取理想的性能,甚至可能出现推理失败的情况。对于默认配置无法满足要求的情形,可以通过如下方式,尝试更换模型的推理后端:
-
找到模型目录中的
inference.yml文件,定位到其中的Hpi字段; -
修改
selected_backends的值。具体而言,selected_backends可能被设置如下:selected_backends: cpu: paddle_infer gpu: onnx_runtime其中每一项均按照
{设备类型}: {推理后端名称}的格式填写,默认选用在官方测试环境中推理耗时最短的后端。supported_backends中记录了官方测试环境中模型支持的推理后端,可供参考。 目前所有可选的推理后端如下:paddle_infer:标准的 Paddle Inference 推理引擎。支持 CPU 和 GPU。paddle_tensorrt:Paddle-TensorRT,Paddle 官方出品的高性能深度学习推理库,采用子图的形式对 TensorRT 进行了集成,以实现进一步优化加速。仅支持 GPU。openvino:OpenVINO,Intel 提供的深度学习推理工具,优化了多种 Intel 硬件上的模型推理性能。仅支持 CPU。onnx_runtime:ONNX Runtime,跨平台、高性能的推理引擎。支持 CPU 和 GPU。tensorrt:TensorRT,NVIDIA 提供的高性能深度学习推理库,针对 NVIDIA GPU 进行优化以提升速度。仅支持 GPU。
以下是目前的官方测试环境的部分关键信息:
- CPU:Intel Xeon Gold 5117
- GPU:NVIDIA Tesla T4
- CUDA版本:11.8
- cuDNN版本:8.6
- Docker 镜像:registry.baidubce.com/paddlepaddle/paddle:latest-dev-cuda11.8-cudnn8.6-trt8.5-gcc82
| 模型产线 | 产线模块 | 具体模型 |
|---|---|---|
| 通用图像分类 | 图像分类 | ResNet18 ResNet34 moreResNet50ResNet101 ResNet152 ResNet18_vd ResNet34_vd ResNet50_vd ResNet101_vd ResNet152_vd ResNet200_vd PP-LCNet_x0_25 PP-LCNet_x0_35 PP-LCNet_x0_5 PP-LCNet_x0_75 PP-LCNet_x1_0 PP-LCNet_x1_5 PP-LCNet_x2_0 PP-LCNet_x2_5 PP-LCNetV2_small PP-LCNetV2_base PP-LCNetV2_large MobileNetV3_large_x0_35 MobileNetV3_large_x0_5 MobileNetV3_large_x0_75 MobileNetV3_large_x1_0 MobileNetV3_large_x1_25 MobileNetV3_small_x0_35 MobileNetV3_small_x0_5 MobileNetV3_small_x0_75 MobileNetV3_small_x1_0 MobileNetV3_small_x1_25 ConvNeXt_tiny ConvNeXt_small ConvNeXt_base_224 ConvNeXt_base_384 ConvNeXt_large_224 ConvNeXt_large_384 MobileNetV1_x0_25 MobileNetV1_x0_5 MobileNetV1_x0_75 MobileNetV1_x1_0 MobileNetV2_x0_25 MobileNetV2_x0_5 MobileNetV2_x1_0 MobileNetV2_x1_5 MobileNetV2_x2_0 SwinTransformer_tiny_patch4_window7_224 SwinTransformer_small_patch4_window7_224 SwinTransformer_base_patch4_window7_224 SwinTransformer_base_patch4_window12_384 SwinTransformer_large_patch4_window7_224 SwinTransformer_large_patch4_window12_384 PP-HGNet_small PP-HGNet_tiny PP-HGNet_base PP-HGNetV2-B0 PP-HGNetV2-B1 PP-HGNetV2-B2 PP-HGNetV2-B3 PP-HGNetV2-B4 PP-HGNetV2-B5 PP-HGNetV2-B6 CLIP_vit_base_patch16_224 CLIP_vit_large_patch14_224 |
| 通用目标检测 | 目标检测 | PP-YOLOE_plus-S PP-YOLOE_plus-M morePP-YOLOE_plus-LPP-YOLOE_plus-X YOLOX-N YOLOX-T YOLOX-S YOLOX-M YOLOX-L YOLOX-X YOLOv3-DarkNet53 YOLOv3-ResNet50_vd_DCN YOLOv3-MobileNetV3 RT-DETR-R18 RT-DETR-R50 RT-DETR-L RT-DETR-H RT-DETR-X PicoDet-S PicoDet-L |
| 通用语义分割 | 语义分割 | Deeplabv3-R50 Deeplabv3-R101 moreDeeplabv3_Plus-R50Deeplabv3_Plus-R101 PP-LiteSeg-T OCRNet_HRNet-W48 OCRNet_HRNet-W18 SeaFormer_tiny SeaFormer_small SeaFormer_base SeaFormer_large SegFormer-B0 SegFormer-B1 SegFormer-B2 SegFormer-B3 SegFormer-B4 SegFormer-B5 |
| 通用实例分割 | 实例分割 | Mask-RT-DETR-L Mask-RT-DETR-H |
| 通用OCR | 文本检测 | PP-OCRv4_server_det PP-OCRv4_mobile_det |
| 文本识别 | PP-OCRv4_server_rec PP-OCRv4_mobile_rec ch_RepSVTR_rec ch_SVTRv2_rec |
|
| 印章文本识别 | 版面区域分析 | PicoDet-S_layout_3cls PicoDet-S_layout_17cls morePicoDet-L_layout_3clsPicoDet-L_layout_17cls RT-DETR-H_layout_3cls RT-DETR-H_layout_17cls |
| 印章文本检测 | PP-OCRv4_server_seal_det PP-OCRv4_mobile_seal_det |
|
| 文本识别 | PP-OCRv4_mobile_rec PP-OCRv4_server_rec |
|
| 通用表格识别 | 版面区域检测 | PicoDet_layout_1x |
| 表格识别 | SLANet | |
| SLANet_plus | ||
| 文本检测 | PP-OCRv4_server_det PP-OCRv4_mobile_det |
|
| 文本识别 | PP-OCRv4_server_rec PP-OCRv4_mobile_rec ch_RepSVTR_rec ch_SVTRv2_rec |
|
| 文档场景信息抽取v3 | 表格识别 | SLANet |
| SLANet_plus | ||
| 版面区域检测 | PicoDet_layout_1x | |
| 文本检测 | PP-OCRv4_server_det | |
| PP-OCRv4_mobile_det | ||
| 文本识别 | PP-OCRv4_server_rec | |
| PP-OCRv4_mobile_rec | ||
| ch_RepSVTR_rec | ||
| ch_SVTRv2_rec | ||
| 印章文本检测 | PP-OCRv4_server_seal_det | |
| PP-OCRv4_mobile_seal_det | ||
| 文本图像矫正 | UVDoc | |
| 文档图像方向分类 | PP-LCNet_x1_0_doc_ori |