[0-9]+(?:\.[0-9]+)*) # release segment
- (?P # pre-release
- [-_\.]?
- (?P(a|b|c|rc|alpha|beta|pre|preview))
- [-_\.]?
- (?P[0-9]+)?
- )?
- (?P # post release
- (?:-(?P[0-9]+))
- |
- (?:
- [-_\.]?
- (?Ppost|rev|r)
- [-_\.]?
- (?P[0-9]+)?
- )
- )?
- (?P # dev release
- [-_\.]?
- (?Pdev)
- [-_\.]?
- (?P[0-9]+)?
- )?
- )
- (?:\+(?P[a-z0-9]+(?:[-_\.][a-z0-9]+)*))? # local version
-"""
-
-
-class Version(_BaseVersion):
-
- _regex = re.compile(r"^\s*" + VERSION_PATTERN + r"\s*$", re.VERBOSE | re.IGNORECASE)
-
- def __init__(self, version: str) -> None:
-
- # Validate the version and parse it into pieces
- match = self._regex.search(version)
- if not match:
- raise InvalidVersion(f"Invalid version: '{version}'")
-
- # Store the parsed out pieces of the version
- self._version = _Version(
- epoch=int(match.group("epoch")) if match.group("epoch") else 0,
- release=tuple(int(i) for i in match.group("release").split(".")),
- pre=_parse_letter_version(match.group("pre_l"), match.group("pre_n")),
- post=_parse_letter_version(
- match.group("post_l"), match.group("post_n1") or match.group("post_n2")
- ),
- dev=_parse_letter_version(match.group("dev_l"), match.group("dev_n")),
- local=_parse_local_version(match.group("local")),
- )
-
- # Generate a key which will be used for sorting
- self._key = _cmpkey(
- self._version.epoch,
- self._version.release,
- self._version.pre,
- self._version.post,
- self._version.dev,
- self._version.local,
- )
-
- def __repr__(self) -> str:
- return f""
-
- def __str__(self) -> str:
- parts = []
-
- # Epoch
- if self.epoch != 0:
- parts.append(f"{self.epoch}!")
-
- # Release segment
- parts.append(".".join(str(x) for x in self.release))
-
- # Pre-release
- if self.pre is not None:
- parts.append("".join(str(x) for x in self.pre))
-
- # Post-release
- if self.post is not None:
- parts.append(f".post{self.post}")
-
- # Development release
- if self.dev is not None:
- parts.append(f".dev{self.dev}")
-
- # Local version segment
- if self.local is not None:
- parts.append(f"+{self.local}")
-
- return "".join(parts)
-
- @property
- def epoch(self) -> int:
- _epoch: int = self._version.epoch
- return _epoch
-
- @property
- def release(self) -> Tuple[int, ...]:
- _release: Tuple[int, ...] = self._version.release
- return _release
-
- @property
- def pre(self) -> Optional[Tuple[str, int]]:
- _pre: Optional[Tuple[str, int]] = self._version.pre
- return _pre
-
- @property
- def post(self) -> Optional[int]:
- return self._version.post[1] if self._version.post else None
-
- @property
- def dev(self) -> Optional[int]:
- return self._version.dev[1] if self._version.dev else None
-
- @property
- def local(self) -> Optional[str]:
- if self._version.local:
- return ".".join(str(x) for x in self._version.local)
- else:
- return None
-
- @property
- def public(self) -> str:
- return str(self).split("+", 1)[0]
-
- @property
- def base_version(self) -> str:
- parts = []
-
- # Epoch
- if self.epoch != 0:
- parts.append(f"{self.epoch}!")
-
- # Release segment
- parts.append(".".join(str(x) for x in self.release))
-
- return "".join(parts)
-
- @property
- def is_prerelease(self) -> bool:
- return self.dev is not None or self.pre is not None
-
- @property
- def is_postrelease(self) -> bool:
- return self.post is not None
-
- @property
- def is_devrelease(self) -> bool:
- return self.dev is not None
-
- @property
- def major(self) -> int:
- return self.release[0] if len(self.release) >= 1 else 0
-
- @property
- def minor(self) -> int:
- return self.release[1] if len(self.release) >= 2 else 0
-
- @property
- def micro(self) -> int:
- return self.release[2] if len(self.release) >= 3 else 0
-
-
-def _parse_letter_version(
- letter: str, number: Union[str, bytes, SupportsInt]
-) -> Optional[Tuple[str, int]]:
-
- if letter:
- # We consider there to be an implicit 0 in a pre-release if there is
- # not a numeral associated with it.
- if number is None:
- number = 0
-
- # We normalize any letters to their lower case form
- letter = letter.lower()
-
- # We consider some words to be alternate spellings of other words and
- # in those cases we want to normalize the spellings to our preferred
- # spelling.
- if letter == "alpha":
- letter = "a"
- elif letter == "beta":
- letter = "b"
- elif letter in ["c", "pre", "preview"]:
- letter = "rc"
- elif letter in ["rev", "r"]:
- letter = "post"
-
- return letter, int(number)
- if not letter and number:
- # We assume if we are given a number, but we are not given a letter
- # then this is using the implicit post release syntax (e.g. 1.0-1)
- letter = "post"
-
- return letter, int(number)
-
- return None
-
-
-_local_version_separators = re.compile(r"[\._-]")
-
-
-def _parse_local_version(local: str) -> Optional[LocalType]:
- """
- Takes a string like abc.1.twelve and turns it into ("abc", 1, "twelve").
- """
- if local is not None:
- return tuple(
- part.lower() if not part.isdigit() else int(part)
- for part in _local_version_separators.split(local)
- )
- return None
-
-
-def _cmpkey(
- epoch: int,
- release: Tuple[int, ...],
- pre: Optional[Tuple[str, int]],
- post: Optional[Tuple[str, int]],
- dev: Optional[Tuple[str, int]],
- local: Optional[Tuple[SubLocalType]],
-) -> CmpKey:
-
- # When we compare a release version, we want to compare it with all of the
- # trailing zeros removed. So we'll use a reverse the list, drop all the now
- # leading zeros until we come to something non zero, then take the rest
- # re-reverse it back into the correct order and make it a tuple and use
- # that for our sorting key.
- _release = tuple(
- reversed(list(itertools.dropwhile(lambda x: x == 0, reversed(release))))
- )
-
- # We need to "trick" the sorting algorithm to put 1.0.dev0 before 1.0a0.
- # We'll do this by abusing the pre segment, but we _only_ want to do this
- # if there is not a pre or a post segment. If we have one of those then
- # the normal sorting rules will handle this case correctly.
- if pre is None and post is None and dev is not None:
- _pre: PrePostDevType = NegativeInfinity
- # Versions without a pre-release (except as noted above) should sort after
- # those with one.
- elif pre is None:
- _pre = Infinity
- else:
- _pre = pre
-
- # Versions without a post segment should sort before those with one.
- if post is None:
- _post: PrePostDevType = NegativeInfinity
-
- else:
- _post = post
-
- # Versions without a development segment should sort after those with one.
- if dev is None:
- _dev: PrePostDevType = Infinity
-
- else:
- _dev = dev
-
- if local is None:
- # Versions without a local segment should sort before those with one.
- _local: LocalType = NegativeInfinity
- else:
- # Versions with a local segment need that segment parsed to implement
- # the sorting rules in PEP440.
- # - Alpha numeric segments sort before numeric segments
- # - Alpha numeric segments sort lexicographically
- # - Numeric segments sort numerically
- # - Shorter versions sort before longer versions when the prefixes
- # match exactly
- _local = tuple(
- (i, "") if isinstance(i, int) else (NegativeInfinity, i) for i in local
- )
-
- return epoch, _release, _pre, _post, _dev, _local
diff --git a/venv/lib/python3.11/site-packages/pip/_vendor/pkg_resources/__init__.py b/venv/lib/python3.11/site-packages/pip/_vendor/pkg_resources/__init__.py
deleted file mode 100644
index ad27940..0000000
--- a/venv/lib/python3.11/site-packages/pip/_vendor/pkg_resources/__init__.py
+++ /dev/null
@@ -1,3361 +0,0 @@
-"""
-Package resource API
---------------------
-
-A resource is a logical file contained within a package, or a logical
-subdirectory thereof. The package resource API expects resource names
-to have their path parts separated with ``/``, *not* whatever the local
-path separator is. Do not use os.path operations to manipulate resource
-names being passed into the API.
-
-The package resource API is designed to work with normal filesystem packages,
-.egg files, and unpacked .egg files. It can also work in a limited way with
-.zip files and with custom PEP 302 loaders that support the ``get_data()``
-method.
-
-This module is deprecated. Users are directed to :mod:`importlib.resources`,
-:mod:`importlib.metadata` and :pypi:`packaging` instead.
-"""
-
-import sys
-import os
-import io
-import time
-import re
-import types
-import zipfile
-import zipimport
-import warnings
-import stat
-import functools
-import pkgutil
-import operator
-import platform
-import collections
-import plistlib
-import email.parser
-import errno
-import tempfile
-import textwrap
-import inspect
-import ntpath
-import posixpath
-import importlib
-from pkgutil import get_importer
-
-try:
- import _imp
-except ImportError:
- # Python 3.2 compatibility
- import imp as _imp
-
-try:
- FileExistsError
-except NameError:
- FileExistsError = OSError
-
-# capture these to bypass sandboxing
-from os import utime
-
-try:
- from os import mkdir, rename, unlink
-
- WRITE_SUPPORT = True
-except ImportError:
- # no write support, probably under GAE
- WRITE_SUPPORT = False
-
-from os import open as os_open
-from os.path import isdir, split
-
-try:
- import importlib.machinery as importlib_machinery
-
- # access attribute to force import under delayed import mechanisms.
- importlib_machinery.__name__
-except ImportError:
- importlib_machinery = None
-
-from pip._internal.utils._jaraco_text import (
- yield_lines,
- drop_comment,
- join_continuation,
-)
-
-from pip._vendor import platformdirs
-from pip._vendor import packaging
-
-__import__('pip._vendor.packaging.version')
-__import__('pip._vendor.packaging.specifiers')
-__import__('pip._vendor.packaging.requirements')
-__import__('pip._vendor.packaging.markers')
-__import__('pip._vendor.packaging.utils')
-
-if sys.version_info < (3, 5):
- raise RuntimeError("Python 3.5 or later is required")
-
-# declare some globals that will be defined later to
-# satisfy the linters.
-require = None
-working_set = None
-add_activation_listener = None
-resources_stream = None
-cleanup_resources = None
-resource_dir = None
-resource_stream = None
-set_extraction_path = None
-resource_isdir = None
-resource_string = None
-iter_entry_points = None
-resource_listdir = None
-resource_filename = None
-resource_exists = None
-_distribution_finders = None
-_namespace_handlers = None
-_namespace_packages = None
-
-
-warnings.warn(
- "pkg_resources is deprecated as an API. "
- "See https://setuptools.pypa.io/en/latest/pkg_resources.html",
- DeprecationWarning,
- stacklevel=2
-)
-
-
-_PEP440_FALLBACK = re.compile(r"^v?(?P(?:[0-9]+!)?[0-9]+(?:\.[0-9]+)*)", re.I)
-
-
-class PEP440Warning(RuntimeWarning):
- """
- Used when there is an issue with a version or specifier not complying with
- PEP 440.
- """
-
-
-parse_version = packaging.version.Version
-
-
-_state_vars = {}
-
-
-def _declare_state(vartype, **kw):
- globals().update(kw)
- _state_vars.update(dict.fromkeys(kw, vartype))
-
-
-def __getstate__():
- state = {}
- g = globals()
- for k, v in _state_vars.items():
- state[k] = g['_sget_' + v](g[k])
- return state
-
-
-def __setstate__(state):
- g = globals()
- for k, v in state.items():
- g['_sset_' + _state_vars[k]](k, g[k], v)
- return state
-
-
-def _sget_dict(val):
- return val.copy()
-
-
-def _sset_dict(key, ob, state):
- ob.clear()
- ob.update(state)
-
-
-def _sget_object(val):
- return val.__getstate__()
-
-
-def _sset_object(key, ob, state):
- ob.__setstate__(state)
-
-
-_sget_none = _sset_none = lambda *args: None
-
-
-def get_supported_platform():
- """Return this platform's maximum compatible version.
-
- distutils.util.get_platform() normally reports the minimum version
- of macOS that would be required to *use* extensions produced by
- distutils. But what we want when checking compatibility is to know the
- version of macOS that we are *running*. To allow usage of packages that
- explicitly require a newer version of macOS, we must also know the
- current version of the OS.
-
- If this condition occurs for any other platform with a version in its
- platform strings, this function should be extended accordingly.
- """
- plat = get_build_platform()
- m = macosVersionString.match(plat)
- if m is not None and sys.platform == "darwin":
- try:
- plat = 'macosx-%s-%s' % ('.'.join(_macos_vers()[:2]), m.group(3))
- except ValueError:
- # not macOS
- pass
- return plat
-
-
-__all__ = [
- # Basic resource access and distribution/entry point discovery
- 'require',
- 'run_script',
- 'get_provider',
- 'get_distribution',
- 'load_entry_point',
- 'get_entry_map',
- 'get_entry_info',
- 'iter_entry_points',
- 'resource_string',
- 'resource_stream',
- 'resource_filename',
- 'resource_listdir',
- 'resource_exists',
- 'resource_isdir',
- # Environmental control
- 'declare_namespace',
- 'working_set',
- 'add_activation_listener',
- 'find_distributions',
- 'set_extraction_path',
- 'cleanup_resources',
- 'get_default_cache',
- # Primary implementation classes
- 'Environment',
- 'WorkingSet',
- 'ResourceManager',
- 'Distribution',
- 'Requirement',
- 'EntryPoint',
- # Exceptions
- 'ResolutionError',
- 'VersionConflict',
- 'DistributionNotFound',
- 'UnknownExtra',
- 'ExtractionError',
- # Warnings
- 'PEP440Warning',
- # Parsing functions and string utilities
- 'parse_requirements',
- 'parse_version',
- 'safe_name',
- 'safe_version',
- 'get_platform',
- 'compatible_platforms',
- 'yield_lines',
- 'split_sections',
- 'safe_extra',
- 'to_filename',
- 'invalid_marker',
- 'evaluate_marker',
- # filesystem utilities
- 'ensure_directory',
- 'normalize_path',
- # Distribution "precedence" constants
- 'EGG_DIST',
- 'BINARY_DIST',
- 'SOURCE_DIST',
- 'CHECKOUT_DIST',
- 'DEVELOP_DIST',
- # "Provider" interfaces, implementations, and registration/lookup APIs
- 'IMetadataProvider',
- 'IResourceProvider',
- 'FileMetadata',
- 'PathMetadata',
- 'EggMetadata',
- 'EmptyProvider',
- 'empty_provider',
- 'NullProvider',
- 'EggProvider',
- 'DefaultProvider',
- 'ZipProvider',
- 'register_finder',
- 'register_namespace_handler',
- 'register_loader_type',
- 'fixup_namespace_packages',
- 'get_importer',
- # Warnings
- 'PkgResourcesDeprecationWarning',
- # Deprecated/backward compatibility only
- 'run_main',
- 'AvailableDistributions',
-]
-
-
-class ResolutionError(Exception):
- """Abstract base for dependency resolution errors"""
-
- def __repr__(self):
- return self.__class__.__name__ + repr(self.args)
-
-
-class VersionConflict(ResolutionError):
- """
- An already-installed version conflicts with the requested version.
-
- Should be initialized with the installed Distribution and the requested
- Requirement.
- """
-
- _template = "{self.dist} is installed but {self.req} is required"
-
- @property
- def dist(self):
- return self.args[0]
-
- @property
- def req(self):
- return self.args[1]
-
- def report(self):
- return self._template.format(**locals())
-
- def with_context(self, required_by):
- """
- If required_by is non-empty, return a version of self that is a
- ContextualVersionConflict.
- """
- if not required_by:
- return self
- args = self.args + (required_by,)
- return ContextualVersionConflict(*args)
-
-
-class ContextualVersionConflict(VersionConflict):
- """
- A VersionConflict that accepts a third parameter, the set of the
- requirements that required the installed Distribution.
- """
-
- _template = VersionConflict._template + ' by {self.required_by}'
-
- @property
- def required_by(self):
- return self.args[2]
-
-
-class DistributionNotFound(ResolutionError):
- """A requested distribution was not found"""
-
- _template = (
- "The '{self.req}' distribution was not found "
- "and is required by {self.requirers_str}"
- )
-
- @property
- def req(self):
- return self.args[0]
-
- @property
- def requirers(self):
- return self.args[1]
-
- @property
- def requirers_str(self):
- if not self.requirers:
- return 'the application'
- return ', '.join(self.requirers)
-
- def report(self):
- return self._template.format(**locals())
-
- def __str__(self):
- return self.report()
-
-
-class UnknownExtra(ResolutionError):
- """Distribution doesn't have an "extra feature" of the given name"""
-
-
-_provider_factories = {}
-
-PY_MAJOR = '{}.{}'.format(*sys.version_info)
-EGG_DIST = 3
-BINARY_DIST = 2
-SOURCE_DIST = 1
-CHECKOUT_DIST = 0
-DEVELOP_DIST = -1
-
-
-def register_loader_type(loader_type, provider_factory):
- """Register `provider_factory` to make providers for `loader_type`
-
- `loader_type` is the type or class of a PEP 302 ``module.__loader__``,
- and `provider_factory` is a function that, passed a *module* object,
- returns an ``IResourceProvider`` for that module.
- """
- _provider_factories[loader_type] = provider_factory
-
-
-def get_provider(moduleOrReq):
- """Return an IResourceProvider for the named module or requirement"""
- if isinstance(moduleOrReq, Requirement):
- return working_set.find(moduleOrReq) or require(str(moduleOrReq))[0]
- try:
- module = sys.modules[moduleOrReq]
- except KeyError:
- __import__(moduleOrReq)
- module = sys.modules[moduleOrReq]
- loader = getattr(module, '__loader__', None)
- return _find_adapter(_provider_factories, loader)(module)
-
-
-def _macos_vers(_cache=[]):
- if not _cache:
- version = platform.mac_ver()[0]
- # fallback for MacPorts
- if version == '':
- plist = '/System/Library/CoreServices/SystemVersion.plist'
- if os.path.exists(plist):
- if hasattr(plistlib, 'readPlist'):
- plist_content = plistlib.readPlist(plist)
- if 'ProductVersion' in plist_content:
- version = plist_content['ProductVersion']
-
- _cache.append(version.split('.'))
- return _cache[0]
-
-
-def _macos_arch(machine):
- return {'PowerPC': 'ppc', 'Power_Macintosh': 'ppc'}.get(machine, machine)
-
-
-def get_build_platform():
- """Return this platform's string for platform-specific distributions
-
- XXX Currently this is the same as ``distutils.util.get_platform()``, but it
- needs some hacks for Linux and macOS.
- """
- from sysconfig import get_platform
-
- plat = get_platform()
- if sys.platform == "darwin" and not plat.startswith('macosx-'):
- try:
- version = _macos_vers()
- machine = os.uname()[4].replace(" ", "_")
- return "macosx-%d.%d-%s" % (
- int(version[0]),
- int(version[1]),
- _macos_arch(machine),
- )
- except ValueError:
- # if someone is running a non-Mac darwin system, this will fall
- # through to the default implementation
- pass
- return plat
-
-
-macosVersionString = re.compile(r"macosx-(\d+)\.(\d+)-(.*)")
-darwinVersionString = re.compile(r"darwin-(\d+)\.(\d+)\.(\d+)-(.*)")
-# XXX backward compat
-get_platform = get_build_platform
-
-
-def compatible_platforms(provided, required):
- """Can code for the `provided` platform run on the `required` platform?
-
- Returns true if either platform is ``None``, or the platforms are equal.
-
- XXX Needs compatibility checks for Linux and other unixy OSes.
- """
- if provided is None or required is None or provided == required:
- # easy case
- return True
-
- # macOS special cases
- reqMac = macosVersionString.match(required)
- if reqMac:
- provMac = macosVersionString.match(provided)
-
- # is this a Mac package?
- if not provMac:
- # this is backwards compatibility for packages built before
- # setuptools 0.6. All packages built after this point will
- # use the new macOS designation.
- provDarwin = darwinVersionString.match(provided)
- if provDarwin:
- dversion = int(provDarwin.group(1))
- macosversion = "%s.%s" % (reqMac.group(1), reqMac.group(2))
- if (
- dversion == 7
- and macosversion >= "10.3"
- or dversion == 8
- and macosversion >= "10.4"
- ):
- return True
- # egg isn't macOS or legacy darwin
- return False
-
- # are they the same major version and machine type?
- if provMac.group(1) != reqMac.group(1) or provMac.group(3) != reqMac.group(3):
- return False
-
- # is the required OS major update >= the provided one?
- if int(provMac.group(2)) > int(reqMac.group(2)):
- return False
-
- return True
-
- # XXX Linux and other platforms' special cases should go here
- return False
-
-
-def run_script(dist_spec, script_name):
- """Locate distribution `dist_spec` and run its `script_name` script"""
- ns = sys._getframe(1).f_globals
- name = ns['__name__']
- ns.clear()
- ns['__name__'] = name
- require(dist_spec)[0].run_script(script_name, ns)
-
-
-# backward compatibility
-run_main = run_script
-
-
-def get_distribution(dist):
- """Return a current distribution object for a Requirement or string"""
- if isinstance(dist, str):
- dist = Requirement.parse(dist)
- if isinstance(dist, Requirement):
- dist = get_provider(dist)
- if not isinstance(dist, Distribution):
- raise TypeError("Expected string, Requirement, or Distribution", dist)
- return dist
-
-
-def load_entry_point(dist, group, name):
- """Return `name` entry point of `group` for `dist` or raise ImportError"""
- return get_distribution(dist).load_entry_point(group, name)
-
-
-def get_entry_map(dist, group=None):
- """Return the entry point map for `group`, or the full entry map"""
- return get_distribution(dist).get_entry_map(group)
-
-
-def get_entry_info(dist, group, name):
- """Return the EntryPoint object for `group`+`name`, or ``None``"""
- return get_distribution(dist).get_entry_info(group, name)
-
-
-class IMetadataProvider:
- def has_metadata(name):
- """Does the package's distribution contain the named metadata?"""
-
- def get_metadata(name):
- """The named metadata resource as a string"""
-
- def get_metadata_lines(name):
- """Yield named metadata resource as list of non-blank non-comment lines
-
- Leading and trailing whitespace is stripped from each line, and lines
- with ``#`` as the first non-blank character are omitted."""
-
- def metadata_isdir(name):
- """Is the named metadata a directory? (like ``os.path.isdir()``)"""
-
- def metadata_listdir(name):
- """List of metadata names in the directory (like ``os.listdir()``)"""
-
- def run_script(script_name, namespace):
- """Execute the named script in the supplied namespace dictionary"""
-
-
-class IResourceProvider(IMetadataProvider):
- """An object that provides access to package resources"""
-
- def get_resource_filename(manager, resource_name):
- """Return a true filesystem path for `resource_name`
-
- `manager` must be an ``IResourceManager``"""
-
- def get_resource_stream(manager, resource_name):
- """Return a readable file-like object for `resource_name`
-
- `manager` must be an ``IResourceManager``"""
-
- def get_resource_string(manager, resource_name):
- """Return a string containing the contents of `resource_name`
-
- `manager` must be an ``IResourceManager``"""
-
- def has_resource(resource_name):
- """Does the package contain the named resource?"""
-
- def resource_isdir(resource_name):
- """Is the named resource a directory? (like ``os.path.isdir()``)"""
-
- def resource_listdir(resource_name):
- """List of resource names in the directory (like ``os.listdir()``)"""
-
-
-class WorkingSet:
- """A collection of active distributions on sys.path (or a similar list)"""
-
- def __init__(self, entries=None):
- """Create working set from list of path entries (default=sys.path)"""
- self.entries = []
- self.entry_keys = {}
- self.by_key = {}
- self.normalized_to_canonical_keys = {}
- self.callbacks = []
-
- if entries is None:
- entries = sys.path
-
- for entry in entries:
- self.add_entry(entry)
-
- @classmethod
- def _build_master(cls):
- """
- Prepare the master working set.
- """
- ws = cls()
- try:
- from __main__ import __requires__
- except ImportError:
- # The main program does not list any requirements
- return ws
-
- # ensure the requirements are met
- try:
- ws.require(__requires__)
- except VersionConflict:
- return cls._build_from_requirements(__requires__)
-
- return ws
-
- @classmethod
- def _build_from_requirements(cls, req_spec):
- """
- Build a working set from a requirement spec. Rewrites sys.path.
- """
- # try it without defaults already on sys.path
- # by starting with an empty path
- ws = cls([])
- reqs = parse_requirements(req_spec)
- dists = ws.resolve(reqs, Environment())
- for dist in dists:
- ws.add(dist)
-
- # add any missing entries from sys.path
- for entry in sys.path:
- if entry not in ws.entries:
- ws.add_entry(entry)
-
- # then copy back to sys.path
- sys.path[:] = ws.entries
- return ws
-
- def add_entry(self, entry):
- """Add a path item to ``.entries``, finding any distributions on it
-
- ``find_distributions(entry, True)`` is used to find distributions
- corresponding to the path entry, and they are added. `entry` is
- always appended to ``.entries``, even if it is already present.
- (This is because ``sys.path`` can contain the same value more than
- once, and the ``.entries`` of the ``sys.path`` WorkingSet should always
- equal ``sys.path``.)
- """
- self.entry_keys.setdefault(entry, [])
- self.entries.append(entry)
- for dist in find_distributions(entry, True):
- self.add(dist, entry, False)
-
- def __contains__(self, dist):
- """True if `dist` is the active distribution for its project"""
- return self.by_key.get(dist.key) == dist
-
- def find(self, req):
- """Find a distribution matching requirement `req`
-
- If there is an active distribution for the requested project, this
- returns it as long as it meets the version requirement specified by
- `req`. But, if there is an active distribution for the project and it
- does *not* meet the `req` requirement, ``VersionConflict`` is raised.
- If there is no active distribution for the requested project, ``None``
- is returned.
- """
- dist = self.by_key.get(req.key)
-
- if dist is None:
- canonical_key = self.normalized_to_canonical_keys.get(req.key)
-
- if canonical_key is not None:
- req.key = canonical_key
- dist = self.by_key.get(canonical_key)
-
- if dist is not None and dist not in req:
- # XXX add more info
- raise VersionConflict(dist, req)
- return dist
-
- def iter_entry_points(self, group, name=None):
- """Yield entry point objects from `group` matching `name`
-
- If `name` is None, yields all entry points in `group` from all
- distributions in the working set, otherwise only ones matching
- both `group` and `name` are yielded (in distribution order).
- """
- return (
- entry
- for dist in self
- for entry in dist.get_entry_map(group).values()
- if name is None or name == entry.name
- )
-
- def run_script(self, requires, script_name):
- """Locate distribution for `requires` and run `script_name` script"""
- ns = sys._getframe(1).f_globals
- name = ns['__name__']
- ns.clear()
- ns['__name__'] = name
- self.require(requires)[0].run_script(script_name, ns)
-
- def __iter__(self):
- """Yield distributions for non-duplicate projects in the working set
-
- The yield order is the order in which the items' path entries were
- added to the working set.
- """
- seen = {}
- for item in self.entries:
- if item not in self.entry_keys:
- # workaround a cache issue
- continue
-
- for key in self.entry_keys[item]:
- if key not in seen:
- seen[key] = 1
- yield self.by_key[key]
-
- def add(self, dist, entry=None, insert=True, replace=False):
- """Add `dist` to working set, associated with `entry`
-
- If `entry` is unspecified, it defaults to the ``.location`` of `dist`.
- On exit from this routine, `entry` is added to the end of the working
- set's ``.entries`` (if it wasn't already present).
-
- `dist` is only added to the working set if it's for a project that
- doesn't already have a distribution in the set, unless `replace=True`.
- If it's added, any callbacks registered with the ``subscribe()`` method
- will be called.
- """
- if insert:
- dist.insert_on(self.entries, entry, replace=replace)
-
- if entry is None:
- entry = dist.location
- keys = self.entry_keys.setdefault(entry, [])
- keys2 = self.entry_keys.setdefault(dist.location, [])
- if not replace and dist.key in self.by_key:
- # ignore hidden distros
- return
-
- self.by_key[dist.key] = dist
- normalized_name = packaging.utils.canonicalize_name(dist.key)
- self.normalized_to_canonical_keys[normalized_name] = dist.key
- if dist.key not in keys:
- keys.append(dist.key)
- if dist.key not in keys2:
- keys2.append(dist.key)
- self._added_new(dist)
-
- def resolve(
- self,
- requirements,
- env=None,
- installer=None,
- replace_conflicting=False,
- extras=None,
- ):
- """List all distributions needed to (recursively) meet `requirements`
-
- `requirements` must be a sequence of ``Requirement`` objects. `env`,
- if supplied, should be an ``Environment`` instance. If
- not supplied, it defaults to all distributions available within any
- entry or distribution in the working set. `installer`, if supplied,
- will be invoked with each requirement that cannot be met by an
- already-installed distribution; it should return a ``Distribution`` or
- ``None``.
-
- Unless `replace_conflicting=True`, raises a VersionConflict exception
- if
- any requirements are found on the path that have the correct name but
- the wrong version. Otherwise, if an `installer` is supplied it will be
- invoked to obtain the correct version of the requirement and activate
- it.
-
- `extras` is a list of the extras to be used with these requirements.
- This is important because extra requirements may look like `my_req;
- extra = "my_extra"`, which would otherwise be interpreted as a purely
- optional requirement. Instead, we want to be able to assert that these
- requirements are truly required.
- """
-
- # set up the stack
- requirements = list(requirements)[::-1]
- # set of processed requirements
- processed = {}
- # key -> dist
- best = {}
- to_activate = []
-
- req_extras = _ReqExtras()
-
- # Mapping of requirement to set of distributions that required it;
- # useful for reporting info about conflicts.
- required_by = collections.defaultdict(set)
-
- while requirements:
- # process dependencies breadth-first
- req = requirements.pop(0)
- if req in processed:
- # Ignore cyclic or redundant dependencies
- continue
-
- if not req_extras.markers_pass(req, extras):
- continue
-
- dist = self._resolve_dist(
- req, best, replace_conflicting, env, installer, required_by, to_activate
- )
-
- # push the new requirements onto the stack
- new_requirements = dist.requires(req.extras)[::-1]
- requirements.extend(new_requirements)
-
- # Register the new requirements needed by req
- for new_requirement in new_requirements:
- required_by[new_requirement].add(req.project_name)
- req_extras[new_requirement] = req.extras
-
- processed[req] = True
-
- # return list of distros to activate
- return to_activate
-
- def _resolve_dist(
- self, req, best, replace_conflicting, env, installer, required_by, to_activate
- ):
- dist = best.get(req.key)
- if dist is None:
- # Find the best distribution and add it to the map
- dist = self.by_key.get(req.key)
- if dist is None or (dist not in req and replace_conflicting):
- ws = self
- if env is None:
- if dist is None:
- env = Environment(self.entries)
- else:
- # Use an empty environment and workingset to avoid
- # any further conflicts with the conflicting
- # distribution
- env = Environment([])
- ws = WorkingSet([])
- dist = best[req.key] = env.best_match(
- req, ws, installer, replace_conflicting=replace_conflicting
- )
- if dist is None:
- requirers = required_by.get(req, None)
- raise DistributionNotFound(req, requirers)
- to_activate.append(dist)
- if dist not in req:
- # Oops, the "best" so far conflicts with a dependency
- dependent_req = required_by[req]
- raise VersionConflict(dist, req).with_context(dependent_req)
- return dist
-
- def find_plugins(self, plugin_env, full_env=None, installer=None, fallback=True):
- """Find all activatable distributions in `plugin_env`
-
- Example usage::
-
- distributions, errors = working_set.find_plugins(
- Environment(plugin_dirlist)
- )
- # add plugins+libs to sys.path
- map(working_set.add, distributions)
- # display errors
- print('Could not load', errors)
-
- The `plugin_env` should be an ``Environment`` instance that contains
- only distributions that are in the project's "plugin directory" or
- directories. The `full_env`, if supplied, should be an ``Environment``
- contains all currently-available distributions. If `full_env` is not
- supplied, one is created automatically from the ``WorkingSet`` this
- method is called on, which will typically mean that every directory on
- ``sys.path`` will be scanned for distributions.
-
- `installer` is a standard installer callback as used by the
- ``resolve()`` method. The `fallback` flag indicates whether we should
- attempt to resolve older versions of a plugin if the newest version
- cannot be resolved.
-
- This method returns a 2-tuple: (`distributions`, `error_info`), where
- `distributions` is a list of the distributions found in `plugin_env`
- that were loadable, along with any other distributions that are needed
- to resolve their dependencies. `error_info` is a dictionary mapping
- unloadable plugin distributions to an exception instance describing the
- error that occurred. Usually this will be a ``DistributionNotFound`` or
- ``VersionConflict`` instance.
- """
-
- plugin_projects = list(plugin_env)
- # scan project names in alphabetic order
- plugin_projects.sort()
-
- error_info = {}
- distributions = {}
-
- if full_env is None:
- env = Environment(self.entries)
- env += plugin_env
- else:
- env = full_env + plugin_env
-
- shadow_set = self.__class__([])
- # put all our entries in shadow_set
- list(map(shadow_set.add, self))
-
- for project_name in plugin_projects:
- for dist in plugin_env[project_name]:
- req = [dist.as_requirement()]
-
- try:
- resolvees = shadow_set.resolve(req, env, installer)
-
- except ResolutionError as v:
- # save error info
- error_info[dist] = v
- if fallback:
- # try the next older version of project
- continue
- else:
- # give up on this project, keep going
- break
-
- else:
- list(map(shadow_set.add, resolvees))
- distributions.update(dict.fromkeys(resolvees))
-
- # success, no need to try any more versions of this project
- break
-
- distributions = list(distributions)
- distributions.sort()
-
- return distributions, error_info
-
- def require(self, *requirements):
- """Ensure that distributions matching `requirements` are activated
-
- `requirements` must be a string or a (possibly-nested) sequence
- thereof, specifying the distributions and versions required. The
- return value is a sequence of the distributions that needed to be
- activated to fulfill the requirements; all relevant distributions are
- included, even if they were already activated in this working set.
- """
- needed = self.resolve(parse_requirements(requirements))
-
- for dist in needed:
- self.add(dist)
-
- return needed
-
- def subscribe(self, callback, existing=True):
- """Invoke `callback` for all distributions
-
- If `existing=True` (default),
- call on all existing ones, as well.
- """
- if callback in self.callbacks:
- return
- self.callbacks.append(callback)
- if not existing:
- return
- for dist in self:
- callback(dist)
-
- def _added_new(self, dist):
- for callback in self.callbacks:
- callback(dist)
-
- def __getstate__(self):
- return (
- self.entries[:],
- self.entry_keys.copy(),
- self.by_key.copy(),
- self.normalized_to_canonical_keys.copy(),
- self.callbacks[:],
- )
-
- def __setstate__(self, e_k_b_n_c):
- entries, keys, by_key, normalized_to_canonical_keys, callbacks = e_k_b_n_c
- self.entries = entries[:]
- self.entry_keys = keys.copy()
- self.by_key = by_key.copy()
- self.normalized_to_canonical_keys = normalized_to_canonical_keys.copy()
- self.callbacks = callbacks[:]
-
-
-class _ReqExtras(dict):
- """
- Map each requirement to the extras that demanded it.
- """
-
- def markers_pass(self, req, extras=None):
- """
- Evaluate markers for req against each extra that
- demanded it.
-
- Return False if the req has a marker and fails
- evaluation. Otherwise, return True.
- """
- extra_evals = (
- req.marker.evaluate({'extra': extra})
- for extra in self.get(req, ()) + (extras or (None,))
- )
- return not req.marker or any(extra_evals)
-
-
-class Environment:
- """Searchable snapshot of distributions on a search path"""
-
- def __init__(
- self, search_path=None, platform=get_supported_platform(), python=PY_MAJOR
- ):
- """Snapshot distributions available on a search path
-
- Any distributions found on `search_path` are added to the environment.
- `search_path` should be a sequence of ``sys.path`` items. If not
- supplied, ``sys.path`` is used.
-
- `platform` is an optional string specifying the name of the platform
- that platform-specific distributions must be compatible with. If
- unspecified, it defaults to the current platform. `python` is an
- optional string naming the desired version of Python (e.g. ``'3.6'``);
- it defaults to the current version.
-
- You may explicitly set `platform` (and/or `python`) to ``None`` if you
- wish to map *all* distributions, not just those compatible with the
- running platform or Python version.
- """
- self._distmap = {}
- self.platform = platform
- self.python = python
- self.scan(search_path)
-
- def can_add(self, dist):
- """Is distribution `dist` acceptable for this environment?
-
- The distribution must match the platform and python version
- requirements specified when this environment was created, or False
- is returned.
- """
- py_compat = (
- self.python is None
- or dist.py_version is None
- or dist.py_version == self.python
- )
- return py_compat and compatible_platforms(dist.platform, self.platform)
-
- def remove(self, dist):
- """Remove `dist` from the environment"""
- self._distmap[dist.key].remove(dist)
-
- def scan(self, search_path=None):
- """Scan `search_path` for distributions usable in this environment
-
- Any distributions found are added to the environment.
- `search_path` should be a sequence of ``sys.path`` items. If not
- supplied, ``sys.path`` is used. Only distributions conforming to
- the platform/python version defined at initialization are added.
- """
- if search_path is None:
- search_path = sys.path
-
- for item in search_path:
- for dist in find_distributions(item):
- self.add(dist)
-
- def __getitem__(self, project_name):
- """Return a newest-to-oldest list of distributions for `project_name`
-
- Uses case-insensitive `project_name` comparison, assuming all the
- project's distributions use their project's name converted to all
- lowercase as their key.
-
- """
- distribution_key = project_name.lower()
- return self._distmap.get(distribution_key, [])
-
- def add(self, dist):
- """Add `dist` if we ``can_add()`` it and it has not already been added"""
- if self.can_add(dist) and dist.has_version():
- dists = self._distmap.setdefault(dist.key, [])
- if dist not in dists:
- dists.append(dist)
- dists.sort(key=operator.attrgetter('hashcmp'), reverse=True)
-
- def best_match(self, req, working_set, installer=None, replace_conflicting=False):
- """Find distribution best matching `req` and usable on `working_set`
-
- This calls the ``find(req)`` method of the `working_set` to see if a
- suitable distribution is already active. (This may raise
- ``VersionConflict`` if an unsuitable version of the project is already
- active in the specified `working_set`.) If a suitable distribution
- isn't active, this method returns the newest distribution in the
- environment that meets the ``Requirement`` in `req`. If no suitable
- distribution is found, and `installer` is supplied, then the result of
- calling the environment's ``obtain(req, installer)`` method will be
- returned.
- """
- try:
- dist = working_set.find(req)
- except VersionConflict:
- if not replace_conflicting:
- raise
- dist = None
- if dist is not None:
- return dist
- for dist in self[req.key]:
- if dist in req:
- return dist
- # try to download/install
- return self.obtain(req, installer)
-
- def obtain(self, requirement, installer=None):
- """Obtain a distribution matching `requirement` (e.g. via download)
-
- Obtain a distro that matches requirement (e.g. via download). In the
- base ``Environment`` class, this routine just returns
- ``installer(requirement)``, unless `installer` is None, in which case
- None is returned instead. This method is a hook that allows subclasses
- to attempt other ways of obtaining a distribution before falling back
- to the `installer` argument."""
- if installer is not None:
- return installer(requirement)
-
- def __iter__(self):
- """Yield the unique project names of the available distributions"""
- for key in self._distmap.keys():
- if self[key]:
- yield key
-
- def __iadd__(self, other):
- """In-place addition of a distribution or environment"""
- if isinstance(other, Distribution):
- self.add(other)
- elif isinstance(other, Environment):
- for project in other:
- for dist in other[project]:
- self.add(dist)
- else:
- raise TypeError("Can't add %r to environment" % (other,))
- return self
-
- def __add__(self, other):
- """Add an environment or distribution to an environment"""
- new = self.__class__([], platform=None, python=None)
- for env in self, other:
- new += env
- return new
-
-
-# XXX backward compatibility
-AvailableDistributions = Environment
-
-
-class ExtractionError(RuntimeError):
- """An error occurred extracting a resource
-
- The following attributes are available from instances of this exception:
-
- manager
- The resource manager that raised this exception
-
- cache_path
- The base directory for resource extraction
-
- original_error
- The exception instance that caused extraction to fail
- """
-
-
-class ResourceManager:
- """Manage resource extraction and packages"""
-
- extraction_path = None
-
- def __init__(self):
- self.cached_files = {}
-
- def resource_exists(self, package_or_requirement, resource_name):
- """Does the named resource exist?"""
- return get_provider(package_or_requirement).has_resource(resource_name)
-
- def resource_isdir(self, package_or_requirement, resource_name):
- """Is the named resource an existing directory?"""
- return get_provider(package_or_requirement).resource_isdir(resource_name)
-
- def resource_filename(self, package_or_requirement, resource_name):
- """Return a true filesystem path for specified resource"""
- return get_provider(package_or_requirement).get_resource_filename(
- self, resource_name
- )
-
- def resource_stream(self, package_or_requirement, resource_name):
- """Return a readable file-like object for specified resource"""
- return get_provider(package_or_requirement).get_resource_stream(
- self, resource_name
- )
-
- def resource_string(self, package_or_requirement, resource_name):
- """Return specified resource as a string"""
- return get_provider(package_or_requirement).get_resource_string(
- self, resource_name
- )
-
- def resource_listdir(self, package_or_requirement, resource_name):
- """List the contents of the named resource directory"""
- return get_provider(package_or_requirement).resource_listdir(resource_name)
-
- def extraction_error(self):
- """Give an error message for problems extracting file(s)"""
-
- old_exc = sys.exc_info()[1]
- cache_path = self.extraction_path or get_default_cache()
-
- tmpl = textwrap.dedent(
- """
- Can't extract file(s) to egg cache
-
- The following error occurred while trying to extract file(s)
- to the Python egg cache:
-
- {old_exc}
-
- The Python egg cache directory is currently set to:
-
- {cache_path}
-
- Perhaps your account does not have write access to this directory?
- You can change the cache directory by setting the PYTHON_EGG_CACHE
- environment variable to point to an accessible directory.
- """
- ).lstrip()
- err = ExtractionError(tmpl.format(**locals()))
- err.manager = self
- err.cache_path = cache_path
- err.original_error = old_exc
- raise err
-
- def get_cache_path(self, archive_name, names=()):
- """Return absolute location in cache for `archive_name` and `names`
-
- The parent directory of the resulting path will be created if it does
- not already exist. `archive_name` should be the base filename of the
- enclosing egg (which may not be the name of the enclosing zipfile!),
- including its ".egg" extension. `names`, if provided, should be a
- sequence of path name parts "under" the egg's extraction location.
-
- This method should only be called by resource providers that need to
- obtain an extraction location, and only for names they intend to
- extract, as it tracks the generated names for possible cleanup later.
- """
- extract_path = self.extraction_path or get_default_cache()
- target_path = os.path.join(extract_path, archive_name + '-tmp', *names)
- try:
- _bypass_ensure_directory(target_path)
- except Exception:
- self.extraction_error()
-
- self._warn_unsafe_extraction_path(extract_path)
-
- self.cached_files[target_path] = 1
- return target_path
-
- @staticmethod
- def _warn_unsafe_extraction_path(path):
- """
- If the default extraction path is overridden and set to an insecure
- location, such as /tmp, it opens up an opportunity for an attacker to
- replace an extracted file with an unauthorized payload. Warn the user
- if a known insecure location is used.
-
- See Distribute #375 for more details.
- """
- if os.name == 'nt' and not path.startswith(os.environ['windir']):
- # On Windows, permissions are generally restrictive by default
- # and temp directories are not writable by other users, so
- # bypass the warning.
- return
- mode = os.stat(path).st_mode
- if mode & stat.S_IWOTH or mode & stat.S_IWGRP:
- msg = (
- "Extraction path is writable by group/others "
- "and vulnerable to attack when "
- "used with get_resource_filename ({path}). "
- "Consider a more secure "
- "location (set with .set_extraction_path or the "
- "PYTHON_EGG_CACHE environment variable)."
- ).format(**locals())
- warnings.warn(msg, UserWarning)
-
- def postprocess(self, tempname, filename):
- """Perform any platform-specific postprocessing of `tempname`
-
- This is where Mac header rewrites should be done; other platforms don't
- have anything special they should do.
-
- Resource providers should call this method ONLY after successfully
- extracting a compressed resource. They must NOT call it on resources
- that are already in the filesystem.
-
- `tempname` is the current (temporary) name of the file, and `filename`
- is the name it will be renamed to by the caller after this routine
- returns.
- """
-
- if os.name == 'posix':
- # Make the resource executable
- mode = ((os.stat(tempname).st_mode) | 0o555) & 0o7777
- os.chmod(tempname, mode)
-
- def set_extraction_path(self, path):
- """Set the base path where resources will be extracted to, if needed.
-
- If you do not call this routine before any extractions take place, the
- path defaults to the return value of ``get_default_cache()``. (Which
- is based on the ``PYTHON_EGG_CACHE`` environment variable, with various
- platform-specific fallbacks. See that routine's documentation for more
- details.)
-
- Resources are extracted to subdirectories of this path based upon
- information given by the ``IResourceProvider``. You may set this to a
- temporary directory, but then you must call ``cleanup_resources()`` to
- delete the extracted files when done. There is no guarantee that
- ``cleanup_resources()`` will be able to remove all extracted files.
-
- (Note: you may not change the extraction path for a given resource
- manager once resources have been extracted, unless you first call
- ``cleanup_resources()``.)
- """
- if self.cached_files:
- raise ValueError("Can't change extraction path, files already extracted")
-
- self.extraction_path = path
-
- def cleanup_resources(self, force=False):
- """
- Delete all extracted resource files and directories, returning a list
- of the file and directory names that could not be successfully removed.
- This function does not have any concurrency protection, so it should
- generally only be called when the extraction path is a temporary
- directory exclusive to a single process. This method is not
- automatically called; you must call it explicitly or register it as an
- ``atexit`` function if you wish to ensure cleanup of a temporary
- directory used for extractions.
- """
- # XXX
-
-
-def get_default_cache():
- """
- Return the ``PYTHON_EGG_CACHE`` environment variable
- or a platform-relevant user cache dir for an app
- named "Python-Eggs".
- """
- return os.environ.get('PYTHON_EGG_CACHE') or platformdirs.user_cache_dir(
- appname='Python-Eggs'
- )
-
-
-def safe_name(name):
- """Convert an arbitrary string to a standard distribution name
-
- Any runs of non-alphanumeric/. characters are replaced with a single '-'.
- """
- return re.sub('[^A-Za-z0-9.]+', '-', name)
-
-
-def safe_version(version):
- """
- Convert an arbitrary string to a standard version string
- """
- try:
- # normalize the version
- return str(packaging.version.Version(version))
- except packaging.version.InvalidVersion:
- version = version.replace(' ', '.')
- return re.sub('[^A-Za-z0-9.]+', '-', version)
-
-
-def _forgiving_version(version):
- """Fallback when ``safe_version`` is not safe enough
- >>> parse_version(_forgiving_version('0.23ubuntu1'))
-
- >>> parse_version(_forgiving_version('0.23-'))
-
- >>> parse_version(_forgiving_version('0.-_'))
-
- >>> parse_version(_forgiving_version('42.+?1'))
-
- >>> parse_version(_forgiving_version('hello world'))
-
- """
- version = version.replace(' ', '.')
- match = _PEP440_FALLBACK.search(version)
- if match:
- safe = match["safe"]
- rest = version[len(safe):]
- else:
- safe = "0"
- rest = version
- local = f"sanitized.{_safe_segment(rest)}".strip(".")
- return f"{safe}.dev0+{local}"
-
-
-def _safe_segment(segment):
- """Convert an arbitrary string into a safe segment"""
- segment = re.sub('[^A-Za-z0-9.]+', '-', segment)
- segment = re.sub('-[^A-Za-z0-9]+', '-', segment)
- return re.sub(r'\.[^A-Za-z0-9]+', '.', segment).strip(".-")
-
-
-def safe_extra(extra):
- """Convert an arbitrary string to a standard 'extra' name
-
- Any runs of non-alphanumeric characters are replaced with a single '_',
- and the result is always lowercased.
- """
- return re.sub('[^A-Za-z0-9.-]+', '_', extra).lower()
-
-
-def to_filename(name):
- """Convert a project or version name to its filename-escaped form
-
- Any '-' characters are currently replaced with '_'.
- """
- return name.replace('-', '_')
-
-
-def invalid_marker(text):
- """
- Validate text as a PEP 508 environment marker; return an exception
- if invalid or False otherwise.
- """
- try:
- evaluate_marker(text)
- except SyntaxError as e:
- e.filename = None
- e.lineno = None
- return e
- return False
-
-
-def evaluate_marker(text, extra=None):
- """
- Evaluate a PEP 508 environment marker.
- Return a boolean indicating the marker result in this environment.
- Raise SyntaxError if marker is invalid.
-
- This implementation uses the 'pyparsing' module.
- """
- try:
- marker = packaging.markers.Marker(text)
- return marker.evaluate()
- except packaging.markers.InvalidMarker as e:
- raise SyntaxError(e) from e
-
-
-class NullProvider:
- """Try to implement resources and metadata for arbitrary PEP 302 loaders"""
-
- egg_name = None
- egg_info = None
- loader = None
-
- def __init__(self, module):
- self.loader = getattr(module, '__loader__', None)
- self.module_path = os.path.dirname(getattr(module, '__file__', ''))
-
- def get_resource_filename(self, manager, resource_name):
- return self._fn(self.module_path, resource_name)
-
- def get_resource_stream(self, manager, resource_name):
- return io.BytesIO(self.get_resource_string(manager, resource_name))
-
- def get_resource_string(self, manager, resource_name):
- return self._get(self._fn(self.module_path, resource_name))
-
- def has_resource(self, resource_name):
- return self._has(self._fn(self.module_path, resource_name))
-
- def _get_metadata_path(self, name):
- return self._fn(self.egg_info, name)
-
- def has_metadata(self, name):
- if not self.egg_info:
- return self.egg_info
-
- path = self._get_metadata_path(name)
- return self._has(path)
-
- def get_metadata(self, name):
- if not self.egg_info:
- return ""
- path = self._get_metadata_path(name)
- value = self._get(path)
- try:
- return value.decode('utf-8')
- except UnicodeDecodeError as exc:
- # Include the path in the error message to simplify
- # troubleshooting, and without changing the exception type.
- exc.reason += ' in {} file at path: {}'.format(name, path)
- raise
-
- def get_metadata_lines(self, name):
- return yield_lines(self.get_metadata(name))
-
- def resource_isdir(self, resource_name):
- return self._isdir(self._fn(self.module_path, resource_name))
-
- def metadata_isdir(self, name):
- return self.egg_info and self._isdir(self._fn(self.egg_info, name))
-
- def resource_listdir(self, resource_name):
- return self._listdir(self._fn(self.module_path, resource_name))
-
- def metadata_listdir(self, name):
- if self.egg_info:
- return self._listdir(self._fn(self.egg_info, name))
- return []
-
- def run_script(self, script_name, namespace):
- script = 'scripts/' + script_name
- if not self.has_metadata(script):
- raise ResolutionError(
- "Script {script!r} not found in metadata at {self.egg_info!r}".format(
- **locals()
- ),
- )
- script_text = self.get_metadata(script).replace('\r\n', '\n')
- script_text = script_text.replace('\r', '\n')
- script_filename = self._fn(self.egg_info, script)
- namespace['__file__'] = script_filename
- if os.path.exists(script_filename):
- with open(script_filename) as fid:
- source = fid.read()
- code = compile(source, script_filename, 'exec')
- exec(code, namespace, namespace)
- else:
- from linecache import cache
-
- cache[script_filename] = (
- len(script_text),
- 0,
- script_text.split('\n'),
- script_filename,
- )
- script_code = compile(script_text, script_filename, 'exec')
- exec(script_code, namespace, namespace)
-
- def _has(self, path):
- raise NotImplementedError(
- "Can't perform this operation for unregistered loader type"
- )
-
- def _isdir(self, path):
- raise NotImplementedError(
- "Can't perform this operation for unregistered loader type"
- )
-
- def _listdir(self, path):
- raise NotImplementedError(
- "Can't perform this operation for unregistered loader type"
- )
-
- def _fn(self, base, resource_name):
- self._validate_resource_path(resource_name)
- if resource_name:
- return os.path.join(base, *resource_name.split('/'))
- return base
-
- @staticmethod
- def _validate_resource_path(path):
- """
- Validate the resource paths according to the docs.
- https://setuptools.pypa.io/en/latest/pkg_resources.html#basic-resource-access
-
- >>> warned = getfixture('recwarn')
- >>> warnings.simplefilter('always')
- >>> vrp = NullProvider._validate_resource_path
- >>> vrp('foo/bar.txt')
- >>> bool(warned)
- False
- >>> vrp('../foo/bar.txt')
- >>> bool(warned)
- True
- >>> warned.clear()
- >>> vrp('/foo/bar.txt')
- >>> bool(warned)
- True
- >>> vrp('foo/../../bar.txt')
- >>> bool(warned)
- True
- >>> warned.clear()
- >>> vrp('foo/f../bar.txt')
- >>> bool(warned)
- False
-
- Windows path separators are straight-up disallowed.
- >>> vrp(r'\\foo/bar.txt')
- Traceback (most recent call last):
- ...
- ValueError: Use of .. or absolute path in a resource path \
-is not allowed.
-
- >>> vrp(r'C:\\foo/bar.txt')
- Traceback (most recent call last):
- ...
- ValueError: Use of .. or absolute path in a resource path \
-is not allowed.
-
- Blank values are allowed
-
- >>> vrp('')
- >>> bool(warned)
- False
-
- Non-string values are not.
-
- >>> vrp(None)
- Traceback (most recent call last):
- ...
- AttributeError: ...
- """
- invalid = (
- os.path.pardir in path.split(posixpath.sep)
- or posixpath.isabs(path)
- or ntpath.isabs(path)
- )
- if not invalid:
- return
-
- msg = "Use of .. or absolute path in a resource path is not allowed."
-
- # Aggressively disallow Windows absolute paths
- if ntpath.isabs(path) and not posixpath.isabs(path):
- raise ValueError(msg)
-
- # for compatibility, warn; in future
- # raise ValueError(msg)
- issue_warning(
- msg[:-1] + " and will raise exceptions in a future release.",
- DeprecationWarning,
- )
-
- def _get(self, path):
- if hasattr(self.loader, 'get_data'):
- return self.loader.get_data(path)
- raise NotImplementedError(
- "Can't perform this operation for loaders without 'get_data()'"
- )
-
-
-register_loader_type(object, NullProvider)
-
-
-def _parents(path):
- """
- yield all parents of path including path
- """
- last = None
- while path != last:
- yield path
- last = path
- path, _ = os.path.split(path)
-
-
-class EggProvider(NullProvider):
- """Provider based on a virtual filesystem"""
-
- def __init__(self, module):
- super().__init__(module)
- self._setup_prefix()
-
- def _setup_prefix(self):
- # Assume that metadata may be nested inside a "basket"
- # of multiple eggs and use module_path instead of .archive.
- eggs = filter(_is_egg_path, _parents(self.module_path))
- egg = next(eggs, None)
- egg and self._set_egg(egg)
-
- def _set_egg(self, path):
- self.egg_name = os.path.basename(path)
- self.egg_info = os.path.join(path, 'EGG-INFO')
- self.egg_root = path
-
-
-class DefaultProvider(EggProvider):
- """Provides access to package resources in the filesystem"""
-
- def _has(self, path):
- return os.path.exists(path)
-
- def _isdir(self, path):
- return os.path.isdir(path)
-
- def _listdir(self, path):
- return os.listdir(path)
-
- def get_resource_stream(self, manager, resource_name):
- return open(self._fn(self.module_path, resource_name), 'rb')
-
- def _get(self, path):
- with open(path, 'rb') as stream:
- return stream.read()
-
- @classmethod
- def _register(cls):
- loader_names = (
- 'SourceFileLoader',
- 'SourcelessFileLoader',
- )
- for name in loader_names:
- loader_cls = getattr(importlib_machinery, name, type(None))
- register_loader_type(loader_cls, cls)
-
-
-DefaultProvider._register()
-
-
-class EmptyProvider(NullProvider):
- """Provider that returns nothing for all requests"""
-
- module_path = None
-
- _isdir = _has = lambda self, path: False
-
- def _get(self, path):
- return ''
-
- def _listdir(self, path):
- return []
-
- def __init__(self):
- pass
-
-
-empty_provider = EmptyProvider()
-
-
-class ZipManifests(dict):
- """
- zip manifest builder
- """
-
- @classmethod
- def build(cls, path):
- """
- Build a dictionary similar to the zipimport directory
- caches, except instead of tuples, store ZipInfo objects.
-
- Use a platform-specific path separator (os.sep) for the path keys
- for compatibility with pypy on Windows.
- """
- with zipfile.ZipFile(path) as zfile:
- items = (
- (
- name.replace('/', os.sep),
- zfile.getinfo(name),
- )
- for name in zfile.namelist()
- )
- return dict(items)
-
- load = build
-
-
-class MemoizedZipManifests(ZipManifests):
- """
- Memoized zipfile manifests.
- """
-
- manifest_mod = collections.namedtuple('manifest_mod', 'manifest mtime')
-
- def load(self, path):
- """
- Load a manifest at path or return a suitable manifest already loaded.
- """
- path = os.path.normpath(path)
- mtime = os.stat(path).st_mtime
-
- if path not in self or self[path].mtime != mtime:
- manifest = self.build(path)
- self[path] = self.manifest_mod(manifest, mtime)
-
- return self[path].manifest
-
-
-class ZipProvider(EggProvider):
- """Resource support for zips and eggs"""
-
- eagers = None
- _zip_manifests = MemoizedZipManifests()
-
- def __init__(self, module):
- super().__init__(module)
- self.zip_pre = self.loader.archive + os.sep
-
- def _zipinfo_name(self, fspath):
- # Convert a virtual filename (full path to file) into a zipfile subpath
- # usable with the zipimport directory cache for our target archive
- fspath = fspath.rstrip(os.sep)
- if fspath == self.loader.archive:
- return ''
- if fspath.startswith(self.zip_pre):
- return fspath[len(self.zip_pre) :]
- raise AssertionError("%s is not a subpath of %s" % (fspath, self.zip_pre))
-
- def _parts(self, zip_path):
- # Convert a zipfile subpath into an egg-relative path part list.
- # pseudo-fs path
- fspath = self.zip_pre + zip_path
- if fspath.startswith(self.egg_root + os.sep):
- return fspath[len(self.egg_root) + 1 :].split(os.sep)
- raise AssertionError("%s is not a subpath of %s" % (fspath, self.egg_root))
-
- @property
- def zipinfo(self):
- return self._zip_manifests.load(self.loader.archive)
-
- def get_resource_filename(self, manager, resource_name):
- if not self.egg_name:
- raise NotImplementedError(
- "resource_filename() only supported for .egg, not .zip"
- )
- # no need to lock for extraction, since we use temp names
- zip_path = self._resource_to_zip(resource_name)
- eagers = self._get_eager_resources()
- if '/'.join(self._parts(zip_path)) in eagers:
- for name in eagers:
- self._extract_resource(manager, self._eager_to_zip(name))
- return self._extract_resource(manager, zip_path)
-
- @staticmethod
- def _get_date_and_size(zip_stat):
- size = zip_stat.file_size
- # ymdhms+wday, yday, dst
- date_time = zip_stat.date_time + (0, 0, -1)
- # 1980 offset already done
- timestamp = time.mktime(date_time)
- return timestamp, size
-
- # FIXME: 'ZipProvider._extract_resource' is too complex (12)
- def _extract_resource(self, manager, zip_path): # noqa: C901
- if zip_path in self._index():
- for name in self._index()[zip_path]:
- last = self._extract_resource(manager, os.path.join(zip_path, name))
- # return the extracted directory name
- return os.path.dirname(last)
-
- timestamp, size = self._get_date_and_size(self.zipinfo[zip_path])
-
- if not WRITE_SUPPORT:
- raise IOError(
- '"os.rename" and "os.unlink" are not supported ' 'on this platform'
- )
- try:
- real_path = manager.get_cache_path(self.egg_name, self._parts(zip_path))
-
- if self._is_current(real_path, zip_path):
- return real_path
-
- outf, tmpnam = _mkstemp(
- ".$extract",
- dir=os.path.dirname(real_path),
- )
- os.write(outf, self.loader.get_data(zip_path))
- os.close(outf)
- utime(tmpnam, (timestamp, timestamp))
- manager.postprocess(tmpnam, real_path)
-
- try:
- rename(tmpnam, real_path)
-
- except os.error:
- if os.path.isfile(real_path):
- if self._is_current(real_path, zip_path):
- # the file became current since it was checked above,
- # so proceed.
- return real_path
- # Windows, del old file and retry
- elif os.name == 'nt':
- unlink(real_path)
- rename(tmpnam, real_path)
- return real_path
- raise
-
- except os.error:
- # report a user-friendly error
- manager.extraction_error()
-
- return real_path
-
- def _is_current(self, file_path, zip_path):
- """
- Return True if the file_path is current for this zip_path
- """
- timestamp, size = self._get_date_and_size(self.zipinfo[zip_path])
- if not os.path.isfile(file_path):
- return False
- stat = os.stat(file_path)
- if stat.st_size != size or stat.st_mtime != timestamp:
- return False
- # check that the contents match
- zip_contents = self.loader.get_data(zip_path)
- with open(file_path, 'rb') as f:
- file_contents = f.read()
- return zip_contents == file_contents
-
- def _get_eager_resources(self):
- if self.eagers is None:
- eagers = []
- for name in ('native_libs.txt', 'eager_resources.txt'):
- if self.has_metadata(name):
- eagers.extend(self.get_metadata_lines(name))
- self.eagers = eagers
- return self.eagers
-
- def _index(self):
- try:
- return self._dirindex
- except AttributeError:
- ind = {}
- for path in self.zipinfo:
- parts = path.split(os.sep)
- while parts:
- parent = os.sep.join(parts[:-1])
- if parent in ind:
- ind[parent].append(parts[-1])
- break
- else:
- ind[parent] = [parts.pop()]
- self._dirindex = ind
- return ind
-
- def _has(self, fspath):
- zip_path = self._zipinfo_name(fspath)
- return zip_path in self.zipinfo or zip_path in self._index()
-
- def _isdir(self, fspath):
- return self._zipinfo_name(fspath) in self._index()
-
- def _listdir(self, fspath):
- return list(self._index().get(self._zipinfo_name(fspath), ()))
-
- def _eager_to_zip(self, resource_name):
- return self._zipinfo_name(self._fn(self.egg_root, resource_name))
-
- def _resource_to_zip(self, resource_name):
- return self._zipinfo_name(self._fn(self.module_path, resource_name))
-
-
-register_loader_type(zipimport.zipimporter, ZipProvider)
-
-
-class FileMetadata(EmptyProvider):
- """Metadata handler for standalone PKG-INFO files
-
- Usage::
-
- metadata = FileMetadata("/path/to/PKG-INFO")
-
- This provider rejects all data and metadata requests except for PKG-INFO,
- which is treated as existing, and will be the contents of the file at
- the provided location.
- """
-
- def __init__(self, path):
- self.path = path
-
- def _get_metadata_path(self, name):
- return self.path
-
- def has_metadata(self, name):
- return name == 'PKG-INFO' and os.path.isfile(self.path)
-
- def get_metadata(self, name):
- if name != 'PKG-INFO':
- raise KeyError("No metadata except PKG-INFO is available")
-
- with io.open(self.path, encoding='utf-8', errors="replace") as f:
- metadata = f.read()
- self._warn_on_replacement(metadata)
- return metadata
-
- def _warn_on_replacement(self, metadata):
- replacement_char = '�'
- if replacement_char in metadata:
- tmpl = "{self.path} could not be properly decoded in UTF-8"
- msg = tmpl.format(**locals())
- warnings.warn(msg)
-
- def get_metadata_lines(self, name):
- return yield_lines(self.get_metadata(name))
-
-
-class PathMetadata(DefaultProvider):
- """Metadata provider for egg directories
-
- Usage::
-
- # Development eggs:
-
- egg_info = "/path/to/PackageName.egg-info"
- base_dir = os.path.dirname(egg_info)
- metadata = PathMetadata(base_dir, egg_info)
- dist_name = os.path.splitext(os.path.basename(egg_info))[0]
- dist = Distribution(basedir, project_name=dist_name, metadata=metadata)
-
- # Unpacked egg directories:
-
- egg_path = "/path/to/PackageName-ver-pyver-etc.egg"
- metadata = PathMetadata(egg_path, os.path.join(egg_path,'EGG-INFO'))
- dist = Distribution.from_filename(egg_path, metadata=metadata)
- """
-
- def __init__(self, path, egg_info):
- self.module_path = path
- self.egg_info = egg_info
-
-
-class EggMetadata(ZipProvider):
- """Metadata provider for .egg files"""
-
- def __init__(self, importer):
- """Create a metadata provider from a zipimporter"""
-
- self.zip_pre = importer.archive + os.sep
- self.loader = importer
- if importer.prefix:
- self.module_path = os.path.join(importer.archive, importer.prefix)
- else:
- self.module_path = importer.archive
- self._setup_prefix()
-
-
-_declare_state('dict', _distribution_finders={})
-
-
-def register_finder(importer_type, distribution_finder):
- """Register `distribution_finder` to find distributions in sys.path items
-
- `importer_type` is the type or class of a PEP 302 "Importer" (sys.path item
- handler), and `distribution_finder` is a callable that, passed a path
- item and the importer instance, yields ``Distribution`` instances found on
- that path item. See ``pkg_resources.find_on_path`` for an example."""
- _distribution_finders[importer_type] = distribution_finder
-
-
-def find_distributions(path_item, only=False):
- """Yield distributions accessible via `path_item`"""
- importer = get_importer(path_item)
- finder = _find_adapter(_distribution_finders, importer)
- return finder(importer, path_item, only)
-
-
-def find_eggs_in_zip(importer, path_item, only=False):
- """
- Find eggs in zip files; possibly multiple nested eggs.
- """
- if importer.archive.endswith('.whl'):
- # wheels are not supported with this finder
- # they don't have PKG-INFO metadata, and won't ever contain eggs
- return
- metadata = EggMetadata(importer)
- if metadata.has_metadata('PKG-INFO'):
- yield Distribution.from_filename(path_item, metadata=metadata)
- if only:
- # don't yield nested distros
- return
- for subitem in metadata.resource_listdir(''):
- if _is_egg_path(subitem):
- subpath = os.path.join(path_item, subitem)
- dists = find_eggs_in_zip(zipimport.zipimporter(subpath), subpath)
- for dist in dists:
- yield dist
- elif subitem.lower().endswith(('.dist-info', '.egg-info')):
- subpath = os.path.join(path_item, subitem)
- submeta = EggMetadata(zipimport.zipimporter(subpath))
- submeta.egg_info = subpath
- yield Distribution.from_location(path_item, subitem, submeta)
-
-
-register_finder(zipimport.zipimporter, find_eggs_in_zip)
-
-
-def find_nothing(importer, path_item, only=False):
- return ()
-
-
-register_finder(object, find_nothing)
-
-
-def find_on_path(importer, path_item, only=False):
- """Yield distributions accessible on a sys.path directory"""
- path_item = _normalize_cached(path_item)
-
- if _is_unpacked_egg(path_item):
- yield Distribution.from_filename(
- path_item,
- metadata=PathMetadata(path_item, os.path.join(path_item, 'EGG-INFO')),
- )
- return
-
- entries = (os.path.join(path_item, child) for child in safe_listdir(path_item))
-
- # scan for .egg and .egg-info in directory
- for entry in sorted(entries):
- fullpath = os.path.join(path_item, entry)
- factory = dist_factory(path_item, entry, only)
- for dist in factory(fullpath):
- yield dist
-
-
-def dist_factory(path_item, entry, only):
- """Return a dist_factory for the given entry."""
- lower = entry.lower()
- is_egg_info = lower.endswith('.egg-info')
- is_dist_info = lower.endswith('.dist-info') and os.path.isdir(
- os.path.join(path_item, entry)
- )
- is_meta = is_egg_info or is_dist_info
- return (
- distributions_from_metadata
- if is_meta
- else find_distributions
- if not only and _is_egg_path(entry)
- else resolve_egg_link
- if not only and lower.endswith('.egg-link')
- else NoDists()
- )
-
-
-class NoDists:
- """
- >>> bool(NoDists())
- False
-
- >>> list(NoDists()('anything'))
- []
- """
-
- def __bool__(self):
- return False
-
- def __call__(self, fullpath):
- return iter(())
-
-
-def safe_listdir(path):
- """
- Attempt to list contents of path, but suppress some exceptions.
- """
- try:
- return os.listdir(path)
- except (PermissionError, NotADirectoryError):
- pass
- except OSError as e:
- # Ignore the directory if does not exist, not a directory or
- # permission denied
- if e.errno not in (errno.ENOTDIR, errno.EACCES, errno.ENOENT):
- raise
- return ()
-
-
-def distributions_from_metadata(path):
- root = os.path.dirname(path)
- if os.path.isdir(path):
- if len(os.listdir(path)) == 0:
- # empty metadata dir; skip
- return
- metadata = PathMetadata(root, path)
- else:
- metadata = FileMetadata(path)
- entry = os.path.basename(path)
- yield Distribution.from_location(
- root,
- entry,
- metadata,
- precedence=DEVELOP_DIST,
- )
-
-
-def non_empty_lines(path):
- """
- Yield non-empty lines from file at path
- """
- with open(path) as f:
- for line in f:
- line = line.strip()
- if line:
- yield line
-
-
-def resolve_egg_link(path):
- """
- Given a path to an .egg-link, resolve distributions
- present in the referenced path.
- """
- referenced_paths = non_empty_lines(path)
- resolved_paths = (
- os.path.join(os.path.dirname(path), ref) for ref in referenced_paths
- )
- dist_groups = map(find_distributions, resolved_paths)
- return next(dist_groups, ())
-
-
-if hasattr(pkgutil, 'ImpImporter'):
- register_finder(pkgutil.ImpImporter, find_on_path)
-
-register_finder(importlib_machinery.FileFinder, find_on_path)
-
-_declare_state('dict', _namespace_handlers={})
-_declare_state('dict', _namespace_packages={})
-
-
-def register_namespace_handler(importer_type, namespace_handler):
- """Register `namespace_handler` to declare namespace packages
-
- `importer_type` is the type or class of a PEP 302 "Importer" (sys.path item
- handler), and `namespace_handler` is a callable like this::
-
- def namespace_handler(importer, path_entry, moduleName, module):
- # return a path_entry to use for child packages
-
- Namespace handlers are only called if the importer object has already
- agreed that it can handle the relevant path item, and they should only
- return a subpath if the module __path__ does not already contain an
- equivalent subpath. For an example namespace handler, see
- ``pkg_resources.file_ns_handler``.
- """
- _namespace_handlers[importer_type] = namespace_handler
-
-
-def _handle_ns(packageName, path_item):
- """Ensure that named package includes a subpath of path_item (if needed)"""
-
- importer = get_importer(path_item)
- if importer is None:
- return None
-
- # use find_spec (PEP 451) and fall-back to find_module (PEP 302)
- try:
- spec = importer.find_spec(packageName)
- except AttributeError:
- # capture warnings due to #1111
- with warnings.catch_warnings():
- warnings.simplefilter("ignore")
- loader = importer.find_module(packageName)
- else:
- loader = spec.loader if spec else None
-
- if loader is None:
- return None
- module = sys.modules.get(packageName)
- if module is None:
- module = sys.modules[packageName] = types.ModuleType(packageName)
- module.__path__ = []
- _set_parent_ns(packageName)
- elif not hasattr(module, '__path__'):
- raise TypeError("Not a package:", packageName)
- handler = _find_adapter(_namespace_handlers, importer)
- subpath = handler(importer, path_item, packageName, module)
- if subpath is not None:
- path = module.__path__
- path.append(subpath)
- importlib.import_module(packageName)
- _rebuild_mod_path(path, packageName, module)
- return subpath
-
-
-def _rebuild_mod_path(orig_path, package_name, module):
- """
- Rebuild module.__path__ ensuring that all entries are ordered
- corresponding to their sys.path order
- """
- sys_path = [_normalize_cached(p) for p in sys.path]
-
- def safe_sys_path_index(entry):
- """
- Workaround for #520 and #513.
- """
- try:
- return sys_path.index(entry)
- except ValueError:
- return float('inf')
-
- def position_in_sys_path(path):
- """
- Return the ordinal of the path based on its position in sys.path
- """
- path_parts = path.split(os.sep)
- module_parts = package_name.count('.') + 1
- parts = path_parts[:-module_parts]
- return safe_sys_path_index(_normalize_cached(os.sep.join(parts)))
-
- new_path = sorted(orig_path, key=position_in_sys_path)
- new_path = [_normalize_cached(p) for p in new_path]
-
- if isinstance(module.__path__, list):
- module.__path__[:] = new_path
- else:
- module.__path__ = new_path
-
-
-def declare_namespace(packageName):
- """Declare that package 'packageName' is a namespace package"""
-
- msg = (
- f"Deprecated call to `pkg_resources.declare_namespace({packageName!r})`.\n"
- "Implementing implicit namespace packages (as specified in PEP 420) "
- "is preferred to `pkg_resources.declare_namespace`. "
- "See https://setuptools.pypa.io/en/latest/references/"
- "keywords.html#keyword-namespace-packages"
- )
- warnings.warn(msg, DeprecationWarning, stacklevel=2)
-
- _imp.acquire_lock()
- try:
- if packageName in _namespace_packages:
- return
-
- path = sys.path
- parent, _, _ = packageName.rpartition('.')
-
- if parent:
- declare_namespace(parent)
- if parent not in _namespace_packages:
- __import__(parent)
- try:
- path = sys.modules[parent].__path__
- except AttributeError as e:
- raise TypeError("Not a package:", parent) from e
-
- # Track what packages are namespaces, so when new path items are added,
- # they can be updated
- _namespace_packages.setdefault(parent or None, []).append(packageName)
- _namespace_packages.setdefault(packageName, [])
-
- for path_item in path:
- # Ensure all the parent's path items are reflected in the child,
- # if they apply
- _handle_ns(packageName, path_item)
-
- finally:
- _imp.release_lock()
-
-
-def fixup_namespace_packages(path_item, parent=None):
- """Ensure that previously-declared namespace packages include path_item"""
- _imp.acquire_lock()
- try:
- for package in _namespace_packages.get(parent, ()):
- subpath = _handle_ns(package, path_item)
- if subpath:
- fixup_namespace_packages(subpath, package)
- finally:
- _imp.release_lock()
-
-
-def file_ns_handler(importer, path_item, packageName, module):
- """Compute an ns-package subpath for a filesystem or zipfile importer"""
-
- subpath = os.path.join(path_item, packageName.split('.')[-1])
- normalized = _normalize_cached(subpath)
- for item in module.__path__:
- if _normalize_cached(item) == normalized:
- break
- else:
- # Only return the path if it's not already there
- return subpath
-
-
-if hasattr(pkgutil, 'ImpImporter'):
- register_namespace_handler(pkgutil.ImpImporter, file_ns_handler)
-
-register_namespace_handler(zipimport.zipimporter, file_ns_handler)
-register_namespace_handler(importlib_machinery.FileFinder, file_ns_handler)
-
-
-def null_ns_handler(importer, path_item, packageName, module):
- return None
-
-
-register_namespace_handler(object, null_ns_handler)
-
-
-def normalize_path(filename):
- """Normalize a file/dir name for comparison purposes"""
- return os.path.normcase(os.path.realpath(os.path.normpath(_cygwin_patch(filename))))
-
-
-def _cygwin_patch(filename): # pragma: nocover
- """
- Contrary to POSIX 2008, on Cygwin, getcwd (3) contains
- symlink components. Using
- os.path.abspath() works around this limitation. A fix in os.getcwd()
- would probably better, in Cygwin even more so, except
- that this seems to be by design...
- """
- return os.path.abspath(filename) if sys.platform == 'cygwin' else filename
-
-
-def _normalize_cached(filename, _cache={}):
- try:
- return _cache[filename]
- except KeyError:
- _cache[filename] = result = normalize_path(filename)
- return result
-
-
-def _is_egg_path(path):
- """
- Determine if given path appears to be an egg.
- """
- return _is_zip_egg(path) or _is_unpacked_egg(path)
-
-
-def _is_zip_egg(path):
- return (
- path.lower().endswith('.egg')
- and os.path.isfile(path)
- and zipfile.is_zipfile(path)
- )
-
-
-def _is_unpacked_egg(path):
- """
- Determine if given path appears to be an unpacked egg.
- """
- return path.lower().endswith('.egg') and os.path.isfile(
- os.path.join(path, 'EGG-INFO', 'PKG-INFO')
- )
-
-
-def _set_parent_ns(packageName):
- parts = packageName.split('.')
- name = parts.pop()
- if parts:
- parent = '.'.join(parts)
- setattr(sys.modules[parent], name, sys.modules[packageName])
-
-
-MODULE = re.compile(r"\w+(\.\w+)*$").match
-EGG_NAME = re.compile(
- r"""
- (?P[^-]+) (
- -(?P[^-]+) (
- -py(?P[^-]+) (
- -(?P.+)
- )?
- )?
- )?
- """,
- re.VERBOSE | re.IGNORECASE,
-).match
-
-
-class EntryPoint:
- """Object representing an advertised importable object"""
-
- def __init__(self, name, module_name, attrs=(), extras=(), dist=None):
- if not MODULE(module_name):
- raise ValueError("Invalid module name", module_name)
- self.name = name
- self.module_name = module_name
- self.attrs = tuple(attrs)
- self.extras = tuple(extras)
- self.dist = dist
-
- def __str__(self):
- s = "%s = %s" % (self.name, self.module_name)
- if self.attrs:
- s += ':' + '.'.join(self.attrs)
- if self.extras:
- s += ' [%s]' % ','.join(self.extras)
- return s
-
- def __repr__(self):
- return "EntryPoint.parse(%r)" % str(self)
-
- def load(self, require=True, *args, **kwargs):
- """
- Require packages for this EntryPoint, then resolve it.
- """
- if not require or args or kwargs:
- warnings.warn(
- "Parameters to load are deprecated. Call .resolve and "
- ".require separately.",
- PkgResourcesDeprecationWarning,
- stacklevel=2,
- )
- if require:
- self.require(*args, **kwargs)
- return self.resolve()
-
- def resolve(self):
- """
- Resolve the entry point from its module and attrs.
- """
- module = __import__(self.module_name, fromlist=['__name__'], level=0)
- try:
- return functools.reduce(getattr, self.attrs, module)
- except AttributeError as exc:
- raise ImportError(str(exc)) from exc
-
- def require(self, env=None, installer=None):
- if self.extras and not self.dist:
- raise UnknownExtra("Can't require() without a distribution", self)
-
- # Get the requirements for this entry point with all its extras and
- # then resolve them. We have to pass `extras` along when resolving so
- # that the working set knows what extras we want. Otherwise, for
- # dist-info distributions, the working set will assume that the
- # requirements for that extra are purely optional and skip over them.
- reqs = self.dist.requires(self.extras)
- items = working_set.resolve(reqs, env, installer, extras=self.extras)
- list(map(working_set.add, items))
-
- pattern = re.compile(
- r'\s*'
- r'(?P.+?)\s*'
- r'=\s*'
- r'(?P[\w.]+)\s*'
- r'(:\s*(?P[\w.]+))?\s*'
- r'(?P\[.*\])?\s*$'
- )
-
- @classmethod
- def parse(cls, src, dist=None):
- """Parse a single entry point from string `src`
-
- Entry point syntax follows the form::
-
- name = some.module:some.attr [extra1, extra2]
-
- The entry name and module name are required, but the ``:attrs`` and
- ``[extras]`` parts are optional
- """
- m = cls.pattern.match(src)
- if not m:
- msg = "EntryPoint must be in 'name=module:attrs [extras]' format"
- raise ValueError(msg, src)
- res = m.groupdict()
- extras = cls._parse_extras(res['extras'])
- attrs = res['attr'].split('.') if res['attr'] else ()
- return cls(res['name'], res['module'], attrs, extras, dist)
-
- @classmethod
- def _parse_extras(cls, extras_spec):
- if not extras_spec:
- return ()
- req = Requirement.parse('x' + extras_spec)
- if req.specs:
- raise ValueError()
- return req.extras
-
- @classmethod
- def parse_group(cls, group, lines, dist=None):
- """Parse an entry point group"""
- if not MODULE(group):
- raise ValueError("Invalid group name", group)
- this = {}
- for line in yield_lines(lines):
- ep = cls.parse(line, dist)
- if ep.name in this:
- raise ValueError("Duplicate entry point", group, ep.name)
- this[ep.name] = ep
- return this
-
- @classmethod
- def parse_map(cls, data, dist=None):
- """Parse a map of entry point groups"""
- if isinstance(data, dict):
- data = data.items()
- else:
- data = split_sections(data)
- maps = {}
- for group, lines in data:
- if group is None:
- if not lines:
- continue
- raise ValueError("Entry points must be listed in groups")
- group = group.strip()
- if group in maps:
- raise ValueError("Duplicate group name", group)
- maps[group] = cls.parse_group(group, lines, dist)
- return maps
-
-
-def _version_from_file(lines):
- """
- Given an iterable of lines from a Metadata file, return
- the value of the Version field, if present, or None otherwise.
- """
-
- def is_version_line(line):
- return line.lower().startswith('version:')
-
- version_lines = filter(is_version_line, lines)
- line = next(iter(version_lines), '')
- _, _, value = line.partition(':')
- return safe_version(value.strip()) or None
-
-
-class Distribution:
- """Wrap an actual or potential sys.path entry w/metadata"""
-
- PKG_INFO = 'PKG-INFO'
-
- def __init__(
- self,
- location=None,
- metadata=None,
- project_name=None,
- version=None,
- py_version=PY_MAJOR,
- platform=None,
- precedence=EGG_DIST,
- ):
- self.project_name = safe_name(project_name or 'Unknown')
- if version is not None:
- self._version = safe_version(version)
- self.py_version = py_version
- self.platform = platform
- self.location = location
- self.precedence = precedence
- self._provider = metadata or empty_provider
-
- @classmethod
- def from_location(cls, location, basename, metadata=None, **kw):
- project_name, version, py_version, platform = [None] * 4
- basename, ext = os.path.splitext(basename)
- if ext.lower() in _distributionImpl:
- cls = _distributionImpl[ext.lower()]
-
- match = EGG_NAME(basename)
- if match:
- project_name, version, py_version, platform = match.group(
- 'name', 'ver', 'pyver', 'plat'
- )
- return cls(
- location,
- metadata,
- project_name=project_name,
- version=version,
- py_version=py_version,
- platform=platform,
- **kw,
- )._reload_version()
-
- def _reload_version(self):
- return self
-
- @property
- def hashcmp(self):
- return (
- self._forgiving_parsed_version,
- self.precedence,
- self.key,
- self.location,
- self.py_version or '',
- self.platform or '',
- )
-
- def __hash__(self):
- return hash(self.hashcmp)
-
- def __lt__(self, other):
- return self.hashcmp < other.hashcmp
-
- def __le__(self, other):
- return self.hashcmp <= other.hashcmp
-
- def __gt__(self, other):
- return self.hashcmp > other.hashcmp
-
- def __ge__(self, other):
- return self.hashcmp >= other.hashcmp
-
- def __eq__(self, other):
- if not isinstance(other, self.__class__):
- # It's not a Distribution, so they are not equal
- return False
- return self.hashcmp == other.hashcmp
-
- def __ne__(self, other):
- return not self == other
-
- # These properties have to be lazy so that we don't have to load any
- # metadata until/unless it's actually needed. (i.e., some distributions
- # may not know their name or version without loading PKG-INFO)
-
- @property
- def key(self):
- try:
- return self._key
- except AttributeError:
- self._key = key = self.project_name.lower()
- return key
-
- @property
- def parsed_version(self):
- if not hasattr(self, "_parsed_version"):
- try:
- self._parsed_version = parse_version(self.version)
- except packaging.version.InvalidVersion as ex:
- info = f"(package: {self.project_name})"
- if hasattr(ex, "add_note"):
- ex.add_note(info) # PEP 678
- raise
- raise packaging.version.InvalidVersion(f"{str(ex)} {info}") from None
-
- return self._parsed_version
-
- @property
- def _forgiving_parsed_version(self):
- try:
- return self.parsed_version
- except packaging.version.InvalidVersion as ex:
- self._parsed_version = parse_version(_forgiving_version(self.version))
-
- notes = "\n".join(getattr(ex, "__notes__", [])) # PEP 678
- msg = f"""!!\n\n
- *************************************************************************
- {str(ex)}\n{notes}
-
- This is a long overdue deprecation.
- For the time being, `pkg_resources` will use `{self._parsed_version}`
- as a replacement to avoid breaking existing environments,
- but no future compatibility is guaranteed.
-
- If you maintain package {self.project_name} you should implement
- the relevant changes to adequate the project to PEP 440 immediately.
- *************************************************************************
- \n\n!!
- """
- warnings.warn(msg, DeprecationWarning)
-
- return self._parsed_version
-
- @property
- def version(self):
- try:
- return self._version
- except AttributeError as e:
- version = self._get_version()
- if version is None:
- path = self._get_metadata_path_for_display(self.PKG_INFO)
- msg = ("Missing 'Version:' header and/or {} file at path: {}").format(
- self.PKG_INFO, path
- )
- raise ValueError(msg, self) from e
-
- return version
-
- @property
- def _dep_map(self):
- """
- A map of extra to its list of (direct) requirements
- for this distribution, including the null extra.
- """
- try:
- return self.__dep_map
- except AttributeError:
- self.__dep_map = self._filter_extras(self._build_dep_map())
- return self.__dep_map
-
- @staticmethod
- def _filter_extras(dm):
- """
- Given a mapping of extras to dependencies, strip off
- environment markers and filter out any dependencies
- not matching the markers.
- """
- for extra in list(filter(None, dm)):
- new_extra = extra
- reqs = dm.pop(extra)
- new_extra, _, marker = extra.partition(':')
- fails_marker = marker and (
- invalid_marker(marker) or not evaluate_marker(marker)
- )
- if fails_marker:
- reqs = []
- new_extra = safe_extra(new_extra) or None
-
- dm.setdefault(new_extra, []).extend(reqs)
- return dm
-
- def _build_dep_map(self):
- dm = {}
- for name in 'requires.txt', 'depends.txt':
- for extra, reqs in split_sections(self._get_metadata(name)):
- dm.setdefault(extra, []).extend(parse_requirements(reqs))
- return dm
-
- def requires(self, extras=()):
- """List of Requirements needed for this distro if `extras` are used"""
- dm = self._dep_map
- deps = []
- deps.extend(dm.get(None, ()))
- for ext in extras:
- try:
- deps.extend(dm[safe_extra(ext)])
- except KeyError as e:
- raise UnknownExtra(
- "%s has no such extra feature %r" % (self, ext)
- ) from e
- return deps
-
- def _get_metadata_path_for_display(self, name):
- """
- Return the path to the given metadata file, if available.
- """
- try:
- # We need to access _get_metadata_path() on the provider object
- # directly rather than through this class's __getattr__()
- # since _get_metadata_path() is marked private.
- path = self._provider._get_metadata_path(name)
-
- # Handle exceptions e.g. in case the distribution's metadata
- # provider doesn't support _get_metadata_path().
- except Exception:
- return '[could not detect]'
-
- return path
-
- def _get_metadata(self, name):
- if self.has_metadata(name):
- for line in self.get_metadata_lines(name):
- yield line
-
- def _get_version(self):
- lines = self._get_metadata(self.PKG_INFO)
- version = _version_from_file(lines)
-
- return version
-
- def activate(self, path=None, replace=False):
- """Ensure distribution is importable on `path` (default=sys.path)"""
- if path is None:
- path = sys.path
- self.insert_on(path, replace=replace)
- if path is sys.path:
- fixup_namespace_packages(self.location)
- for pkg in self._get_metadata('namespace_packages.txt'):
- if pkg in sys.modules:
- declare_namespace(pkg)
-
- def egg_name(self):
- """Return what this distribution's standard .egg filename should be"""
- filename = "%s-%s-py%s" % (
- to_filename(self.project_name),
- to_filename(self.version),
- self.py_version or PY_MAJOR,
- )
-
- if self.platform:
- filename += '-' + self.platform
- return filename
-
- def __repr__(self):
- if self.location:
- return "%s (%s)" % (self, self.location)
- else:
- return str(self)
-
- def __str__(self):
- try:
- version = getattr(self, 'version', None)
- except ValueError:
- version = None
- version = version or "[unknown version]"
- return "%s %s" % (self.project_name, version)
-
- def __getattr__(self, attr):
- """Delegate all unrecognized public attributes to .metadata provider"""
- if attr.startswith('_'):
- raise AttributeError(attr)
- return getattr(self._provider, attr)
-
- def __dir__(self):
- return list(
- set(super(Distribution, self).__dir__())
- | set(attr for attr in self._provider.__dir__() if not attr.startswith('_'))
- )
-
- @classmethod
- def from_filename(cls, filename, metadata=None, **kw):
- return cls.from_location(
- _normalize_cached(filename), os.path.basename(filename), metadata, **kw
- )
-
- def as_requirement(self):
- """Return a ``Requirement`` that matches this distribution exactly"""
- if isinstance(self.parsed_version, packaging.version.Version):
- spec = "%s==%s" % (self.project_name, self.parsed_version)
- else:
- spec = "%s===%s" % (self.project_name, self.parsed_version)
-
- return Requirement.parse(spec)
-
- def load_entry_point(self, group, name):
- """Return the `name` entry point of `group` or raise ImportError"""
- ep = self.get_entry_info(group, name)
- if ep is None:
- raise ImportError("Entry point %r not found" % ((group, name),))
- return ep.load()
-
- def get_entry_map(self, group=None):
- """Return the entry point map for `group`, or the full entry map"""
- try:
- ep_map = self._ep_map
- except AttributeError:
- ep_map = self._ep_map = EntryPoint.parse_map(
- self._get_metadata('entry_points.txt'), self
- )
- if group is not None:
- return ep_map.get(group, {})
- return ep_map
-
- def get_entry_info(self, group, name):
- """Return the EntryPoint object for `group`+`name`, or ``None``"""
- return self.get_entry_map(group).get(name)
-
- # FIXME: 'Distribution.insert_on' is too complex (13)
- def insert_on(self, path, loc=None, replace=False): # noqa: C901
- """Ensure self.location is on path
-
- If replace=False (default):
- - If location is already in path anywhere, do nothing.
- - Else:
- - If it's an egg and its parent directory is on path,
- insert just ahead of the parent.
- - Else: add to the end of path.
- If replace=True:
- - If location is already on path anywhere (not eggs)
- or higher priority than its parent (eggs)
- do nothing.
- - Else:
- - If it's an egg and its parent directory is on path,
- insert just ahead of the parent,
- removing any lower-priority entries.
- - Else: add it to the front of path.
- """
-
- loc = loc or self.location
- if not loc:
- return
-
- nloc = _normalize_cached(loc)
- bdir = os.path.dirname(nloc)
- npath = [(p and _normalize_cached(p) or p) for p in path]
-
- for p, item in enumerate(npath):
- if item == nloc:
- if replace:
- break
- else:
- # don't modify path (even removing duplicates) if
- # found and not replace
- return
- elif item == bdir and self.precedence == EGG_DIST:
- # if it's an .egg, give it precedence over its directory
- # UNLESS it's already been added to sys.path and replace=False
- if (not replace) and nloc in npath[p:]:
- return
- if path is sys.path:
- self.check_version_conflict()
- path.insert(p, loc)
- npath.insert(p, nloc)
- break
- else:
- if path is sys.path:
- self.check_version_conflict()
- if replace:
- path.insert(0, loc)
- else:
- path.append(loc)
- return
-
- # p is the spot where we found or inserted loc; now remove duplicates
- while True:
- try:
- np = npath.index(nloc, p + 1)
- except ValueError:
- break
- else:
- del npath[np], path[np]
- # ha!
- p = np
-
- return
-
- def check_version_conflict(self):
- if self.key == 'setuptools':
- # ignore the inevitable setuptools self-conflicts :(
- return
-
- nsp = dict.fromkeys(self._get_metadata('namespace_packages.txt'))
- loc = normalize_path(self.location)
- for modname in self._get_metadata('top_level.txt'):
- if (
- modname not in sys.modules
- or modname in nsp
- or modname in _namespace_packages
- ):
- continue
- if modname in ('pkg_resources', 'setuptools', 'site'):
- continue
- fn = getattr(sys.modules[modname], '__file__', None)
- if fn and (
- normalize_path(fn).startswith(loc) or fn.startswith(self.location)
- ):
- continue
- issue_warning(
- "Module %s was already imported from %s, but %s is being added"
- " to sys.path" % (modname, fn, self.location),
- )
-
- def has_version(self):
- try:
- self.version
- except ValueError:
- issue_warning("Unbuilt egg for " + repr(self))
- return False
- except SystemError:
- # TODO: remove this except clause when python/cpython#103632 is fixed.
- return False
- return True
-
- def clone(self, **kw):
- """Copy this distribution, substituting in any changed keyword args"""
- names = 'project_name version py_version platform location precedence'
- for attr in names.split():
- kw.setdefault(attr, getattr(self, attr, None))
- kw.setdefault('metadata', self._provider)
- return self.__class__(**kw)
-
- @property
- def extras(self):
- return [dep for dep in self._dep_map if dep]
-
-
-class EggInfoDistribution(Distribution):
- def _reload_version(self):
- """
- Packages installed by distutils (e.g. numpy or scipy),
- which uses an old safe_version, and so
- their version numbers can get mangled when
- converted to filenames (e.g., 1.11.0.dev0+2329eae to
- 1.11.0.dev0_2329eae). These distributions will not be
- parsed properly
- downstream by Distribution and safe_version, so
- take an extra step and try to get the version number from
- the metadata file itself instead of the filename.
- """
- md_version = self._get_version()
- if md_version:
- self._version = md_version
- return self
-
-
-class DistInfoDistribution(Distribution):
- """
- Wrap an actual or potential sys.path entry
- w/metadata, .dist-info style.
- """
-
- PKG_INFO = 'METADATA'
- EQEQ = re.compile(r"([\(,])\s*(\d.*?)\s*([,\)])")
-
- @property
- def _parsed_pkg_info(self):
- """Parse and cache metadata"""
- try:
- return self._pkg_info
- except AttributeError:
- metadata = self.get_metadata(self.PKG_INFO)
- self._pkg_info = email.parser.Parser().parsestr(metadata)
- return self._pkg_info
-
- @property
- def _dep_map(self):
- try:
- return self.__dep_map
- except AttributeError:
- self.__dep_map = self._compute_dependencies()
- return self.__dep_map
-
- def _compute_dependencies(self):
- """Recompute this distribution's dependencies."""
- dm = self.__dep_map = {None: []}
-
- reqs = []
- # Including any condition expressions
- for req in self._parsed_pkg_info.get_all('Requires-Dist') or []:
- reqs.extend(parse_requirements(req))
-
- def reqs_for_extra(extra):
- for req in reqs:
- if not req.marker or req.marker.evaluate({'extra': extra}):
- yield req
-
- common = types.MappingProxyType(dict.fromkeys(reqs_for_extra(None)))
- dm[None].extend(common)
-
- for extra in self._parsed_pkg_info.get_all('Provides-Extra') or []:
- s_extra = safe_extra(extra.strip())
- dm[s_extra] = [r for r in reqs_for_extra(extra) if r not in common]
-
- return dm
-
-
-_distributionImpl = {
- '.egg': Distribution,
- '.egg-info': EggInfoDistribution,
- '.dist-info': DistInfoDistribution,
-}
-
-
-def issue_warning(*args, **kw):
- level = 1
- g = globals()
- try:
- # find the first stack frame that is *not* code in
- # the pkg_resources module, to use for the warning
- while sys._getframe(level).f_globals is g:
- level += 1
- except ValueError:
- pass
- warnings.warn(stacklevel=level + 1, *args, **kw)
-
-
-def parse_requirements(strs):
- """
- Yield ``Requirement`` objects for each specification in `strs`.
-
- `strs` must be a string, or a (possibly-nested) iterable thereof.
- """
- return map(Requirement, join_continuation(map(drop_comment, yield_lines(strs))))
-
-
-class RequirementParseError(packaging.requirements.InvalidRequirement):
- "Compatibility wrapper for InvalidRequirement"
-
-
-class Requirement(packaging.requirements.Requirement):
- def __init__(self, requirement_string):
- """DO NOT CALL THIS UNDOCUMENTED METHOD; use Requirement.parse()!"""
- super(Requirement, self).__init__(requirement_string)
- self.unsafe_name = self.name
- project_name = safe_name(self.name)
- self.project_name, self.key = project_name, project_name.lower()
- self.specs = [(spec.operator, spec.version) for spec in self.specifier]
- self.extras = tuple(map(safe_extra, self.extras))
- self.hashCmp = (
- self.key,
- self.url,
- self.specifier,
- frozenset(self.extras),
- str(self.marker) if self.marker else None,
- )
- self.__hash = hash(self.hashCmp)
-
- def __eq__(self, other):
- return isinstance(other, Requirement) and self.hashCmp == other.hashCmp
-
- def __ne__(self, other):
- return not self == other
-
- def __contains__(self, item):
- if isinstance(item, Distribution):
- if item.key != self.key:
- return False
-
- item = item.version
-
- # Allow prereleases always in order to match the previous behavior of
- # this method. In the future this should be smarter and follow PEP 440
- # more accurately.
- return self.specifier.contains(item, prereleases=True)
-
- def __hash__(self):
- return self.__hash
-
- def __repr__(self):
- return "Requirement.parse(%r)" % str(self)
-
- @staticmethod
- def parse(s):
- (req,) = parse_requirements(s)
- return req
-
-
-def _always_object(classes):
- """
- Ensure object appears in the mro even
- for old-style classes.
- """
- if object not in classes:
- return classes + (object,)
- return classes
-
-
-def _find_adapter(registry, ob):
- """Return an adapter factory for `ob` from `registry`"""
- types = _always_object(inspect.getmro(getattr(ob, '__class__', type(ob))))
- for t in types:
- if t in registry:
- return registry[t]
-
-
-def ensure_directory(path):
- """Ensure that the parent directory of `path` exists"""
- dirname = os.path.dirname(path)
- os.makedirs(dirname, exist_ok=True)
-
-
-def _bypass_ensure_directory(path):
- """Sandbox-bypassing version of ensure_directory()"""
- if not WRITE_SUPPORT:
- raise IOError('"os.mkdir" not supported on this platform.')
- dirname, filename = split(path)
- if dirname and filename and not isdir(dirname):
- _bypass_ensure_directory(dirname)
- try:
- mkdir(dirname, 0o755)
- except FileExistsError:
- pass
-
-
-def split_sections(s):
- """Split a string or iterable thereof into (section, content) pairs
-
- Each ``section`` is a stripped version of the section header ("[section]")
- and each ``content`` is a list of stripped lines excluding blank lines and
- comment-only lines. If there are any such lines before the first section
- header, they're returned in a first ``section`` of ``None``.
- """
- section = None
- content = []
- for line in yield_lines(s):
- if line.startswith("["):
- if line.endswith("]"):
- if section or content:
- yield section, content
- section = line[1:-1].strip()
- content = []
- else:
- raise ValueError("Invalid section heading", line)
- else:
- content.append(line)
-
- # wrap up last segment
- yield section, content
-
-
-def _mkstemp(*args, **kw):
- old_open = os.open
- try:
- # temporarily bypass sandboxing
- os.open = os_open
- return tempfile.mkstemp(*args, **kw)
- finally:
- # and then put it back
- os.open = old_open
-
-
-# Silence the PEP440Warning by default, so that end users don't get hit by it
-# randomly just because they use pkg_resources. We want to append the rule
-# because we want earlier uses of filterwarnings to take precedence over this
-# one.
-warnings.filterwarnings("ignore", category=PEP440Warning, append=True)
-
-
-# from jaraco.functools 1.3
-def _call_aside(f, *args, **kwargs):
- f(*args, **kwargs)
- return f
-
-
-@_call_aside
-def _initialize(g=globals()):
- "Set up global resource manager (deliberately not state-saved)"
- manager = ResourceManager()
- g['_manager'] = manager
- g.update(
- (name, getattr(manager, name))
- for name in dir(manager)
- if not name.startswith('_')
- )
-
-
-class PkgResourcesDeprecationWarning(Warning):
- """
- Base class for warning about deprecations in ``pkg_resources``
-
- This class is not derived from ``DeprecationWarning``, and as such is
- visible by default.
- """
-
-
-@_call_aside
-def _initialize_master_working_set():
- """
- Prepare the master working set and make the ``require()``
- API available.
-
- This function has explicit effects on the global state
- of pkg_resources. It is intended to be invoked once at
- the initialization of this module.
-
- Invocation by other packages is unsupported and done
- at their own risk.
- """
- working_set = WorkingSet._build_master()
- _declare_state('object', working_set=working_set)
-
- require = working_set.require
- iter_entry_points = working_set.iter_entry_points
- add_activation_listener = working_set.subscribe
- run_script = working_set.run_script
- # backward compatibility
- run_main = run_script
- # Activate all distributions already on sys.path with replace=False and
- # ensure that all distributions added to the working set in the future
- # (e.g. by calling ``require()``) will get activated as well,
- # with higher priority (replace=True).
- tuple(dist.activate(replace=False) for dist in working_set)
- add_activation_listener(
- lambda dist: dist.activate(replace=True),
- existing=False,
- )
- working_set.entries = []
- # match order
- list(map(working_set.add_entry, sys.path))
- globals().update(locals())
diff --git a/venv/lib/python3.11/site-packages/pip/_vendor/pkg_resources/__pycache__/__init__.cpython-311.pyc b/venv/lib/python3.11/site-packages/pip/_vendor/pkg_resources/__pycache__/__init__.cpython-311.pyc
deleted file mode 100644
index ccf1389..0000000
Binary files a/venv/lib/python3.11/site-packages/pip/_vendor/pkg_resources/__pycache__/__init__.cpython-311.pyc and /dev/null differ
diff --git a/venv/lib/python3.11/site-packages/pip/_vendor/platformdirs/__init__.py b/venv/lib/python3.11/site-packages/pip/_vendor/platformdirs/__init__.py
deleted file mode 100644
index 5ebf595..0000000
--- a/venv/lib/python3.11/site-packages/pip/_vendor/platformdirs/__init__.py
+++ /dev/null
@@ -1,566 +0,0 @@
-"""
-Utilities for determining application-specific dirs. See for details and
-usage.
-"""
-from __future__ import annotations
-
-import os
-import sys
-from typing import TYPE_CHECKING
-
-from .api import PlatformDirsABC
-from .version import __version__
-from .version import __version_tuple__ as __version_info__
-
-if TYPE_CHECKING:
- from pathlib import Path
-
- if sys.version_info >= (3, 8): # pragma: no cover (py38+)
- from typing import Literal
- else: # pragma: no cover (py38+)
- from pip._vendor.typing_extensions import Literal
-
-
-def _set_platform_dir_class() -> type[PlatformDirsABC]:
- if sys.platform == "win32":
- from pip._vendor.platformdirs.windows import Windows as Result
- elif sys.platform == "darwin":
- from pip._vendor.platformdirs.macos import MacOS as Result
- else:
- from pip._vendor.platformdirs.unix import Unix as Result
-
- if os.getenv("ANDROID_DATA") == "/data" and os.getenv("ANDROID_ROOT") == "/system":
- if os.getenv("SHELL") or os.getenv("PREFIX"):
- return Result
-
- from pip._vendor.platformdirs.android import _android_folder
-
- if _android_folder() is not None:
- from pip._vendor.platformdirs.android import Android
-
- return Android # return to avoid redefinition of result
-
- return Result
-
-
-PlatformDirs = _set_platform_dir_class() #: Currently active platform
-AppDirs = PlatformDirs #: Backwards compatibility with appdirs
-
-
-def user_data_dir(
- appname: str | None = None,
- appauthor: str | None | Literal[False] = None,
- version: str | None = None,
- roaming: bool = False, # noqa: FBT001, FBT002
- ensure_exists: bool = False, # noqa: FBT001, FBT002
-) -> str:
- """
- :param appname: See `appname `.
- :param appauthor: See `appauthor `.
- :param version: See `version `.
- :param roaming: See `roaming `.
- :param ensure_exists: See `ensure_exists `.
- :returns: data directory tied to the user
- """
- return PlatformDirs(
- appname=appname,
- appauthor=appauthor,
- version=version,
- roaming=roaming,
- ensure_exists=ensure_exists,
- ).user_data_dir
-
-
-def site_data_dir(
- appname: str | None = None,
- appauthor: str | None | Literal[False] = None,
- version: str | None = None,
- multipath: bool = False, # noqa: FBT001, FBT002
- ensure_exists: bool = False, # noqa: FBT001, FBT002
-) -> str:
- """
- :param appname: See `appname `.
- :param appauthor: See `appauthor `.
- :param version: See `version `.
- :param multipath: See `roaming `.
- :param ensure_exists: See `ensure_exists `.
- :returns: data directory shared by users
- """
- return PlatformDirs(
- appname=appname,
- appauthor=appauthor,
- version=version,
- multipath=multipath,
- ensure_exists=ensure_exists,
- ).site_data_dir
-
-
-def user_config_dir(
- appname: str | None = None,
- appauthor: str | None | Literal[False] = None,
- version: str | None = None,
- roaming: bool = False, # noqa: FBT001, FBT002
- ensure_exists: bool = False, # noqa: FBT001, FBT002
-) -> str:
- """
- :param appname: See `appname `.
- :param appauthor: See `appauthor `.
- :param version: See `version `.
- :param roaming: See `roaming `.
- :param ensure_exists: See `ensure_exists `.
- :returns: config directory tied to the user
- """
- return PlatformDirs(
- appname=appname,
- appauthor=appauthor,
- version=version,
- roaming=roaming,
- ensure_exists=ensure_exists,
- ).user_config_dir
-
-
-def site_config_dir(
- appname: str | None = None,
- appauthor: str | None | Literal[False] = None,
- version: str | None = None,
- multipath: bool = False, # noqa: FBT001, FBT002
- ensure_exists: bool = False, # noqa: FBT001, FBT002
-) -> str:
- """
- :param appname: See `appname `.
- :param appauthor: See `appauthor `.
- :param version: See `version `.
- :param multipath: See `roaming `.
- :param ensure_exists: See `ensure_exists `.
- :returns: config directory shared by the users
- """
- return PlatformDirs(
- appname=appname,
- appauthor=appauthor,
- version=version,
- multipath=multipath,
- ensure_exists=ensure_exists,
- ).site_config_dir
-
-
-def user_cache_dir(
- appname: str | None = None,
- appauthor: str | None | Literal[False] = None,
- version: str | None = None,
- opinion: bool = True, # noqa: FBT001, FBT002
- ensure_exists: bool = False, # noqa: FBT001, FBT002
-) -> str:
- """
- :param appname: See `appname `.
- :param appauthor: See `appauthor `.
- :param version: See `version `.
- :param opinion: See `roaming `.
- :param ensure_exists: See `ensure_exists `.
- :returns: cache directory tied to the user
- """
- return PlatformDirs(
- appname=appname,
- appauthor=appauthor,
- version=version,
- opinion=opinion,
- ensure_exists=ensure_exists,
- ).user_cache_dir
-
-
-def site_cache_dir(
- appname: str | None = None,
- appauthor: str | None | Literal[False] = None,
- version: str | None = None,
- opinion: bool = True, # noqa: FBT001, FBT002
- ensure_exists: bool = False, # noqa: FBT001, FBT002
-) -> str:
- """
- :param appname: See `appname `.
- :param appauthor: See `appauthor `.
- :param version: See `version `.
- :param opinion: See `opinion `.
- :param ensure_exists: See `ensure_exists `.
- :returns: cache directory tied to the user
- """
- return PlatformDirs(
- appname=appname,
- appauthor=appauthor,
- version=version,
- opinion=opinion,
- ensure_exists=ensure_exists,
- ).site_cache_dir
-
-
-def user_state_dir(
- appname: str | None = None,
- appauthor: str | None | Literal[False] = None,
- version: str | None = None,
- roaming: bool = False, # noqa: FBT001, FBT002
- ensure_exists: bool = False, # noqa: FBT001, FBT002
-) -> str:
- """
- :param appname: See `appname `.
- :param appauthor: See `appauthor `.
- :param version: See `version `.
- :param roaming: See `roaming `.
- :param ensure_exists: See `ensure_exists `.
- :returns: state directory tied to the user
- """
- return PlatformDirs(
- appname=appname,
- appauthor=appauthor,
- version=version,
- roaming=roaming,
- ensure_exists=ensure_exists,
- ).user_state_dir
-
-
-def user_log_dir(
- appname: str | None = None,
- appauthor: str | None | Literal[False] = None,
- version: str | None = None,
- opinion: bool = True, # noqa: FBT001, FBT002
- ensure_exists: bool = False, # noqa: FBT001, FBT002
-) -> str:
- """
- :param appname: See `appname `.
- :param appauthor: See `appauthor `.
- :param version: See `version
 +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+
+ <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  + }
+
+ }
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  + }
+
+ }
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+ 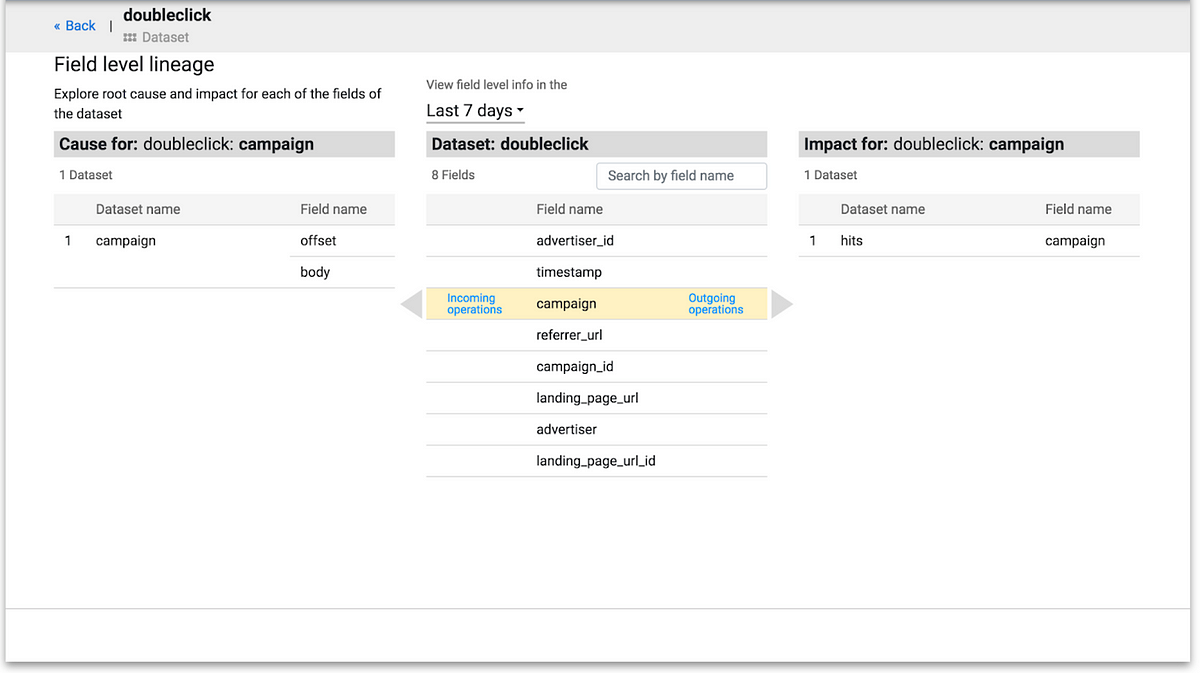 +
+  +
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+  +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+ 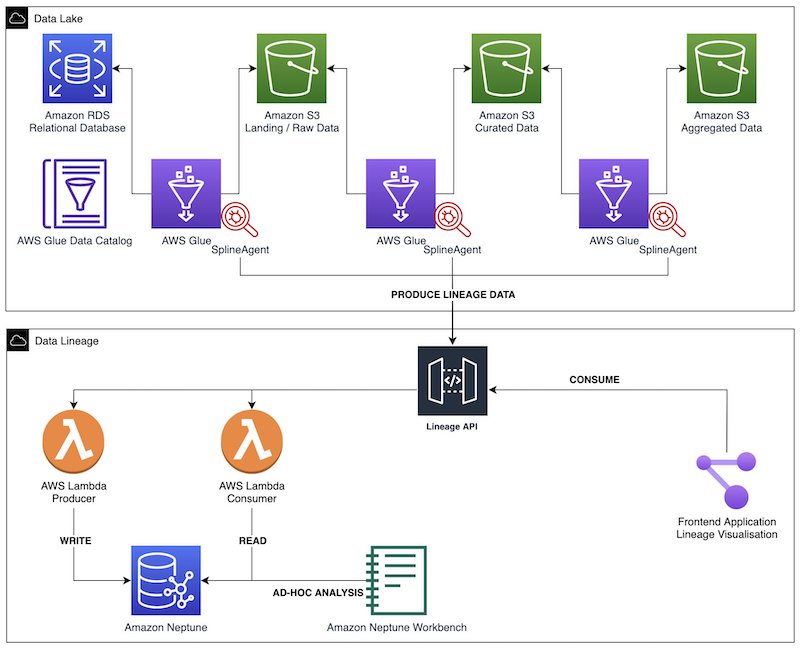 +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  + }
+
+ }
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+ 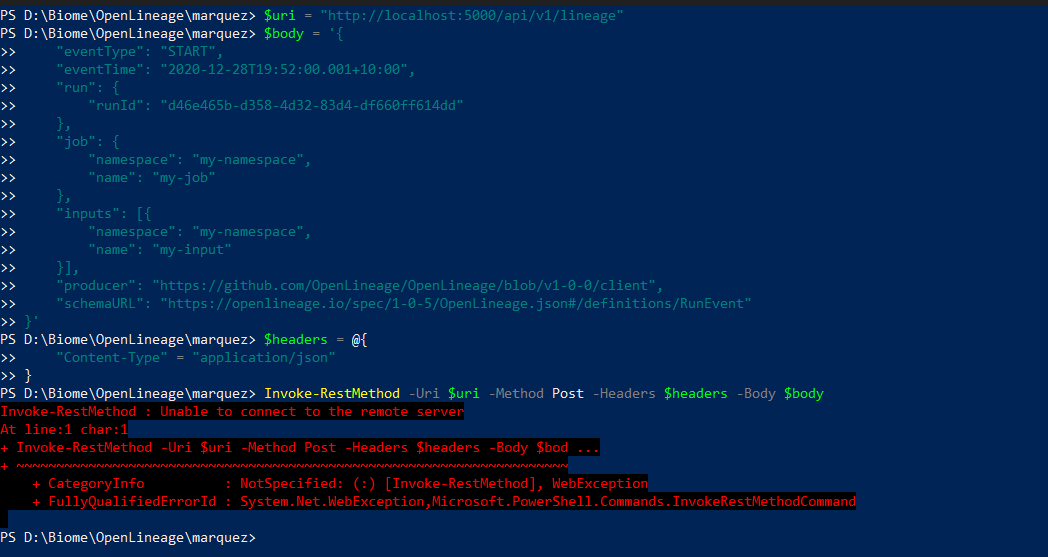 +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+  +
+  +
+
+
+
+
+ 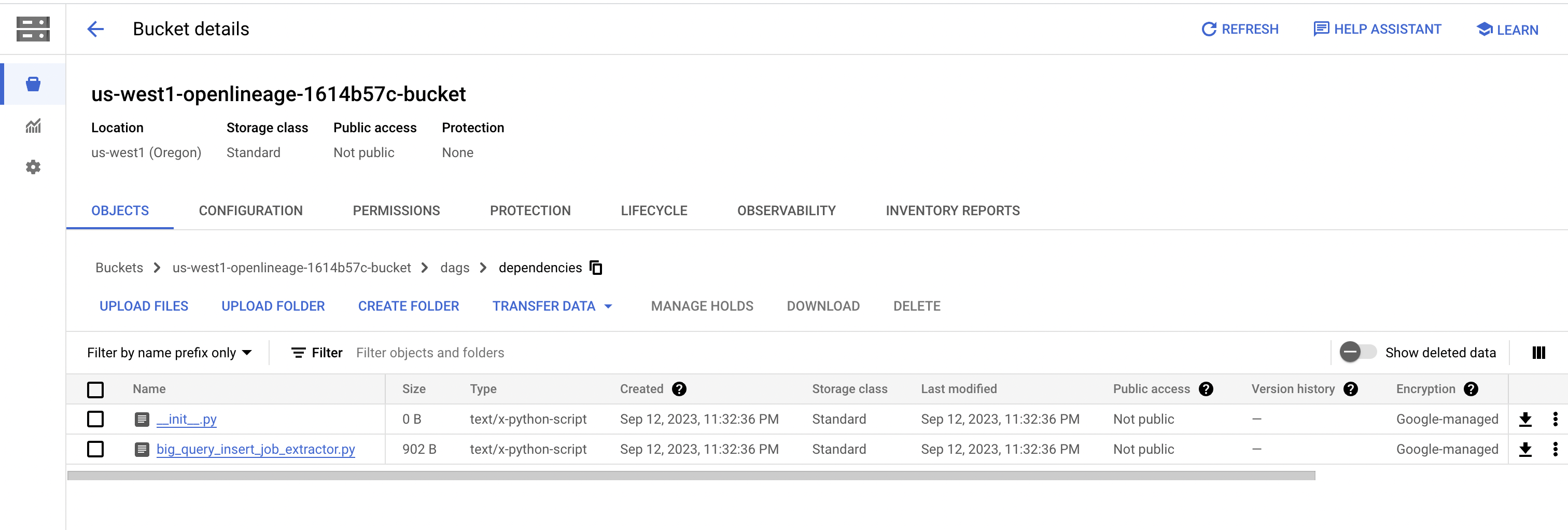 +
+ 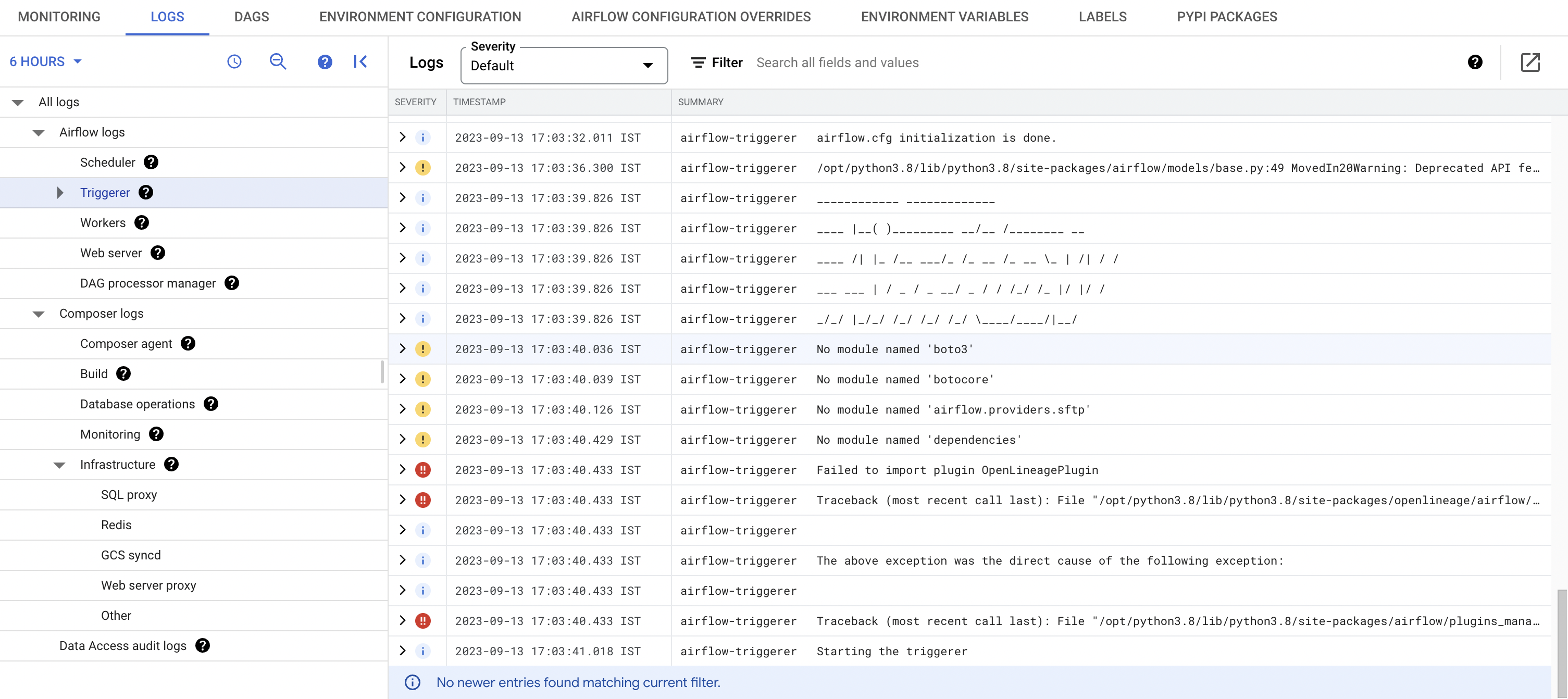 +
+ 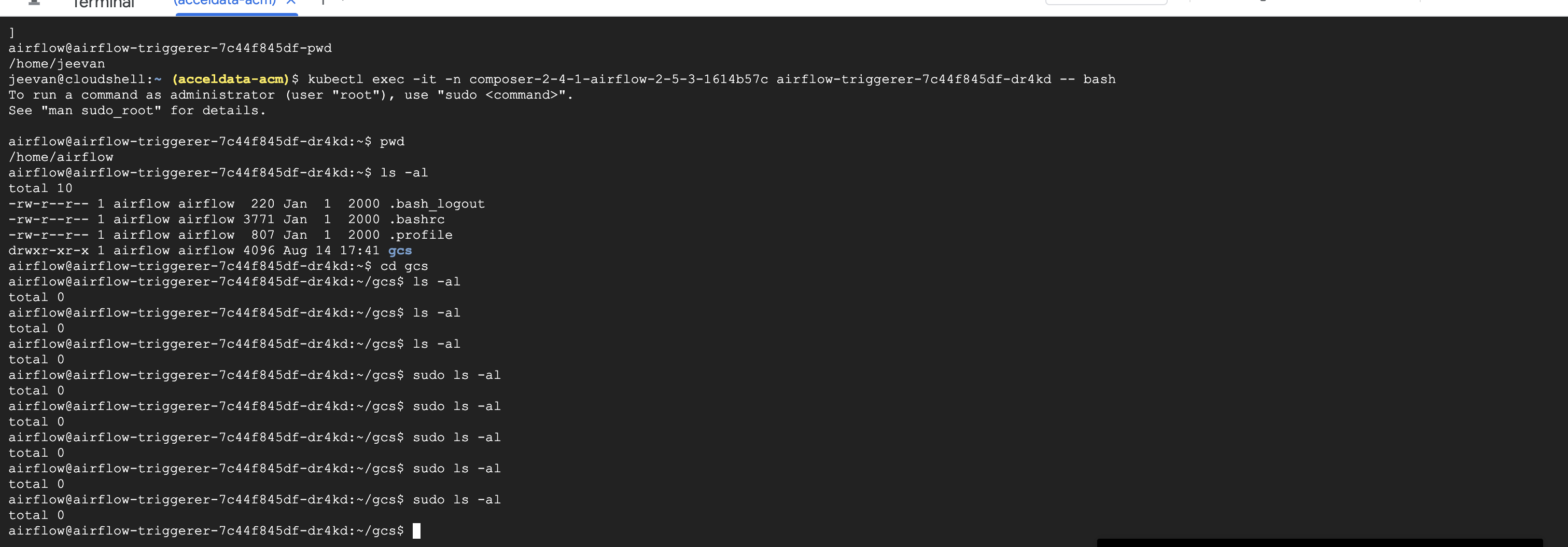 +
+  + }
+
+ }
+  +
+ 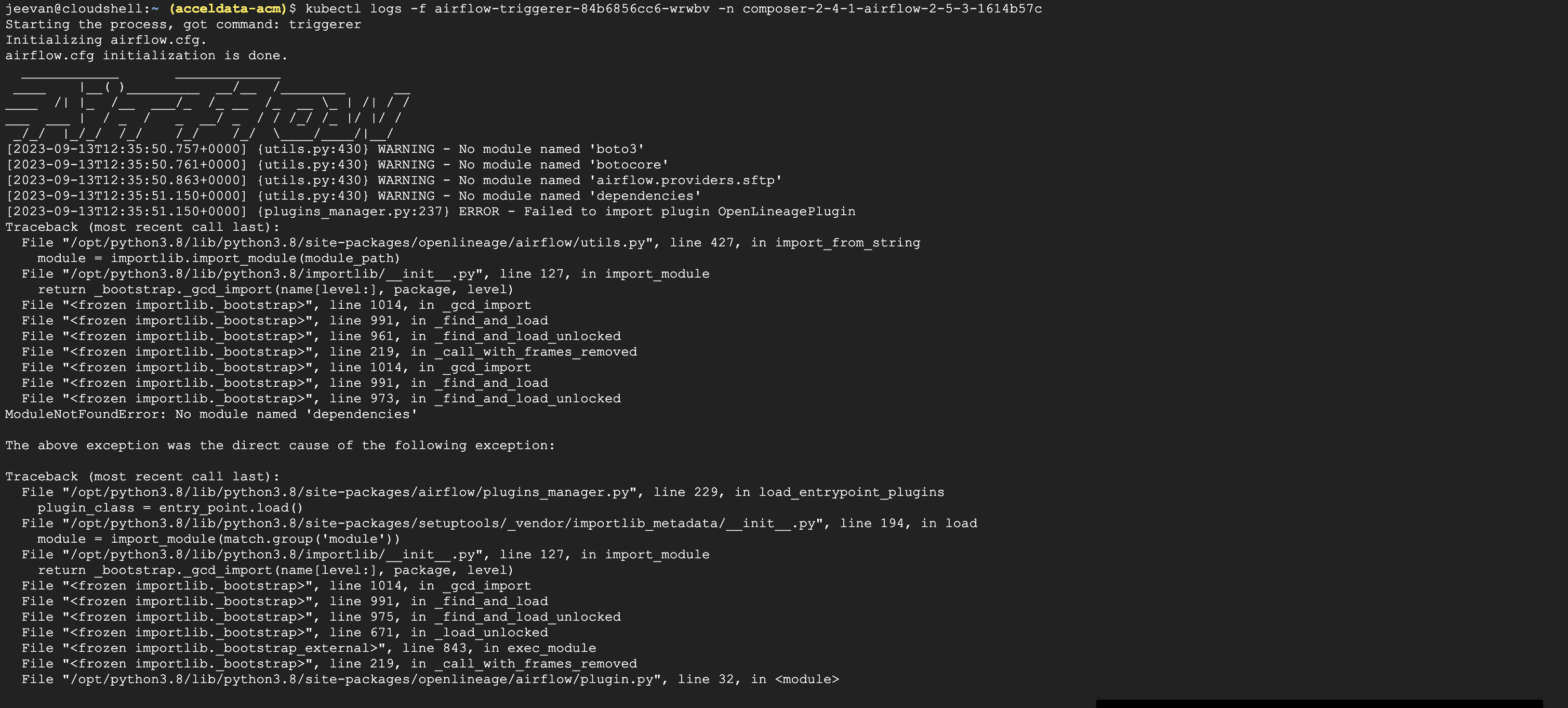 +
+ 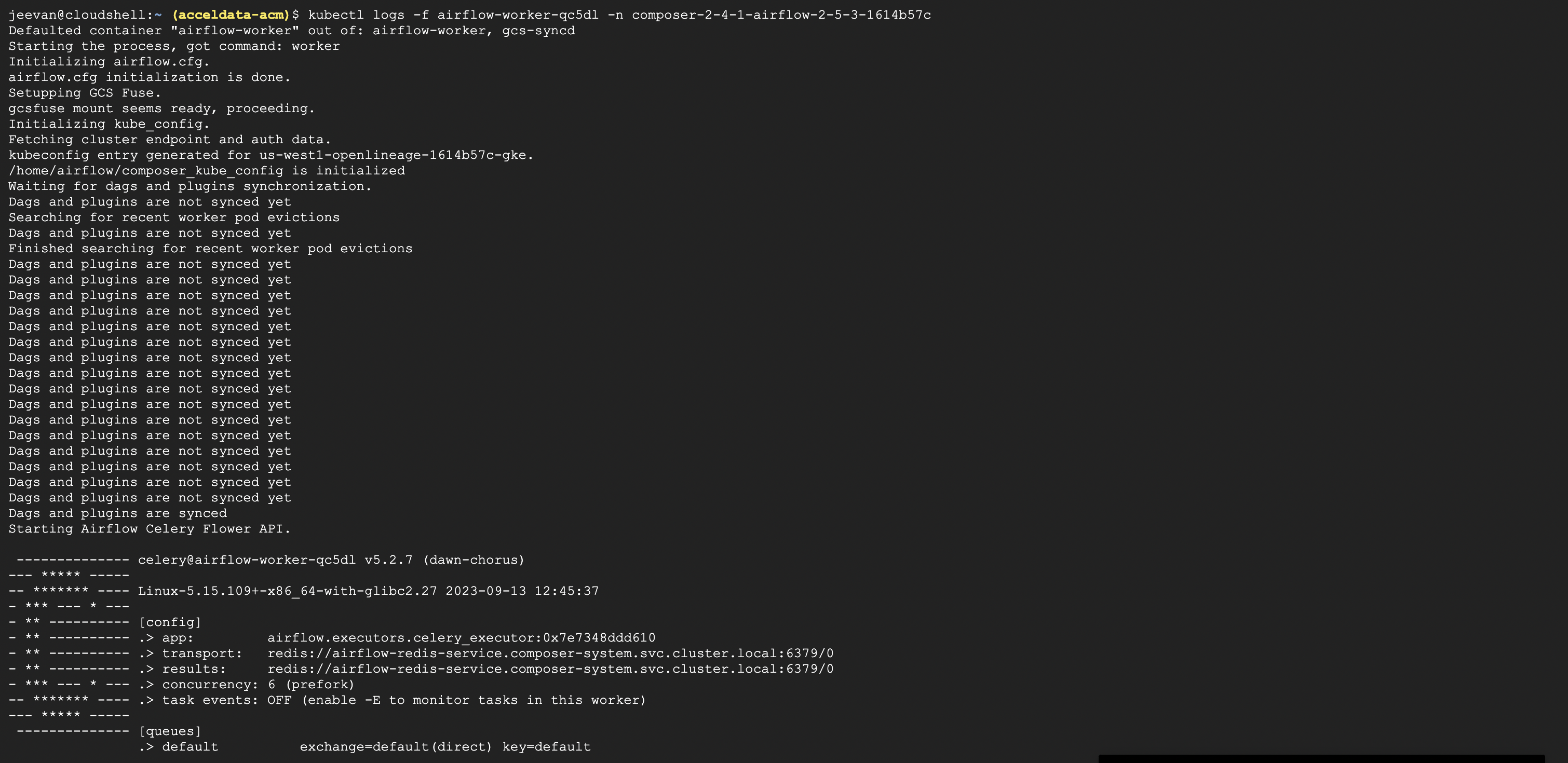 +
+ 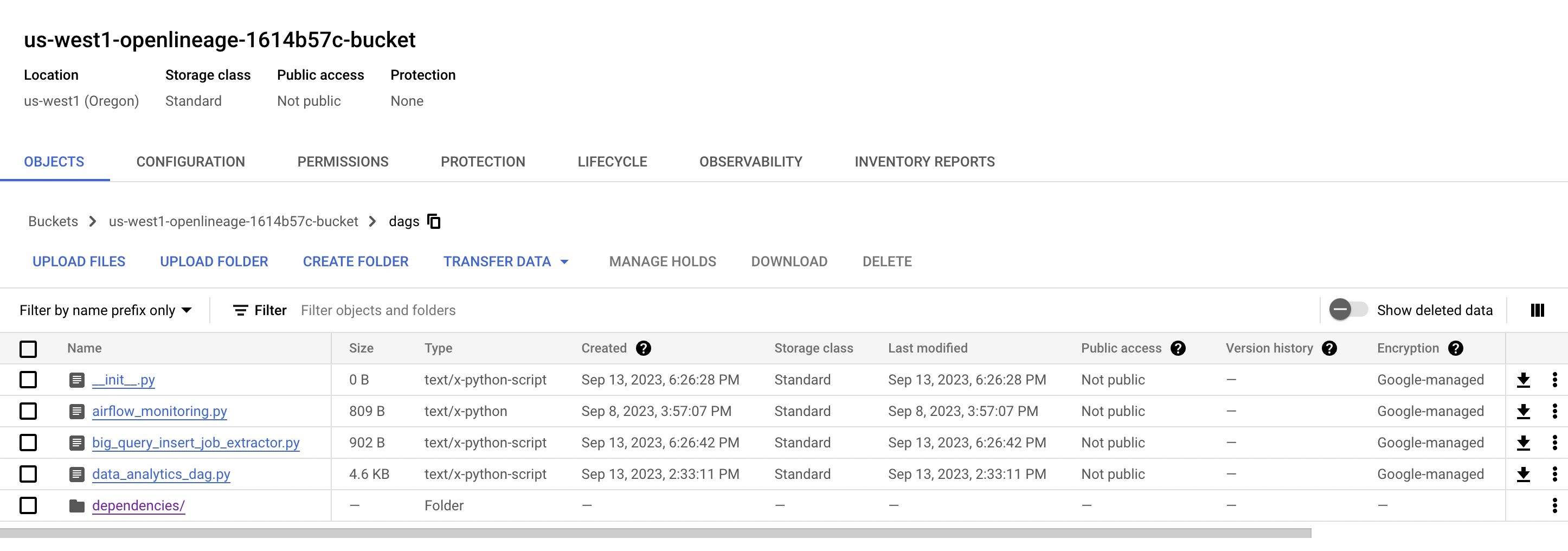 +
+  +
+  +
+  + }
+
+ }
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+ 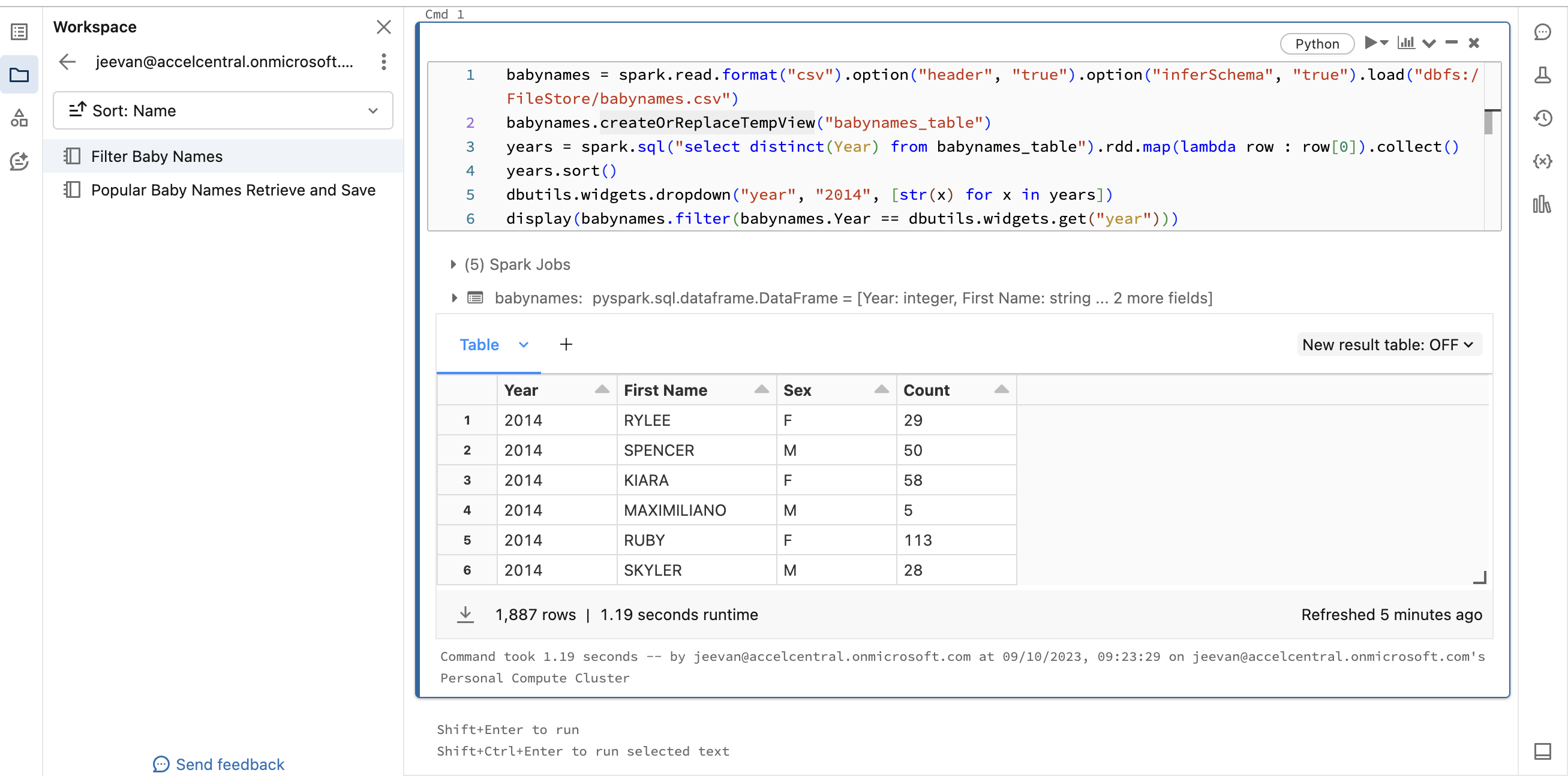 +
+  +
+  +
+
+
+
+
+ 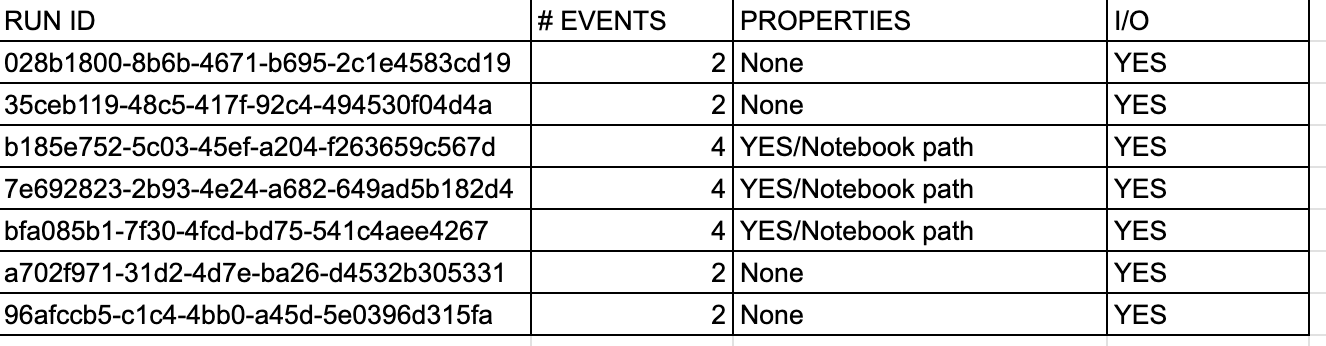 +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  + }
+
+ }
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+  +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+ {kind=link}
{kind=link}
{kind=link}
{kind=link}